C++拾取——Linux下实测布隆过滤器(Bloom filter)和unordered_multiset查询效率
Posted breaksoftware
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了C++拾取——Linux下实测布隆过滤器(Bloom filter)和unordered_multiset查询效率相关的知识,希望对你有一定的参考价值。
布隆过滤器是一种判定元素是否存在于集合中的方法。其基本原理是使用哈希方法将数据映射到一个很长的向量上。在维基百科上,它被称为“空间效率和查询时间都远远超过一般的算法”的方法。由于它只保存散列的数据,所以对于很长的数据有着良好的压缩特性,这个是个不争的事实(可以参见《布隆过滤器 (Bloom Filter) 详解》)。但是其查询效率究竟如何,我们还是要实际测试一下。(转载请指明出于breaksoftware的csdn博客)
我们选用unordered_multiset作为对比对象,是因为在《C++拾趣——STL容器的插入、删除、遍历和查找操作性能对比(ubuntu g++)——遍历和查找》中,实验验证它的查询效率是最高的。
由于布隆过滤器存在以下特性:
- 判定不存在的一定不存在
- 判定存在的可能不存在
实验分为两部分:
- 查找集合中不存在的元素
- 查找集合中存在的元素
由于布隆过滤器存在一定的误算率,所以在1的场景下,存在判定元素存在的可能性(存在误算率)。
我们使用的是https://github.com/ArashPartow/bloom版本的实现,它可以指定误算率。
由于散列计算需要时间,所以数据的长度也将是一个比较因子。于是上述每个实验都有三个影响因素
