lstm in caffe
Posted 机器学习的小学生
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了lstm in caffe相关的知识,希望对你有一定的参考价值。
// Message that stores parameters used by RecurrentLayer
message RecurrentParameter
// The dimension of the output (and usually hidden state) representation --
// must be explicitly set to non-zero.
optional uint32 num_output = 1 [default = 0];
optional FillerParameter weight_filler = 2; // The filler for the weight
optional FillerParameter bias_filler = 3; // The filler for the bias
// Whether to enable displaying debug_info in the unrolled recurrent net.
optional bool debug_info = 4 [default = false];
// Whether to add as additional inputs (bottoms) the initial hidden state
// blobs, and add as additional outputs (tops) the final timestep hidden state
// blobs. The number of additional bottom/top blobs required depends on the
// recurrent architecture -- e.g., 1 for RNNs, 2 for LSTMs.
optional bool expose_hidden = 5 [default = false];
from caffe import layers as L, params as P, to_proto
import caffe
# some utility functions
def add_layer_to_net_spec(ns, caffe_layer, name, *args, **kwargs):
kwargs.update('name':name)
l = caffe_layer(*args, **kwargs)
ns.__setattr__(name, l)
return ns.__getattr__(name)
def add_layer_with_multiple_tops(ns, caffe_layer, lname, ntop, *args, **kwargs):
kwargs.update('name':lname,'ntop':ntop)
num_in = len(args)-ntop # number of input blobs
tops = caffe_layer(*args[:num_in], **kwargs)
for i in range(ntop):
ns.__setattr__(args[num_in+i],tops[i])
return tops
# implement single time step LSTM unit
def single_time_step_lstm( ns, h0, c0, x, prefix, num_output, weight_names=None):
"""
see arXiv:1511.04119v1
"""
if weight_names is None:
weight_names = ['w_'+prefix+nm for nm in ['Mxw','Mxb','Mhw']]
# full InnerProduct (incl. bias) for x input
Mx = add_layer_to_net_spec(ns, L.InnerProduct, prefix+'lstm/Mx', x,
inner_product_param='num_output':4*num_output,'axis':2,
'weight_filler':'type':'uniform','min':-0.05,'max':0.05,
'bias_filler':'type':'constant','value':0,
param=['lr_mult':1,'decay_mult':1,'name':weight_names[0],
'lr_mult':2,'decay_mult':0,'name':weight_names[1]])
Mh = add_layer_to_net_spec(ns, L.InnerProduct, prefix+'lstm/Mh', h0,
inner_product_param='num_output':4*num_output, 'axis':2, 'bias_term': False,
'weight_filler':'type':'uniform','min':-0.05,'max':0.05,
'bias_filler':'type':'constant','value':0,
param='lr_mult':1,'decay_mult':1,'name':weight_names[2])
M = add_layer_to_net_spec(ns, L.Eltwise, prefix+'lstm/Mx+Mh', Mx, Mh,
eltwise_param='operation':P.Eltwise.SUM)
raw_i1, raw_f1, raw_o1, raw_g1 = \\
add_layer_with_multiple_tops(ns, L.Slice, prefix+'lstm/slice', 4, M,
prefix+'lstm/raw_i', prefix+'lstm/raw_f', prefix+'lstm/raw_o', prefix+'lstm/raw_g',
slice_param='axis':2,'slice_point':[num_output,2*num_output,3*num_output])
i1 = add_layer_to_net_spec(ns, L.Sigmoid, prefix+'lstm/i', raw_i1, in_place=True)
f1 = add_layer_to_net_spec(ns, L.Sigmoid, prefix+'lstm/f', raw_f1, in_place=True)
o1 = add_layer_to_net_spec(ns, L.Sigmoid, prefix+'lstm/o', raw_o1, in_place=True)
g1 = add_layer_to_net_spec(ns, L.TanH, prefix+'lstm/g', raw_g1, in_place=True)
c1_f = add_layer_to_net_spec(ns, L.Eltwise, prefix+'lstm/c_f', f1, c0, eltwise_param='operation':P.Eltwise.PROD)
c1_i = add_layer_to_net_spec(ns, L.Eltwise, prefix+'lstm/c_i', i1, g1, eltwise_param='operation':P.Eltwise.PROD)
c1 = add_layer_to_net_spec(ns, L.Eltwise, prefix+'lstm/c', c1_f, c1_i, eltwise_param='operation':P.Eltwise.SUM)
act_c = add_layer_to_net_spec(ns, L.TanH, prefix+'lstm/act_c', c1, in_place=False) # cannot override c - it MUST be preserved for next time step!!!
