DDD:如何领用领域驱动设计来避免写流水账代码
Posted Java Punk
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了DDD:如何领用领域驱动设计来避免写流水账代码相关的知识,希望对你有一定的参考价值。

过去一年里我们团队做了大量的老系统重构和迁移,其中有大量的代码属于流水账代码。通常能看到是开发在对外的API接口里直接写业务逻辑代码,或者在一个服务里大量的堆接口,导致业务逻辑实际无法收敛,接口复用性比较差。
所以这讲主要想系统性的解释一下如何通过DDD的重构,将原有的流水账代码改造为逻辑清晰、职责分明的模块。
一、案例分析
举一个简单的常见案例:下单链路。
假设我们在做一个checkout接口,需要做各种校验、查询商品信息、 调用库存服务扣库存、然后生成订单:
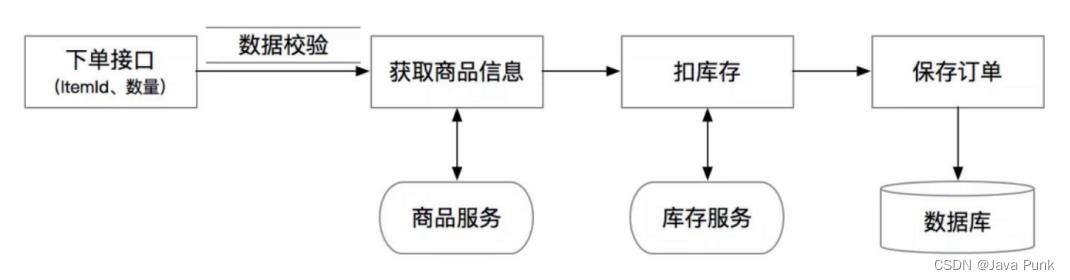
一个比较典型的代码,如下:
@RestController
@RequestMapping("/check")
public class CheckoutController
@Resource
private ItemService itemService;
@Resource
private InventoryService inventoryService;
@Resource
private OrderRepository orderRepository;
@PostMapping("checkout")
public Result<OrderDO> checkout(Long itemId, Integer quantity)
// 1) Session管理
Long userId = SessionUtils.getLoggedInUserId();
if (userId <= 0)
return Result.fail("Not Logged In");
// 2)参数校验
if (itemId <= 0 || quantity <= 0 || quantity >= 1000)
return Result.fail("Invalid Args");
// 3)外部数据补全
ItemDO item = itemService.getItem(itemId);
if (item == null)
return Result.fail("Item Not Found");
// 4)调用外部服务
boolean withholdSuccess = inventoryService.withhold(itemId, quantity);
if (!withholdSuccess)
return Result.fail("Inventory not enough");
// 5)领域计算
Long cost = item.getPriceInCents() * quantity;
// 6)领域对象操作
OrderDO order = new OrderDO();
order.setItemId(itemId);
order.setBuyerId(userId);
order.setSellerId(item.getSellerId());
order.setCount(quantity);
order.setTotalCost(cost);
// 7)数据持久化
orderRepository.createOrder(order);
// 8)返回
return Result.success(order);
这样的代码是不是非常熟悉呢?为什么这种典型的流水账代码在实际应用中会有问题?其本质问题是违背了SRP(Single Responsbility Principle)单一职责原则。
这段代码里混杂了业务计算、校验逻辑、基础设施、和通信协议等,在未来无论哪一部分的逻辑变更都会直接影响到这段代码,长期当后人不断的在上面叠加新的逻辑时,会造成代码复杂度增加、逻辑分支越来越多,最终造成bug或者没人敢重构的历史包袱。
所以我们才需要用DDD的分层思想去重构一下以上的代码,通过不同的代码分层和规范,拆分出逻辑清晰,职责明确的分层和模块,也便于一些通用能力的沉淀。
主要的几个步骤分为:
- 分离出独立的Interface接口层,负责处理网络协议相关的逻辑;
- 从真实业务场景中,找出具体用例(Use Cases),然后将具体用例通过专用的Command指令、Query查询、和Event事件对象来承接;
- 分离出独立的Application应用层,负责业务流程的编排,响应Command、Query和Event。每个应用层的方法应该代表整个业务流程中的一个节点;
- 处理一些跨层的横切关注点,如鉴权、异常处理、校验、缓存、日志等;
下面会针对每个点做详细的解释。
二、分层设计理念
2.1 Interface 接口层