- 误算率
- 集合大小
- 数据长度
查找集合中不存在的元素
不同数据长度
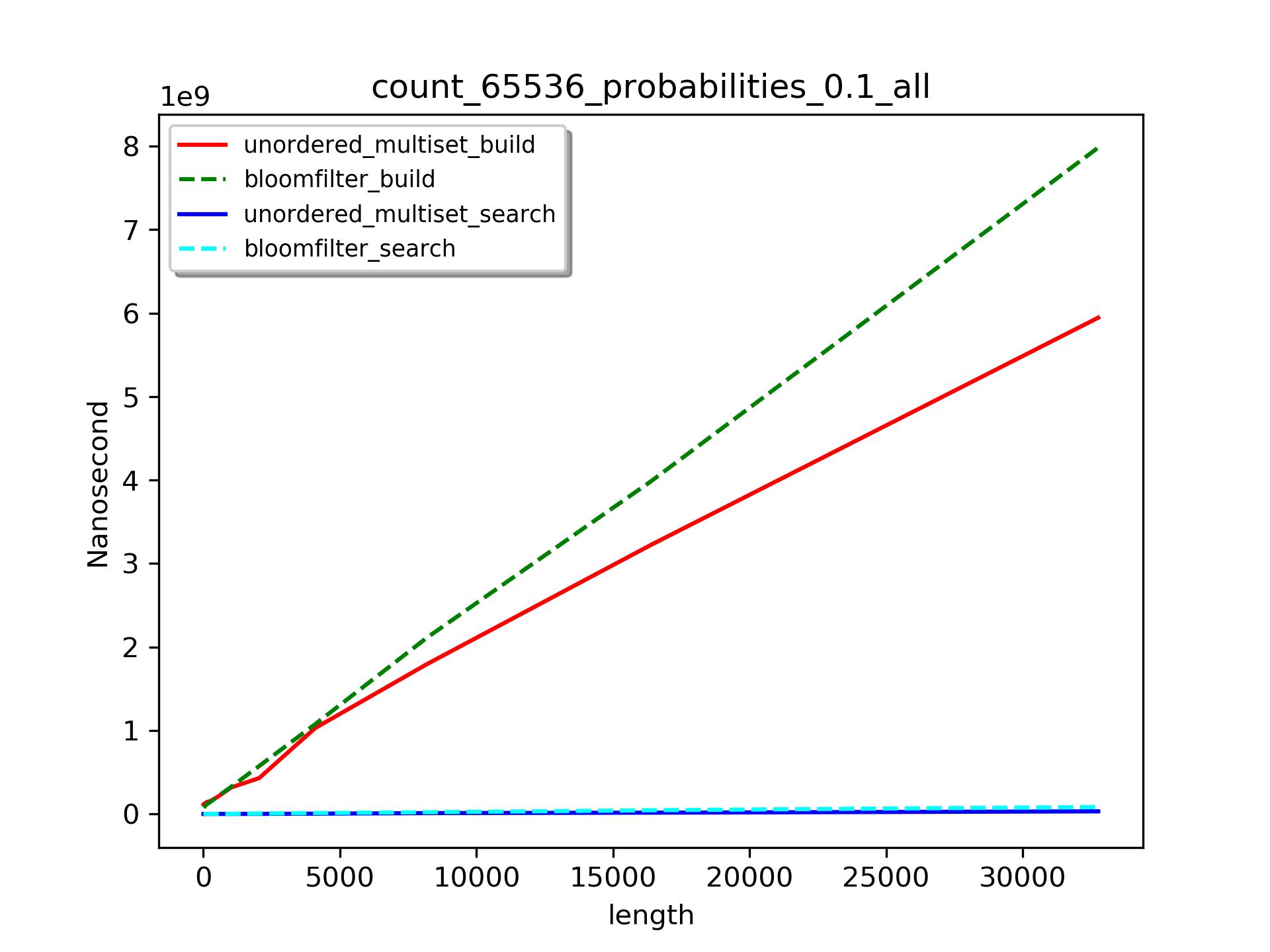
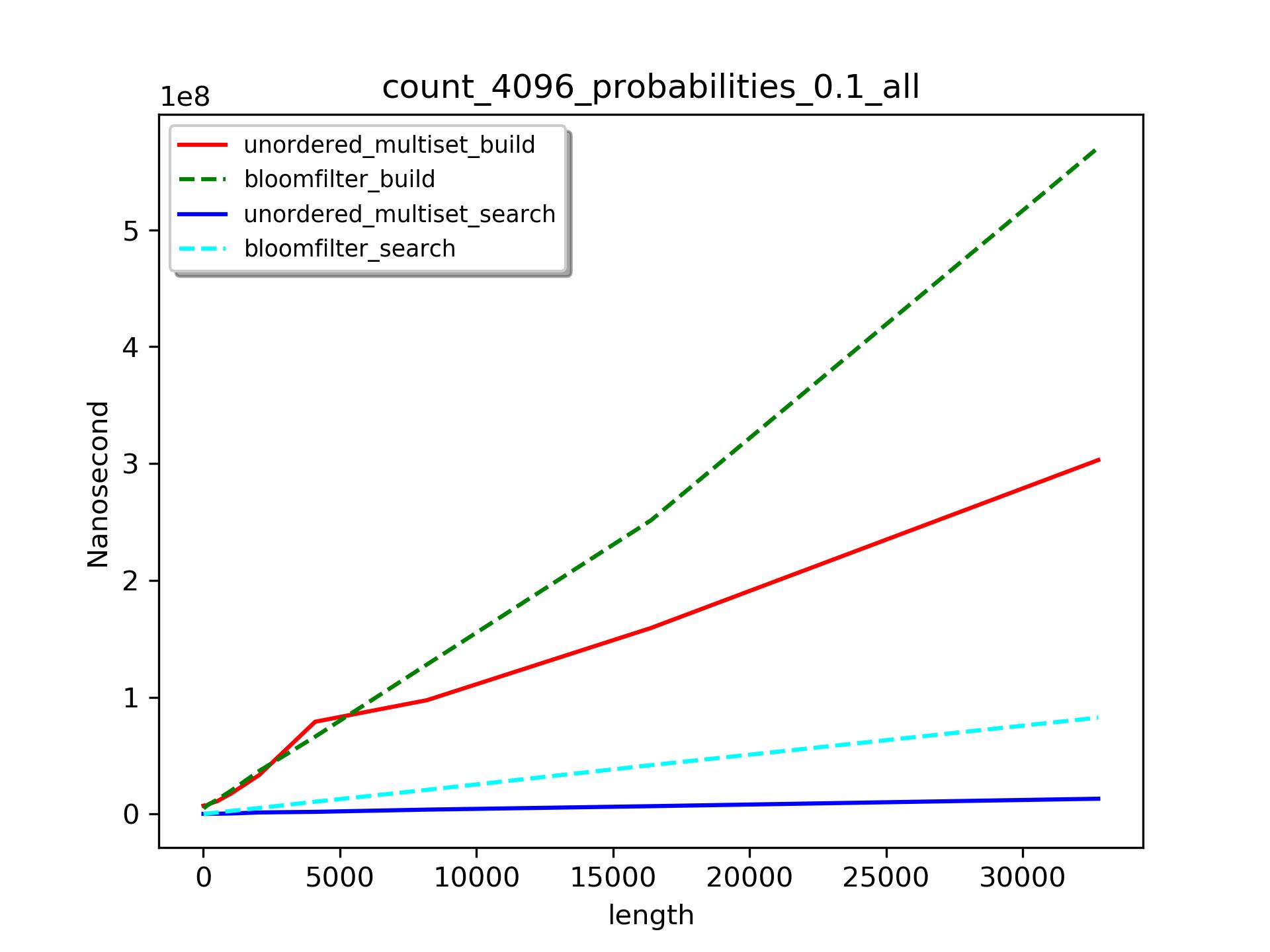
在集合大小(65536)和误算率(0.1)确定的情况下,我们比较不同数据长度下,unordered_multiset、bloomfilter的构建,和它们查找1024个不存在的元素的时间消耗。
构建时间

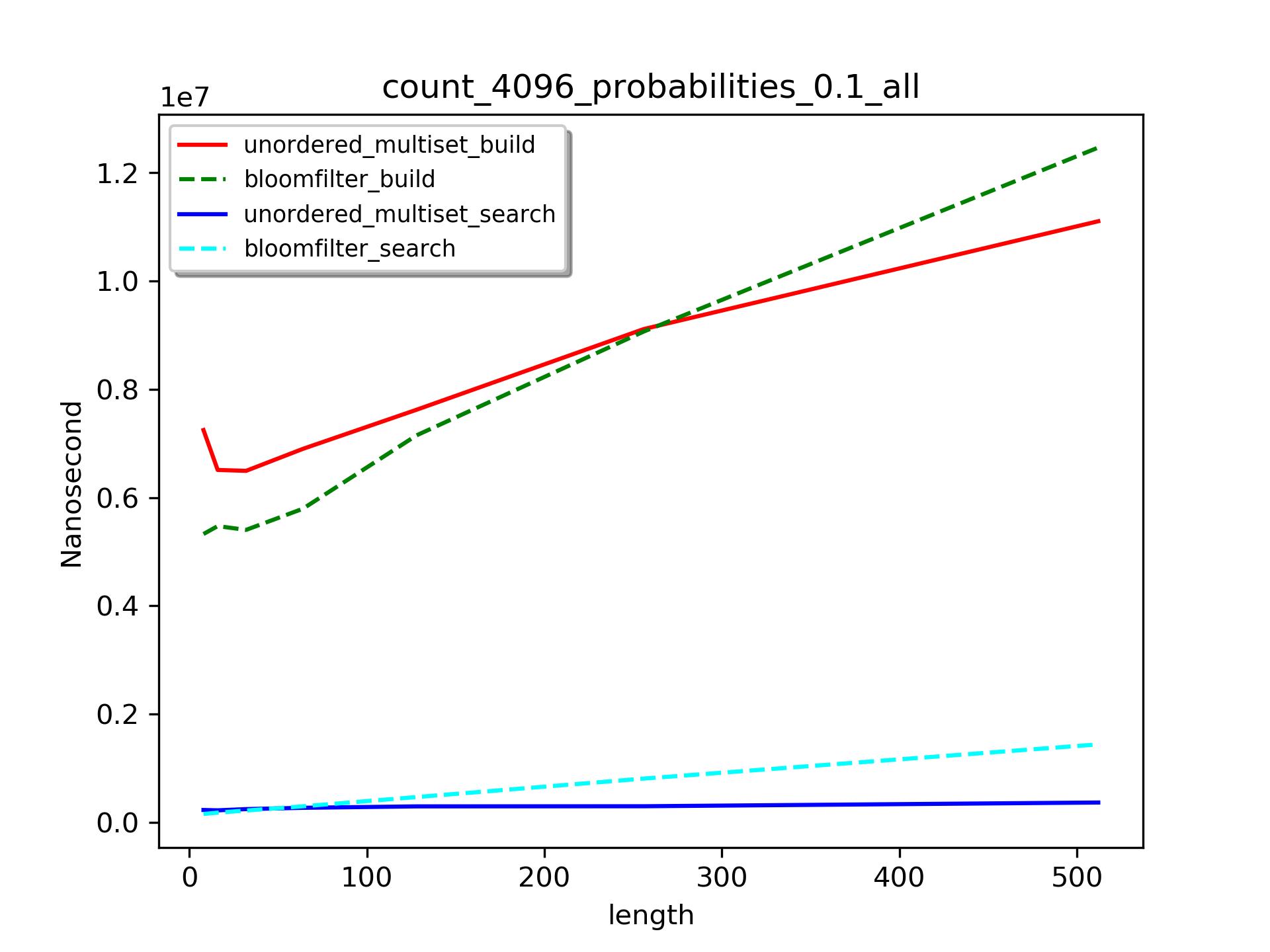
可以见得,查找(search)时间比构建(build)时间要少很多。