h1 = add_layer_to_net_spec(ns, L.Eltwise, prefix+'lstm/h', o1, act_c, eltwise_param='operation':P.Eltwise.PROD)
return c1, h1, weight_names
def exmaple_use_of_lstm():
T = 3 # number of time steps
B = 10 # batch size
lstm_output = 500 # dimension of LSTM unit
# use net spec
ns = caffe.NetSpec()
# we need initial values for h and c
ns.h0 = L.DummyData(name='h0', dummy_data_param='shape':'dim':[1,B,lstm_output],
'data_filler':'type':'constant','value':0)
ns.c0 = L.DummyData(name='c0', dummy_data_param='shape':'dim':[1,B,lstm_output],
'data_filler':'type':'constant','value':0)
# simulate input X over T time steps and B sequences (batch size)
ns.X = L.DummyData(name='X', dummy_data_param='shape': 'dim':[T,B,128,10,10] )
# slice X for T time steps
xt = L.Slice(ns.X, name='slice_X',ntop=T,slice_param='axis':0,'slice_point':list(range(1,T)))
# unroling
h = ns.h0
c = ns.c0
lstm_weights = None
tops = []
for t in range(T):
c, h, lstm_weights = single_time_step_lstm(ns, h, c, xt[t], 't'+str(t)+'/', lstm_output, lstm_weights)
tops.append(h)
ns.__setattr__('c'+str(t),c)
ns.__setattr__('h'+str(t),h)
# concat all LSTM tops (h[t]) to a single layer
ns.H = L.Concat( *tops, name='concat_h',concat_param='axis':0 )
return ns
ns = exmaple_use_of_lstm()
with open('lstm_demo.prototxt','w') as W:
W.write('name: "LSTM using NetSpec example"\\n')
W.write('%s\\n' % ns.to_proto())
lisa-caffe-public-lstm_video_deploy.zip
name: "lstm_joints"
layer
name: "data"
type: "Python"
top: "data"
top: "label"
top: "clip_markers"
python_param
module: "sequence_input_layer"
layer: "videoReadTrain_RGB"
layer
name: "conv1"
type: "Convolution"
bottom: "data"
top: "conv1"
param
lr_mult: 1
decay_mult: 1
param
lr_mult: 2
decay_mult: 0
convolution_param
num_output: 96
kernel_size: 7
stride: 2
weight_filler
type: "gaussian"
std: 0.01
bias_filler
type: "constant"
value: 0.1
layer
name: "relu1"
type: "ReLU"
bottom: "conv1"
top: "conv1"
layer
name: "pool1"
type: "Pooling"
bottom: "conv1"
top: "pool1"
pooling_param
pool: MAX
kernel_size: 3
stride: 2
layer
name: "norm1"
type: "LRN"
bottom: "pool1"
top: "norm1"
lrn_param
local_size: 5
alpha: 0.0001
