Multi-Task Learning Using Uncertainty to Weigh Losses for Scene Geometry and Semantics 阅读
Posted 一杯敬朝阳一杯敬月光
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Multi-Task Learning Using Uncertainty to Weigh Losses for Scene Geometry and Semantics 阅读相关的知识,希望对你有一定的参考价值。
摘要
多任务学习的效果很大程度依赖各损失的相对权重( the performance of such systems is strongly dependent on the relative weighting between each task’s loss),人工调节将这些权重所花费的代价是巨大的。文中提出依据各任务的同方差不确定性对损失进行加权(weighs multiple loss functions by considering the homoscedastic uncertainty of each task)。这样就可以同时学习分类和回归任务中的不同单位或不同尺度的数据(This allows us to simultaneously learn various quantities with different units or scales in both classification and regression settings)。展示了模型学习,从从单目输入图像进行per-pixel depth regression、semantic and instance segmentation。令人惊讶的是,模型可以学习多任务权重,并且优于针对每个任务单独训练的单独模型。
引言
多任务学习旨在通过共享信息学习多个目标来提高效率和预测的准确性。
实验场景是视觉场景理解visual scene understanding,场景理解算法必须同时理解场景的几何和语义,这意味着需要同时学习具有不同单位和尺度的各种分类和回归任务(joint learning of various regression and classification tasks with different units and scales)。视觉场景理解的多任务学习在禁止长时间计算的系统中至关重要,例如机器人技术中使用的系统。多个任务整合到一起,可以减少计算量,实时性更好。
在这之前的工作,多任务学习的损失函数要么使用简单的加和,要么人工调优。在实验中观察到每个任务最优权重取决于度量的尺度(例如,米,厘米,毫米),归根结底取决于任务噪声的大小(the optimal weighting of each task is dependent on the measurement scale (e.g. meters, centimetres or millimetres) and ultimately the magnitude of the task’s noise)。
将同方差不确定性作为任务间的权重(interpret homoscedastic uncertainty as task-dependent weighting),文中展示了如何导出可以平衡各回归和分类损失的多任务损失函数(derive a principled multi-task loss function which can learn to balance various regression and classification losses)。
具体来说,我们将通过三个任务演示我们学习场景几何和语义的方法。首先,我们学习在像素级别对对象进行分类,也称为语义分割(semantic segmentation)。其次,我们的模型执行实例分割(instance segmentation),这是一项更困难的任务,即为图像中的每个单独对象分割单独的masks(例如,为道路上的每个单独的汽车分割单独的、精确的masks)。这是一项比语义分割更困难的任务,因为它不仅需要估计每个像素的类别,还需要估计该像素属于哪个对象。它也比目标检测更复杂,因为目标检测通常只预测对象边界框。最后,我们的模型预测像素级度量深度(predicts pixel-wise metric depth)。通过有监督和无监督的深度学习,使用密集预测网络(dense prediction network)证明了识别深度。然而,很难以一种通用的方式来估计深度。我们表明,通过使用语义标签和多任务深度学习,我们可以改进对几何和深度的估计。
