实习解决请求参数过长问题
Posted 王六六的IT日常
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了实习解决请求参数过长问题相关的知识,希望对你有一定的参考价值。
又要解决bug啦!!!

由于前端传过来的json数据过长导致请求参数太长,最后出现空指针异常。
HTTP/1.1 414 Request-URI Too Large
解决方法:
参考:Java使用GZIP进行压缩和解压缩(GZIPOutputStream,GZIPInputStream)
使用gzip压缩/解压缩字符串
一、使用gzip压缩字符串(str 要压缩的字符串)
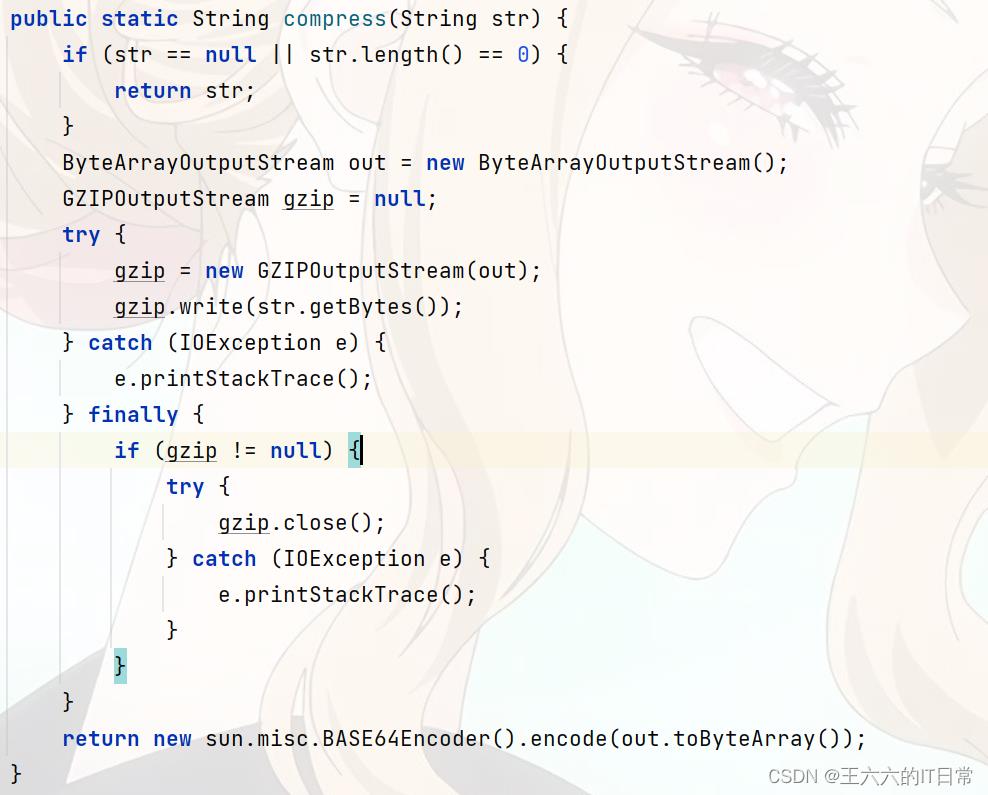
①
参考:
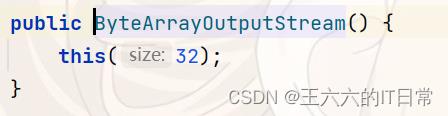
Java ByteArrayOutputStream类
//创建一个32字节(默认大小)的缓冲区
ByteArrayOutputStream out = new ByteArrayOutputStream();
源码:
②
//创建具有默认缓冲区大小out的新字节数组输出流对象。
GZIPOutputStream gzip = new GZIPOutputStream(out);
参考:
Java_io体系之FilterInputStream/FilterOutputStream简介、走进源码及示例——07
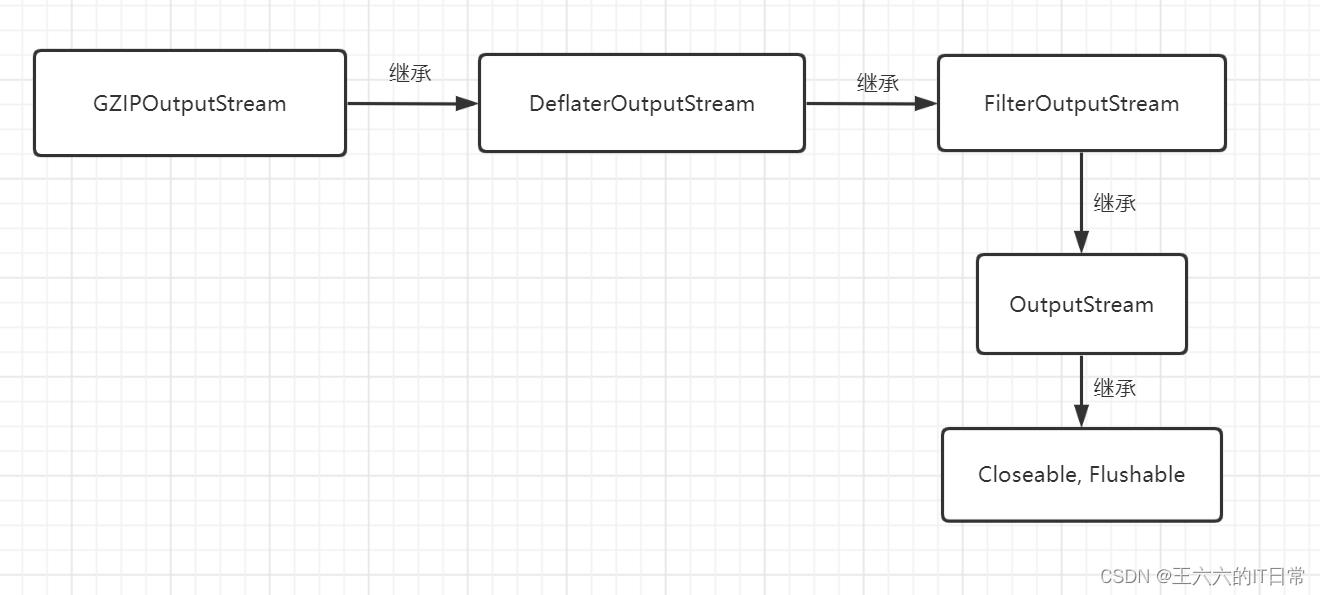
源码:
创建具有默认缓冲区大小的新输出流。
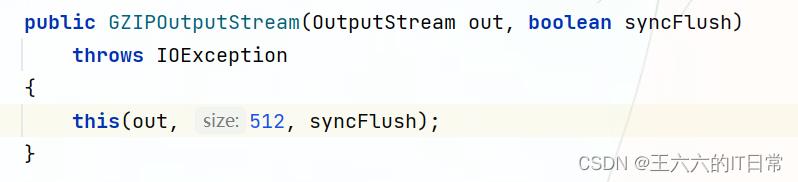
新的输出流实例是通过调用2参数构造函数GZIPOutputStream(out,false)创建的。

