python编程获取续蜀山剑侠传:目录名称网址内容,保存到文件
Posted 紫郢剑侠
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python编程获取续蜀山剑侠传:目录名称网址内容,保存到文件相关的知识,希望对你有一定的参考价值。
昨天已经用Python编程完成了 从《续蜀山剑侠传》连载网站页面上获取目录信息,包括目录名称和网址,进而读取每个网址对应的网页中连载内容,详见:
 https://blog.csdn.net/Purpleendurer/article/details/125827266?spm=1001.2014.3001.5501
https://blog.csdn.net/Purpleendurer/article/details/125827266?spm=1001.2014.3001.5501今天我们要先统计出需要保存的网址数量,然后把每个网页国中的连载内容逐一保存到txt文件中,文件名就用目录名,然后调用记事本打开。为了避免枯燥,我们每保存1个txt就会更新并输出进度。
完整代码如下:
# -*- coding:UTF-8 -*-
import urllib.request, re, sys, os #, win32api
#--------------------------
def openUrl(url):
try:
page = urllib.request.urlopen(url, data=None, timeout=5)
except urllib.error.HTTPError as e:
print(e.code)
print(e.reason)
return ''
except urllib.error.URLError as e:
print(e.reason)
return ''
else:
html = page.read().decode('utf-8')
return html
#--------------------------
def getCon(html, tag):
i = html.find(tag)
if i == -1:
print ('没有找到' + tag)
return ''
else:
con = html[i+len(tag):]
#print ("前30个字符:" + con[:30])
tag = 'ul'
tag_pat = r'(?<=<'+ tag + '>).*?(?=</' + tag + '>)'
tag_ex = re.compile(tag_pat, re.M|re.S)
con = re.findall(tag_ex, con)
#con = html.split('正文')
#print (con[0])
return con[0]
#--------------------------
def showCon(url):
print (url)
html = openUrl(url)
if len(html) <= 0:
print ('……未能打开-_-!')
return
#print (html)
#html = html.replace('\\u3000', ' ')
html = html.replace('', '\\n')
#取回目
res = r'(.*?)'
t = re.findall(res, html, re.I|re.S|re.M)
print (t[0])
#获取内容
res = r'(.*?)'
c = re.findall(res, html, re.I|re.S|re.M)
#t = c[0].replace('\\u3000',' ')
#t = t.replace('','\\n')
print (c[0])
#--------------------------
def showFile (fileSpec):
with open(fileSpec, 'r', encoding='utf-8') as f:
print (f.read())
f.close()
#--------------------------
def saveCon (url, path):
#print (url)
html = openUrl(url)
if len(html) <= 0:
print ('……未能打开-_-!')
return
#print (html)
#html = html.replace('\\u3000', ' ')
html = html.replace('', '\\n')
#取回目
res = r'(.*?)'
t = re.findall(res, html, re.I|re.S|re.M)
#print (t[0])
#获取内容
res = r'(.*?)'
c = re.findall(res, html, re.I|re.S|re.M)
#t = c[0].replace('\\u3000',' ')
#t = t.replace('','\\n')
#print (c[0])
print ('至' + t[0] + '.txt')
saveFile (t[0], path, c[0])
fileSpec = path + '\\\\' + t[0] + '.txt'
showFile (fileSpec)
os.system('notepad ' + fileSpec)
#win32api.ShellExecute(0, 'open', fileSpec, '', '', 1)
#--------------------------
def printList(list, host):
#获取text
res = r'(.*?)'
t = re.findall(res, list, re.S|re.M)
#获取href
res_url = r"(?<=href=\\").+?(?=\\")|(?<=href=\\').+?(?=\\')"
h = re.findall(res_url, list, re.I|re.S|re.M)
for i in range(len(t)):
print (str(i+1) + '\\t' + t[i] + '\\t' + host + h[i])
#--------------------------
def getListHref(list, host):
#获取text
#res = r'(.*?)'
#t = re.findall(res, list, re.S|re.M)
#获取href
res_url = r"(?<=href=\\").+?(?=\\")|(?<=href=\\').+?(?=\\')"
h = re.findall(res_url, list, re.I|re.S|re.M)
return h
#--------------------------
def saveFile (fileName, path, txt):
#write_flag = True
# open(file, mode='r', buffering=-1, encoding=None, \\
# errors=None, newline=None, closefd=True, opener=None)
with open(path + '\\\\' + fileName + '.txt', 'a', encoding='utf-8') as f:
f.write(fileName + '\\n\\n')
f.writelines(txt)
f.close()
#--------------------------
def saveBook(url, host):
#for i in range(len(url)):
i = 0
href = host + url[i]
print ('保存第' + str(i+1) + '个页面' + href)
saveCon(href, 'e:\\\\book')
#--------------------------
def showList(list, host):
#获取text
res = r'(.*?)'
t = re.findall(res, list, re.S|re.M)
#获取href
res_url = r"(?<=href=\\").+?(?=\\")|(?<=href=\\').+?(?=\\')"
h = re.findall(res_url, list, re.I|re.S|re.M)
showCon(host + h[0])
#for i in range(len(t)):
# showCon (host + h[i])
#--------------------------
def main():
url = 'http://www.mengxi.net/book/263745/index.html'
i = url.index('/', 7)
host = url[0 : i]
#print ('分析' + url)
html = openUrl(url)
if len(html) > 0:
tag = '正文'
list = getCon(html, tag)
#printList(list, host)
#showList(list, host)
h = getListHref(list, host)
print('共有' + str(len(h)) + '个页面')
saveBook(h, host)
main()
代码运行结果如下:
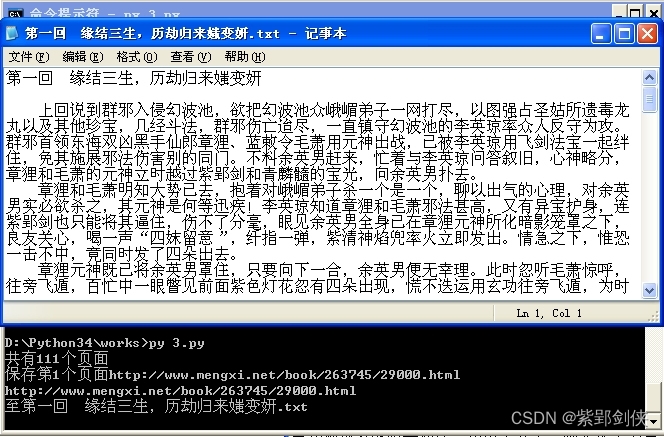
在Python中调用Windows的应用程序还是很方便的。
以上是关于python编程获取续蜀山剑侠传:目录名称网址内容,保存到文件的主要内容,如果未能解决你的问题,请参考以下文章