细读《深入理解 Android 内核设计思想》Binder 机制 [上]
Posted 王英豪
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了细读《深入理解 Android 内核设计思想》Binder 机制 [上]相关的知识,希望对你有一定的参考价值。
对冗余挑拣重点,对重点深入补充,输出结构清晰的精简版
1.必备知识
设备驱动
文件描述符
页框
2.Binder 概述
3.binder 驱动
binder_open
binder_mmap
binder_ioctl
4.Service Manager
启动
注册与查询
5.最后
必备知识
设备驱动
Linux 把所有的硬件访问都抽象为对文件的读写、设置,这一"抽象"的具体实现就是驱动程序。驱动程序充当硬件和软件之间的枢纽,提供了一套标准化的调用,并将这些调用映射为实际硬件设备相关的操作,对应用程序来说隐藏了设备工作的细节。
Linux 设备分为三类,分别是字符设备、块设备和网络设备:
1.字符设备: 能够像字节流(类似文件)一样被访问的设备。对字符设备进行读/写操作时,实际硬件的 I/O 操作一般也紧接着发生。字符设备驱动程序通常都会实现 open、close、read 和 write 系统调用,比如触摸屏、键盘、串口、LCD、LED 等。
2.块设备: 指通过传输数据块(一般为 512 或 1k)来访问的设备,比如硬盘、SD卡、U盘、光盘等。
3.网络设备: 能够和其他主机交换数据的设备,比如网卡设备、蓝牙设备等。
通过 cat /proc/devices 命令可以查看字符设备和块设备:
Character devices:
1 mem
4 ttyS
10 misc
...
Block devices:
1 ramdisk
7 loop
8 sd
...
可以看到属于字符设备的 misc 杂项设备,设备号为 10。通过 ls /dev -l 命令可以查看具体的注册设备:
crw-rw-rw- 1 root root 10, 61 2020-03-16 16:52 ashmem
