论文阅读|深读GAS:Role-Oriented Graph Auto-encoder Guided by Structural Information
Posted 海轰Pro
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文阅读|深读GAS:Role-Oriented Graph Auto-encoder Guided by Structural Information相关的知识,希望对你有一定的参考价值。
目录

前言
Hello!
非常感谢您阅读海轰的文章,倘若文中有错误的地方,欢迎您指出~
自我介绍 ଘ(੭ˊᵕˋ)੭
昵称:海轰
标签:程序猿|C++选手|学生
简介:因C语言结识编程,随后转入计算机专业,获得过国家奖学金,有幸在竞赛中拿过一些国奖、省奖…已保研。
学习经验:扎实基础 + 多做笔记 + 多敲代码 + 多思考 + 学好英语!
唯有努力💪
知其然 知其所以然!
本文仅记录自己感兴趣的内容
简介
原文链接:https://link.springer.com/chapter/10.1007/978-3-030-59416-9_28
会议:International Conference on Database Systems for Advanced Applications(DASFAA CCF B类)
年度:2020/09/22
Abstract
在复杂网络中,角色通常代表节点的局部连接模式,它反映了相应实体的功能或行为
角色发现对理解网络的形成与演化具有重要意义
随着角色发现在网络中的重要性逐渐被认识到,各种面向角色的网络表示学习方法被提出
现有的方法几乎都依赖于人工的高阶结构特性,而这些特性往往是零碎的
它们的性能不稳定,泛化能力较差,因为其手工结构特征有时会忽略不同网络的特征
此外,图神经网络(gnn)在自动捕获结构特性方面具有很大潜力,但由于面向角色无监督损失的设计困难,很难对其进行控制
为了克服这些挑战,我们提出了一个想法,利用低维提取的结构特征作为指导训练图神经网络
在此基础上,我们提出了一种新的基于结构信息的图数据自编码器GAS来学习面向角色的节点表示
大量的实验结果表明,该方法具有较好的性能。
1 Introduction
Graph or Network是不规则数据在众多应用领域的自然表示结构,包括社交网络[28]、蛋白质组学[31]等
具体来说,网络中的节点和边被用来表示现实世界的实体及其关系
这样,许多领域的不同问题就可以转化为相应的网络研究问题
在现实中对复杂系统进行建模时,网络中包含着许多有用的隐藏信息,值得我们仔细挖掘和分析
社区检测[11]和角色发现[21,24]就是在介观层面挖掘网络信息的两个研究领域
社区检测和角色发现是两种基于不同标准的图数据聚类问题
如图1所示,在形成内部连接多于外部连接的社区时,节点在局部连接模式中发挥着不同的作用
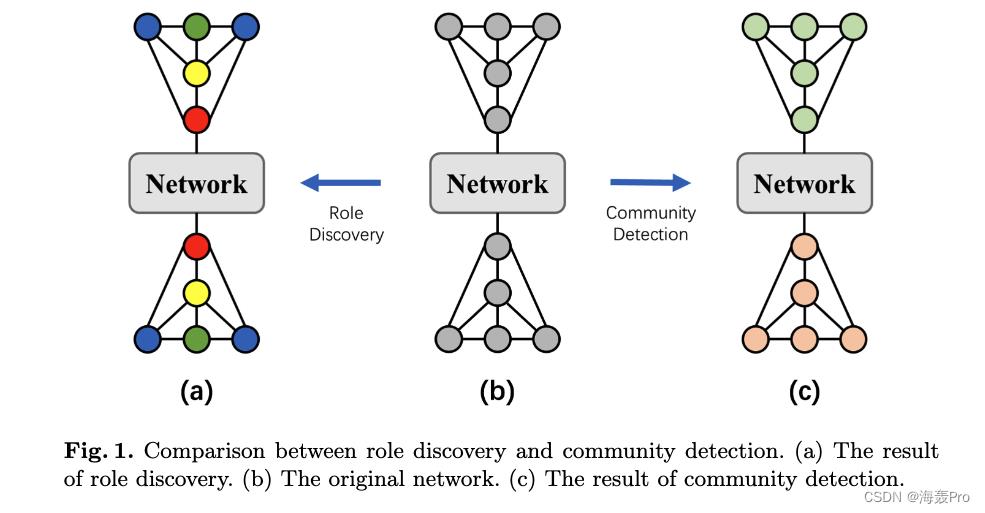
与之相对应的是,现实世界中的实体总是在群体中执行各种功能和行为,比如不同岗位的雇主和员工组成公司
- 研究社区可以帮助了解实体的共同利益和目标
- 而研究角色则有助于捕捉关系之间的区别
因此,社区和角色对于理解网络的形成和演化具有重要意义
然而,长期以来,社区发现得到了深入的研究,而角色发现近年来却受到越来越多的关注
本质上,角色发现是捕获节点结构属性的过程
因此,基于节点中心结构计算的经典度量,例如PageRank[18]和其他节点中心,可以被视为角色度量
