搜索引擎模块设计与实现——分片模块
Posted Dreamchaser追梦
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了搜索引擎模块设计与实现——分片模块相关的知识,希望对你有一定的参考价值。
文章目录
前言
之前参加了字节青训营后端进阶班,我们选择的题目是搜索引擎,临近ddl,故有此文。
GoDance是一款用go语言编写的分布式搜索引擎,同时也是一款分布式文档数据库。支持分布式搜索以及分布式存储功能,对外提供restful Api接口来操作GoDance。
一、设计目标
- 保证文档数据可以以分片形式分布在各个节点
- 支持搜索任何节点,返回对应的查询数据
- 支持水平拓展
- 支持分片副本,保证分布式情况下的高可用
二、设计方案
分片模块的基本原理就是将文本数据切割成n个小份存储在不同的节点上,减少大文件存储在单个节点上对设备带来的压力
分片是一个功能完整的搜索引擎,它拥有使用一个节点上的所有资源的能力
以下借鉴于ES对于分片的设计
正常(绿色):主分片和副分片都能正常工作
预警(黄色):某个或某些副分片没有达到指定数量,但查询操作可以正常工作
报警(红色):集群不可正常使用。某个或某些分片及其副本异常不可用,这时集群的查询操作还能执行,但是返回的结果会不准确;对于分配到这个分片的写入请求将会报错,最终会导致数据的丢失
1.分片角色
每个分片包含一部分文档数据以及对应的正排索引和倒排索引
主分片
主分片负责数据的写入
副本分片
- 冗余存储,用于备份。在集群中某个节点宕掉后,通过副本可以快速对缺失数据进行复盘
- 可支持查询功能,分担压力
2.分片规则
- 主分片和对应的副本分片是不会在同一个节点上的,所以副本分片数的最大值是 n -1(其中n为节点数)
- 写操作都是在主分片上完成,完成之后才能被复制到相关的副本分片(这个阶段是并发完成的)
- 副本分片和写分片都可以支持查询操作
2.分片方式
2.1 分布式id
打算采用UUID方式生成。
暂时采用该id作为分片的特征值
2.2 hash function+rangehash
分片方式如下图

图左是range partition,右是hash partition。range partition就是使用字段本身作为分片的边界,比如上图的x;而hash partition会将字段重新hash到一个更大、更离散的值域区间。
3.分片路由
不同分片路由
当文档查询api落在某一节点上时,如果仅仅是根据id查文档则对文档id进行hash区域,计算涉及到的分片,再将请求转发到其他分片。
同分片路由
当确定好要转发的分片时,还需要决定转发到分片中的那个副本当中。
这里大致采用轮询的策略来进行负载均衡路由
一些优化
数据查询操作的搜索效率很大程度上取决于索引是否在内存中以及存储索引的数据结构。
就拿倒排索引来讲,每个数据结构都有自己的特点,比如:
-
Hashmap查找速度快,但是空间使用多
-
而Fst这种充分复用了前缀和后缀使其空间消耗达到最小,但相应的查找效率就变低了
基于此,我们针对每个节点的负载情况(索引内存加载率来衡量存储策略)有针对性的采用不同的策略,比如:
-
在数据量小的时候,内存空间充足的情况下,我们使用hashmap进行存储倒排索引
-
当内存吃紧时,首先先将部分正排索引持久化;还是吃紧时,我们再将倒排索引陆续转化为FST
-
当全部都是FST时还是内存吃紧,此时我们需要将部分索引删除(持久化操作已经陆续变成段文件了)
同时用一个内存索引加载率来衡量分片的负载状态,在后期也可以用一个可视化界面查看集群中节点的负载情况,便于管理者水平拓展设备。
简而言之,就是根据当前节点的负载情况去有针对性的改变存储策略,并将负载情况通过心跳RPC近实时地返回给Leader,而这也为上层优化提供可能。
我们会对分片的负载情况进行打分,分数越高,说明该分片的索引在内存中就越多,查询效率越高,时延越小,此时作为协调者的节点会优先将请求转发到这种分片上。
4.分片迁移
当节点宕机时,会进行分片迁移,尽量将宕机节点中的主分片和副分片迁移到负载比较小的节点
4.1 水平扩容
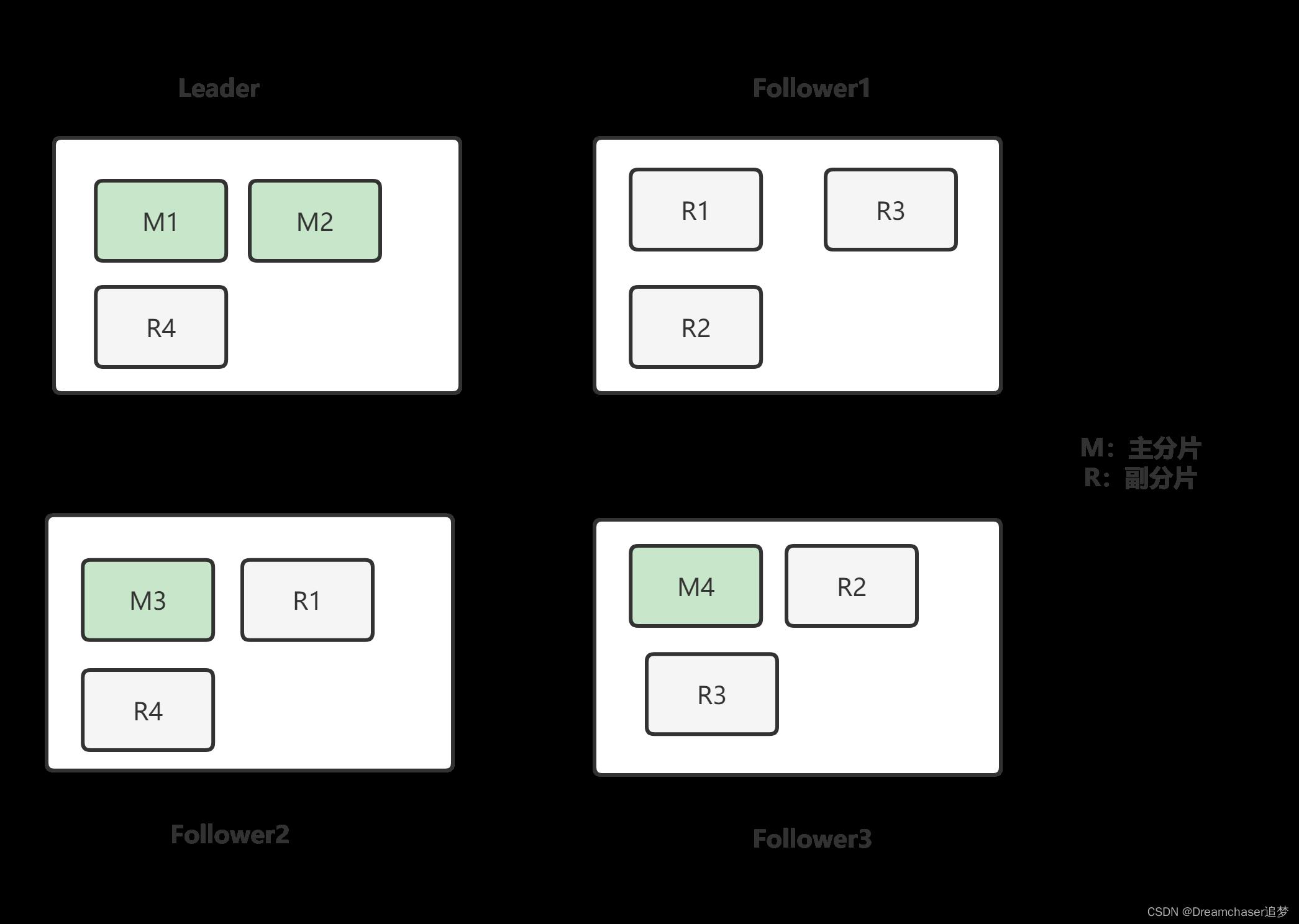