crw-rw-rw- 1 root root 10, 58 2020-03-16 16:52 binder
...
其中 Ashmem、Binder 的设备号是 10,都属于 misc 杂项设备,10 是 主设备号,61、58 叫做 从设备号,有了主、从设备号,就可以唯一标识一个设备。
文件描述符
Linux 中一切都可以看作文件,包括普通文件、链接文件、Socket 以及设备驱动等,对其进行相关操作时,都可能会创建对应的文件描述符。文件描述符(file descriptor)是内核为了高效管理已被打开的文件所创建的索引,用于指代被打开的文件,对文件所有 I/O 操作相关的系统调用都需要通过文件描述符。
文件描述符与文件是什么关系呢?下图 Linux 中的三张表可以体现:
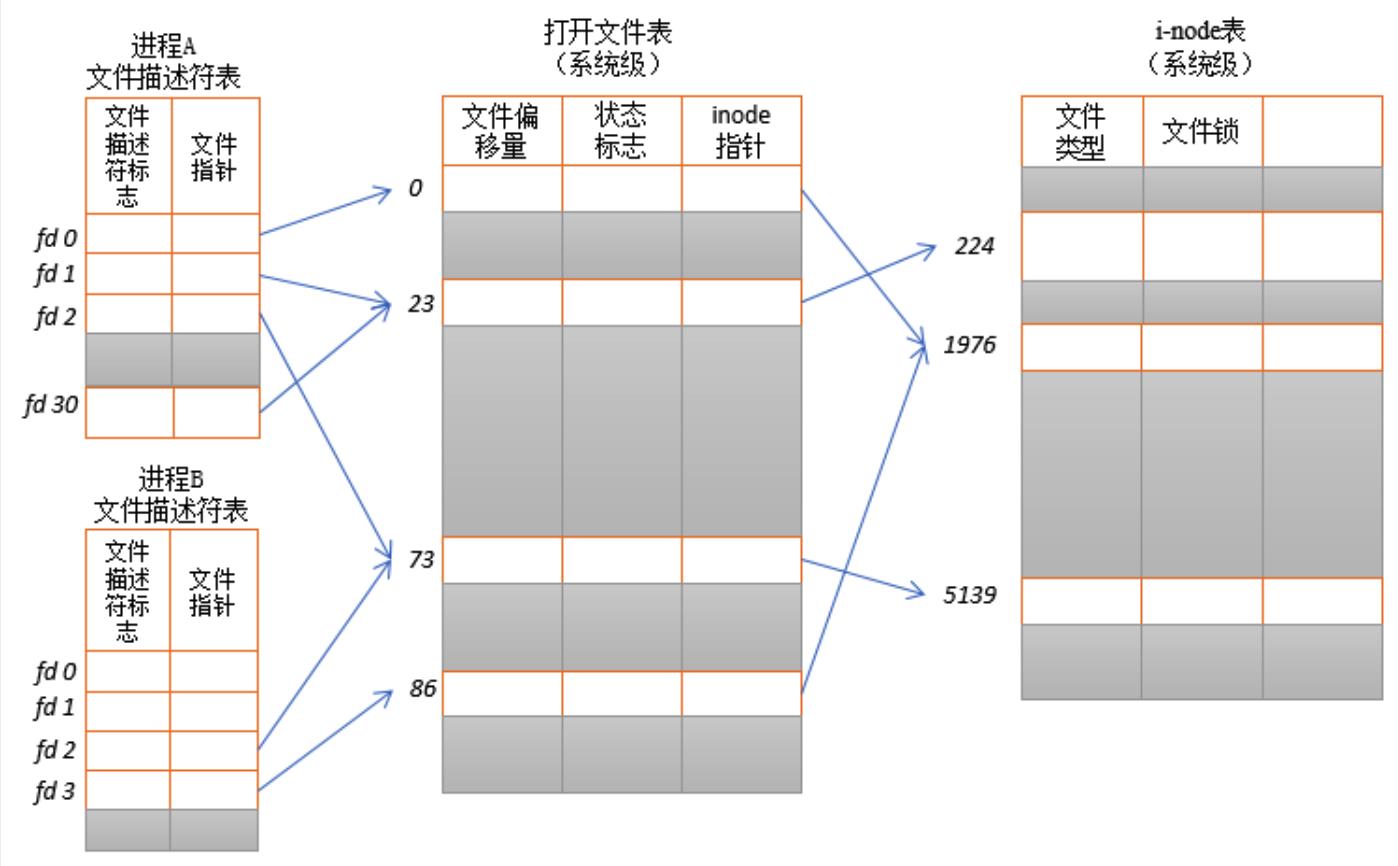
-
进程级别的文件描述符表:内核为每个进程维护一个文件描述符表,该表记录了文件描述符的相关信息,包括文件描述符、指向打开文件表中记录的指针。
-
系统级别的打开文件表:内核对所有打开文件维护的一个进程共享的打开文件描述表,表中存储了处于打开状态文件的相关信息,包括文件类型、访问权限、文件操作函数(file_operations)等。
-
系统级别的 i-node 表:i-node 结构体记录了文件相关的信息,包括文件长度,文件所在设备,文件物理位置,创建、修改和更新时间等,“ls -i” 命令可以查看文件 i-node 节点
文件描述符是一种系统资源,可以通过以下命令来查看文件描述符的上限:
#查看所有进程允许打开的最大 fd 数量
126|generic_x86:/ # cat /proc/sys/fs/file-max
174139
#查看所有进程已经打开的 fd 数量以及允许的最大数量
generic_x86:/ # cat /proc/sys/fs/file-nr
11040 0 174139
#查看单个进程允许打开的最大 fd 数量.