当数据长度小于500时,bloomfilter比unordered_multiset构建时间要短。但是随着数据长度的增长,前者将花费更多的时间。也就是说unordered_multiset和bloomfilter的构建时间都符合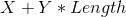 线性增长规律,但是unordered_multiset初始耗时
线性增长规律,但是unordered_multiset初始耗时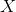 比bloomfilter要长,但是其增长系数
比bloomfilter要长,但是其增长系数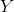 比后者小。
比后者小。
查找时间
再看下查找(search)时间
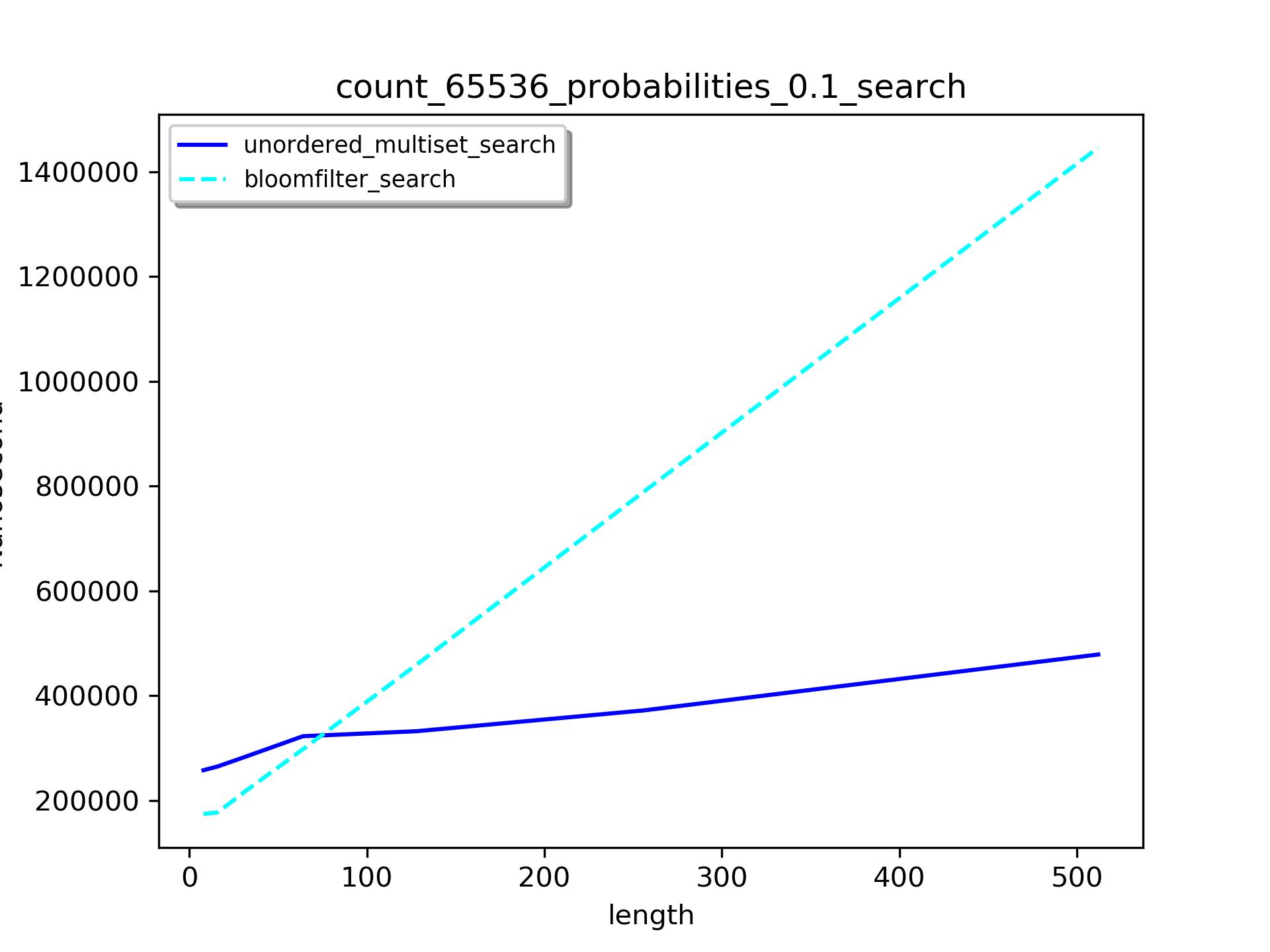