使用默认缓冲区大小和指定的刷新模式创建新的输出流。
参数:
out–输出流syncFlush–如果此实例的继承flush()方法的调用为true,则使用flush mode Deflater刷新压缩器。在刷新输出流之前进行SYNC\\u刷新,否则仅刷新输出流.
③
gzip.write(str.getBytes());
getBytes() 是Java编程语言中将一个字符串转化为一个字节数组byte[]的方法。
//getBytes() 源码:
public byte[] getBytes()
return StringCoding.encode(value, off:0, value.length);
write源码:
将b.length字节写入此输出流。
FilterOutputStream的write方法使用参数b、0和b.length调用其三个参数的write方法。
注意,该方法不使用单参数b调用其底层流的单参数write方法。

其三个参数的write方法源码:
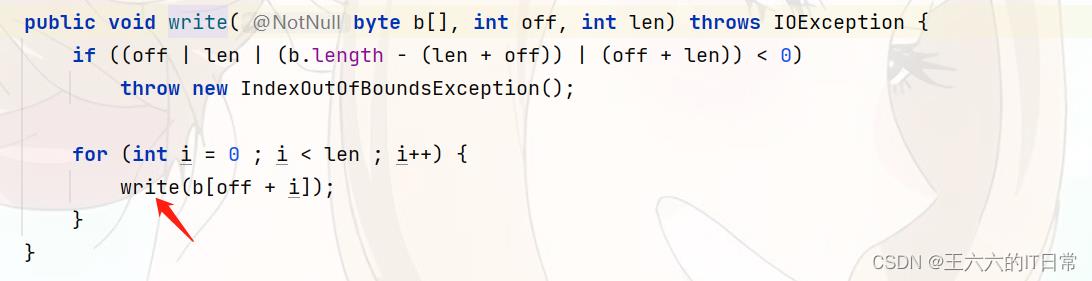
从偏移量off开始,将指定字节数组中的len字节写入此输出流。
FilterOutputStream的write方法调用每个字节上一个参数的write方法进行输出。
请注意,此方法不会使用相同的参数调用其底层输入流的write方法。FilterOutputStream的子类应提供此方法的更有效实现。
将指定的字节写入此输出流。
FilterOutputStream的write方法调用其底层输出流的write方法,即执行。写入(b)。实现OutputStream的抽象写入方法。