beta: 0.75
layer
name: "conv2"
type: "Convolution"
bottom: "norm1"
top: "conv2"
param
lr_mult: 1
decay_mult: 1
param
lr_mult: 2
decay_mult: 0
convolution_param
num_output: 384
kernel_size: 5
group: 2
stride: 2
weight_filler
type: "gaussian"
std: 0.01
bias_filler
type: "constant"
value: 0.1
layer
name: "relu2"
type: "ReLU"
bottom: "conv2"
top: "conv2"
layer
name: "pool2"
type: "Pooling"
bottom: "conv2"
top: "pool2"
pooling_param
pool: MAX
kernel_size: 3
stride: 2
layer
name: "norm2"
type: "LRN"
bottom: "pool2"
top: "norm2"
lrn_param
local_size: 5
alpha: 0.0001
beta: 0.75
layer
name: "conv3"
type: "Convolution"
bottom: "norm2"
top: "conv3"
param
lr_mult: 1
decay_mult: 1
param
lr_mult: 2
decay_mult: 0
convolution_param
num_output: 512
pad: 1
kernel_size: 3
weight_filler
type: "gaussian"
std: 0.01
bias_filler
type: "constant"
value: 0.1
layer
name: "relu3"
type: "ReLU"
bottom: "conv3"
top: "conv3"
layer
name: "conv4"
type: "Convolution"
bottom: "conv3"
top: "conv4"
param
lr_mult: 1
decay_mult: 1
param
lr_mult: 2
decay_mult: 0
convolution_param
num_output: 512
pad: 1
kernel_size: 3
group: 2
weight_filler
type: "gaussian"
std: 0.01
bias_filler
type: "constant"
value: 0.1
layer
name: "relu4"
type: "ReLU"
bottom: "conv4"
top: "conv4"
layer
name: "conv5"
type: "Convolution"
bottom: "conv4"
top: "conv5"
param
lr_mult: 1
decay_mult: 1
param
lr_mult: 2
decay_mult: 0
convolution_param
num_output: 384
pad: 1
kernel_size: 3
group: 2
weight_filler
type: "gaussian"
std: 0.01
bias_filler
type: "constant"
value: 0.1
layer
name: "relu5"
type: "ReLU"
bottom: "conv5"
top: "conv5"
layer
name: "pool5"
type: "Pooling"
bottom: "conv5"
top: "pool5"
pooling_param
pool: MAX
kernel_size: 3
stride: 2
layer
name: "fc6"
type: "InnerProduct"
bottom: "pool5"
top: "fc6"
param
lr_mult: 1
decay_mult: 1
param
lr_mult: 2
decay_mult: 0
inner_product_param
num_output: 4096
weight_filler
type: "gaussian"
std: 0.01
bias_filler
type: "constant"
value: 0.1
layer
name: "relu6"
type: "ReLU"
bottom: "fc6"
top: "fc6"
layer
name: "drop6"
type: "Dropout"
bottom: "fc6"
top: "fc6"
dropout_param
dropout_ratio: 0.9
layer
name: "reshape-data"
