CDH之impala
Posted 小基基o_O
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了CDH之impala相关的知识,希望对你有一定的参考价值。
文章目录
1、概述
官方图标

- Cloudera Impala是一款 时髦的、开源的、大规模并行处理的 SQL引擎
为Hadoop提供 低延时、高并发的 查询分析功能
1.1、特点
- 对内存的依赖很大,速度快但容易内存溢出
- data locality:尽可能地将读数和计算分配在同一台机器,减少网络开销
- 支持各种文件格式,如:文本文件、序列文件、RCFile、Avro、Parquet
- 支持压缩,如:snappy、gzip、bz2
- 可访问HIVE元数据,查询HIVE数据
- HIVE数据更新时,需要刷新该HIVE表【缺点】
1.2、架构
架构图

- 创建impalad进程,impalad向StateStore提交注册订阅信息,StateStore创建1个statestored进程,用来处理impalad的注册订阅信息
- 客户端提交SQL
- Query Planner解析SQL,生成解析树;然后Planner把解析树变成若干PlanFragment,发送到Query Coordinator
- Coordinator从元数据库中获取元数据,从HDFS的名称节点中获取数据地址,以得到存储这个查询相关数据的所有数据节点
- Query Coordinator初始化相应impalad上的任务执行,即把查询任务分配给所有存储这个查询相关数据的数据节点
- Query Executor读取HDFS数据
- Query Executor之间交换信息
- Query Coordinator汇聚来自各个Query Executor的结果
- Query Coordinator把结果返回给客户端。
| impala组成 | 进程 | 说明 |
|---|---|---|
| Catalog daemon | catalogd | 作为Impala的目录存储库和元数据接入网关 |
| Statestore daemon | statestored | 将整个集群的元数据传播到所有Impala进程 |
| Impala daemon | impalad | 1、负责协调客户端提交的查询的执行; 2、给其它impalad分配任务以及汇总其它Impalad的执行结果; 3、读取HDFS |
建议Impalad运行在DataNode所在节点
建议StateStore和Catalog服务在同一节点
2、CDH添加impala
添加服务
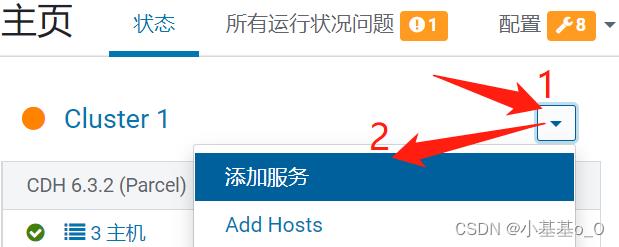
点选impala,然后继续