将指定的字节写入此输出流。
写入的一般约定是将一个字节写入输出流。要写入的字节是参数b的八个低位。忽略b的24个高位。OutputStream的子类必须提供此方法的实现。

④
if (gzip != null)
try
gzip.close();
catch (IOException e)
e.printStackTrace();
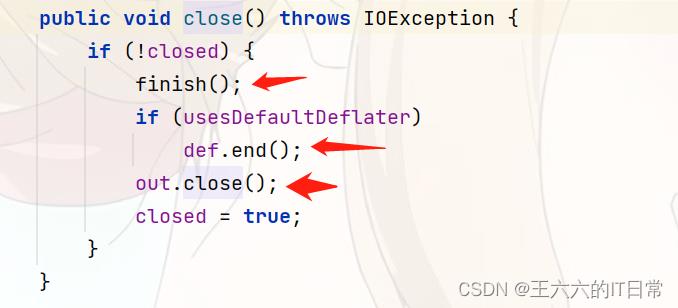
close源码:
将剩余的压缩数据写入输出流并关闭底层流。
private boolean closed = false;
boolean usesDefaultDeflater = false;
将压缩数据写入输出流而不关闭底层流。
当对同一输出流连续应用多个过滤器时,请使用此方法。

关闭压缩机并丢弃任何未处理的输入。当压缩器不再使用时,应调用此方法,但也将由finalize()方法自动调用。调用此方法后,Deflater对象的行为未定义。

关闭此输出流并释放与此流关联的任何系统资源。
关闭的一般约定是关闭输出流。关闭的流无法执行输出操作,也无法重新打开。
OutputStream的close方法不起任何作用。

⑤
//编码-压缩
return new sun.misc.BASE64Encoder().encode(out.toByteArray());
参考:
- sun.misc.BASE64Encoder详解
- base64编码解码及sun.misc.BASE64Decoder的用法
- 关于Base64编码(Encode)与解码(Decode)的几种方式,这里面有道道
在JAVA中要实现Base64的编码和解码是非常容易的,因为JDK中已经有提供有现成的类:
//编码:
String src ="BASE64编码测试";
sun.misc.BASE64Encoder en = new sun.misc.BASE64Encoder();
String encodeStr = en.encode(src.getBytes());
//解码:
sun.misc.BASE64Decoder dec = newsun.misc.BASE64Decoder();
byte[] data = dec.decodeBuffer(decodeStr);