但这些指标只能从特定角度表征角色,通常具有较高的计算复杂度,限制了其在大规模网络上复杂大规模分析和机器学习任务中的应用
幸运的是,网络嵌入(Network Embedding,又称网络表示学习)利用低维向量保存网络中原始节点信息
在大规模网络表示方面表现出了巨大的能力
与上述指标相比,学习到的嵌入是更通用的表示
这种嵌入方法在失去复杂的图结构、将大量信息保留在向量中的同时,可以轻松有效地用于大量的网络分析和机器学习任务
然而,现有的网络嵌入算法[5,19,25]大多基于节点的邻近性,即网络中节点越近,嵌入的相似性越高
换句话说,这些算法是面向社区的
随着角色重要性的逐渐认识,近年来提出了一些面向角色的网络嵌入方法
面向角色网络嵌入的目的是对以节点为中心的结构信息进行编码,将节点之间的结构相似性转化为嵌入空间中的几何关系
基于此目的,几乎所有面向角色的网络嵌入方法都分为两个步骤:
- (S1)获取节点的结构属性
- (S2)将结构性质和相似性映射到嵌入
大多数面向角色的嵌入方法利用高阶结构特征来捕获结构信息。例如,
- role2vec[1]和HONE[23]利用了称为motifs的小诱导子图
- 而RolX[8]、GLRD[3]和DMER[12]利用了递归特征聚合算法ReFeX[9]
- DRNE[27]使用层规范化的lstm来表示排序邻居上的节点
- 同时,随机漫步[1,20]、矩阵分解[7,8]和图神经网络[12,27]是常用的映射方法
显然,获得高质量的结构性能是学习面向角色嵌入的关键
然而,大多数面向角色的嵌入方法使用的提取结构属性的方法有许多限制
- 首先,这些提取方法是手工的,得到的信息比较零碎。虽然在不同的网络中,决定角色的特征是不同的,但提取的特征并不普遍适用
- 第二,一些无监督学习方法会使生成的嵌入过度拟合输入特征,而忽略图结构。手工结构特征虽然直观易懂,易于操作,但存在大量信息丢失的问题
- 第三,提取高阶结构特征,如图案,可能是相当耗时的
此外,图神经网络(GNNs)由于其在边上的传播机制,具有学习结构特性的天然能力
然而,设计面向角色的无监督损失是相当困难的。虽然已有一些研究尝试了输入特征重构、邻域递归聚集近似嵌入等不同方法
但由于过于依赖人工提取过程,仍存在上述局限性
面向角色的GNN模型只需要很少的指导就可以自动提取出高质量的结构信息
为了解决上述问题,我们提出了一种新的基于结构信息的图形自编码器GAS
- 在GAS中,我们使用图卷积层[14]来获取结构属性
- 我们将每个图卷积层中的对称归一化邻接矩阵替换为非归一化邻接矩阵,以更有力地区分局部结构
- 我们利用结构特征作为引导信息,而不是输入信息,这样我们的方法可以极大地缓解过度依赖手工特征带来的问题
- 此外,我们使用的特征是通过聚集一次邻居的主要特征,它们的维数很低。由于没有大量不必要的计算,我们的模型是非常高效的
综上所述,本文的贡献如下:
- 我们首次提出了利用结构特征作为指导信息训练面向角色的图神经网络的思想。
- 我们提出了一种新的基于结构信息的面向角色任务的图数据自编码器GAS。我们利用极低维度的特性来提高GAS的效率和有效性。
- 在多个真实数据集上的各种实验中,我们的嵌入方法比其他先进的嵌入方法表现得更好,我们的指导思想的正确性和方法的有效性得到了验证。
2 Related Work
图是不规则结构,现实世界的网络往往是大规模的、稀疏的
因此,直接利用图结构数据作为复杂、海量网络任务的输入非常困难
受词嵌入方法对稀疏分布的词产生低维密集表示的启发,提出了将节点编码到低维嵌入空间的网络嵌入方法
