ZooKeeper 的原理是什么?
Posted 学一次
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ZooKeeper 的原理是什么?相关的知识,希望对你有一定的参考价值。
分析&回答
什么是ZooKeeper
ZooKeeper是一项集中式服务,用于维护配置信息,命名,提供分布式同步和提供组服务。 ZooKeeper简单,分布式,可靠且快速。
- 维护配置信息: 它维护集群配置信息,该信息在集群中的所有节点之间共享。
- 命名:Zookeeper可以用作命名服务,以便集群中的一个节点可以在大型集群中找到另一个节点,例如:1000个节点集群
- 提供分布式同步: 我们还可以使用Zookeeper通过使用锁,队列等来解决集群中的分布式同步问题。
- 提供群组服务:Zookeeper还可以通过选择集群中的主机来帮助进行群组服务(领导者选举过程)。
ZooKeeper设计目标:
ZooKeeper允许分布式进程通过共享的层次结构命名空间进行相互协调,这与标准文件系统类似。 名称空间由ZooKeeper中的数据寄存器组成 - 称为znode,这些类似于文件和目录。 与为存储设计的典型文件系统不同,ZooKeeper数据保存在内存中,这意味着ZooKeeper可以实现高吞吐量和低延迟。
Zookeeper层次结构命名空间示意图如下:
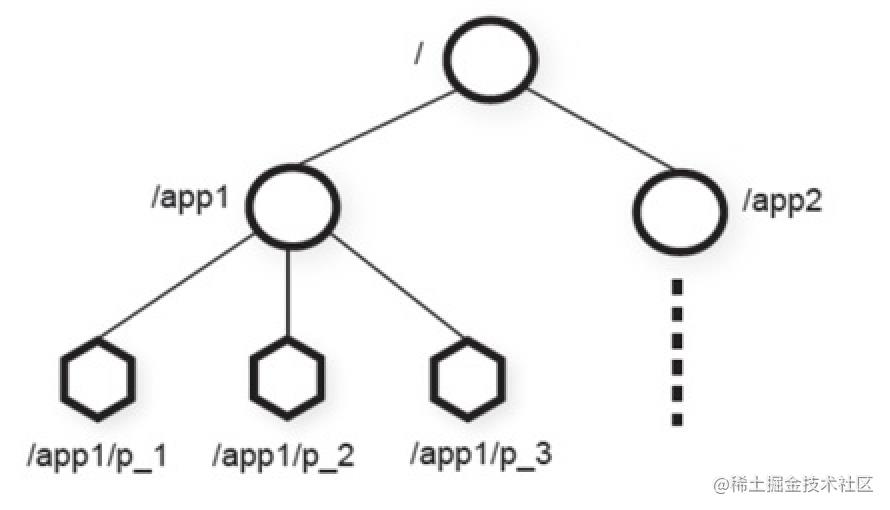
ZooKeeper主要特点:
- 最终一致性:为客户端展示同一视图,这是 ZooKeeper 最重要的性能。
- 可靠性:如果消息被一台服务器接受,那么它将被所有的服务器接受。
- 实时性:ZooKeeper 不能保证两个客户端同时得到刚更新的数据,如果需要最新数据,应该在读数据之前调用sync()接口。
- 等待无关(wait-free):慢的或者失效的 client 不干预快速的client的请求。
- 原子性:更新只能成功或者失败,没有中间其它状态。
- 顺序性:对于所有Server,同一消息发布顺序一致。
ZooKeeper 系统架构
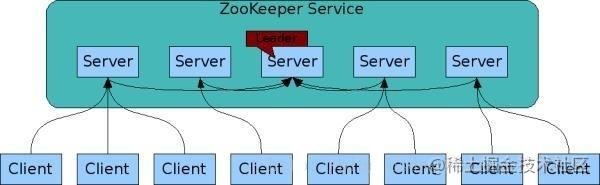
ZooKeeper 的架构图中我们需要了解和掌握的主要有:
- ZooKeeper分为服务器端(Server) 和客户端(Client) ,客户端可以连接到整个 ZooKeeper服务的任意服务器上(除非 leaderServes 参数被显式设置, leader 不允许接受客户端连接)。
- 客户端使用并维护一个 TCP 连接,通过这个连接发送请求、接受响应、获取观察的事件以及发送心跳。如果这个 TCP 连接中断,客户端将自动尝试连接到另外的 ZooKeeper服务器。客户端第一次连接到 ZooKeeper服务时,接受这个连接的 ZooKeeper服务器会为这个客户端建立一个会话。当这个客户端连接到另外的服务器时,这个会话会被新的服务器重新建立。
- 上图中每一个Server代表一个安装Zookeeper服务的机器,即是整个提供Zookeeper服务的集群(或者是由伪集群组成);
- 组成ZooKeeper服务的服务器必须彼此了解。 它们维护一个内存中的状态图像,以及持久存储中的事务日志和快照, 只要大多数服务器可用,ZooKeeper服务就可用;
- ZooKeeper 启动时,将从实例中选举一个 leader,Leader 负责处理数据更新等操作,一个更新操作成功的标志是当且仅当大多数Server在内存中成功修改数据。每个Server 在内存中存储了一份数据。
- Zookeeper是可以集群复制的,集群间通过Zab协议(Zookeeper Atomic Broadcast)来保持数据的一致性;
- Zab协议包含两个阶段:leader election阶段和Atomic Brodcast阶段。
- a) 集群中将选举出一个leader,其他的机器则称为follower,所有的写操作都被传送给leader,并通过brodcast将所有的更新告诉给follower。
- b) 当leader崩溃或者leader失去大多数的follower时,需要重新选举出一个新的leader,让所有的服务器都恢复到一个正确的状态。
- c) 当leader被选举出来,且大多数服务器完成了 和leader的状态同步后,leadder election 的过程就结束了,就将会进入到Atomic brodcast的过程。