在数据长度低于80时,bloomfilter比unordered_multiset要快。但是随着数据长度的增加,前者越来越慢。当数据长度达到30000时,存在2倍多的差距。

随着数据长度增加,bloomfilter的查找时间比unordered_multiset要长。
上述趋势规律在数据个数比较小时也适合,只是交叉点有所变化
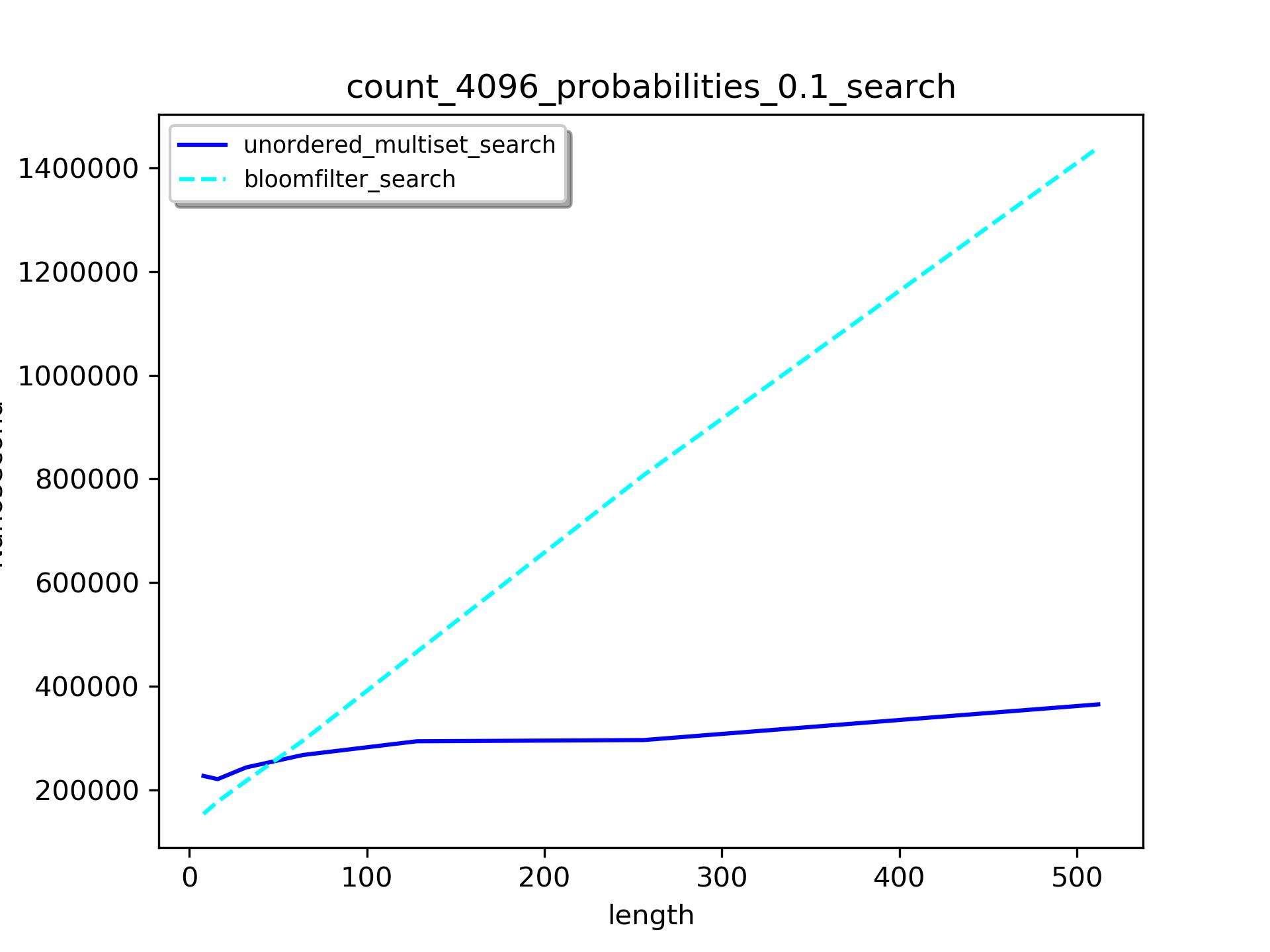
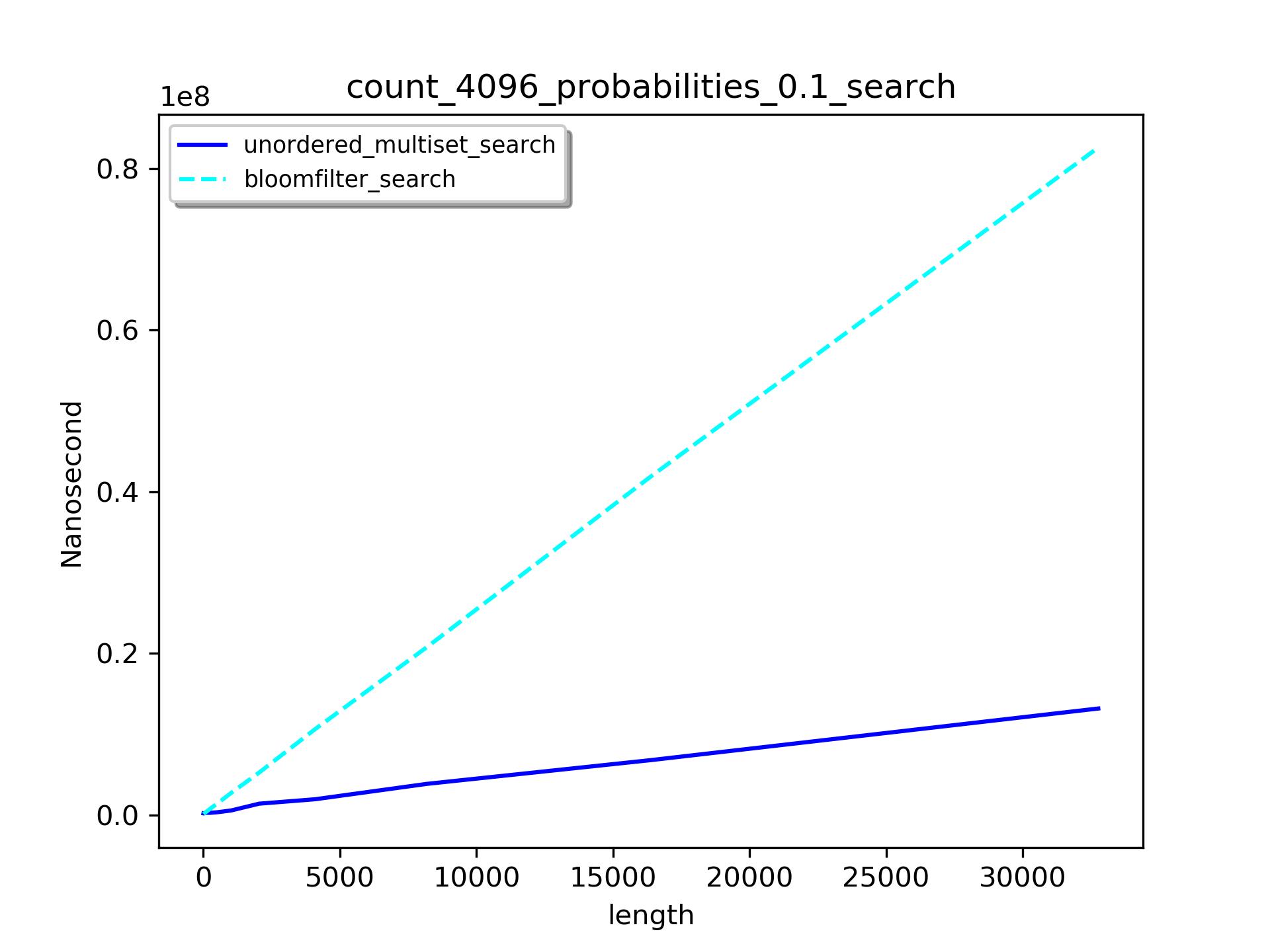
不同集合大小
在数据长度(256)和误算率(0.1)确定的情况下,我们比较不同集合大小时,unordered_multiset、bloomfilter的构建,和它们查找1024个不存在的元素的时间消耗。
构建耗时