- DeepWalk[19]是第一个将经典语言模型SkipGram[17]引入网络表示学习的。它利用随机遍历生成由节点组成的序列作为Skip-Gram的输入。然后,SkipGram生成节点的表示
- Node2vec[5]在DeepWalk的基础上,通过添加两个超参数使随机漫步有偏差,以同时捕捉节点的同质性和结构特性。然而,由于相似的节点上下文,网络中接近的节点的嵌入仍然是相似的
- 为了适用于大规模网络,LINE[25]使用了保留节点直接链接(一阶邻近性)和共享邻居(二阶邻近性)的目标函数和优化目标的边缘采样算法
因此,这些方法都是为获取节点的邻近性而设计的,对于面向角色的任务不可行
近年来提出了一些面向角色的网络嵌入方法,ReFeX[9]提取本地和egonet特征,递归地聚合邻居的特征
ReFeX作为一种高效的高阶结构特征提取方法,在许多面向角色的嵌入方法中得到了广泛的应用。例如,
- RolX[8]利用ReFeX提取结构特征,并通过非负矩阵分解生成嵌入
- 随后,GLRD[3]扩展了RolX,在NMF公式中加入了稀疏性和多样性约束
- 同样,REGAL[7]中的xNetMF首先通过计算每个节点k-hop邻居的节点度来获得结构特征。然后利用奇异值分解将基于结构和属性计算的相似度编码到表示中
有几种基于随机游动的方法
- Role2vec[1]设计了一个基于特征的随机游走学习面向角色的嵌入。它将DeepWalk中的节点序列替换为基于主题的特征值序列,以便在表示中保留结构信息
- 与Role2vec直接利用随机游走的特性不同,Struc2vec[20]通过将基于程度的结构相似性转换为边的权值来构建完全图的层次结构。构建完成后,在多层网络上训练Skip-Gram。
图神经网络由于其在边缘上的传播机制,在获取局部连通性模式方面具有很大的潜力
然而,最广为人知的是,只有两种面向角色的嵌入方法利用了图神经网络
- DRNE[27]使用层归一化LSTMs[10]来处理输入的图形数据。本质上,它是一种捕获结构特性的半手工方法。DRNE还定义了一个递归聚合过程来学习节点的规则等价性
- DMER[12]是一种结合图卷积网络[14]和基于特征的自编码器的深度互编码模型,它试图减少对人工过程的依赖。应该指出的是,传播机制可能是一把双刃剑。大量的聚合过程可能会使连接节点的嵌入更加平滑,这对面向角色的嵌入是非常不利的。
- 另外,HONE[23]和GraphWave[2]使用不同的扩散方法来学习节点的局部连通性模式。
很明显,几乎所有以上面向角色的嵌入方法都可以归结为两个步骤:结构属性提取和映射
虽然提取属性的质量决定了学习表示的有效性,但这些方法由于它们的相互提取方法而面临许多问题。
3 Method
在本节中,我们将介绍我们提出的名为GAS的面向角色的网络嵌入框架的符号和细节
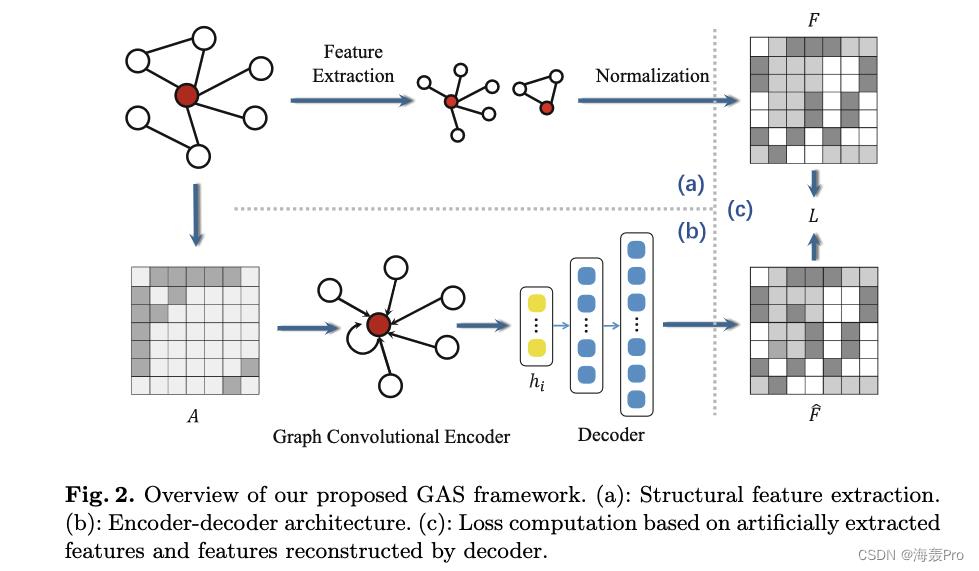
如图2所示,我们的框架大致分为三个部分
- ( a ) (a) (a)提取结构特征作为指导信息
- ( b ) (b) (b)使用图自编码器将节点编码为面向角色的嵌入,解码器将这些嵌入重构为特征
- ( c ) (c) (c)基于引导特征和重构特征计算损失,用于训练图形自编码器
3.1 Notations
给定一个无向无权网络 G = ( V , E ) G = (V, E) G=(V,E),其中
- V = v 1 , … , v n V = \\v_1,…, v_n\\ V=v1,…,vn为 n n n个节点的集合
- E ⊆ V × V E⊆V × V E⊆V×V为节点间边的集合。对于每个节点 v ∈ V v∈V v∈V