- d) Atomic Brodcast同步leader和follower之间的信息,保证leader和follower具有形同的系统状态。
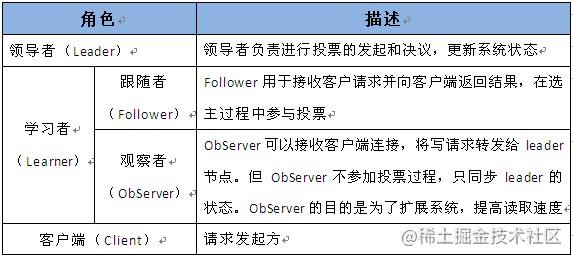
Zookeeper的角色
- 领导者(leader),负责进行投票的发起和决议,更新系统状态
- 学习者(learner),包括跟随者(follower)和观察者(observer)
- Follower用于接受客户端请求并想客户端返回结果,在选主过程中参与投票
- Observer可以接受客户端连接,将写请求转发给leader,但observer不参加投票过程,只同步leader的状态,observer的目的是为了扩展系统,提高读取速度
- 客户端(client),请求发起方
ZooKeeper数据模型
ZooKeeper具有层次结构的名称空间。 名称空间可以具有与其关联的数据以及子级。 到节点的路径始终表示为规范的,绝对的,斜杠分隔的路径。 没有相对参考。 这些名称空间的组织方式非常类似于Linux中的文件系统。ZooKeeper树中的每个节点都称为znode。 Znodes维护一个统计信息结构,其中包括用于数据更改,acl(访问控制列表)更改的版本号。 数据存储在znode中。
ZooKeeper 写数据流程
ZooKeeper 写数据的流程图如下所示。
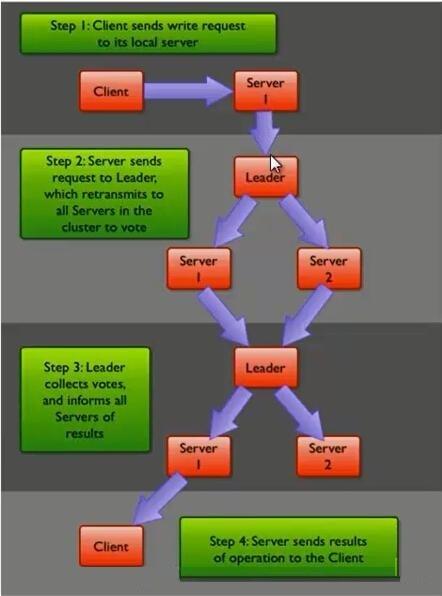
ZooKeeper 的写数据流程主要分为以下几步:
- a) 比如 Client 向 ZooKeeper 的 Server1 上写数据,发送一个写请求。
- b) 如果Server1不是Leader,那么Server1 会把接受到的请求进一步转发给Leader,因为每个ZooKeeper的Server里面有一个是Leader。这个Leader 会将写请求广播给各个Server,比如Server1和Server2, 各个Server写成功后就会通知Leader。
- c) 当Leader收到大多数 Server 数据写成功了,那么就说明数据写成功了。如果这里三个节点的话,只要有两个节点数据写成功了,那么就认为数据写成功了。写成功之后,Leader会告诉Server1数据写成功了。
- d) Server1会进一步通知 Client 数据写成功了,这时就认为整个写操作成功。
ZooKeeper 组件
ZooKeeper组件显示了ZooKeeper服务的高级组件。 除了请求处理器,组成ZooKeeper服务的每个服务器复制其自己的每个组件的副本。

Replicated Database是包含整个数据树的内存数据库。 更新操作会记录到磁盘里以进行可恢复性,并且写操作将在放到内存数据库之前序列化到磁盘。
每个ZooKeeper服务器服务客户端。 客户端连接到一个服务器以提交irequest。 读取请求从每个服务器数据库的本地副本服务。 更改服务状态(写入请求)的请求由协议进行处理。
作为协议协议的一部分,来自客户端的所有写请求被转发到单个服务器,称为leader。 其余的ZooKeeper服务器(称为followers)从领导者接收消息提议并同意消息传递。 消息层负责在失败时替换领导者,并与leader同步followers。
反思&扩展
为什么zookeeper集群的数目,一般为奇数个?
- Leader选举算法采用了Paxos协议;
- Paxos核心思想:当多数Server写成功,则任务数据写成功如果有3个Server,则两个写成功即可;如果有4或5个Server,则三个写成功即可。
- Server数目一般为奇数(3、5、7)如果有3个Server,则最多允许1个Server挂掉;如果有4个Server,则同样最多允许1个Server挂掉由此,我们看出3台服务器和4台服务器的的容灾能力是一样的,所以为了节省服务器资源,一般我们采用奇数个数,作为服务器部署个数。
为了大家更加方便的刷题,我们对文章进行了分类和整理,免费为大家提供刷题服务。程序员不欺骗程序员,赶紧扫码小程序刷起来!

为了一站式解决面者刷题问题,部分内容可能存在摘录情况,如有侵权辛苦您留言联系我们,我们会删除文章或添加引用文案,Thanks!
以上是关于ZooKeeper 的原理是什么?的主要内容,如果未能解决你的问题,请参考以下文章