generic_x86:/ # ulimit -n
32768
也可以查看某进程当前已使用的 fd :
#查看某进程(进程 id 为 15077)已经打开的 fd
generic_x86:/ # ls -l /proc/15077/fd/
total 0
lrwx------ 1 u0_a136 u0_a136 64 2020-04-15 23:04 0 -> /dev/null
lrwx------ 1 u0_a136 u0_a136 64 2020-04-15 23:04 1 -> /dev/null
lrwx------ 1 u0_a136 u0_a136 64 2020-04-15 23:04 35 -> /dev/binder
lrwx------ 1 u0_a136 u0_a136 64 2020-04-09 01:01 44 -> socket:[780404]
lrwx------ 1 u0_a136 u0_a136 64 2020-04-15 23:04 55 -> /dev/ashmem
lrwx------ 1 u0_a136 u0_a136 64 2020-04-15 23:04 60 -> /dev/ashmem
...
上面这个进程是一个 android 应用进程,所以能看到 ashmem、binder 等 Android 特有设备文件相关的 fd 。再来看一个实际打开磁盘文件的例子:
File file = new File(getCacheDir(), "testFdFile");
FileOutputStream out = new FileOutputStream(file);
执行上面代码后会申请一个对应的 fd:
# ls -l /proc/pid/fd/
...
l-wx------ u0_a55 u0_a55 2020-04-16 00:24 995 -> /data/data/com.example.test/cache/testFdFile
...
实际开发中,可能会遇到 fd 资源超过上限导致的 “Too many open files” 之类的问题,一般都是因为没有及时释放掉 fd,比如上面代码中 FileOutputStream 没有关闭,若循环执行超过单个进程允许打开的最大 fd 数量,程序就会出现异常。
页框
页框(Page Frame)是指一块实际的物理内存块,页是指程序的一块内存数据单元。内存数据一定是存储在实际的物理内存上,即页必然对应于一个页框,页数据实际是存储在页框上的。
页框和页一样大,都是内核对内存的分块单位。一个页框可以映射给多个页,也就是说一块实际的物理存储空间可以映射给多个进程的多个虚拟内存空间,这也是 mmap 机制依赖的基础规则。
Binder 概述
不同进程处于不同的内存空间,具有不同的虚拟地址映射规则,所以不能直接通信。 Binder 是 Android 中使用最广泛的 IPC 机制,正因为有了 Binder,Android 系统中形形色色的进程与组件才能真正统一成有机的整体。Binder 通信机制与 TCP/IP 有共通之处,其组成元素可以这样来类比:
- binder 驱动 -> 路由器
- Service Manager -> DNS
- Binder Client -> 客户端
- Binder Server -> 服务器
Binder 的本质目标就是客户端要与服务器通信,但由于是不同的进程,必须通过 binder 驱动(路由器)把请求正确投递到对方进程中,所以通信的进程需要持有一个唯一的 Binder 标志(IP 地址)。
而 Binder 标志可能是会动态更新的 “IP 地址”,对通信进程来说获取难度较大且可读性差,这就需要一个 Service Manager(DNS)来解决这个问题。但 Service Manager 自身也是一个 Binder Server(服务器),怎么找到它的 "IP 地址"呢?Binder 机制对此做了特别规定:Service Manager 在 Binder 通信过程中的唯一标志永远是 0。
binder 驱动
binder 驱动运行在内核态,向上层提供 /dev/binder 设备节点,并不对应真实的硬件设备。binder 驱动的注册逻辑在 Binder.c 中:
//drivers/staging/android/Binder.c
static init __init binder_init(void)
...