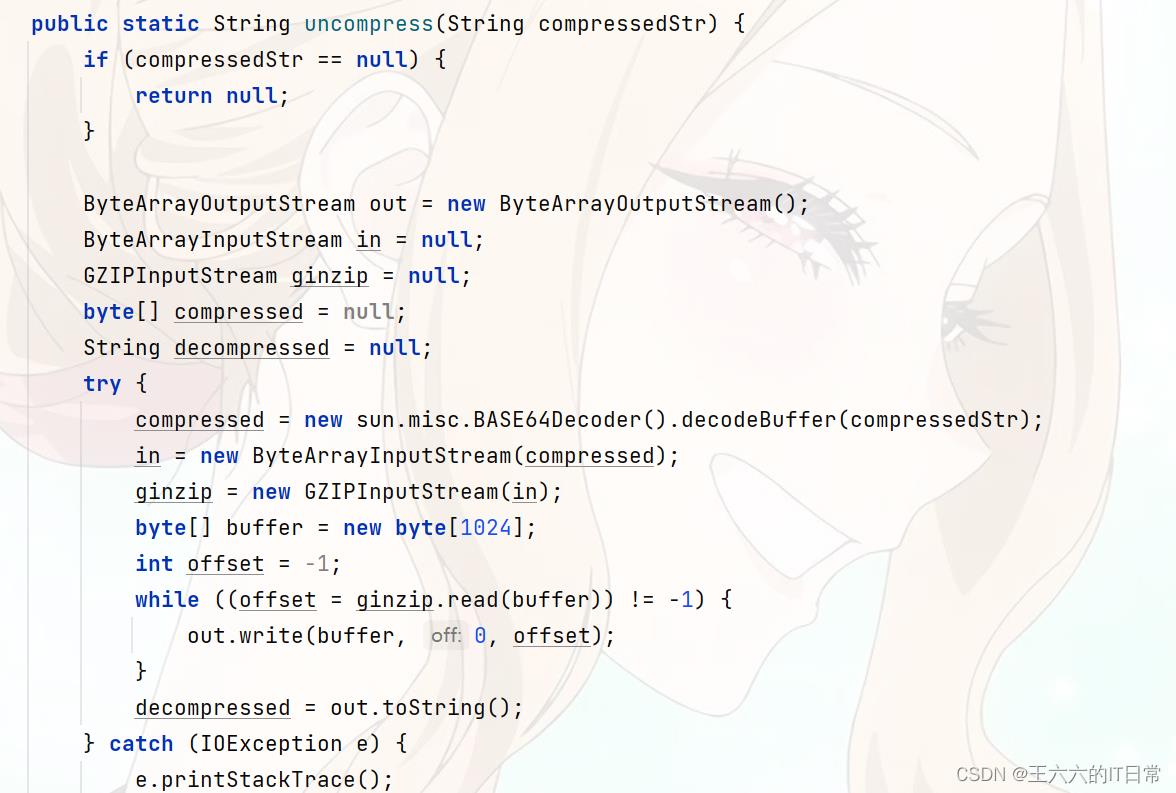
二、使用gzip解压缩(compressedStr 压缩字符串)

①
//初始化,建立默认大小的缓冲分区
ByteArrayOutputStream out = new ByteArrayOutputStream();
ByteArrayInputStream in = null;
GZIPInputStream ginzip = null;
byte[] compressed = null;
String decompressed = null;
②
//decodeBuffer()解码
compressed = new sun.misc.BASE64Decoder().decodeBuffer(compressedStr);
③
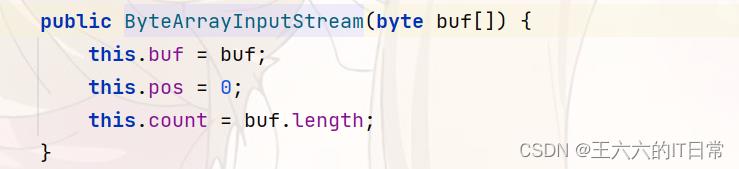
in = new ByteArrayInputStream(compressed);
创建ByteArrayInputStream,以便使用buf作为其缓冲区数组。未复制缓冲区阵列。pos的初始值为0,count的初始值为buf的长度。
④
ginzip = new GZIPInputStream(in);
创建具有默认缓冲区大小的新输入流。

⑤
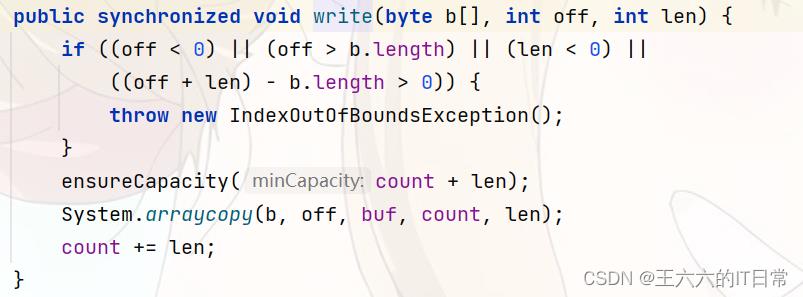
while ((offset = ginzip.read(buffer)) != -1)
out.write(buffer, 0, offset);
最多读取字节。将此输入流中的数据长度字节设置为字节数组。此方法会阻塞,直到有一些输入可用。
该方法只执行调用读取(b,0,b.length)并返回结果。重要的是,它不适用于。改为(b);FilterInputStream的某些子类取决于实际使用的实现策略。

