分布式系统下的纠删码技术 -- Erasure Code (EC)
Posted Z-Pilgrim
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了分布式系统下的纠删码技术 -- Erasure Code (EC)相关的知识,希望对你有一定的参考价值。
近几个月主要参与一个分布式存储系统的纠删码部分(用于数据容错),纠删码在学术界出现比较早,现在ceph,微软的存储系统,Hadoop 3.0等都用了EC。文章会分为多篇,主要将Erasure Code,LRC, 以及相关的数学基础,作为学习总结。
一、纠删码简介
分布式系统需要在硬件失效等故障发生后仍然能继续提供服务。就数据而言,HDFS采用每份数据3副本的方式,保证某些数据损失之后仍能继续使用。
数据的容错除了副本还有另一种做法,就是把丢失的数据计算出来。这就是纠删码的思想了。(PS: Spark的数据也可以通过计算恢复,详见spark论文)。
与副本相比,纠删码的优点在于节省存储空间(见下文解释),缺点在于有计算开销而且修复需要一定时间,而副本损失只要复制出来损失的数据,未损失的数据可以继续提供服务。
二、Erasure Codes(EC)原理
1、朴素的解释
有下列6个方程组成的方程组
(1)x1 = 1
(2)x2 = 2
(3)x3 = 3
(4)x1 + x2 + x3= 6
(5)x1 + 2*x2 +4*x3 = 17
(6)x1 + 3*x2 +9*x3 = 34
要知道x1,x2,x3三个数的值,只需要上面任意三个方程即可解出来。假设有上面4个方程,有趣的地方出现了,如果丢了一个方程,那么仍然可以用其他三个方程求出x1,x2, x3的值。相当于只多了一个方程就能解决x1,x2,x3任何一个数的值丢失的问题。
把上面的方程(1)(2)(3)看做是分布式系统的数据,(4)(5)(6)看做是code,那么只要一个code,即使丢了(1)(2)(3)中的任何一个数据都是可以恢复的, 达到这样的效果只需要存储4个方程。 如果采取副本策略,要达到(1)(2)(3)丢失任何一个数据都能恢复的话,只要把(1)(2)(3)三个方程都存储两份,也就是存储了6个方程。于是纠删码比副本策略在存储效率上的优势就体现出来,4/6的比值,节省1/3的空间。实际根据code的多少,存储效率会不一样。
2、存储系统中的符号约定
k:数据块的个数
m:校验块的个数(就是code)
n:k+m,也就是数据块和校验块的个数总和。
编码效率:r = k/m
上面的解释是参照Jerasure库的代码解释的,IntelEC库符号表示不同,但是意义一样,不再赘述。
3、现有的EC库
(1)Jerasure库
http://jerasure.org/
(2)Intel EC库
http://www.intel.com/content/www/us/en/storage/erasure-code-isa-l-solution-video.html
实际实验发现,(1)线程不安全,(2)线程安全(本人简单看过一部分代码+1000线程并发测试)
尚未面世的Hadoop 3.0据说要使用EC编码。查资料发现用的应该也是英特尔库。本人近日工作是基于英特尔的EC库封装LRC库, 也就是线程安全的LRC(见后文)。
三、模拟EC编码、解码(恢复)的例子
假设4个data块,2个Code块。
1、编码
通用的编码矩阵:
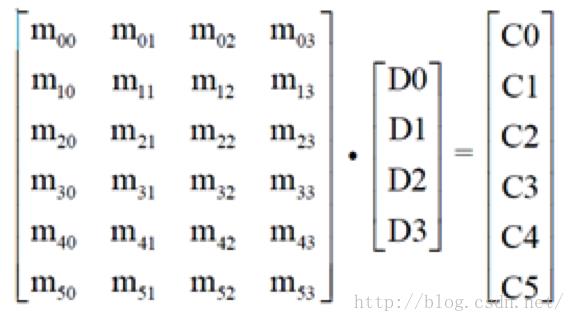
4个data块,2个Code块情况下,编码过程如下:

(a)
Code块是:
C0=D0+D1+D2+D3
C1=D0+2*D1+4*D2+8*D3
图1 EC编码过程