ret = misc_register(&binder_miscdev); //注册为 misc 驱动
binder_miscdev 即 Binder 设备描述如下:
static struct miscdevice binder_miscdev =
.minor = MISC_DYNAMIC_MINOR, //自动分配次设备号
.name = "binder", //驱动名称
.fops = &binder_fops //binder 驱动支持的文件操作
binder_fops 为 Binder 设备支持的操作函数,如下:
static const struct file_operations binder_fops =
.owner = THIS_MODULE,
.poll = binder_poll,
.unlocked_ioctl = binder_ioctl,
.mmap = binder_mmap,
.open = binder_open,
.flush = binder_flush,
.release = binder_release,
;
与 Ashmem 设备类似,最关键的是 binder_open()、binder_mmap()、binder_ioctl(),下面分别介绍这三个函数。
binder_open
用户应用程序通过 Binder 通信时,需先调用 binder_open() 方法打开 binder 驱动,binder_open() 中主要做了两个工作,对应的分为两部分来看:
//binder.c
static int binder_open(struct inode *nodp, struct file *filp)
struct binder_proc *proc;
...
proc = kzalloc(sizeof(*proc), GFP_KERNEL); //创建 binder_proc
if (proc == NULL)
return -ENOMEM;
get_task_struct(current);
proc->tsk = current;
INIT_LIST_HEAD(&proc->todo); //初始化 todo 队列
init_waitqueue_head(&proc->wait); //初始化 todo 队列
proc->default_priority = task_nice(current);
上面代码的主要工作是 创建及初始化 binder_proc,binder_proc 就是用来存放 binder 相关数据的结构体,每个进程独有一份。
binder_lock(__func__);
binder_stats_created(BINDER_STAT_PROC);
hlist_add_head(&proc->proc_node, &binder_procs);
proc->pid = current->group_leader->pid;
INIT_LIST_HEAD(&proc->delivered_death);
filp->private_data = proc;
binder_unlock(__func__);
...
第二个主要工作是 将 binder_proc 记录起来,方便后续使用,如上代码所示,通过 hlist_add_head() 方法将 binder_proc 记录到了内核的 binder_procs 表中,另外还将 binder_proc 存放在 filp 的 private_data 域,以便于在后续调用 mmap、ioctl 等方法时获取。
binder_mmap
对于 binder 驱动来说,上层应用调用的 mmap() 最终会执行到 binder_mmap() 方法,binder_mmap() 的主要工作是将上层应用的虚拟内存块和 Binder 申请的物理内存块建立映射,应用程序和 Binder 就拥有了共享的内存空间,这样不同的应用程序之间可以通过 Binder 实现数据共享。举个例子:
- Binder 中有一物理内存块 P;A 进程中有一内存块 a ;B 进程中有一内存块 b
- 将 P 分别与 a、b 建立映射,这样 a、b 就可以看作同一块内存
- 若 A 进程想要发送数据给 B 进程,只需将数据拷贝到 a 内存,B 进程就能直接读取到了
所以 Binder 只需一次拷贝,binder_mmap() 要做的就是将 P 与 a 建立映射,该方法代码较长,分段看关键部分代码:
static int binder_mmap(struct file *filp, struct vm_area_struct *vma)
