数据湖(十三):Spark与Iceberg整合DDL操作
Posted Lansonli
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据湖(十三):Spark与Iceberg整合DDL操作相关的知识,希望对你有一定的参考价值。

文章目录
二、CREATE TAEBL ... AS SELECT
1、创建表hadoop_prod.default.mytbl,并插入数据
2、使用“create table ... as select”语法创建表mytal2并查询
1、创建表“hadoop_prod.default.mytbl3”,并插入数据、展示
2、重建表“hadoop_prod.default.mytbl3”,并插入对应数据
Spark与Iceberg整合DDL操作
这里使用Hadoop Catalog 来演示Spark 与Iceberg的DDL操作。
一、CREATE TABLE 创建表
Create table 创建Iceberg表,创建表不仅可以创建普通表还可以创建分区表,再向分区表中插入一批数据时,必须对数据中分区列进行排序,否则会出现文件关闭错误,代码如下:
val spark: SparkSession = SparkSession.builder().master("local").appName("SparkOperateIceberg")
//指定hadoop catalog,catalog名称为hadoop_prod
.config("spark.sql.catalog.hadoop_prod", "org.apache.iceberg.spark.SparkCatalog")
.config("spark.sql.catalog.hadoop_prod.type", "hadoop")
.config("spark.sql.catalog.hadoop_prod.warehouse", "hdfs://mycluster/sparkoperateiceberg")
.getOrCreate()
//创建普通表
spark.sql(
"""
| create table if not exists hadoop_prod.default.normal_tbl(id int,name string,age int) using iceberg
""".stripMargin)
//创建分区表,以 loc 列为分区字段
spark.sql(
"""
|create table if not exists hadoop_prod.default.partition_tbl(id int,name string,age int,loc string) using iceberg partitioned by (loc)
""".stripMargin)
//向分区表中插入数据时,必须对分区列排序,否则报错:java.lang.IllegalStateException: Already closed files for partition:xxx
spark.sql(
"""
|insert into table hadoop_prod.default.partition_tbl values (1,"zs",18,"beijing"),(3,"ww",20,"beijing"),(2,"ls",19,"shanghai"),(4,"ml",21,"shagnhai")
""".stripMargin)
spark.sql("select * from hadoop_prod.default.partition_tbl").show()查询结果如下:

创建Iceberg分区时,还可以通过一些转换表达式对timestamp列来进行转换,创建隐藏分区,常用的转换表达式有如下几种:
- years(ts):按照年分区
//创建分区表 partition_tbl1 ,指定分区为year
spark.sql(
"""
|create table if not exists hadoop_prod.default.partition_tbl1(id int ,name string,age int,regist_ts timestamp) using iceberg
|partitioned by (years(regist_ts))
""".stripMargin)
//向表中插入数据,注意,插入的数据需要提前排序,必须排序,只要是相同日期数据写在一起就可以
//(1,'zs',18,1608469830) --"2020-12-20 21:10:30"
//(2,'ls',19,1634559630) --"2021-10-18 20:20:30"
//(3,'ww',20,1603096230) --"2020-10-19 16:30:30"
//(4,'ml',21,1639920630) --"2021-12-19 21:30:30"
//(5,'tq',22,1608279630) --"2020-12-18 16:20:30"
//(6,'gb',23,1576843830) --"2019-12-20 20:10:30"
spark.sql(
"""
|insert into hadoop_prod.default.partition_tbl1 values
|(1,'zs',18,cast(1608469830 as timestamp)),
|(3,'ww',20,cast(1603096230 as timestamp)),
|(5,'tq',22,cast(1608279630 as timestamp)),
|(2,'ls',19,cast(1634559630 as timestamp)),
|(4,'ml',21,cast(1639920630 as timestamp)),
|(6,'gb',23,cast(1576843830 as timestamp))
""".stripMargin)
//查询结果
spark.sql(
"""
|select * from hadoop_prod.default.partition_tbl1
""".stripMargin).show()数据结果如下:

在HDFS中是按照年进行分区:

- months(ts):按照“年-月”月级别分区
//创建分区表 partition_tbl2 ,指定分区为months,会按照“年-月”分区
spark.sql(
"""
|create table if not exists hadoop_prod.default.partition_tbl2(id int ,name string,age int,regist_ts timestamp) using iceberg
|partitioned by (months(regist_ts))
""".stripMargin)
//向表中插入数据,注意,插入的数据需要提前排序,必须排序,只要是相同日期数据写在一起就可以
//(1,'zs',18,1608469830) --"2020-12-20 21:10:30"
//(2,'ls',19,1634559630) --"2021-10-18 20:20:30"
//(3,'ww',20,1603096230) --"2020-10-19 16:30:30"
//(4,'ml',21,1639920630) --"2021-12-19 21:30:30"
//(5,'tq',22,1608279630) --"2020-12-18 16:20:30"
//(6,'gb',23,1576843830) --"2019-12-20 20:10:30"
spark.sql(
"""
|insert into hadoop_prod.default.partition_tbl2 values
|(1,'zs',18,cast(1608469830 as timestamp)),
|(5,'tq',22,cast(1608279630 as timestamp)),
|(2,'ls',19,cast(1634559630 as timestamp)),
|(3,'ww',20,cast(1603096230 as timestamp)),
|(4,'ml',21,cast(1639920630 as timestamp)),
|(6,'gb',23,cast(1576843830 as timestamp))
""".stripMargin)
//查询结果
spark.sql(
"""
|select * from hadoop_prod.default.partition_tbl2
""".stripMargin).show()数据结果如下:

在HDFS中是按照“年-月”进行分区:
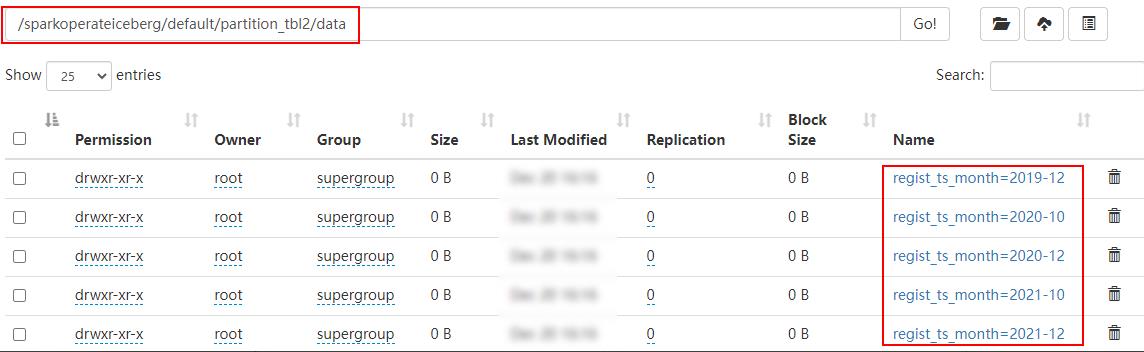
- days(ts)或者date(ts):按照“年-月-日”天级别分区
//创建分区表 partition_tbl3 ,指定分区为 days,会按照“年-月-日”分区
spark.sql(
"""
|create table if not exists hadoop_prod.default.partition_tbl3(id int ,name string,age int,regist_ts timestamp) using iceberg
|partitioned by (days(regist_ts))
""".stripMargin)
//向表中插入数据,注意,插入的数据需要提前排序,必须排序,只要是相同日期数据写在一起就可以
//(1,'zs',18,1608469830) --"2020-12-20 21:10:30"
//(2,'ls',19,1634559630) --"2021-10-18 20:20:30"
//(3,'ww',20,1603096230) --"2020-10-19 16:30:30"
//(4,'ml',21,1639920630) --"2021-12-19 21:30:30"
//(5,'tq',22,1608279630) --"2020-12-18 16:20:30"
//(6,'gb',23,1576843830) --"2019-12-20 20:10:30"
spark.sql(
"""
|insert into hadoop_prod.default.partition_tbl3 values
|(1,'zs',18,cast(1608469830 as timestamp)),
|(5,'tq',22,cast(1608279630 as timestamp)),
|(2,'ls',19,cast(1634559630 as timestamp)),
|(3,'ww',20,cast(1603096230 as timestamp)),
|(4,'ml',21,cast(1639920630 as timestamp)),
|(6,'gb',23,cast(1576843830 as timestamp))
""".stripMargin)
//查询结果
spark.sql(
"""
|select * from hadoop_prod.default.partition_tbl3
""".stripMargin).show()数据结果如下:

在HDFS中是按照“年-月-日”进行分区:

- hours(ts)或者date_hour(ts):按照“年-月-日-时”小时级别分区
//创建分区表 partition_tbl4 ,指定分区为 hours,会按照“年-月-日-时”分区
spark.sql(
"""
|create table if not exists hadoop_prod.default.partition_tbl4(id int ,name string,age int,regist_ts timestamp) using iceberg
|partitioned by (hours(regist_ts))
""".stripMargin)
//向表中插入数据,注意,插入的数据需要提前排序,必须排序,只要是相同日期数据写在一起就可以
//(1,'zs',18,1608469830) --"2020-12-20 21:10:30"
//(2,'ls',19,1634559630) --"2021-10-18 20:20:30"
//(3,'ww',20,1603096230) --"2020-10-19 16:30:30"
//(4,'ml',21,1639920630) --"2021-12-19 21:30:30"
//(5,'tq',22,1608279630) --"2020-12-18 16:20:30"
//(6,'gb',23,1576843830) --"2019-12-20 20:10:30"
spark.sql(
"""
|insert into hadoop_prod.default.partition_tbl4 values
|(1,'zs',18,cast(1608469830 as timestamp)),
|(5,'tq',22,cast(1608279630 as timestamp)),
|(2,'ls',19,cast(1634559630 as timestamp)),
|(3,'ww',20,cast(1603096230 as timestamp)),
|(4,'ml',21,cast(1639920630 as timestamp)),
|(6,'gb',23,cast(1576843830 as timestamp))
""".stripMargin)
//查询结果
spark.sql(
"""
|select * from hadoop_prod.default.partition_tbl4
""".stripMargin).show()数据结果如下:
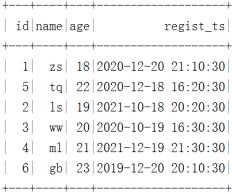
在HDFS中是按照“年-月-日-时”进行分区:
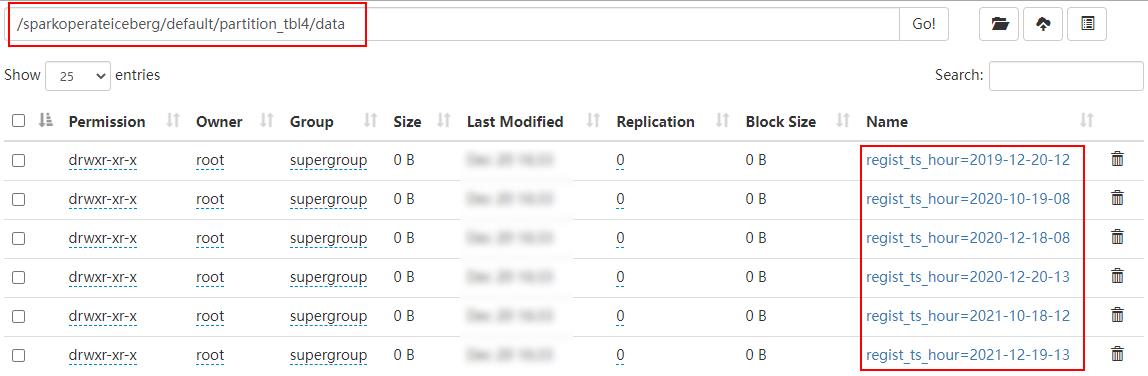
Iceberg支持的时间分区目前和将来只支持UTC,UTC是国际时,UTC+8就是国际时加八小时,是东八区时间,也就是北京时间,所以我们看到上面分区时间与数据时间不一致。
除了以上常用的时间隐藏分区外,Iceberg还支持bucket(N,col)分区,这种分区方式可以按照某列的hash值与N取余决定数据去往的分区。truncate(L,col),这种隐藏分区可以将字符串列截取L长度,相同的数据会被分到相同分区中。
二、CREATE TAEBL ... AS SELECT
Iceberg支持“create table .... as select ”语法,可以从查询语句中创建一张表,并插入对应的数据,操作如下:
1、创建表hadoop_prod.default.mytbl,并插入数据
val spark: SparkSession = SparkSession.builder().master("local").appName("SparkOperateIceberg")
//指定hadoop catalog,catalog名称为hadoop_prod
.config("spark.sql.catalog.hadoop_prod", "org.apache.iceberg.spark.SparkCatalog")
.config("spark.sql.catalog.hadoop_prod.type", "hadoop")
.config("spark.sql.catalog.hadoop_prod.warehouse", "hdfs://mycluster/sparkoperateiceberg")
.getOrCreate()
//创建普通表
spark.sql(
"""
| create table hadoop_prod.default.mytbl(id int,name string,age int) using iceberg
""".stripMargin)
//向表中插入数据
spark.sql(
"""
|insert into table hadoop_prod.default.mytbl values (1,"zs",18),(3,"ww",20),(2,"ls",19),(4,"ml",21)
""".stripMargin)
//查询数据
spark.sql("select * from hadoop_prod.default.mytbl").show()2、使用“create table ... as select”语法创建表mytal2并查询
spark.sql(
"""
|create table hadoop_prod.default.mytbl2 using iceberg as select id,name,age from hadoop_prod.default.mytbl
""".stripMargin)
spark.sql(
"""
|select * from hadoop_prod.default.mytbl2
""".stripMargin).show()结果如下:

三、REPLACE TABLE ... AS SELECT
Iceberg支持“replace table .... as select ”语法,可以从查询语句中重建一张表,并插入对应的数据,操作如下:
1、创建表“hadoop_prod.default.mytbl3”,并插入数据、展示
spark.sql(
"""
|create table hadoop_prod.default.mytbl3 (id int,name string,loc string,score int) using iceberg
""".stripMargin)
spark.sql(
"""
|insert into table hadoop_prod.default.mytbl3 values (1,"zs","beijing",100),(2,"ls","shanghai",200)
""".stripMargin)
spark.sql(
"""
|select * from hadoop_prod.default.mytbl3
""".stripMargin).show 
2、重建表“hadoop_prod.default.mytbl3”,并插入对应数据
spark.sql(
"""
|replace table hadoop_prod.default.mytbl2 using iceberg as select * from hadoop_prod.default.mytbl3
""".stripMargin)
spark.sql(
"""
|select * from hadoop_prod.default.mytbl2
""".stripMargin).show()
四、DROP TABLE
删除iceberg表时直接执行:“drop table xxx”语句即可,删除表时,表数据会被删除,但是库目录存在。
//删除表
spark.sql(
"""
|drop table hadoop_prod.default.mytbl
""".stripMargin) 
五、ALTER TABLE
Iceberg的alter操作在Spark3.x版本中支持,alter一般包含以下操作:
- 添加、删除列
添加列操作:ALTER TABLE ... ADD COLUMN
删除列操作:ALTER TABLE ... DROP COLUMN
//1.创建表test,并插入数据、查询
spark.sql(
"""
|create table hadoop_prod.default.test(id int,name string,age int) using iceberg
""".stripMargin)
spark.sql(
"""
|insert into table hadoop_prod.default.test values (1,"zs",18),(2,"ls",19),(3,"ww",20)
""".stripMargin)
spark.sql(
"""
| select * from hadoop_prod.default.test
""".stripMargin).show()
//2.添加字段,给 test表增加 gender 列、loc列
spark.sql(
"""
|alter table hadoop_prod.default.test add column gender string,loc string
""".stripMargin)
//3.删除字段,给test 表删除age 列
spark.sql(
"""
|alter table hadoop_prod.default.test drop column age
""".stripMargin)
//4.查看表test数据
spark.sql(
"""
|select * from hadoop_prod.default.test
""".stripMargin).show()最终表展示的列少了age列,多了gender、loc列:
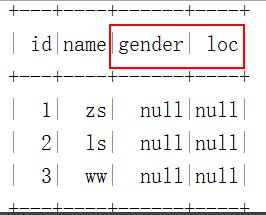
- 重命名列
重命名列语法:ALTER TABLE ... RENAME COLUMN,操作如下:
//5.重命名列
spark.sql(
"""
|alter table hadoop_prod.default.test rename column gender to xxx
|
""".stripMargin)
spark.sql(
"""
|select * from hadoop_prod.default.test
""".stripMargin).show()最终表展示的列 gender列变成了xxx列:

六、ALTER TABLE 分区操作
alter 分区操作包括增加分区和删除分区操作,这种分区操作在Spark3.x之后被支持,spark2.4版本不支持,并且使用时,必须在spark配置中加入spark.sql.extensions属性,其值为:org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions,在添加分区时还支持分区转换,语法如下:
- 添加分区语法:ALTER TABLE ... ADD PARTITION FIELD
- 删除分区语法:ALTER TABLE ... DROP PARTITION FIELD
具体操作如下:
1、创建表mytbl,并插入数据
val spark: SparkSession = SparkSession.builder().master("local").appName("SparkOperateIceberg")
//指定hadoop catalog,catalog名称为hadoop_prod
.config("spark.sql.catalog.hadoop_prod", "org.apache.iceberg.spark.SparkCatalog")
.config("spark.sql.catalog.hadoop_prod.type", "hadoop")
.config("spark.sql.catalog.hadoop_prod.warehouse", "hdfs://mycluster/sparkoperateiceberg")
.config("spark.sql.extensions","org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions")
.getOrCreate()
//1.创建普通表
spark.sql(
"""
| create table hadoop_prod.default.mytbl(id int,name string,loc string,ts timestamp) using iceberg
""".stripMargin)
//2.向表中插入数据,并查询
spark.sql(
"""
|insert into hadoop_prod.default.mytbl values
|(1,'zs',"beijing",cast(1608469830 as timestamp)),
|(3,'ww',"shanghai",cast(1603096230 as timestamp))
""".stripMargin)
spark.sql("select * from hadoop_prod.default.mytbl").show()在HDFS中数据存储和结果如下:


2、将表loc列添加为分区列,并插入数据,查询
//3.将 loc 列添加成分区,必须添加 config("spark.sql.extensions", "org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions") 配置
spark.sql(
"""
|alter table hadoop_prod.default.mytbl add partition field loc
""".stripMargin)
//4.向表 mytbl中继续插入数据,之前数据没有分区,之后数据有分区
spark.sql(
"""
|insert into hadoop_prod.default.mytbl values
|(5,'tq',"hangzhou",cast(1608279630 as timestamp)),
|(2,'ls',"shandong",cast(1634559630 as timestamp))
""".stripMargin )
spark.sql("select * from hadoop_prod.default.mytbl").show()在HDFS中数据存储和结果如下:


注意:添加分区字段是元数据操作,不会改变现有的表数据,新数据将使用新分区写入数据,现有数据将继续保留在原有的布局中。
3、将ts列进行转换作为分区列,插入数据并查询
//5.将 ts 列通过分区转换添加为分区列
spark.sql(
"""
|alter table hadoop_prod.default.mytbl add partition field years(ts)
""".stripMargin)
//6.向表 mytbl中继续插入数据,之前数据没有分区,之后数据有分区
spark.sql(
"""
|insert into hadoop_prod.default.mytbl values
|(4,'ml',"beijing",cast(1639920630 as timestamp)),
|(6,'gb',"tianjin",cast(1576843830 as timestamp))
""".stripMargin )
spark.sql("select * from hadoop_prod.default.mytbl").show()在HDFS中数据存储和结果如下:


4、删除分区loc
//7.删除表 mytbl 中的loc分区
spark.sql(
"""
|alter table hadoop_prod.default.mytbl drop partition field loc
""".stripMargin)
//8.继续向表 mytbl 中插入数据,并查询
spark.sql(
"""
|insert into hadoop_prod.default.mytbl values
|(4,'ml',"beijing",cast(1639920630 as timestamp)),
|(6,'gb',"tianjin",cast(1576843830 as timestamp))
""".stripMargin )
spark.sql("select * from hadoop_prod.default.mytbl").show()在HDFS中数据存储和结果如下:

注意:由于表中还有ts分区转换之后对应的分区,所以继续插入的数据loc分区为null

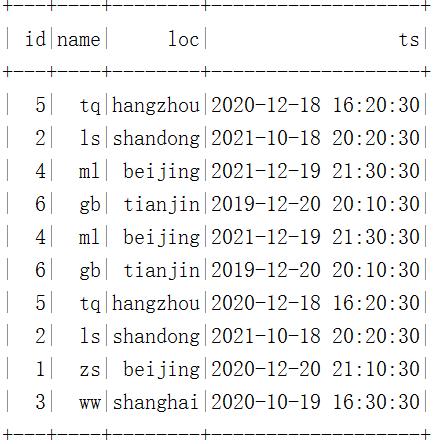
5、删除分区years(ts)
//9.删除表 mytbl 中的years(ts) 分区
spark.sql(
"""
|alter table hadoop_prod.default.mytbl drop partition field years(ts)
""".stripMargin)
//10.继续向表 mytbl 中插入数据,并查询
spark.sql(
"""
|insert into hadoop_prod.default.mytbl values
|(5,'tq',"hangzhou",cast(1608279630 as timestamp)),
|(2,'ls',"shandong",cast(1634559630 as timestamp))
""".stripMargin )
spark.sql("select * from hadoop_prod.default.mytbl").show()在HDFS中数据存储和结果如下:

- 📢博客主页:https://lansonli.blog.csdn.net
- 📢欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指正!
- 📢本文由 Lansonli 原创,首发于 CSDN博客🙉
- 📢停下休息的时候不要忘了别人还在奔跑,希望大家抓紧时间学习,全力奔赴更美好的生活✨
 高性能云服务器
高性能云服务器
 精品线路独享带宽,毫秒延迟,年中盛惠 1 折起
精品线路独享带宽,毫秒延迟,年中盛惠 1 折起
以上是关于数据湖(十三):Spark与Iceberg整合DDL操作的主要内容,如果未能解决你的问题,请参考以下文章