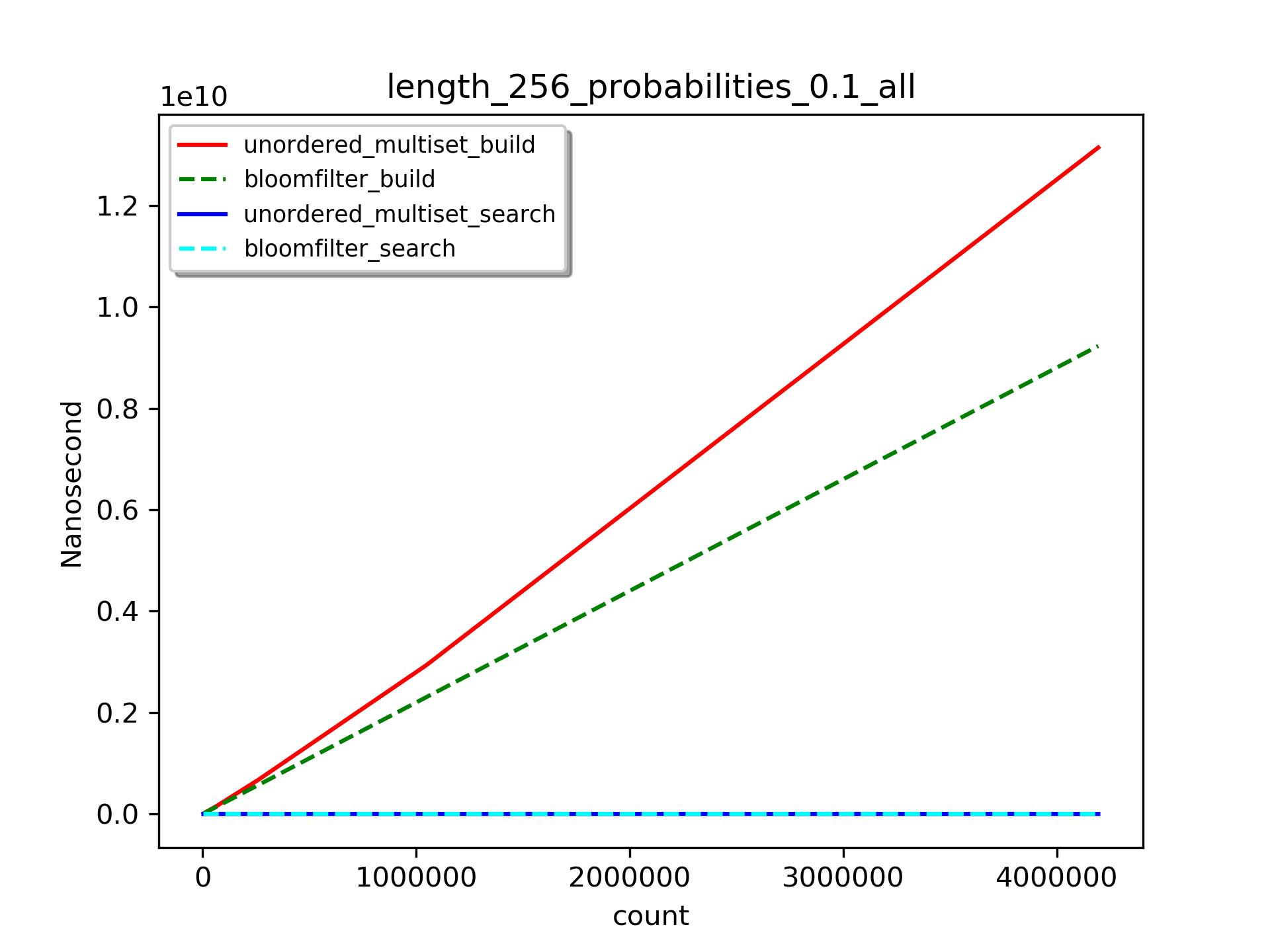
在相同数据长度的情况下,bloomfilter比unordered_multiset构建速度要快些,而且随着集合个数增长,其优势更加明显。
查找时间
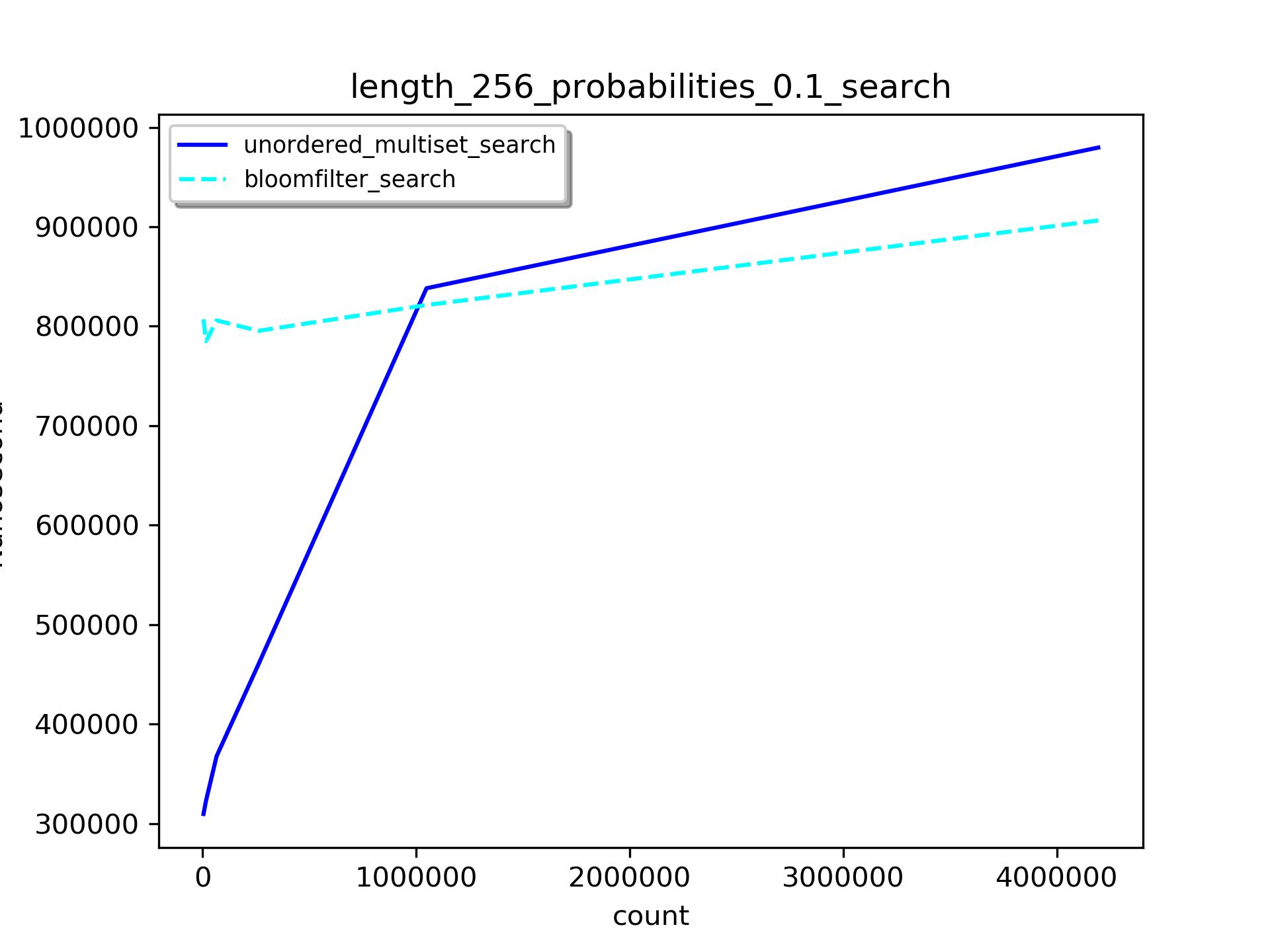
当集合个数少于1,000,000个时,bloomfilter的查找还是比unordered_multiset慢,但是unordered_multiset随着集合大小增长会越来越慢。一旦超过阀值,unordered_multiset就永远比bloomfilter要慢了。而bloomfilter的查找速度一直比较稳定。
不同误算率
在数据长度(256)和集合个数(1048576)确定的情况下,我们比较不同误算率下,unordered_multiset、bloomfilter的构建,和它们查找1024个不存在的元素的时间消耗。