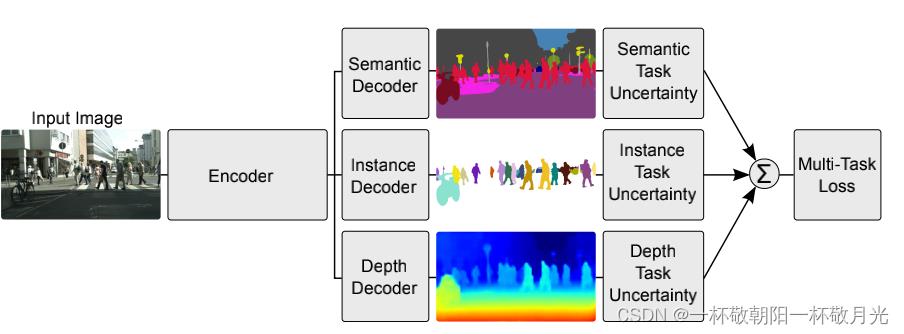
图1:多任务深度学习。我们推导了一种将多元回归和分类损失函数结合起来进行多任务学习的方法。我们的架构将单个单目RGB图像作为输入,并生成逐像素分类、实例语义分割和每个像素深度估计。与单独训练的模型相比,多任务学习可以提高准确性,因为来自一个任务的线索(例如深度)被用于正则化和提升另一个领域(例如分割)的泛化。
在现有文献中,分别使用单独的深度学习模型来学习深度回归、语义分割和实例分割(depth regression, semantic segmentation and instance segmentation),以创建一个完整的场景理解系统。给定单个单目输入图像,我们的系统是第一个联合生成语义分割、度量深度密集估计和实例级分割的系统(图1)。虽然其他视觉模型已经演示了多任务学习,但我们展示了如何学习将语义和几何结合起来。将这些任务组合到一个模型中可以确保模型在减少计算的同时,在单独的任务输出之间保持一致。最后,我们展示了在多任务学习中使用共享表示可以提高各种指标的性能,使模型更加有效。
总体来说,文章的贡献如下:
- 利用同余项任务不确定性,同时学习不同数量和单位(varying quantities and units)的各种分类和回归损失,
- semantic segmentation, instance segmentation and depth regression的统一架构,
- 演示损失加权在多任务深度学习中的重要性,以及如何获得优于同等单独训练模型的性能。
相关工作
多任务学习旨在提高每个任务的学习效率和预测准确性,相对于为每个任务单独训练一个模型来说。它可以被视为知识转移的一种方法,通过在互补任务之间共享领域信息来提高泛化能力。它通过使用共享表示来学习多个任务来实现这一点–从一个任务中学习的内容可以帮助学习其他任务。
微调[1,36]是多任务学习的一个基本示例,我们可以通过将不同的学习任务视为预训练步骤来利用它们。其他模型在每个训练任务之间交替学习,例如在自然语言处理中[11]。多任务学习也可用于数据流设置【40】,或防止在强化学习【26】中忘记之前学习的任务。它还可以使用自动编码器从各种数据源学习无监督的特征。
在计算机视觉中,有许多多任务学习方法的例子。许多研究侧重于语义任务,如分类和语义分割[30]或分类和检测[38]。MultiNet[39]提出了一种 detection, classification and semantic segmentation的体系结构。十字绣网络[34]explore methods to combine multi-task neural activations。Uhrig等人【41】在分类设置下学习语义和实例分段。多任务深度学习也用于几何和回归任务。[15] 演示如何学习语义分割、深度和曲面法线。PoseNet【25】是一种学习相机位置和方向的模型。UberNet[27]在一个架构下学习了多个不同的回归和分类任务。我们首次提出了一种联合学习深度回归、语义和实例分割的方法(depth regression, semantic and instance segmentation)。与[15]中的模型一样,我们的模型学习语义和几何表示(semantic and geometry representations),这对于场景理解很重要。然而,我们的模型学习了更加困难的实例分割任务(instance segmentation),这需要语义和几何知识。这是因为我们的模型必须确定每个对象中每个像素的类和空间关系,以便进行实例分割。
更重要的是,以前所有同时学习多个任务的方法都使用了一个简单的损失加和,其中损失权重是一致的,或者是粗略地手动调整的。在这项工作中,我们提出了一种结合多个损失函数的原则性方法,以使用同构任务不确定性同时学习多个目标。我们说明了在深度学习中适当加权每个任务以获得良好性能的重要性,并表明我们的方法可以学习如何最佳地平衡这些权重。
3. Multi Task Learning with Homoscedastic Uncertainty
多任务学习涉及到针对多个目标优化模型的问题。它普遍存在于许多深度学习问题中。组合多目标损失的简单方法是对每个任务的损失进行线性加和:
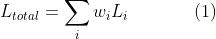
