一文掌握数仓中auto analyze的使用
Posted 华为云开发者联盟
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了一文掌握数仓中auto analyze的使用相关的知识,希望对你有一定的参考价值。
摘要:analyze执行的是否及时,在一定程度上直接决定了SQL执行的快慢。
本文分享自华为云社区《一文读懂autoanalyze使用【这次高斯不是数学家】》,作者: leapdb。
analyze执行的是否及时,在一定程度上直接决定了SQL执行的快慢。因此,GaussDB(DWS)引入了自动统计信息收集,可以做到让用户不再担心统计信息是否过期。
1. 自动收集场景
需要进行自动统计信息收集的场景通常有五个:批量DML结束时,增量DML结束时,DDL结束时,查询开始时和后台定时任务。
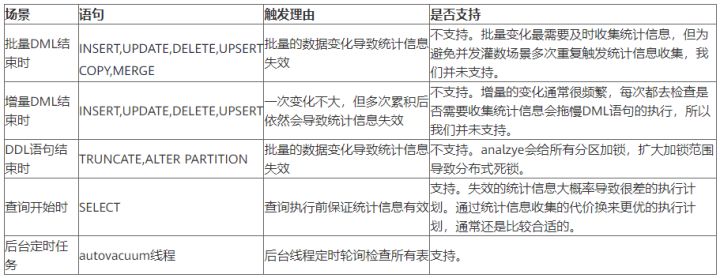
所以,为了避免对DML,DDL带来不必要的性能开销和死锁风险,我们选择了在查询开始前触发analzye。
2. 自动收集原理
GaussDB(DWS)在SQL执行过程中,会记录表增删改查相关的运行时统计信息,并在事务提交或回滚后记录到共享的内存种。
这些信息可以通过 “pg_stat_all_tables视图” 查询,也可以通过下面函数进行查询。
pg_stat_get_tuples_inserted --表累积insert条数
pg_stat_get_tuples_updated --表累积update条数
pg_stat_get_tuples_deleted --表累积delete条数
pg_stat_get_tuples_changed --表自上次analyze以来,修改的条数
pg_stat_get_last_analyze_time --查询最近一次analyze时间因此,根据共享内存中 "表自上次analyze以来修改过的条数" 是否超过一定阈值,就可以判定是否需要做analyze了。
3. 自动收集阈值
3.1 全局阈值
autovacuum_analyze_threshold #表触发analyze的最小修改量
autovacuum_analyze_scale_factor #表触发analyze时的修改百分比当"表自上次analyze以来修改的条数" >= autovacuum_analyze_threshold + 表估算大小 * autovacuum_analyze_scale_factor时,需要自动触发analyze。
3.2 表级阈值
--设置表级阈值
ALTER TABLE item SET (autovacuum_analyze_threshold=50);
ALTER TABLE item SET (autovacuum_analyze_scale_factor=0.1);
--查询阈值
postgres=# select pg_options_to_table(reloptions) from pg_class where relname='item';
pg_options_to_table
---------------------------------------
(autovacuum_analyze_threshold,50)
(autovacuum_analyze_scale_factor,0.1)
(2 rows)
--重置阈值
ALTER TABLE item RESET (autovacuum_analyze_threshold);
ALTER TABLE item RESET (autovacuum_analyze_scale_factor);不同表的数据特征不一样,需要触发analyze的阈值可能有不同的需求。表级阈值优先级高于全局阈值。
3.3 查看表的修改量是否超过了阈值(仅当前CN)
postgres=# select pg_stat_get_local_analyze_status('t_analyze'::regclass);
pg_stat_get_local_analyze_status
----------------------------------
Analyze not needed
(1 row)4. 自动收集方式
GaussDB(DWS)提供了三种场景下表的自动分析。
- 当查询中存在“统计信息完全缺失”或“修改量达到analyze阈值”的表,且执行计划不采取FQS (Fast Query Shipping)执行时,则通过autoanalyze控制此场景下表统计信息的自动收集。此时,查询语句会等待统计信息收集成功后,生成更优的执行计划,再执行原查询语句。
- 当autovacuum设置为on时,系统会定时启动autovacuum线程,对“修改量达到analyze阈值”的表在后台自动进行统计信息收集。
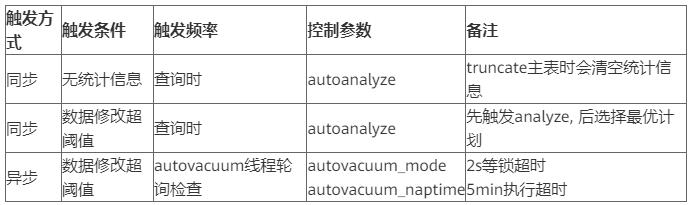
5.冻结统计信息
5.1 冻结表的distinct值
当一个表的distinct总是估算不准,例如:数据扎堆儿重复场景。如果表的distinct值固定,可以通过以下方式冻结表的distinct值。
postgres=# alter table lineitem alter l_orderkey set (n_distinct=0.9);
ALTER TABLE
postgres=# select relname,attname,attoptions from pg_attribute a,pg_class c where c.oid=a.attrelid and attname='l_orderkey';
relname | attname | attoptions
----------+------------+------------------
lineitem | l_orderkey | n_distinct=0.9
(1 row)
postgres=# alter table lineitem alter l_orderkey reset (n_distinct);
ALTER TABLE
postgres=# select relname,attname,attoptions from pg_attribute a,pg_class c where c.oid=a.attrelid and attname='l_orderkey';
relname | attname | attoptions
----------+------------+------------
