R-FCN: Object Detection via Region-based Fully Convolutional Networks
Posted 07H_JH
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了R-FCN: Object Detection via Region-based Fully Convolutional Networks相关的知识,希望对你有一定的参考价值。
1. 简介
物体检测的深度网络按感兴趣区域 (RoI) 池化层分为两大主流:共享计算的全卷积子网络 (每个子网络与 RoI 无关) 和 不共享计算的作用于各自 RoI 的子网络。工程分类结构 (如 Alexnet 和 VGG Nets) 造成这样的分流。而工程上的图像分类结构被设计为两个子网络——1个后缀1个空间池化层的卷积子网络和多个全连接层。因此,图像分类网络中最后的空间池化层自然变成了物体检测网络中的 RoI 池化层。
近年来,诸如残差网络和 GoogLeNets 等先进的图像分类网络为全卷积网络。类似地,自然会想到用在物体检测中用全卷积网络 (隐藏层不包含作用于 RoI 的子网络)。然而,物体检测工作中的经验表明,这样天真的解决方案的检测效果远差于该网络的分类效果。 为弥补尴尬,更快 R-CNN 检测器不自然地在两卷积层间插入RoI 池化层,这样更深的作用于各 RoI 的子网络虽精度更高,但各个 RoI 计算不共享所以速度慢。
尴尬在于:物体分类要求平移不变性越大越好 (图像中物体的移动不用区分),而物体检测要求有平移变化。所以,ImageNet 分类领先的结果证明尽可能有平移不变性的全卷积结构更受亲睐。另一方面,物体检测任务需要一些平移变化的定位表示。比如,物体的平移应该使网络产生响应,这些响应对描述候选框覆盖真实物体的好坏是有意义的。我们假设图像分类网络的卷积层越深,则该网络对平移越不敏感。
我曾看到的尴尬包括:
a) Kaggle 中的白鲸身份识别。刚开始很多人尝试从图像到坐标的直接回归,到后面有几位心善的大哥分享了自己手动标定后白鲸的图像坐标,后来显著的进展大多是因为把白鲸的位置检测和身份识别问题简化为白鲸的身份识别问题。
b) Caffe 用于物体检测时的均值收敛问题。
为消除尴尬,在网络的卷积层间插入 RoI 池化层。这种具体到区域的操作在不同区域间跑时不再有平移不变性。然而,该设计因引入相当数目的按区域操作层 (region-wise layers) 而牺牲了训练和测试效率。