从该输入流中读取多达len个字节的数据到一个字节数组中。如果len不为零,该方法将阻塞,直到有一些输入可用;否则,不读取任何字节,并返回0。
此方法仅在中执行。读取(b,off,len)并返回结果。
参数:
b–读取数据的缓冲区。off–目标阵列b len中的开始偏移量–读取的最大字节数。

从偏移量off开始,将指定字节数组中的len字节写入此字节数组输出流。
⑥
//转换为String类型
decompressed = out.toString();
针对java,注意:
- 如果项目的JDK版本小于1.8,请使用org.apache.commons.codec.binary.Base64;
- 如果项目的JDK版本大于1.8,请使用java.util.Base64;
- 使用org.apache.commons.codec.binary.Base64时,要选择与项目JDK相符的JAR包,否则实现不了效果;
- java.util.Base64与org.apache.commons.codec.binary.Base64包冲突,不能同时存在一个类中;
- 注意,UTF-8和GBK中文格式的Base64编码结果是不同的。
三、修改service实现类-Json转换为sql方法中conditionJson的压缩格式
原来:
params.put("conditionJson", URLEncoder.encode(tagInfo.getGenerationLogic(),"UTF-8")); // conditionJson条件json字段 同 生成逻辑字段:generationLogic
修改后: 请求url的时候经过压缩后的参数不会过长
//压缩后的逻辑json
String compressGenerationLogic = CompressUtil.compress(tagInfo.getGenerationLogic());
params.put("conditionJson", URLEncoder.encode(Base64.encodeBase64String(compressGenerationLogic.getBytes()),"UTF-8"));
URLEncoder.encode(String s, String enc):
s–要翻译的字符串。enc–支持的字符编码的名称。
URLEncoder.encode(tagInfo.getGenerationLogic(),"UTF-8")
使用特定的编码方案将字符串转换为application/x-www-form-urlencoded格式。此方法使用提供的编码方案来获取不安全字符的字节。
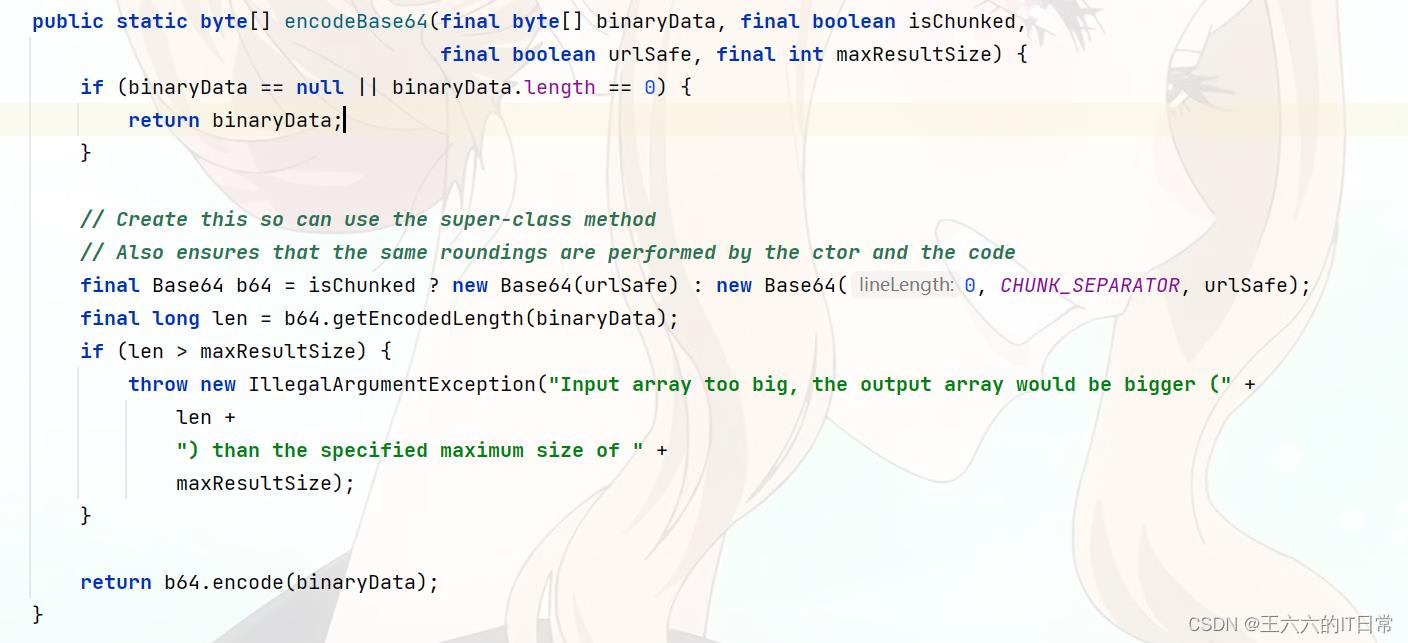
String encode(String s, String enc)
使用base64算法对二进制数据进行编码,但不将输出分块。
注:我们将该方法的行为从多行分块(commons-codec-1.4)更改为单行非分块(commons-codec-1.5)。