struct vm_struct *area;
struct binder_proc *proc = filp->private_data;
const char *failure_string;
struct binder_buffer *buffer;
//映射空间至多 4M
if ((vma->vm_end - vma->vm_start) > SZ_4M)
vma->vm_end = vma->vm_start + SZ_4M;
//检查 vma 是否被禁用
if (vma->vm_flags & FORBIDDEN_MMAP_FLAGS)
ret = -EPERM;
failure_string = "bad vm_flags";
goto err_bad_arg;
- vma(vm_area_struct) 是用户态虚拟内存地址空间,也就是 a
- area(vm_struct) 是内核态虚拟地址空间,指向 P
- proc(binder_proc) 即 binder_open() 中创建的、存放 binder 相关数据的结构体
- 另外还做了限制映射空间至多 4M 等映射规则的检查和处理
mutex_lock(&binder_mmap_lock);
//检查是否已执行过 binder_mmap 映射过
if (proc->buffer)
ret = -EBUSY;
failure_string = "already mapped";
goto err_already_mapped;
//申请内核虚拟内存地址空间
area = get_vm_area(vma->vm_end - vma->vm_start, VM_IOREMAP);
if (area == NULL)
ret = -ENOMEM;
failure_string = "get_vm_area";
goto err_get_vm_area_failed;
//将内核虚拟内存地址记录在 proc 中
proc->buffer = area->addr;
//记录用户态虚拟内存地址和内核态虚拟内存地址的偏移量
proc->user_buffer_offset = vma->vm_start - (uintptr_t)proc->buffer;
mutex_unlock(&binder_mmap_lock);
- proc->buffer 用于存储最终映射的内核态虚拟地址,并通过此变量控制只能映射一次
- get_vm_area() 方法申请了与用户态空间大小一致的内核态虚拟地址空间,注意此时还没分配实际的物理内存
- proc->user_buffer_offset 记录了用户态虚拟内存和内核态虚拟内存地址的偏移量,这样后续方便获取用户态虚拟内存地址
//分配存放物理页地址的数组
proc->pages = kzalloc(sizeof(proc->pages[0]) * ((vma->vm_end - vma->vm_start) / PAGE_SIZE), GFP_KERNEL);
proc->buffer_size = vma->vm_end - vma->vm_start;
//申请一页物理内存
if (binder_update_page_range(proc, 1, proc->buffer, proc->buffer + PAGE_SIZE, vma))
ret = -ENOMEM;
failure_string = "alloc small buf";
goto err_alloc_small_buf_failed;
//最后的收尾工作:将内存记录到相应链表中,设置状态等
INIT_LIST_HEAD(&proc->buffers);
list_add(&buffer->entry, &proc->buffers);
buffer->free = 1;
binder_insert_free_buffer(proc, buffer);
proc->free_async_space = proc->buffer_size / 2;
proc->files = get_files_struct(current);
proc->vma = vma;
- proc->pages 是一个二维指针,用于存放管理物理页面
- binder_update_page_range() 方法真正的申请物理页面,并分别映射到内核态和用户态的虚拟内存地址空间
至此 binder_mmap 方法执行结束,书中并没有对 binder_update_page_range() 方法具体展开介绍,但个人认为此方法代码非常有助于我们理解页框以及与虚拟内存地址的映射逻辑,所以继续分析,先了解此方法的参数:
- proc:申请内存的进程所持有的 binder_proc 对象
- allocate:1 表示申请内存,0 表示释放内存
- start:虚拟内存地址起点
- end:虚拟内存地址终点
- vma:用户态虚拟内存地址空间
static int binder_update_page_range(struct binder_proc *proc, int allocate,
void *start, void *end,
struct vm_area_struct *vma)
if (allocate == 0) //区分是申请还是释放
goto free_range;
//依据 start、end 循环分配物理页
for (page_addr = start; page_addr < end; page_addr += PAGE_SIZE)
//每次分配 1 个页框*/
*page = **alloc_page**(GFP_KERNEL | __GFP_HIGHMEM | __GFP_ZERO);
//将页框映射到内核态虚拟内存地址
ret = **map_kernel_range_noflush**((unsigned long)page_addr, PAGE_SIZE, PAGE_KERNEL, page);
//根据 binder_mmap 方法中记录的偏移量计算出用户态虚拟内存地址
user_page_addr = (uintptr_t)page_addr + proc->user_buffer_offset;
//将页框映射到用户态虚拟内存地址
ret = vm_insert_page(vma, user_page_addr, page[0]);
return 0;
binder_mmap() 的 allocate 参数传入 1 为申请内存,执行上面的代码。若为释放则执行以下代码:
free_range:
//依据 start、end 从后往前遍历
for (page_addr = end - PAGE_SIZE; page_addr >= start; page_addr -= PAGE_SIZE)
page = &proc->pages[(page_addr - proc->buffer) / PAGE_SIZE];
if (vma)
//解除用户态虚拟地址和物理页框的映射
zap_page_range(vma, (uintptr_t)page_addr + proc->user_buffer_offset, PAGE_SIZE, NULL);
err_vm_insert_page_failed:
//解除内核态虚拟地址和物理页框的映射
unmap_kernel_range((unsigned long)page_addr, PAGE_SIZE);
err_map_kernel_failed:
//释放页框物理内存
__free_page(*page);
*page = NULL;
binder_ioctl
binder 驱动并不提供常规的 read()、write() 等文件操作,全部通过 binder_ioctl() 实现,所以 binder_ioctl() 是 binder 驱动中工作量最大的一个,它承担了 binder 驱动的大部分业务。这里不深入分析源码,只列出 binder_ioctl() 支持的命令列表:
| 命令 | 说明 |
|---|---|
| BINDER_WRITE_READ | 向 binder 驱动写入或读取数据 |
| BINDER_SET_MAX_THREADS | 设置支持的最大线程数 |
| BINDER_SET_CONTEXT_MGR | Service Manager 专用的注册命令 |
| BINDER_THREAD_EXIT | 通知 binder 驱动某线程退出,释放相应资源 |
| BINDER_VERSION | 获取 Binder 版本号 |
其中 BINDER_WRITE_READ 最为关键,分为若干子命令:
| 命令 | 说明 |
|---|---|
| BC_INCREFS、BC_ACQUIRE、BC_RELEASE、BC_DECREFS | 管理 binder_ref 的引用计数 |
| BC_INCREFS_DONE、BC_ACQUIRE_NODE | 管理 binder_node 的引用计数 |
| BC_FREE_BUFFER | 释放 Binder 内存缓冲区 |
| BC_TRANSACTION | 向 binder 驱动发送通信数据(主动调用) |