角色分配
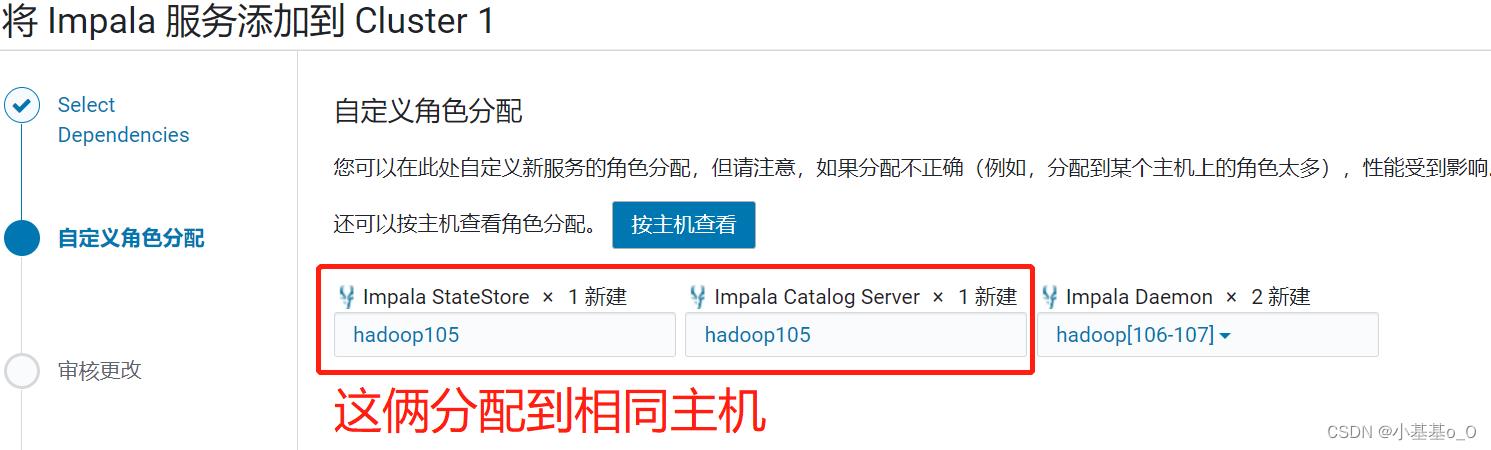
无修改

Hue配置关联impala
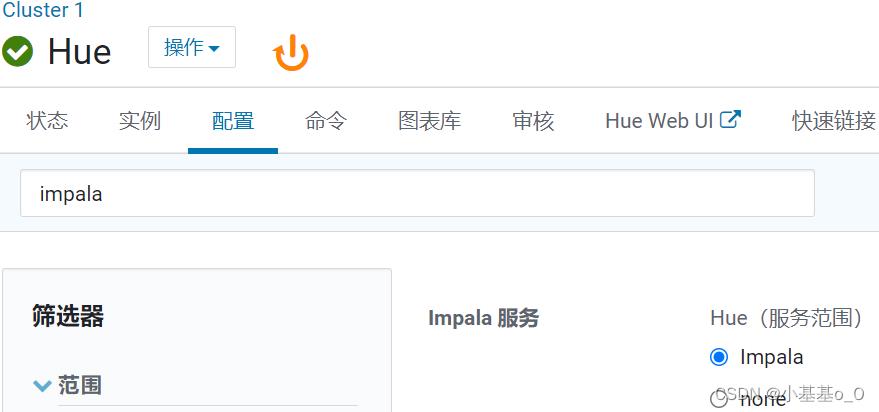
2.1、配置
impalad内存

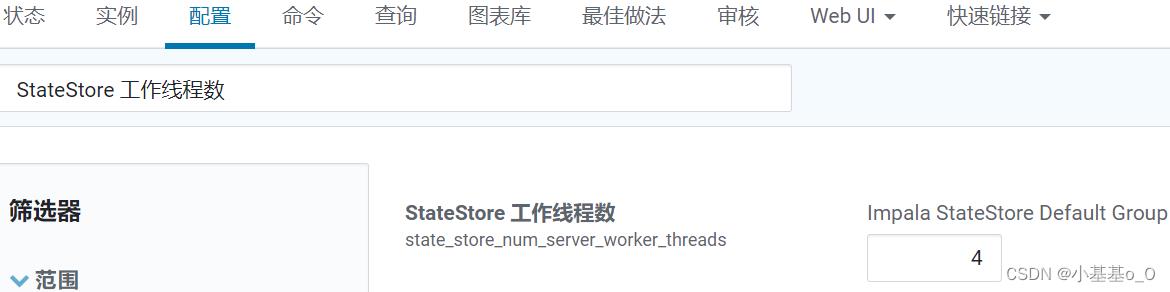
StateStore工作线程数
3、impala客户端
3.1、impala-shell
| 常用选项 | 说明 | 默认值 |
|---|---|---|
-h, --help | 显示帮助信息 | |
-i IMPALAD, --impalad=IMPALAD | impalad连接的<host:port> | 当前主机的主机名:21000 |
-f QUERY_FILE,--query_file=QUERY_FILE | 执行文件中的查询,多个查询用;分隔。If the argument to -f is “-”, then queries are read from stdin and terminated with ctrl-d. | none |
-o OUTPUT_FILE,--output_file=OUTPUT_FILE | 查询结果写入指定文件。Results from multiple semicolon-terminated queries will be appended to the same file | none |
--print_header | Print column names in delimited mode when pretty-printed. | False |
-V, --verbose | 输出详细信息 | True |
-p, --show_profiles | Always display query profiles after execution | False |
--quiet | 不输出详细信息 | False |
-v, --version | 打印版本信息 | False |
-c, --ignore_query_failure | 查询失败时继续 | False |
-d DEFAULT_DB--database=DEFAULT_DB | 在启动时发出use database命令 | none |
-u USER, --user=USER | 用户身份验证 | root |
例:用-q查询数据,用-o将结果写到文件
impala-shell -q 'select * from teacher' -o output.txt
例:刷新元数据
impala-shell -q 'invalidate metadata'
3.2、Hue
切换编辑器

4、命令
刷新单个表的元数据
refresh 表名
刷新所有元数据(表很多的情况下要谨慎使用)
invalidate metadata
不退出impala-shell执行shell命令
shell hadoop fs -ls /;
查询 最近一次的查询 的 底层信息
profile;
5、查询
建库
CREATE DATABASE sale;
USE sale;
建表
CREATE TABLE good(
order_number STRING COMMENT "订单号",
good STRING COMMENT "商品",
good_costs INT COMMENT "商品金额",
goods_costs INT COMMENT "商品总额",
transport_costs INT COMMENT "运费",
costs INT COMMENT "订单总额"
)COMMENT "商品分析";
插入
INSERT INTO TABLE good VALUES
('a1','牛奶',3000,9000,1000,10000),
('a1','坚果',3000,9000,1000,10000),
('a1','蛋糕',3000,9000,1000,10000),
('a2','酸奶',6000,18000,2000,20000),
('a2','坚果',6000,18000,2000,20000),
('a2','蛋糕',6000,18000,2000,20000);
查询
SELECT * FROM good;
5.1、时间函数
当前时间,返回timestamp类型
SELECT current_timestamp(),now();
今天,返回string类型
SELECT to_date(now());
昨天,返回string类型
SELECT to_date(date_sub(now(),1));
年月日,返回int类型
SELECT year(now()),month(now()),day(now());
当前时间,返回string类型
SELECT from_timestamp(now(),'yyyy-MM-dd HH:mm:ss');


6、与HIVE的区别
- Impala缺少某些函数,如:
str_to_map、explode、collect_set… - Impala支持窗口函数,但不支持
CLUSTER BY、DISTRIBUTE BY、SORT BY语法 - Impala中不支持分桶表
7、Appendix
本文版本

| 英 | 🔉 | 中 |
|---|---|---|
| impala | ɪmˈpɑːlə | n. 黑斑羚(产于非洲中南部) |
| MPP | Massively Parallel Processing | 大规模并行处理 |
| coordinator | koʊˈɔːrdɪneɪtər | n. 协调人,统筹者 |
| semicolon | ˈsemikoʊlən | 分号 |
| quiet | ˈkwaɪət | 安静的;朴素大方的 |
| invalidate | ɪnˈvælɪdeɪt | v. (对论点、声明或理论)驳斥;使作废 |
| profile | ˈproʊfaɪl | 轮廓;n. (人头部的)侧面;v. 概述;显出……侧面轮廓; |
❤️

以上是关于CDH之impala的主要内容,如果未能解决你的问题,请参考以下文章