使用base64算法对二进制数据进行编码,可以选择将输出分块为76个字符块。
isChunked–如果为true,则此编码器将base64输出分为76个字符块

使用base64算法对二进制数据进行编码,可以选择将输出分块为76个字符块。
参数:
binaryData–包含要编码的二进制数据的数组。
isChunked–如果为true,则此编码器将base64输出分为76个字符块
urlSafe–如果为true,则此编码器将发出-和_而不是通常的+和/字符。注意:使用URL安全字母表编码时不添加填充。

使用base64算法对二进制数据进行编码,可以选择将输出分块为76个字符块。
参数:
binaryData–包含要编码的二进制数据的数组。
isChunked–如果为true,则此编码器将base64输出分为76个字符块
urlSafe–如果为true,则此编码器将发出-和_而不是通常的+和/字符。
注意:使用URL安全字母表编码时不添加填充。
maxResultSize–要接受的最大结果大小。
四、修改Controller的接口
往request中添加条件json—是解压缩后的。
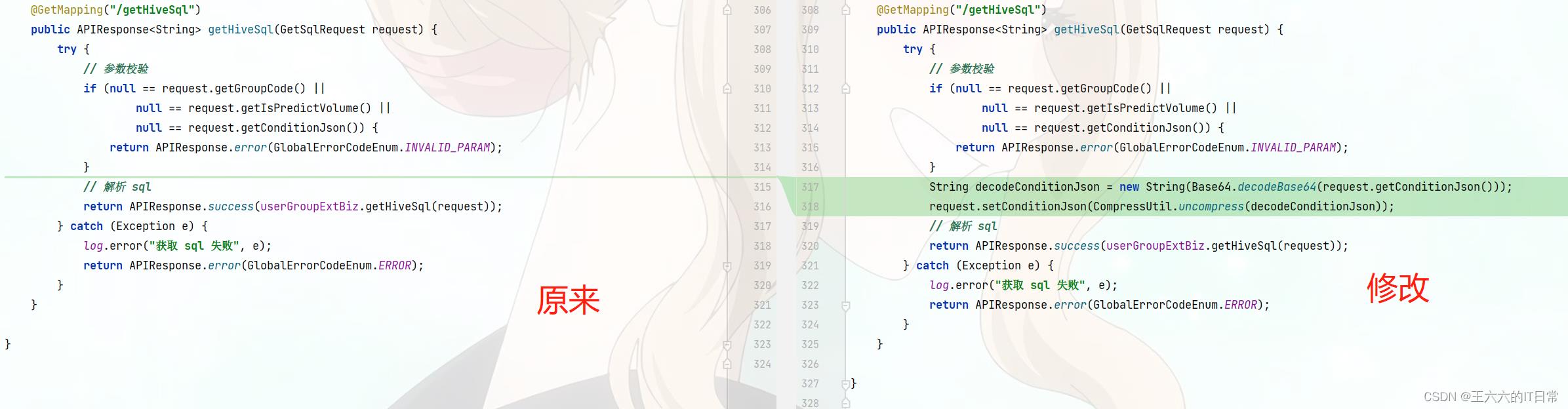
String decodeConditionJson = new String(Base64.decodeBase64(request.getConditionJson()));
request.setConditionJson(CompressUtil.uncompress(decodeConditionJson));
将Base64字符串解码为八位字节:

解码包含N进制字母中字符的字符串。

解码包含N进制字母中字符的字节数组。

发送端在数据发送前的处理流程如下(接收端互逆):
1.先对原始字符串签名,以保证签名忠实于原始内容;
2.然后压缩,以精简内容的尺寸,提高后续加密和传输的效率;
3.最后加密,保证数据安全。
以上是关于实习解决请求参数过长问题的主要内容,如果未能解决你的问题,请参考以下文章