随着REST和MVC架构的普及,经常能看到开发同学直接在Controller中写业务逻辑,如上面的典型案例,但实际上MVC Controller不是唯一的重灾区。以下的几种常见的代码写法通常都可能包含了同样的问题:
- HTTP 框架:如Spring MVC框架,Spring Cloud等
- RPC 框架:如Dubbo、HSF、gRPC等
- 消息队列MQ的“消费者”:比如JMS的 onMessage,RocketMQ的MessageListener等
- Socket通信:Socket通信的receive、WebSocket的onMessage等
- 文件系统:WatcherService等
- 分布式任务调度:SchedulerX等
这些的方法都有一个共同的点就是都有自己的网络协议,而如果我们的业务代码和网络协议混杂在一起,则会直接导致代码跟网络协议绑定,无法被复用。
所以,在DDD的分层架构中,我们单独会抽取出来Interface接口层,作为所有对外的门户,将网络协议和业务逻辑解耦。
2.1.1 接口层的组成
接口层主要由以下几个功能组成:
- 网络协议的转化:通常这个已经由各种框架给封装掉了,我们需要构建的类要么是被注解的bean,要么是继承了某个接口的bean;
- 统一鉴权:比如在一些需要AppKey+Secret的场景,需要针对某个租户做鉴权的,包括一些加密串的校验;
- Session管理:一般在面向用户的接口或者有登陆态的,通过Session或者RPC上下文可以拿到当前调用的用户,以便传递给下游服务;
- 限流配置:对接口做限流避免大流量打到下游服务;
- 前置缓存:针对变更不是很频繁的只读场景,可以前置结果缓存到接口层;
- 异常处理:通常在接口层要避免将异常直接暴露给调用端,所以需要在接口层做统一的异常捕获,转化为调用端可以理解的数据格式;
- 日志:在接口层打调用日志,用来做统计和debug等。一般微服务框架可能都直接包含了这些功能。
当然,如果有一个独立的网关设施/应用,则可以抽离出鉴权、Session、限流、日志等逻辑,但是目前来看API网关也只能解决一部分的功能,即使在有API网关的场景下,应用里独立的接口层还是有必要的。
在interface层,鉴权、Session、限流、缓存、日志等都比较直接,只有一个异常处理的点需要重点说下。
2.1.2 返回值和异常处理规范,Result vs Exception
注:这部分主要还是面向REST和RPC接口,其他的协议需要根据协议的规范产生返回值。
在我见过的一些代码里,接口的返回值比较多样化,有些直接返回DTO甚至DO,另一些返回Result。
接口层的核心价值是对外,所以如果只是返回DTO或DO会不可避免的面临异常和错误栈泄漏到使用方的情况,包括错误栈被序列化反序列化的消耗。所以,这里提出一个规范:
规范:Interface层的HTTP和RPC接口,返回值为Result,捕捉所有异常
规范:Application层的所有接口返回值为DTO,不负责处理异常
Application层的具体规范等下再讲,在这里先展示Interface层的逻辑。 举个例子:
@PostMapping("checkout")
public Result<OrderDTO> checkout(Long itemId, Integer quantity)
try
CheckoutCommand cmd = new CheckoutCommand();
OrderDTO orderDTO = checkoutService.checkout(cmd);
return Result.success(orderDTO);
catch (ConstraintViolationException cve)
// 捕捉一些特殊异常,比如Validation异常
return Result.fail(cve.getMessage());
catch (Exception e)
// 兜底异常捕获
return Result.fail(e.getMessage());
当然,每个接口都要写异常处理逻辑会比较烦,所以可以用AOP做个注解。
@Target(ElementType.METHOD)
@Retention(RetentionPolicy.RUNTIME)
public @interface ResultHandler
@Aspect
@Component
public class ResultAspect
@Around("@annotation(ResultHandler)")
public Object logExecutionTime(ProceedingJoinPoint joinPoint) throws Throwable
Object proceed = null;
try
proceed = joinPoint.proceed();
catch (ConstraintViolationException cve)
return Result.fail(cve.getMessage());
catch (Exception e)
return Result.fail(e.getMessage());