这是先前工作中使用的主要方法【39、38、30、41】。然而,这种方法存在许多问题。模型性能对权重选择 非常敏感,如图2所示。这些权重超参数的调整成本很高,每次测试通常需要很多天。因此,希望找到一种更方便的方法来学习最优权重。
非常敏感,如图2所示。这些权重超参数的调整成本很高,每次测试通常需要很多天。因此,希望找到一种更方便的方法来学习最优权重。
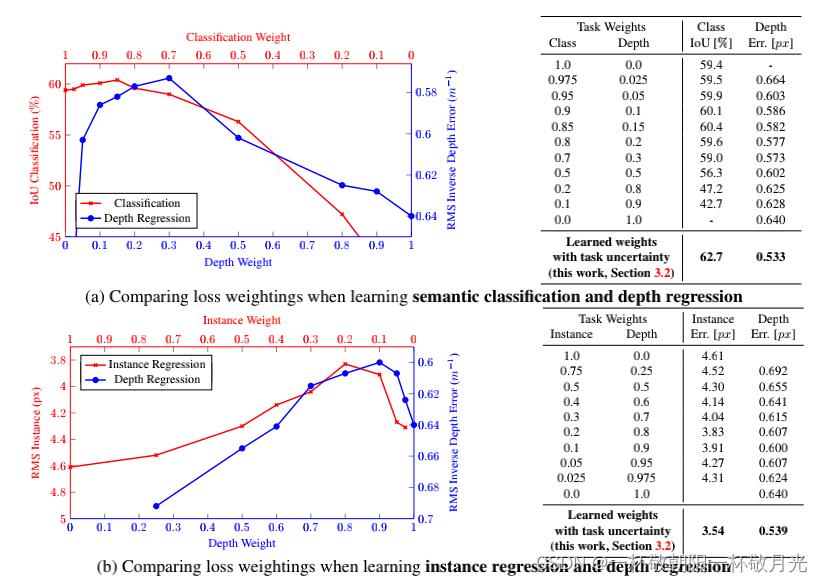
图2:学习多个任务可以提高模型的表示和单个任务的性能。这些图表说明了多任务学习对于(a)semantic classification and depth regression以及(b)instance and depth regression的优势。在w=0和w=1的绘图的两侧可以看到模型在单个任务中的性能。对于每个任务之间的某些权重,我们观察到两个任务的性能都有所提高。所有模型均以0.01的学习率进行训练,并使用(1)中的损失函数将各自的权重应用于损失。结果显示使用Tiny CityScapes validation dataset,使用128×256的下采样分辨率。
更具体地说,让我们考虑一个网络,该网络学习从输入图像预测pixel-wise depth and semantic class。在图2中,每个图的两个边界显示了针对单个任务训练的模型,曲线显示了每个任务的不同权重的表现。我们观察到,在某些权重下,联合网络的性能优于分别针对每个任务训练的单独网络(在图的两侧可以看到模型在各个任务中的性能:w=0和w=1)。在接近最佳权重的情况下,网络在其中一项任务上的性能较差。然而,对于任务众多的大型模型,搜索这些最佳权重的成本很高,而且越来越困难。图2还显示了两个回归任务的类似结果;instance segmentation and depth regression。接下来,我们将展示如何使用概率建模的思想来学习最佳任务权重。
3.1. Homoscedastic uncertainty as task-dependent uncertainty
在贝叶斯建模中,有两种主要的不确定性可以建模
- Epistemic uncertainty,认知不确定性它捕获了模型由于缺乏培训练据而不知道的信息。这可以用增加训练数据来解释。
- Aleatoric uncertainty,任意不确定性反映了我们对数据无法解释的信息的不确定性。任意不确定性可以用观察所有解释变量的能力来解释,并提高精度(can be explained away with the ability to observe all explanatory variables with increasing precision)。
任意不确定性又可分为两个子类。
- Data-dependent or Heteroscedastic uncertainty,数据相关或异方差不确定性,取决于输入数据,并作为模型输出进行预测(depends on the input data and is predicted as a model output)。
- Task-dependent or Homoscedastic uncertainty,任务相关或同质不确定性不依赖输入数据。它不是一个模型输出,而是一个对所有输入数据保持不变并在不同任务之间变化的量(it is a quantity which stays constant for all input data and varies between different tasks)。因此,它可以被描述为与任务相关的不确定性。
在多任务设置中,我们发现任务不确定性捕获了任务之间的相对置信度,反映了回归或分类任务固有的不确定性。它还将取决于任务的表示或度量单位。我们建议,在多任务学习问题中,我们可以使用同方差不确定性作为加权损失的基础(In a multi-task setting, we show that the task uncertainty captures the relative confidence between tasks, reflecting the uncer tainty inherent to the regression or classification task. It will also depend on the task’s representation or unit of measure. We propose that we can use homoscedastic uncertainty as a basis for weighting losses in a multi-task learning problem.)。
