Python爬虫实战 不生产小说,只做网站的搬运工,太牛逼了~(附源码)
Posted 嗨!栗子同学
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python爬虫实战 不生产小说,只做网站的搬运工,太牛逼了~(附源码)相关的知识,希望对你有一定的参考价值。
前言

遇见你时,漫天星河皆为浮尘

不知从什么时候开始。小说开始掀起了一股浪潮,它让我们平日里的生活不在枯燥乏
味,很多我们做不到的事情在小说里都能轻易实现。
那么话不多说,下面我们就来具体看看它是如何实现的吧👇

正文
这里以一部小说为例,将每一章的内容爬取下来保存到本地。
👇是我们要爬的小说目录

爬取下来的数据:

分析网页拿数据
首先利用requests库的强大能力,向目标发起请求,拿到页面中的所有html数据。
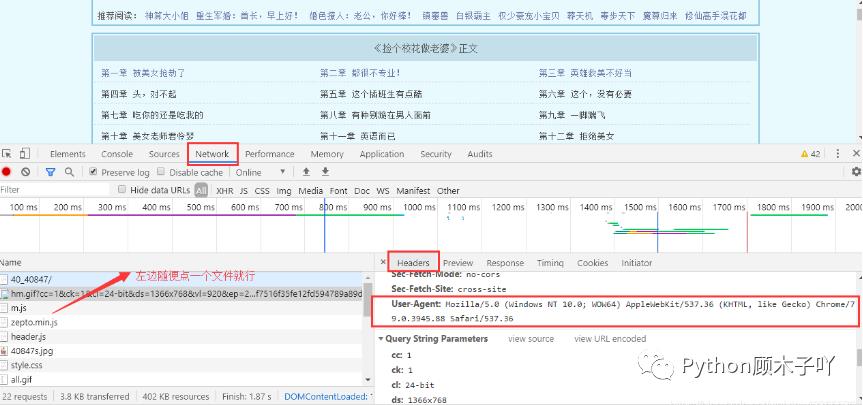
url(https://www.biduo.cc/biquge/40_40847/)需要注意的是:请求太多次很容易被反爬,最好在请求时带上请求头(模拟浏览器发请求),每个人
的浏览器的请求头都不同,不能直接使用我代码中的请求头,怎么获取自己的请求头可按如下图方
式拿到:
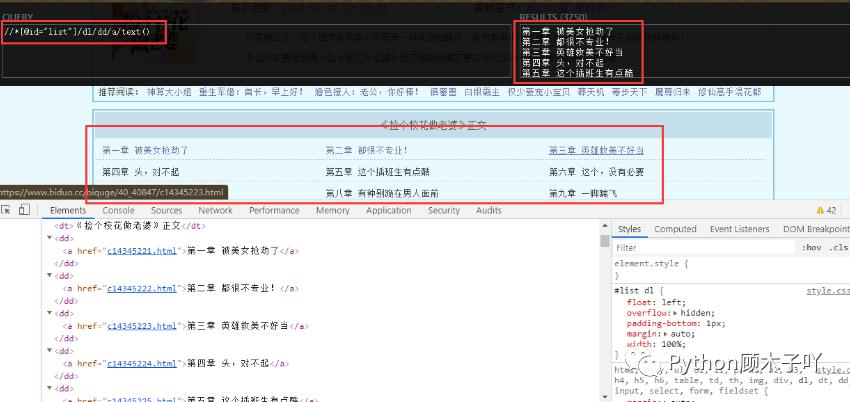
拿到所有HTML数据后,利用正则库结合xpath语法(可以自己去学一下XPath 教程)从中抽取章名和
每一章的链接,如下图 //*[@id=“list”]/dl/dd/a/text() 和 //*[@id=“list”]/dl/dd/a/@href 即可拿到我们需
要的章节名称和对应的链接地址:

现在已经拿到我们需要的章节名称和对应每一章的链接地址了,这里得到的每一章的链接地址还不
是一个完整的url地址,分析地址栏可知目标url(https://www.biduo.cc/biquge/40_40847/)与每一
章的链接地址拼接,即可得到我们最终所需的URL。
# 2. 请求文章拿到HTML数据,抽取文章内容并保存response = requests.get(url + src,headers=headers)
得到最终URL后,层层递进,相同的方法:向最终的URL地址发起请求得到小说内容页的所有
HTML数据,再从中抽取我们需要的小说文字内容,并保存到本地以我们抽取到的章名来命名文
件:
# 2. 请求文章拿到HTML数据,抽取文章内容并保存response = requests.get(url + src,headers=headers)html = etree.HTML(response.content.decode('gbk')) # 整理文档对象content = "\\n".join(html.xpath('//*[@id="content"]/text()'))file_name = tit + ".txt"print("正在保存文件:".format(file_name))with open(file_name, "a", encoding="utf-8") as f:f.write(content)