return proceed;
然后,代码最终则简化为:
@PostMapping("checkout")
@ResultHandler
public Result<OrderDTO> checkout(Long itemId, Integer quantity)
CheckoutCommand cmd = new CheckoutCommand();
OrderDTO orderDTO = checkoutService.checkout(cmd);
return Result.success(orderDTO);
2.2 Application层
2.2.1 Application层的组成部分
Application层的几个核心类:
- ApplicationService应用服务:最核心的类,负责业务流程的编排,但本身不负责任何业务逻辑
- DTO Assembler:负责将内部领域模型转化为可对外的DTO
- Command、Query、Event对象:作为ApplicationService的入参
- 返回的DTO:作为ApplicationService的出参
Application层最核心的对象是ApplicationService,它的核心功能是承接“业务流程“。但是在讲ApplicationService的规范之前,必须要先重点的讲几个特殊类型的对象,即Command、Query和Event。
2.2.2 Command、Query、Event对象
从本质上来看,这几种对象都是Value Object,但是从语义上来看有比较大的差异:
- Command指令:指调用方明确想让系统操作的指令,其预期是对一个系统有影响,也就是写操作。通常来讲指令需要有一个明确的返回值(如同步的操作结果,或异步的指令已经被接受)。
- Query查询:指调用方明确想查询的东西,包括查询参数、过滤、分页等条件,其预期是对一个系统的数据完全不影响的,也就是只读操作。
- Event事件:指一件已经发生过的既有事实,需要系统根据这个事实作出改变或者响应的,通常事件处理都会有一定的写操作。事件处理器不会有返回值。这里需要注意一下的是,Application层的Event概念和Domain层的DomainEvent是类似的概念,但不一定是同一回事,这里的Event更多是外部一种通知机制而已。
简单总结下:
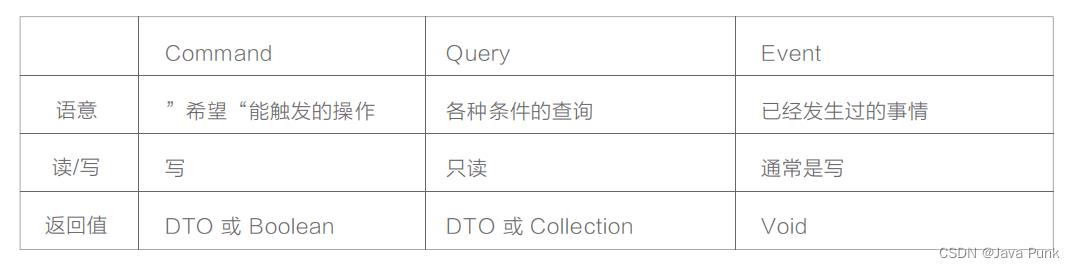
问题1:为什么要用CQE对象?
通常在很多代码里,能看到接口上有多个参数,比如上文中的案例:
Result<OrderDO> checkout(Long itemId, Integer quantity); 如果需要在接口上增加参数,考虑到向前兼容,则需要增加一个方法:
Result<OrderDO> checkout(Long itemId, Integer quantity);
Result<OrderDO> checkout(Long itemId, Integer quantity, Integer channel);或者常见的查询方法,由于条件的不同导致多个方法:
List<OrderDO> queryByItemId(Long itemId);
List<OrderDO> queryBySellerId(Long sellerId);
List<OrderDO> queryBySellerIdWithPage(Long sellerId, int currentPage, int pageSize);可以看出来,传统的接口写法有几个问题:
- 接口膨胀:一个查询条件一个方法;
- 难以扩展:每新增一个参数都有可能需要调用方升级;
- 难以测试:接口一多,职责随之变得繁杂,业务场景各异,测试用例难以维护。
但是另外一个最重要的问题是:这种类型的参数罗列,本身没有任何业务上的”语意“,只是一堆参数而已,无法明确的表达出来意图。
问题2:CQE vs DTO 的区别?
CQE规范:ApplicationService 的接口入参只能是一个Command、Query或Event对象,CQE对象需要能代表当前方法的语意。唯一可以的例外是根据单一ID查询的情况,可以省略掉一个Query对象的创建。
ApplicationService的入参是CQE对象,但是出参却是一个DTO,从代码格式上来看都是简单的POJO对象,那么他们之间有什么区别呢?
- CQE:CQE对象是ApplicationService的输入,是有明确的”意图“的,所以这个对象必须保证其”正确性“。
- DTO:DTO对象只是数据容器,只是为了和外部交互,所以本身不包含任何逻辑,只是贫血对象。
但可能最重要的一点:因为CQE是”意图“,所以CQE对象在理论上可以有”无限“个,每个代表不同的意图;但是DTO作为模型数据容器,和模型一一对应,所以是有限的。
问题3:CQE的校验
CQE作为ApplicationService的输入,必须保证其正确性,那么这个校验是放在哪里呢?