| BC_REPLY | 向 binder 驱动发送通信数据(返回结果) |
| BC_REGISTER_LOOPER、BC_ENTER_LOOPER、BC_EXIT_LOOPER | 设置 Binder looper 状态 |
| BC_REQUEST_DEATH_NOTIFICATION | 注册 Binder 死亡通知 |
| BC_CLEAR_DEATH_NOTIFICATION | 清除 Binder 死亡通知 |
| BC_DEAD_BINDER_DONE | 告知 Binder 已处理完 Binder 死亡通知 |
以上均为 binder 驱动作为接收方 binder_ioctl() 方法接收的命令,还有一些与之对应的 BR_ 开头的命令,由 binder 驱动主动发出,比如 BR_TRANSACTION、BR_REPLY,在一次 IPC 调用中是这样应用的:
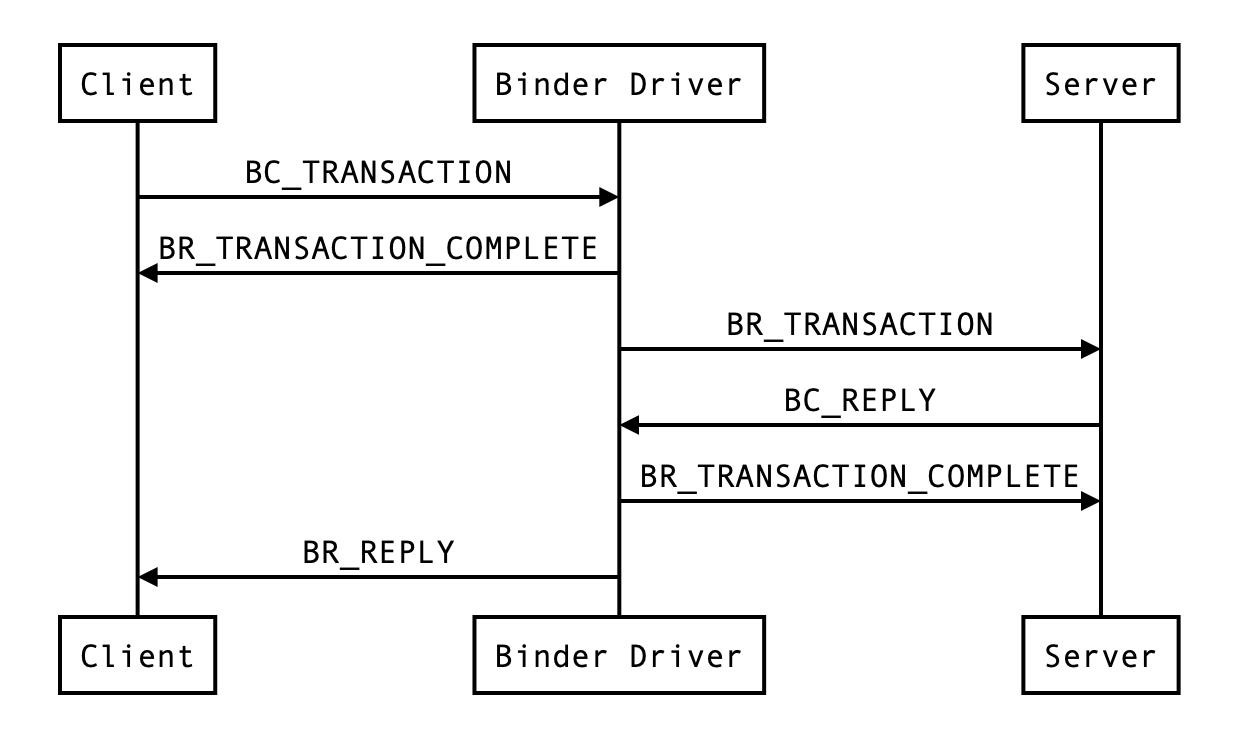
Service Manager
Service Manager 是为了完成 Binder Server Name(域名)和 Service Handle(IP 地址)之间对应关系的查询而存在的,可以推测它主要包含的功能:
注册:当一个 Binder Server 创建后,应该将这个 Server 的 name 和 Handle 对应关系记录到 Service Manager 中
查询:其他应用可以根据 Server 的 name 查询到对应的 Service Handle
启动
Android 系统第一个启动的 init 进程解析 init.rc 脚本时构建出系统的初始运行状态,Android 系统服务程序大多是在这个脚本中描述并被相继启动的,包括 zygote、mediaserver、surfaceflinger 以及 servicemanager 等,其中 servicemanager 描述如下:
#init.rc
service servicemanager /system/bin/servicemanager
class core
user system
group system
critical
onrestart restart healthd
onrestart restart zygote
onrestart restart media
onrestart restart surfaceflinger
onrestart restart drm
可以看到,当 servicemanager 发生问题重启时,其他 healthd、zygote、media 等服务也会被重启。servicemanager 服务启动后执行 service_manager.c 的 main 函数,关键代码如下:
//frameworks/native/cmds/servicemanager/service_manager.c
int main()
struct binder_state *bs;
bs = binder_open(128*1024);
if (binder_become_context_manager(bs))
ALOGE("cannot become context manager (%s)\\n", strerror(errno));
return -1;
...
binder_loop(bs, svcmgr_handler);
return 0;
其中三个函数对应了 servicemanager 初始化的三个关键工作:
- binder 驱动并映射内存块大小为 128KB :binder_open()
- 将自己设置为 Binder “DNS” 管理者 :binder_become_context_manager()
- 进入循环,等待 binder 驱动发来消息 :binder_loop()
下面分别来分析这三个函数,binder_open() 关键代码如下:
struct binder_state *binder_open(size_t mapsize)
struct binder_state *bs;
struct binder_version vers;
bs = malloc(sizeof(*bs));
...
//打开 binder 驱动,最终调用 binder_open() 函数
bs->fd = open("/dev/binder", O_RDWR | O_CLOEXEC);
...
//获取 Binder 版本,最终调用 binder_ioctl() 函数
ioctl(bs->fd, BINDER_VERSION, &vers)
...