tainty inherent to the regression or classification task. It will also depend on the task’s representation or unit of measure. We propose that we can use homoscedastic uncertainty as a basis for weighting losses in a multi-task learning problem.)。
3.2. Multi-task likelihoods
在本节中,我们推导了一个多任务损失函数,该函数基于具有同余不确定性的高斯似然最大化。令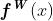 表示输入权重矩阵
表示输入权重矩阵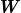 的情况下神经网络的输出。定义如下的概率模型。对于回归任务,我们将可能性定义为高斯分布,其中均值由模型输出给出:
的情况下神经网络的输出。定义如下的概率模型。对于回归任务,我们将可能性定义为高斯分布,其中均值由模型输出给出:
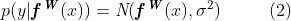
其中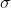 是观测噪声,对于分类,我们通常通过softmax函数压缩模型输出,并从产生的概率向量中采样( For classification we often squash the model output through a softmax function, and sample from the resulting probability vector)。
是观测噪声,对于分类,我们通常通过softmax函数压缩模型输出,并从产生的概率向量中采样( For classification we often squash the model output through a softmax function, and sample from the resulting probability vector)。
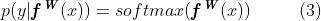
在多输出模型(multiple model outputs)的情况下,我们通常定义在给定一些充分统计量的情况下对输出进行因式分解的可能性。我们将定义为我们的充分统计量,并获得以下多任务可能性:
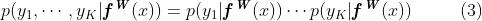
其中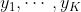 是模型的输出,例如semantic segmentation, depth regression, etc
是模型的输出,例如semantic segmentation, depth regression, etc
在最大似然推断中,我们将模型的对数似然最大化。例如,在回归中,对数似然可以写成
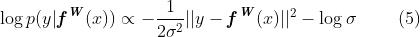
对于具有σ(模型的观测噪声参数-捕获输出中的噪声量)的高斯似然(或类似的拉普拉斯似然)。然后,我们在给定模型参数和观测噪声参数σ的情况下最大化对数似然。
现在让我们假设我们的模型输出由两个向量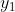 和
和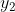 组成,每个向量遵循高斯分布:
组成,每个向量遵循高斯分布:

这就使得可以对我们的多输出模型最小化目标函数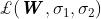 :
:

从上式可以看出,若的噪声参数
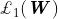 的对整个损失函数的影响减小;反之,若噪声参数减小,则的对整个损失函数的影响增加。目标中的最后一个项
的对整个损失函数的影响减小;反之,若噪声参数减小,则的对整个损失函数的影响增加。目标中的最后一个项 不鼓励噪声增加太多(实际上忽略了数据),该项充当噪声项的正则化器。
不鼓励噪声增加太多(实际上忽略了数据),该项充当噪声项的正则化器。