本文,我们为物体检测推出了基于区域的全卷积网络 (R-FCN),采用全卷积网络结构作为 FCN,为给 FCN 引入平移变化,用专门的卷积层构建位置敏感分数地图 (position-sensitive score maps)。每个空间敏感地图编码感兴趣区域的相对空间位置信息。 在FCN上面增加1个位置敏感 RoI 池化层来监管这些分数地图。
2. 方法
(1) 简介
效仿 R-CNN,采用流行的物体检测策略,包括区域建议和区域分类两步。不依赖区域建议的方法确实存在 (SSD 和 Yolo 弟兄),基于区域的系统在不同 benchmarks 上依然精度领先。用更快 R-CNN 中的区域建议网络 (RPN) 提取候选区域,该 RPN 为全卷积网络。效仿更快 R-CNN,共享 RPN 和 R-FCN 的特征。
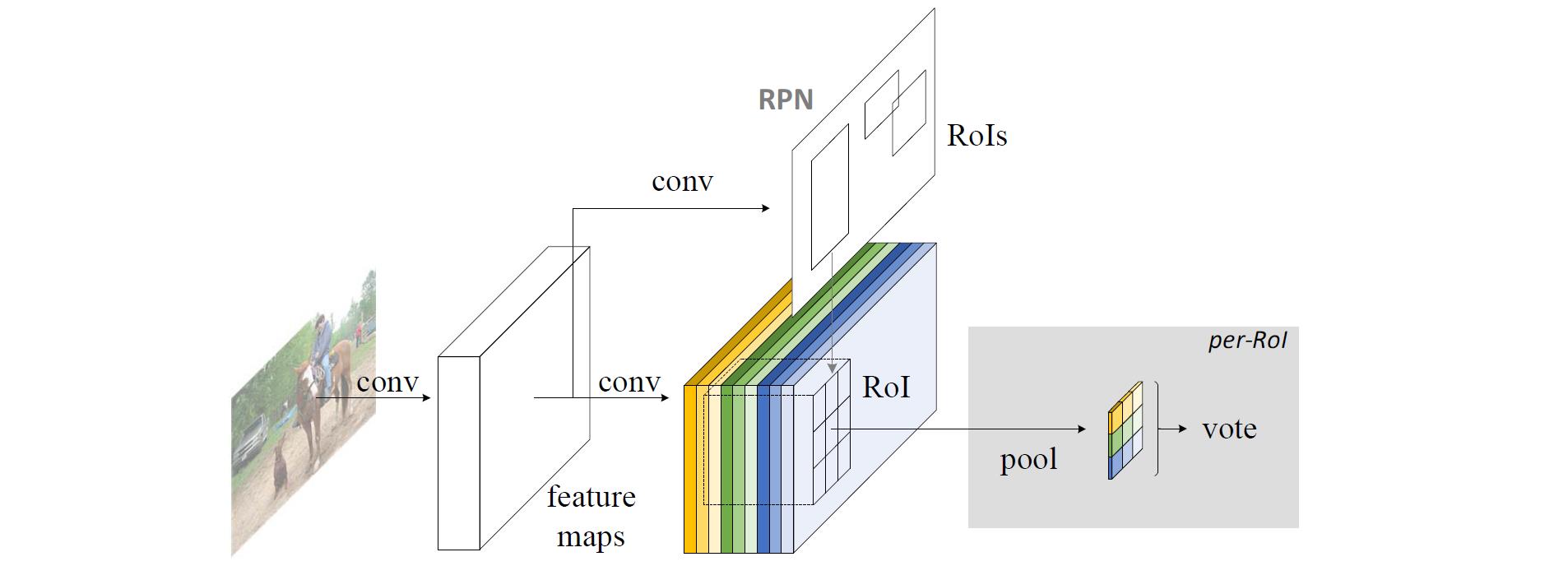
RPN 给出感兴趣区域,R-FCN 对该感兴趣区域分类。R-FCN 在与 RPN 共享的卷积层后多加1个卷积层。所以,R-FCN 与 RPN 一样,输入为整幅图像。但 R-FCN 最后1个卷积层的输出从整幅图像的卷积响应图像中分割出感兴趣区域的卷积响应图像。
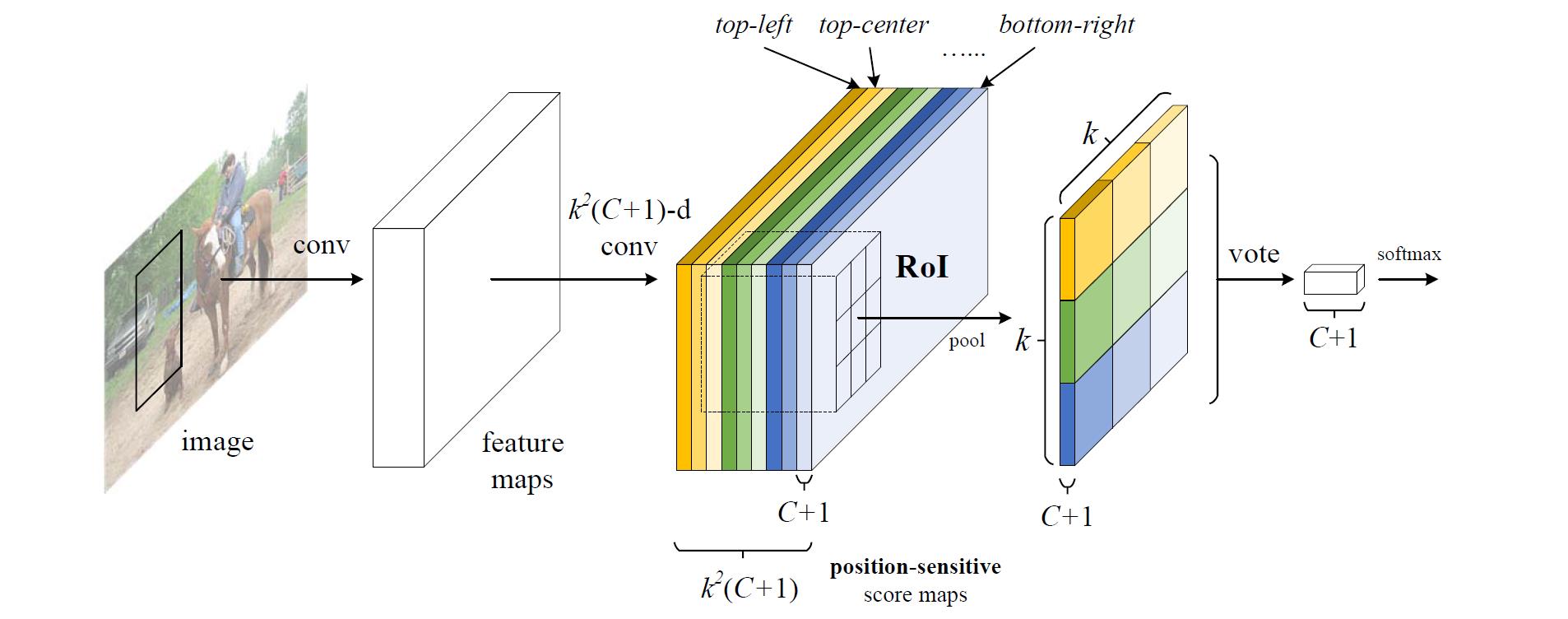
R-FCN 最后1个卷积层在整幅图像上为每类生成 k2 个位置敏感分数图,有 C 类物体外加1个背景,因此有 k2(C+1) 个通道的输出层。 k2 个分数图对应描述位置的空间网格。比如, k×k=3×3 ,则9个分数图编码单个物体类的 top−left,top−center,top−right,...,bottom−right 。
R-FCN 最后用位置敏感 RoI 池化层,给每个 RoI 1个分数。选择性池化图解:看上图的橙色响应图像 ( top−left ),抠出橙色方块 RoI,池化橙色方块 RoI 得到橙色小方块 (分数);其它颜色的响应图像同理。对所有颜色的小方块投票 (或池化) 得到1类的响应结果。
选择性池化是跨通道的,投票部分的池化为所有通道的池化。而一般池化都在通道内。
R-FCN 最后1个卷积层的输出为什么会具有相对空间位置这样的物理意义 (top-left,top-center,…,bottom-right)?