编码矩阵如上图,Di表示数据块,Ci表示校验块。编码矩阵(encodematrix)组成有两部分,上面是k*k的单位矩阵,下面是m*k的编码矩阵,如图是范德蒙矩阵,Jerasure库用的是范德蒙矩阵,Intel EC提供了范德蒙矩阵和柯西矩阵的实现,奇怪的是Intel EC说范德蒙不一定可逆,柯西一定可逆,所以本人在用Intel EC的时候一直用柯西矩阵。(为什么需要可逆见下文:解码)。
2、解码
解码粗浅理解就是未损失的数据块和校验块乘以编码矩阵的逆矩阵可以得到原来的数据。大部分博客感觉也就是能让人有这种粗浅的感觉,所以本文写得更详细一点。
以4个data块,2个Code块的情况的解码来解释,当code的块数为2时,最多坏掉两块数据块(按照解方程就是四元一次方程,至少4个才能解出来四个元的值)。此处假设一个数据块D1和一个code块C0丢失
解码过程分为两步:
(1)根据已有的数据求解出所有的Data块, D0 ~ D3
更具体而言,顺序遍历编码矩阵的前n行,顺序选取没有损坏的前k行(意思是该行对应的数据块或者校验块没有损坏)。生成k*k的矩阵 M。本例中M矩阵如下:
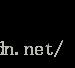
编码encode的时候这几行发生了下面的事情:
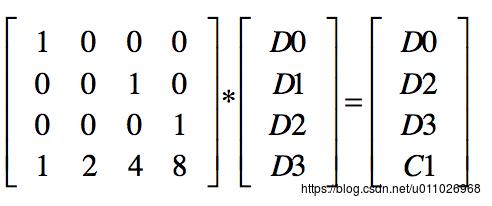 (b)
(b)
(注:等号右边应该是D0 D2 D3 C1,因为我们假定D1和C0坏掉了)
所以解码的时候,有D0 D2 D3 C1 以及M,很显然可以通过求M的逆矩阵来求出D0D1 D2D3 :
 (c)
(c)
(2)求出损失的数据
(1)中已经求出来了所有的数据块的内容,而且编码矩阵是知道的,因此可以求出所有的数据,对于本例子,其实是在(c)式子两边同时乘以一个矩阵来求出C0,矩阵很简单,就是相应的编码矩阵的部分:
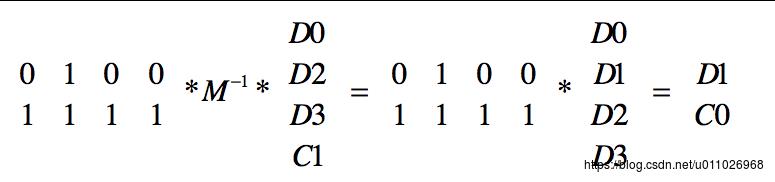
于是就求出来了丢失的数据D1和Code C0
结合Intel EC的源码简单再讲下decode生成解码矩阵decodematrix的过程:
| (1)顺序遍历编码矩阵的前n行,顺序选取没有损坏的前k行(意思是该行对应的数据块或者校验块没有损坏)。生成k*k的矩阵 M。 (2)求M的逆矩阵 M_inv (后续文章讲怎么求) (3)求解码矩阵decode matrix,解码矩阵构成: a) 损失的数据块:损失的数据所在的行对应的M_inv的行复制到decode matric b)直接上代码…
|
Decode matrix的构成的代码:
nsrcerrs就是数据块的损失的个数;
nerrs是总的(数据块加上校验块)损失的个数;
invert_matrix就是上面说的M_inv ;
src_err_list是失效的数据块对应的行的下标(idx);
Gf_mul以及下面的异或符号,简单说下就是EC的矩阵运算都是在有限域进行的。 直接把异或理解成加法, 把gf_mul理解成乘法,然后下面的循环看成矩阵运算很容易明白了…
| for (i = 0; i < nsrcerrs; i++) for (j = 0; j < k; j++) decode_matrix[k * i + j] = invert_matrix[k * src_err_list[i] + j];
/* src_err_list from encode_matrix * invert of b for parity decoding */ for (p = nsrcerrs; p < nerrs; p++) for (i = 0; i < k; i++) s = 0; for (j = 0; j < k; j++) s ^= gf_mul(invert_matrix[j * k + i], encode_matrix[k * src_err_list[p] + j]);