lineitem | l_orderkey |
(1 row)5.2. 冻结表的全部统计信息
如果表的数据特征基本不变,还可以冻结表的统计信息,来避免重复进行analyze。
alter table table_name set frozen_stats=true;6. 手动查看表是否需要做analyze
a. 不想在业务高峰期时触发数据库后台任务,所以不愿意打开autovacuum来触发analyze,怎么办?
b. 业务修改了一批表,想立即对这些表马上做一次analyze,又不知道都有哪些表,怎么办?
c. 业务高峰来临前想对临近阈值的表都做一次analyze,怎么办?
我们将autovacuum检查阈值判断是否需要analyze逻辑,抽取成了函数,帮助用户灵活主动的检查哪些表需要做analyze。
6.1 判断表是否需要analyze(串行版,适用于所有历史版本)
-- the function for get all pg_stat_activity information in all CN of current cluster.
CREATE OR REPLACE FUNCTION pg_catalog.pgxc_stat_table_need_analyze(in table_name text)
RETURNS BOOl
AS $$
DECLARE
row_data record;
coor_name record;
fet_active text;
fetch_coor text;
relTuples int4;
changedTuples int4:= 0;
rel_anl_threshold int4;
rel_anl_scale_factor float4;
sys_anl_threshold int4;
sys_anl_scale_factor float4;
anl_threshold int4;
anl_scale_factor float4;
need_analyze bool := false;
BEGIN
--Get all the node names
fetch_coor := 'SELECT node_name FROM pgxc_node WHERE node_type=''C''';
FOR coor_name IN EXECUTE(fetch_coor) LOOP
fet_active := 'EXECUTE DIRECT ON (' || coor_name.node_name || ') ''SELECT pg_stat_get_tuples_changed(oid) from pg_class where relname = ''''|| table_name ||'''';''';
FOR row_data IN EXECUTE(fet_active) LOOP
changedTuples = changedTuples + row_data.pg_stat_get_tuples_changed;
END LOOP;
END LOOP;
EXECUTE 'select pg_stat_get_live_tuples(oid) from pg_class c where c.oid = '''|| table_name ||'''::REGCLASS;' into relTuples;
EXECUTE 'show autovacuum_analyze_threshold;' into sys_anl_threshold;
EXECUTE 'show autovacuum_analyze_scale_factor;' into sys_anl_scale_factor;
EXECUTE 'select (select option_value from pg_options_to_table(c.reloptions) where option_name = ''autovacuum_analyze_threshold'') as value
from pg_class c where c.oid = '''|| table_name ||'''::REGCLASS;' into rel_anl_threshold;
EXECUTE 'select (select option_value from pg_options_to_table(c.reloptions) where option_name = ''autovacuum_analyze_scale_factor'') as value
from pg_class c where c.oid = '''|| table_name ||'''::REGCLASS;' into rel_anl_scale_factor;
--dbms_output.put_line('relTuples='||relTuples||'; sys_anl_threshold='||sys_anl_threshold||'; sys_anl_scale_factor='||sys_anl_scale_factor||'; rel_anl_threshold='||rel_anl_threshold||'; rel_anl_scale_factor='||rel_anl_scale_factor||';');
if rel_anl_threshold IS NOT NULL then
anl_threshold = rel_anl_threshold;
else
anl_threshold = sys_anl_threshold;
end if;
if rel_anl_scale_factor IS NOT NULL then
anl_scale_factor = rel_anl_scale_factor;
else
anl_scale_factor = sys_anl_scale_factor;
end if;
if changedTuples > anl_threshold + anl_scale_factor * relTuples then
need_analyze := true;
end if;
return need_analyze;
END; $$
LANGUAGE 'plpgsql';6.2 判断表是否需要analyze(并行版,适用于支持并行执行框架的版本)
-- the function for get all pg_stat_activity information in all CN of current cluster.