效果展示——
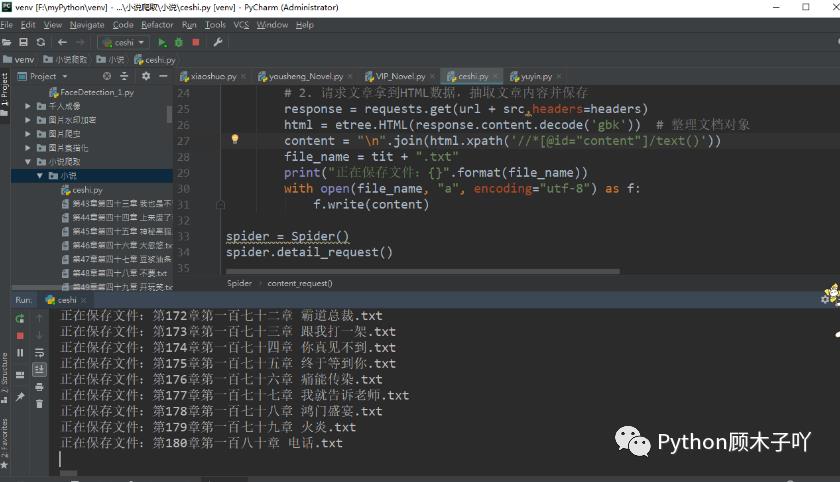
代码展示——
import requests
from lxml import etree
url = "https://www.biduo.cc/biquge/40_40847/"
headers =
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.88 Safari/537.36'
class Spider(object):
def detail_request(self):
# 1. 请求目录拿到HTML数据,抽取章名、章链接
response = requests.get(url,headers=headers)
# print(response.content.decode('gbk'))
html = etree.HTML(response.content.decode('gbk')) # 整理文档对象
# print(html)
tit_list = html.xpath('//*[@id="list"]/dl/dd/a/text()')
url_list = html.xpath('//*[@id="list"]/dl/dd/a/@href')
print(tit_list,url_list)
for tit, src in zip(tit_list, url_list):
self.content_request(tit, src)
def content_request(self, tit, src):
# 2. 请求文章拿到HTML数据,抽取文章内容并保存
response = requests.get(url + src,headers=headers)
html = etree.HTML(response.content.decode('gbk')) # 整理文档对象
content = "\\n".join(html.xpath('//*[@id="content"]/text()'))
file_name = tit + ".txt"
print("正在保存文件:".format(file_name))
with open(file_name, "a", encoding="utf-8") as f:
f.write(content)
spider = Spider()
spider.detail_request()总结
好啦!文章到这里就正式结束,比起听歌我还是更喜欢看小说的啦!
大家喜欢什么项目可以评论区留言哦~
有问题或者需要视频学习的可以找我沟通哈👇
✨完整的素材源码等:可以滴滴我吖!或者点击文末hao自取免费拿的哈~
😘往期推荐阅读——
项目0.1 【Python爬虫系列】Python爬虫入门并不难,甚至入门也很简单(引言)项目0.2
项目0.3 Python爬虫入门推荐案例:学会爬虫_表情包手到擒来~
项目0.4 【Tkinter界面化小程序】用Python做一款免费音乐下载器、无广告无弹窗、清爽超流畅哦
项目0.5 【Python爬虫系列】浅尝一下爬虫40例实战教程+源代码【基础+进阶】
项目0.6 【Python爬虫实战】使用Selenium爬某音乐歌曲及评论信息啦~
🎁文章汇总——
Python文章合集 | (入门到实战、游戏、Turtle、案例等)
(文章汇总还有更多你案例等你来学习啦~源码找我即可免费!)

以上是关于Python爬虫实战 不生产小说,只做网站的搬运工,太牛逼了~(附源码)的主要内容,如果未能解决你的问题,请参考以下文章