在水平增加一个节点后,部分节点会将部分分片转移到新的节点上,这个过程是由Leader来调配的。
这里分片的选择会综合考虑各节点的负载状况,优先从负载高的节点进行转移,尽量让各个节点的负载状况相近。
在细节实现上,主要分为三个节点:发送转移RPC,应用增加分片日志,应用删除分片日志。
分片过程如下(A向B转移分片):
- Leader向要节点A发送分片转移PRC
- 节点A收到后生成一个快照,向目标节点B转移分片文件
- 目标节点B收到后,向Leader发起转移成功RPC调用
- Leader向集群执行增加分片的状态修改的流程,若大多数成功,则成功
- 成功后Leader执行删除分片状态日志
- 当该删除日志提交后,其他节点需要将该日志提交到状态机,而节点A提交时不仅要提交状态机,还要删除该分片文件和内存索引
4.2 节点故障与恢复
一个节点故障时,提升对应副本分片为主分片(只是修改集群状态,这个过程是瞬间发生的)

当节点故障时,会在meta中移除,当故障超过一定时间,会分配一个新的Replica到新的Node上,此时需要全量同步数据。
如果之前故障的Replica回来了,就可以只回补故障之后的数据,追平后加回来即可,实现快速故障恢复。
实现快速故障恢复的条件有两个,一个是能够保存故障期间所有的操作以及其顺序,另一个是能够知道从哪个点开始同步数据。第一个条件可以通过保存一定时间的Translog实现,第二个条件可以通过Checkpoint实现,所以就能够实现快速的故障恢复。
5.文档数据写入
从大的角度来看,写入流程为先写入Primary,再并发写入Replica,等待所有Replica响应(或连接失败)后返回最后应答客户端
- 检查Active的Shard数(wait_for_active_shards,默认为1)
- 写入Primary
- 并发写入Replica
- 等待所有Replica响应
- 失败尝试重试
- 最终返回客户端成功多少个,失败多少个
如果一个Replica写失败了,Primary会将这个信息报告给Master,然后Master会在Meta中更新这个Index的InSyncAllocations配置,将这个Replica从中移除,移除后它就不再承担读请求

6.数据查询
对于非特征值(这里默认id)的查询,需要去查询所有的分片,然后由接受客户端请求的节点进行聚合返回。
对于特征值的查询,可以根据分片的规则,查询涉及到分片即可。
7.分片特性
- 数据高可靠:数据具有多个副本
- 服务高可用:Primary挂掉之后,可以从Replica中选出新的Primary提供服务
- 读能力扩展:Primary和Replica都可以承担读请求
- 故障恢复能力:Primary或Replica挂掉都会导致副本数不足,此时可以由新的Primary通过复制数据产生新的副本
PS:目前方案有所欠缺,很多细节并未补全,有些方案的选定,比如分布式id生成、分片方式等都有待商榷。但由于ddl将近,所以先发出来,以后将会根据自身情况再做修改
以上是关于搜索引擎模块设计与实现——分片模块的主要内容,如果未能解决你的问题,请参考以下文章