--SELECT sum(a) FROM pg_catalog.pgxc_parallel_query('cn', 'SELECT 1::int FROM pg_class LIMIT 10') AS (a int); 利用并发执行框架
CREATE OR REPLACE FUNCTION pg_catalog.pgxc_stat_table_need_analyze(in table_name text)
RETURNS BOOl
AS $$
DECLARE
relTuples int4;
changedTuples int4:= 0;
rel_anl_threshold int4;
rel_anl_scale_factor float4;
sys_anl_threshold int4;
sys_anl_scale_factor float4;
anl_threshold int4;
anl_scale_factor float4;
need_analyze bool := false;
BEGIN
--Get all the node names
EXECUTE 'SELECT sum(a) FROM pg_catalog.pgxc_parallel_query(''cn'', ''SELECT pg_stat_get_tuples_changed(oid)::int4 from pg_class where relname = ''''|| table_name ||'''';'') AS (a int4);' into changedTuples;
EXECUTE 'select pg_stat_get_live_tuples(oid) from pg_class c where c.oid = '''|| table_name ||'''::REGCLASS;' into relTuples;
EXECUTE 'show autovacuum_analyze_threshold;' into sys_anl_threshold;
EXECUTE 'show autovacuum_analyze_scale_factor;' into sys_anl_scale_factor;
EXECUTE 'select (select option_value from pg_options_to_table(c.reloptions) where option_name = ''autovacuum_analyze_threshold'') as value
from pg_class c where c.oid = '''|| table_name ||'''::REGCLASS;' into rel_anl_threshold;
EXECUTE 'select (select option_value from pg_options_to_table(c.reloptions) where option_name = ''autovacuum_analyze_scale_factor'') as value
from pg_class c where c.oid = '''|| table_name ||'''::REGCLASS;' into rel_anl_scale_factor;
dbms_output.put_line('relTuples='||relTuples||'; sys_anl_threshold='||sys_anl_threshold||'; sys_anl_scale_factor='||sys_anl_scale_factor||'; rel_anl_threshold='||rel_anl_threshold||'; rel_anl_scale_factor='||rel_anl_scale_factor||';');
if rel_anl_threshold IS NOT NULL then
anl_threshold = rel_anl_threshold;
else
anl_threshold = sys_anl_threshold;
end if;
if rel_anl_scale_factor IS NOT NULL then
anl_scale_factor = rel_anl_scale_factor;
else
anl_scale_factor = sys_anl_scale_factor;
end if;
if changedTuples > anl_threshold + anl_scale_factor * relTuples then
need_analyze := true;
end if;
return need_analyze;
END; $$
LANGUAGE 'plpgsql';6.3 判断表是否需要analyze(自定义阈值)
-- the function for get all pg_stat_activity information in all CN of current cluster.
CREATE OR REPLACE FUNCTION pg_catalog.pgxc_stat_table_need_analyze(in table_name text, int anl_threshold, float anl_scale_factor)
RETURNS BOOl
AS $$
DECLARE
relTuples int4;
changedTuples int4:= 0;
need_analyze bool := false;
BEGIN
--Get all the node names
EXECUTE 'SELECT sum(a) FROM pg_catalog.pgxc_parallel_query(''cn'', ''SELECT pg_stat_get_tuples_changed(oid)::int4 from pg_class where relname = ''''|| table_name ||'''';'') AS (a int4);' into changedTuples;
EXECUTE 'select pg_stat_get_live_tuples(oid) from pg_class c where c.oid = '''|| table_name ||'''::REGCLASS;' into relTuples;
if changedTuples > anl_threshold + anl_scale_factor * relTuples then
need_analyze := true;
end if;
return need_analyze;
END; $$
LANGUAGE 'plpgsql';通“优化器触发的实时analyze”和“后台autovacuum触发的轮询analyze”,GaussDB(DWS)已经可以做到让用户不再关心表是否需要analyze。建议在最新版本中试用。
以上是关于一文掌握数仓中auto analyze的使用的主要内容,如果未能解决你的问题,请参考以下文章