在最早的代码里,曾经有这样的校验逻辑,当时写在了服务里:
if (itemId <= 0 || quantity <= 0 || quantity >= 1000)
return Result.fail("Invalid Args");
这种代码在日常非常常见,但其最大的问题就是大量的非业务代码混杂在业务代码中,很明显的违背了单一职责原则。但因为当时入参仅仅是简单的int,所以这个逻辑只能出现在服务里。
现在当入参改为了CQE之后,我们可以利用java标准JSR303或JSR380的Bean Validation来前置这个校验逻辑。
规范:CQE对象的校验应该前置,避免在ApplicationService里做参数的校验。可以通过JSR303/380和 Spring Validation来实现
前面的例子可以改造为:
@Validated // Spring的注解
public class CheckoutServiceImpl implements CheckoutService
OrderDTO checkout(@Valid CheckoutCommand cmd) // 这里@Valid是JSR-303/380的注解
// 如果校验失败会抛异常,在interface层被捕捉
@Data
public class CheckoutCommand
@NotNull(message = "用户未登陆")
private Long userId;
@NotNull
@Positive(message = "需要是合法的itemId")
private Long itemId;
@NotNull
@Min(value = 1, message = "最少1件")
@Max(value = 1000, message = "最多不能超过1000件")
private Integer quantity;
规范:针对于不同语意的指令,要避免CQE对象的复用。
2.3 Anti-Corruption Layer 防腐层
在ApplicationService中,经常会依赖外部服务,从代码层面对外部系统产生了依赖。比如上文中的:
ItemDO item = itemService.getItem(cmd.getItemId());
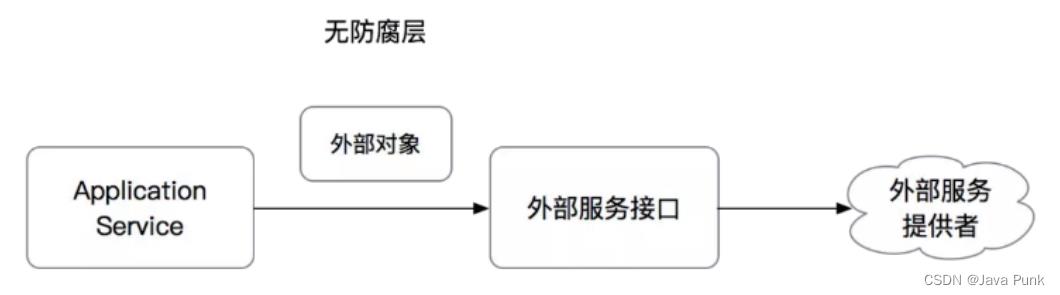
boolean withholdSuccess = inventoryService.withhold(cmd.getItemId(), cmd.getQuantity());会发现我们的ApplicationService会强依赖ItemService、InventoryService以及ItemDO这个对象。如果任何一个服务的方法变更,或者ItemDO字段变更,都会有可能影响到ApplicationService的代码。也就是说,我们自己的代码会因为强依赖了外部系统的变化而变更,这个在复杂系统中应该是尽量避免的。那么如何做到对外部系统的隔离呢?需要加入ACL防腐层。
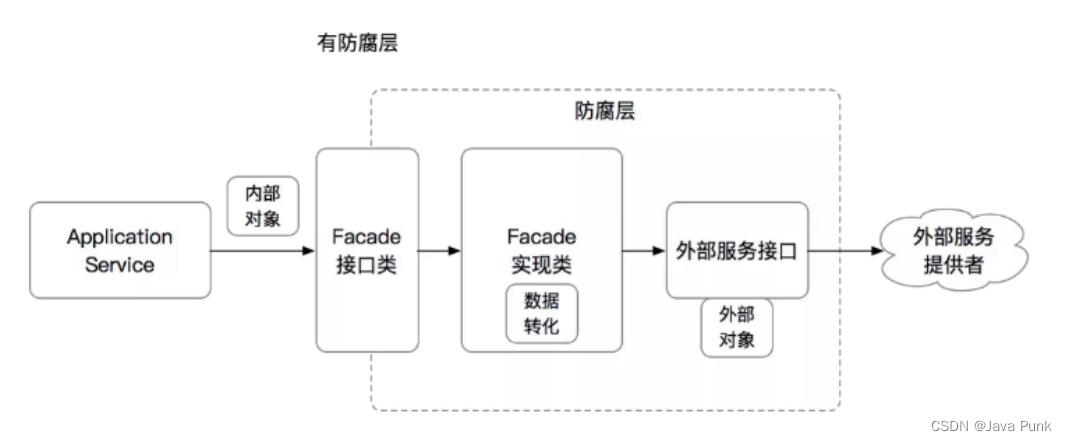
ACL防腐层的简单原理如下:
- 对于依赖的外部对象,我们抽取出所需要的字段,生成一个内部所需的VO或DTO类
- 构建一个新的Facade,在Facade中封装调用链路,将外部类转化为内部类
- 针对外部系统调用,同样的用Facade方法封装外部调用链路
无防腐层的情况:
有防腐层的情况:
具体简单实现,假设所有外部依赖都命名为ExternalXXXService:
// 自定义的内部值类
@Data
public class ItemDTO
private Long itemId;
private Long sellerId;
private String title;
private Long priceInCents;
// 商品Facade接口
public interface ItemFacade
ItemDTO getItem(Long itemId);
// 商品facade实现
@Service
public class ItemFacadeImpl implements ItemFacade
@Resource
private ExternalItemService externalItemService;
@Override
public ItemDTO getItem(Long itemId)
ItemDO itemDO = externalItemService.getItem(itemId);
if (itemDO != null)
ItemDTO dto = new ItemDTO();
dto.setItemId(itemDO.getItemId());