- 其邻域集合记为 N ( v ) = u ∣ ( v , u ) ∈ E N (v) = \\u|(v, u)∈E\\ N(v)=u∣(v,u)∈E
- A ∈ R n × n A∈R^n×n A∈Rn×n是 G G G的邻接矩阵。如果 v i v_i vi和 v j v_j vj在 G G G中链接, A i j = 1 A_ij= 1 Aij=1,否则 A i j = 0 A_ij = 0 Aij=0
ε ( v ) = ( V ε ( v ) , E ε ( v ) ) \\varepsilon(v) = (V_\\varepsilon(v), E_\\varepsilon(v)) ε(v)=(Vε(v),Eε(v))表示节点 v v v的egonet,其中
- V ε ( v ) = N ( v ) ∪ v V_\\varepsilon(v)= N (v)∪\\v\\ Vε(v)=N(v)∪v
- E ε ( v ) = ( u , u ′ ) ∣ ( u , u ′ ) ∈ E ∧ u , u ′ ∈ V ε ( v ) E_\\varepsilon(v)= \\(u, u')| (u, u') \\in E \\land u, u' \\in V_\\varepsilon(v)\\ Eε(v)=(u,u′)∣(u,u′)∈E∧u,u′∈Vε(v)
- T ( v ) = v , u , u ′ ∣ ( v , u ) , ( v , u ′ ) , ( u , u ′ ) ∈ E T (v) = \\\\v, u, u '\\|(v, u), (v, u '), (u, u ')∈E\\ T(v)=v,u,u′∣(v,u),(v,u′),(u,u′)∈E表示节点 v v v参与的三角形集合
- 度矩阵的符号为 D i i = ∑ j A i j D_ii =∑_j A_ij Dii=∑jAij
- F ∈ R n × m F∈R^n×m F∈Rn×m表示提取的结构特征矩阵,其中每一行 F i F_i Fi为节点 v i v_i vi的 m m m维特征向量

3.2 Feature Extraction
面向角色的网络表示学习是无监督的
当处理手工结构特征作为输入时,生成的嵌入将适合特征。这种对特性的依赖性太强了,使得嵌入方法不能普遍适用。
为了缓解这些问题,我们选择使用提取的特征作为指导信息来训练我们的面向角色的图自动编码器
我们借鉴了refex[9]的经验,它递归地聚合了邻居的简单本地和egonet特性。对于每个节点v,提取的local和egonet特征如下:
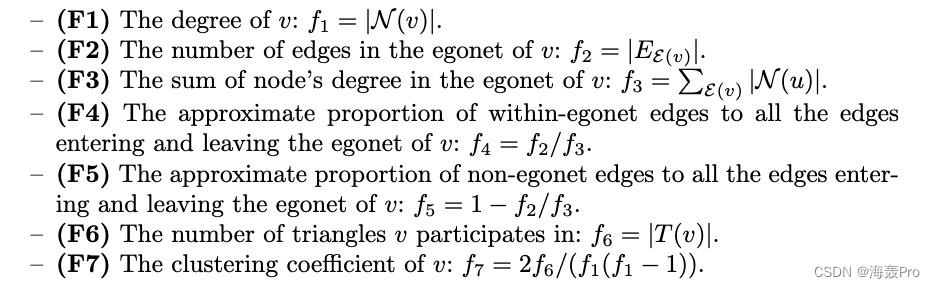
然后将上述每种特征归一化到范围(0,1)。
我们构造了主要结构特征矩阵 F ~ \\tilde F F~,其中每一行是一个归一化特征组成的7维向量
最后,通过计算每个egonet中节点特征的均值和和来聚合特征,如下所示:
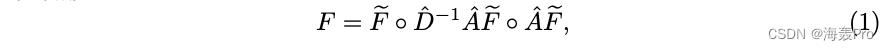
其中
- ◦ ◦ ◦是串联操作
- A ^ = A + I \\hat A = A + I A^=A+I是添加自环的图G的邻接矩阵,其中 I ∈ R n × n I∈R^n×n I∈Rn×n是单位矩阵
-
D
^
i
i
=
∑
j
A
^
i
j
\\hat D_ii =∑_j\\hat A_ij
D^ii=∑jA^ij
以上是关于论文阅读|深读GAS:Role-Oriented Graph Auto-encoder Guided by Structural Information的主要内容,如果未能解决你的问题,请参考以下文章