//将虚拟内存映射到 Binder,最终调用 binder_mmap() 函数
bs->mapped = mmap(NULL, mapsize, PROT_READ, MAP_PRIVATE, bs->fd, 0);
...
return bs;
binder_become_context_manager() :
int binder_become_context_manager(struct binder_state *bs)
//发送 BINDER_SET_CONTEXT_MGR 命令,最终调用 binder_ioctl() 函数
return ioctl(bs->fd, BINDER_SET_CONTEXT_MGR, 0);
binder_loop() 关键代码如下:
void binder_loop(struct binder_state *bs, binder_handler func)
int res;
//执行 BINDER_WRITE_READ 命令所需的数据格式:
struct binder_write_read bwr;
uint32_t readbuf[32]; //每次读取数据的大小
readbuf[0] = BC_ENTER_LOOPER;
//先将 binder 驱动的进入循环命令发送给 binder 驱动:
binder_write(bs, readbuf, sizeof(uint32_t));
for (;;) //进入循环
bwr.read_size = sizeof(readbuf);
bwr.read_buffer = (uintptr_t) readbuf; //读取到的消息数据存储在 readbuf
//执行 BINDER_WRITE_READ 命令读取消息数据
res = ioctl(bs->fd, BINDER_WRITE_READ, &bwr);
if (res < 0)
ALOGE("binder_loop: ioctl failed (%s)\\n", strerror(errno));
break;
//处理读取到的消息数据
res = binder_parse(bs, 0, (uintptr_t) readbuf, bwr.read_consumed, func);
...
BINDER_WRITE_READ 命令既可以用来读取数据也可以写入数据,具体是写入还是读取依赖 binder_write_read 结构体的 write_size 和 read_size 哪个大于 0,上面代码通过 bwr.read_size = sizeof(readbuf) 赋值,所以是读取消息。
binder_parse() 方法内部处理由 binder 驱动主动发出的、一系列 BR_ 开头的命令,包括上面提到过的 BR_TRANSACTION、BR_REPLY 等,简化后的代码如下:
int binder_parse(struct binder_state *bs, struct binder_io *bio,
uintptr_t ptr, size_t size, binder_handler func)
switch(cmd)
case BR_TRANSACTION:
...
res = func(bs, txn, &msg, &reply); //处理消息
//返回处理结果
inder_send_reply(bs, &reply, txn->data.ptr.buffer, res);
...
break;
case BR_REPLY: ...
case BR_DEAD_BINDER: ...
...
对于 BR_TRANSACTION 命令主要做了两个工作,一是调用 func() 具体处理消息;二是调用 inder_send_reply() 将消息处理结果告知给 binder 驱动,注意这里的 func 是由 service_manager.c main 函数中传过来的方法指针,也就是 svcmgr_handler() 方法。
注册与查询
经过上面 Service Manager 服务启动的过程分析,已经知道由 binder 驱动主动发过来的 BR_TRANSACTION 命令最终在 service_manager.c 的 svcmgr_handler() 方法中处理,那服务的注册与查询请求想必就是在这个方法中实现的了,确实如此,简化后的关键代码如下:
int svcmgr_handler(struct binder_state *bs,
struct binder_transaction_data *txn,
struct binder_io *msg,
struct binder_io *reply)
switch(txn->code)
case SVC_MGR_GET_SERVICE:
case SVC_MGR_CHECK_SERVICE:
//查询服务,根据 name 查询 Server Handle
handle = do_find_service(s, len, txn->sender_euid, txn->sender_pid);
return 0;
case SVC_MGR_ADD_SERVICE:
//注册服务,记录服务的 name(下面的参数 s) 与 handle
if (do_add_service(bs, s, len, handle, txn->sender_euid,
allow_isolated, txn->sender_pid))
return -1;
break;
case SVC_MGR_LIST_SERVICES:
//查询所有服务,返回存储所有服务的链表 svclist
si = svclist;
while (以上是关于细读《深入理解 Android 内核设计思想》Binder 机制 [上]的主要内容,如果未能解决你的问题,请参考以下文章