dto.setTitle(itemDO.getTitle());
dto.setPriceInCents(itemDO.getPriceInCents());
dto.setSellerId(itemDO.getSellerId());
return dto;
return null;
// 库存Facade
public interface InventoryFacade
boolean withhold(Long itemId, Integer quantity);
@Service
public class InventoryFacadeImpl implements InventoryFacade
@Resource
private ExternalInventoryService externalInventoryService;
@Override
public boolean withhold(Long itemId, Integer quantity)
return externalInventoryService.withhold(itemId, quantity);
通过ACL改造之后,我们ApplicationService的代码改为:
@Service
public class CheckoutServiceImpl implements CheckoutService
@Resource
private ItemFacade itemFacade;
@Resource
private InventoryFacade inventoryFacade;
@Override
public OrderDTO checkout(@Valid CheckoutCommand cmd)
ItemDTO item = itemFacade.getItem(cmd.getItemId());
if (item == null)
throw new IllegalArgumentException("Item not found");
boolean withholdSuccess = inventoryFacade.withhold(cmd.getItemId(), cmd.getQuantity());
if (!withholdSuccess)
throw new IllegalArgumentException("Inventory not enough");
// ...
很显然,这么做的好处是ApplicationService的代码已经完全不再直接依赖外部的类和方法,而是依赖了我们自己内部定义的值类和接口。如果未来外部服务有任何的变更,需要修改的是Facade类和数据转化逻辑,而不需要修改ApplicationService的逻辑。
Repository可以认为是一种特殊的ACL,屏蔽了具体数据操作的细节,即使底层数据库结构变更,数据库类型变更,或者加入其他的持久化方式,Repository的接口保持稳定,ApplicationService就能保持不变。
在一些理论框架里ACL Facade也被叫做Gateway,含义是一样的。
总结
只要是做业务的,一定会需要写业务流程和服务编排,但不代表这种代码一定质量差。通过DDD的分层架构里的Interface层和Application层的合理拆分,代码可以变得优雅、灵活,能更快的响应业务但同时又能更好的沉淀。 本文主要介绍了一些代码的设计规范,帮助大家掌握一定的技巧。
Interface层:
- 职责:主要负责承接网络协议的转化、Session管理等;
- 接口数量:避免所谓的统一API,不必人为限制接口类的数量,每个/每类业务对应一套接口即可,接口参数应该符合业务需求,避免大而全的入参;
- 接口出参:统一返回Result;
- 异常处理:应该捕捉所有异常,避免异常信息的泄漏。可以通过AOP统一处理,避免代码里有大量重复代码。
部分Interface层:
- 用ACL防腐层将外部依赖转化为内部代码,隔离外部的影响。
Application层:
- 入参:具像化Command、Query、Event对象作为ApplicationService的入参,唯一可以的例外是单ID查询的场景;
- CQE的语意化:CQE对象有语意,不同用例之间语意不同,即使参数一样也要避免复用;
- 入参校验:基础校验通过Bean Validation api解决。Spring Validation自带Validation的AOP,也可以自己写AOP;
- 出参:统一返回DTO,而不是Entity或DO;
- DTO转化:用DTO Assembler负责Entity/VO到DTO的转化;
- 异常处理:不统一捕捉异常,可以随意抛异常。
以上是关于DDD:如何领用领域驱动设计来避免写流水账代码的主要内容,如果未能解决你的问题,请参考以下文章