原文为“With end-to-end training, this RoI layer shepherds the last convolutional layer to learn specialized position-sensitive score maps.”。所以,假设端到端训练后每层真有相对位置的意义,那么投票前的输入一定位置敏感。投票后面的内容用作分类。
端到端训练先自行脑补:
假设已知原图像与真实物体的边界框中心坐标和宽高,把1个物体的边界框中心坐标分成
k2
个网格的中心坐标,宽高缩放为物体宽高的
1k
倍,得到每个网格的掩码。用原图像和每类物体的网格在整幅图像中的掩码端到端训练全卷积网络。挺像图像分割~
(2) 基础结构
ResNet-101 网络有100个卷积层,1个全局平均池化层和1个1000类的全连接层。仅用ImageNet预训练的该网络的卷积层计算特征图。
(3) 位置敏感分数图
对 R-FCN 的卷积响应图像按 RPN 的结果分割出来感兴趣区域,对单通道的感兴趣区域分成
k×k
个网格,每个网格平均池化,然后所有通道再平均池化。
其实不是这样的~ 因为 RoI 覆盖的所有面积的橙色方片都是左上位置的响应。
“To explicitly encode position information into each RoI, we divide each RoI rectangle into k×k bins by a regular grid.” 这句话应对应下图 (对应后面效果图的黄色虚线部分):
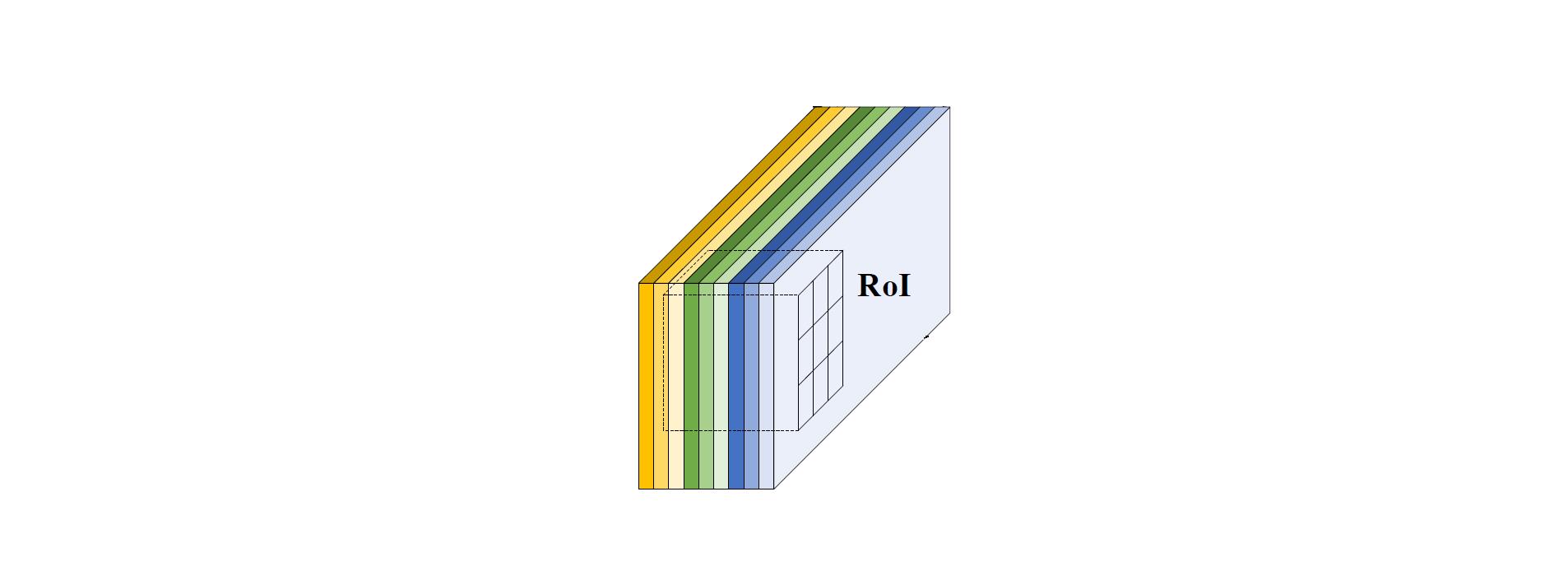
对1个大小为 w×h 的 RoI,1个桶 (bin) 的大小为 wk×hk ,最后1个卷积层为每类产生 k2 个分数图。对第 (i,j) 个桶 (