decode_matrix[k * p + i] = s;
|
3、编码矩阵需要满足的性质
从上面的过程可以看出,编码矩阵必须可逆,否则无法解码,也就无法恢复数据。
k*k的范德蒙矩阵可逆的简单证明(保研狗,就大一学过线代,如果出错的话求指教):
| (1) 范德蒙的性质之一是有求行列式的式子:
式子来源: (https://zh.wikipedia.org/wiki/%E8%8C%83%E5%BE%B7%E8%92%99%E7%9F%A9%E9%99%A3)
(2) 对于我们用的范德蒙矩阵,ai=i (i = 1,2,3…)
所以任意两行ai和aj一定不一样,也就是det(V) 不为0 (3)行列式的值不为0等价于矩阵可逆。 证毕。(略羞耻,因为(1)直接用的人家的结论。也可以从满秩的角度很容易证明)
|

所以当数据损失之后,选取k*k的矩阵,一定可逆,也就可以继续解码。
四、编码类型
1、编码方式
(1)横式编码(horizontalcodes)
这种编码方式下,code数据块单独uoweie数据块,而不是和data块放在一起。例如EVENODD编码,RDP编码都是横式编码。
(2)纵式编码(verticalcodes)
code存储在数据所在的磁盘,某些块既有数据又有code。如X-code编码。
2、RS编码
RS编码是唯一可以满足任意的数据磁盘数目(n)和冗余磁盘数目(m)的MDS(maximum distance separable)的编码方法。解码重构的原理推到中,有一个重要的条件,就是未出错的信息所对应的残余生成矩阵在GF(2w)上满足可逆。
(1) 范德蒙RS编码
范德蒙矩阵满足上述的“可逆”的条件。
(2) 柯西RS编码
柯西矩阵满足上述的“可逆”的条件。
与范德蒙RS编码区别就在于用柯西矩阵代替范德蒙行列式,并且有位运算的方法可以对柯西RS编码中的乘法进行改进,转化为二进制乘法,整个RS编码的运算可以转化为只包含异或的简单运算。(此部分待补充)
五、分布式系统的工程实现
1、简单实现方案
(1)编码
在创建数据块以及数据块远远未写满的情况下,使用副本策略做数据容错。当若干数据块(比如k个数据块)都基本写满,则禁止对这些数据块做写(包括修改、删除)等操作。此时进行编码,当编码成功时,删除冗余的数据块副本。此时就从副本策略变成纠删码策略。
(2)解码
a)一个线程定期扫描数据,比如对数据块和校验块做crc校验,如果发现有数据块或者校验块失效,则启动恢复线程。
b)恢复线程先根据EC组现有的数据情况,从远程或本地获取必要的数据进行解码,恢复失效数据。
2、EC的一些优化策略
本人参与的项目遇到了这种情况。最初在解码前未损失的数据都拉到本地,然后恢复数据。后来发现这样是多余的。于是只顺序拉去必要的数据块。实际如果肯修改相应的EC库的代码,还可以有其他选择策略,比如选择同一机房,同一机器不同磁盘的数据用于恢复(这个时候构造的解码矩阵也有一定变化,需要做相应修改,详见本文的解码矩阵的生成过程)。
参考及相关资料:
Hadoop EC的一个实现:
https://sourceforge.net/projects/hadoop-ec/
http://blog.cloudera.com/blog/2016/02/progress-report-bringing-erasure-coding-to-apache-hadoop/
以上是关于分布式系统下的纠删码技术 -- Erasure Code (EC)的主要内容,如果未能解决你的问题,请参考以下文章