这种构造可以简单地扩展到多元回归输出。然而,对分类问题的扩展更有趣。我们在分类输出上套上一层softmax函数,将其输出压缩到[0,1]:
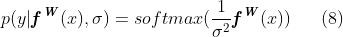
具有正标量σ。这可以解释为Boltzmann分布(也称为Gibbs分布),其中输入按 缩放(通常称为温度)。该标量是固定的或可以学习的,其中参数的大小决定离散分布的“均匀”(平坦)程度。这与熵测量的不确定性有关。然后,此输出的对数似然写为:
缩放(通常称为温度)。该标量是固定的或可以学习的,其中参数的大小决定离散分布的“均匀”(平坦)程度。这与熵测量的不确定性有关。然后,此输出的对数似然写为:
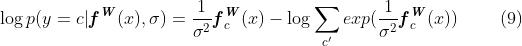
其中 是的第
是的第 个元素。
个元素。
接下来,假设模型的多个输出由连续输出y1和离散输出y2组成,分别用高斯似然和softmax似然建模。整体损失函数以之前的方式给出:
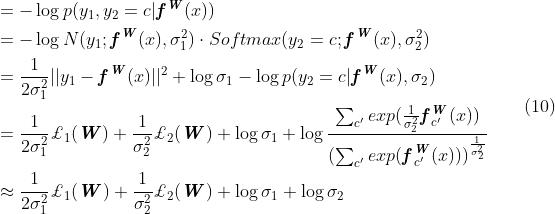
其中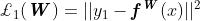 是的欧几里得损失,
是的欧几里得损失,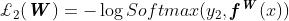 是的交叉熵损失,
是的交叉熵损失,
在上面转换中,我们引入了显式简化假设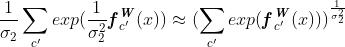 当
当
最后一个目标可以看作是学习每个输出损失的相对权重。较大的
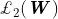 对整个损失函数的贡献,而较小的
对整个损失函数的贡献,而较小的
这种构造可以容易地扩展到离散和连续损失函数的任意组合,使我们能够很好的学习每个损失的相对权重。此损失是可平滑可微分的,并且格式良好,因此任务权重不会收敛到零。相反,使用简单的线性损失和(1)直接学习权重将导致权重快速收敛到零(allowing us to learn the relative weights of each loss in a principled and well-founded way. This loss is smoothly differentiable, and is well formed such that the task weights will not converge to zero. In contrast, directly learning the weights using a simple linear sum of losses (1) would result in weights which quickly converge to zero)。在下面的章节中,我们将介绍我们的实验模型并给出实证结果。
在实践中,我们训练网络预测对数方差,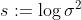 。这是因为它在数值上比回归方差更稳定,因为损失函数避免了任何除以零的情况。指数映射还允许我们回归无约束的标量值,其中
。这是因为它在数值上比回归方差更稳定,因为损失函数避免了任何除以零的情况。指数映射还允许我们回归无约束的标量值,其中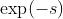 被解析为正域,给出有效的方差值。
被解析为正域,给出有效的方差值。
4. Scene Understanding Model
为了理解语义和几何,我们首先提出了一种可以在像素级学习回归和分类输出的体系结构。我们的架构是一个深度卷积编解码网络[3]。我们的模型由许多产生共享表示的卷积编码器组成,然后是相应数量的特定于任务的卷积解码器。结构参见图1。
编码器的目的是使用大量相关任务中的领域知识,学习深度映射以生成丰富的上下文特征。我们的编码器基于DeepLabV3[10],这是一个最先进的语义分割框架。我们使用ResNet101[20]作为基本特征编码器,然后使用Atrous Spatial Pyramid Pooling (ASPP) 模块[10]来增加上下文感知。我们在这个编码器中应用了扩展卷积,这样得到的特征映射与输入图像的维数相比是8倍的子采样。
以上是关于Multi-Task Learning Using Uncertainty to Weigh Losses for Scene Geometry and Semantics 阅读的主要内容,如果未能解决你的问题,请参考以下文章