构建时间
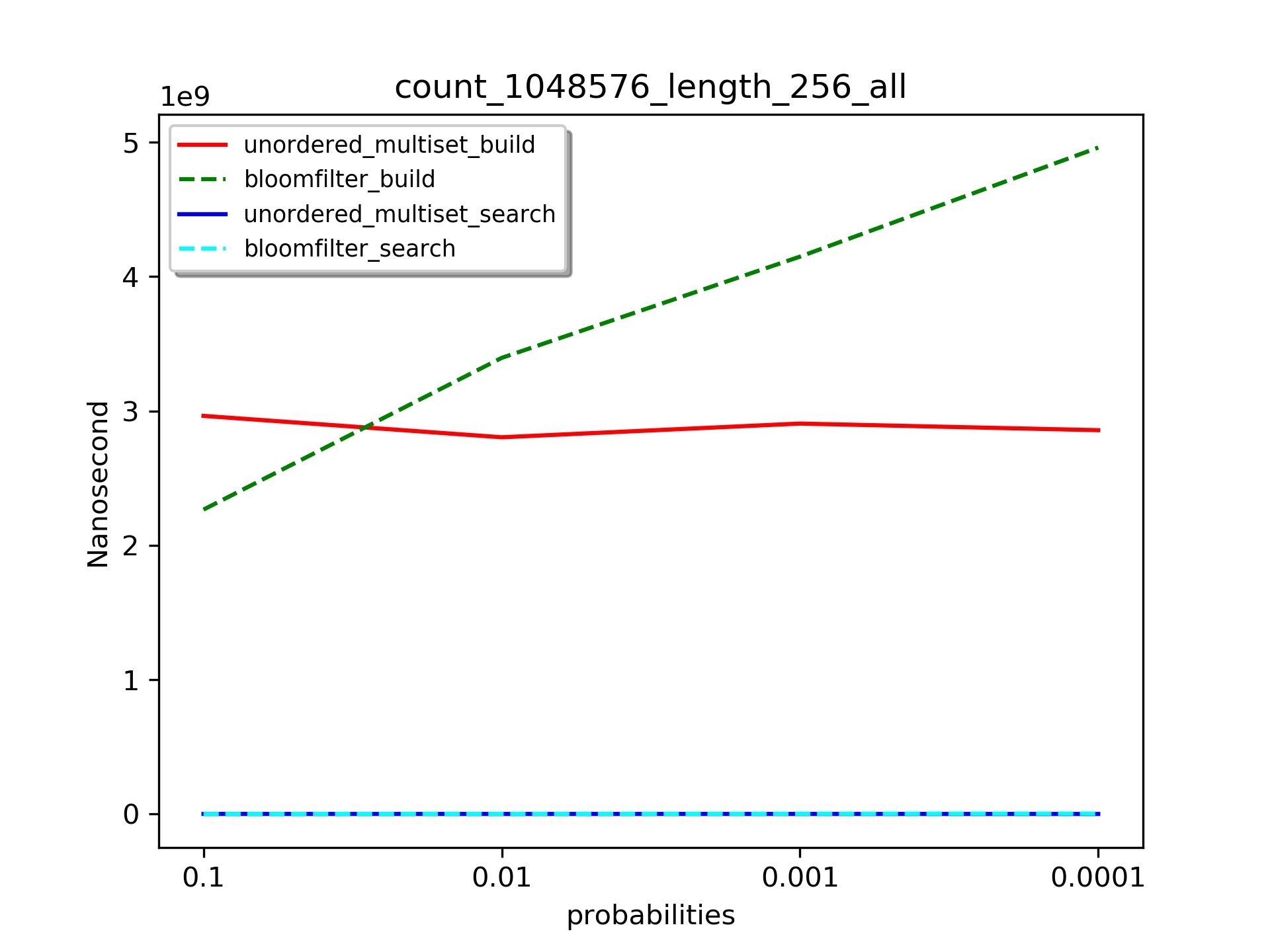
因为unordered_multiset和误算率没有关系,而且数据长度和集合大小固定,所以它几乎是条直线。但是我们看到随着误算率的降低,bloomfilter的构建速度也在变慢。
查找时间

由于unordered_multiset和误算率无关,所以其查找时间也几乎是条直线。但是随着误算率降低,bloomfilter的查找时间越来越高。
查找集合中存在的元素
经过实验,其结果和“查找集合中不存在的元素”规律一致,这儿就不把图再罗列了。
总结:
- 随着集合个数增长,unordered_multiset的查找速度越来越慢。而bloomfilter比较稳定。个数较少时bloomfilter比unordered_multiset慢,但是超过一定阀值,bloomfilter将比unordered_multiset快。
- 随着数据长度增长,bloomfilter的查找速度越来越慢。而且速度比unordered_multiset慢较多。
- 随着误算率降低,bloomfilter的查找速度越来越慢。
- 除了内存因素外,检测bloomfilter是否是适合应用场景,需要基于上面三个因素做实验之后才能判断。
测试代码和生成图的代码见https://github.com/f304646673/test_bloomfilter
以上是关于C++拾取——Linux下实测布隆过滤器(Bloom filter)和unordered_multiset查询效率的主要内容,如果未能解决你的问题,请参考以下文章