type: "Reshape"
bottom: "fc6"
top: "fc6-reshape"
reshape_param
shape
dim: 16
dim: 24
dim: 4096
layer
name: "reshape-label"
type: "Reshape"
bottom: "label"
top: "reshape-label"
reshape_param
shape
dim: 16
dim: 24
layer
name: "reshape-cm"
type: "Reshape"
bottom: "clip_markers"
top: "reshape-cm"
reshape_param
shape
dim: 16
dim: 24
layer
name: "lstm1"
type: "LSTM"
bottom: "fc6-reshape"
bottom: "reshape-cm"
top: "lstm1"
recurrent_param
num_output: 256
weight_filler
type: "uniform"
min: -0.01
max: 0.01
bias_filler
type: "constant"
value: 0
layer
name: "lstm1-drop"
type: "Dropout"
bottom: "lstm1"
top: "lstm1-drop"
dropout_param
dropout_ratio: 0.5
layer
name: "fc8-final"
type: "InnerProduct"
bottom: "lstm1-drop"
top: "fc8-final"
param
lr_mult: 10
decay_mult: 1
param
lr_mult: 20
decay_mult: 0
inner_product_param
num_output: 101
weight_filler
type: "gaussian"
std: 0.01
bias_filler
type: "constant"
value: 0
axis: 2
layer
name: "loss"
type: "SoftmaxWithLoss"
bottom: "fc8-final"
bottom: "reshape-label"
top: "loss"
softmax_param
axis: 2
需要注意的是:fc8-final 和 loss层有个axis=2的参数。
prototxt可视化:
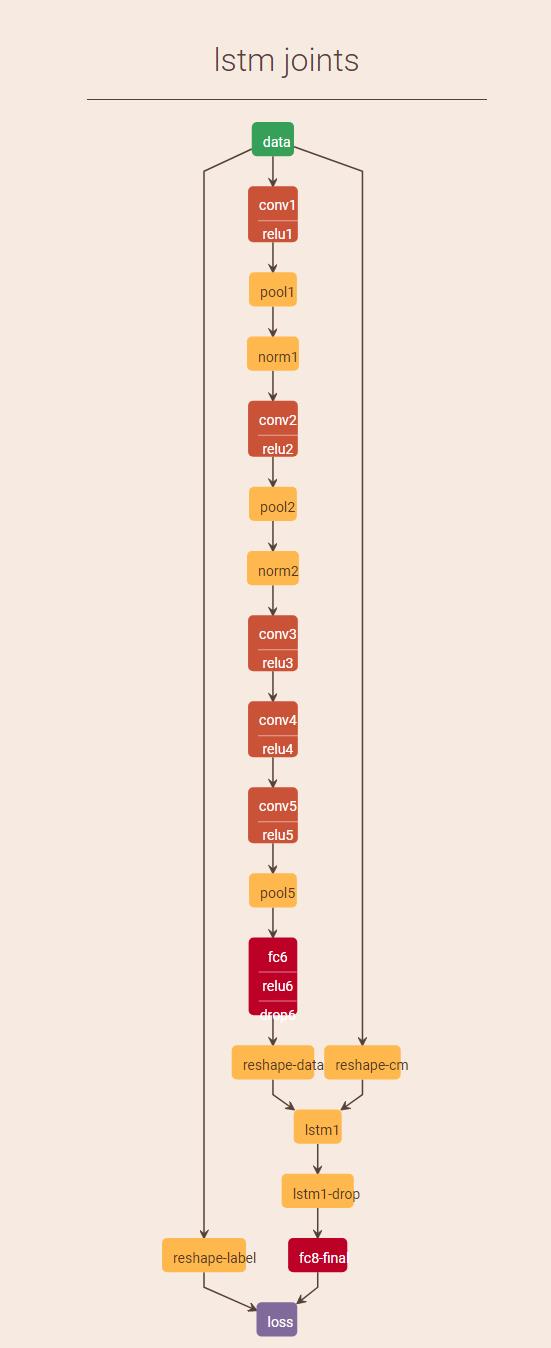
检查协议中的blobs形状:
loss1[it] = mysolver.net.blobs['loss'].data.copy()
data = mysolver.net.blobs['data'].data.copy()
fc6 = mysolver.net.blobs['fc6'].data.copy()
label = mysolver.net.blobs['label'].data.copy()
clip_markers = mysolver.net.blobs['clip_markers'].data.copy()
fc6_reshape = mysolver.net.blobs['fc6-reshape'].data.copy()
reshape_label = mysolver.net.blobs['reshape-label'].data.copy()
reshape_cm = mysolver.net.blobs['reshape-cm'].data.copy()
lstm1 = mysolver.net.blobs['lstm1'].data.copy()
fc8_final = mysolver.net.blobs['fc8-final'].data.copy()
# 24 the number of video , train_buffer
# 16 the length of processed clip, train_frames
print('data: ', data.shape)
print('fc6: ', fc6.shape)
print('label: ', label.shape)
print('clip_markers: ', clip_markers.shape)
print('fc6_reshape: ',fc6_reshape.shape)
print('reshape_cm: ',reshape_cm.shape)
print('lstm1: ',lstm1.shape)
print('reshape_label: ',reshape_label.shape)
print('fc8-final: ',fc8_final.shape)
print('shape over...')
exit(-1)
输出结果:
('data: ', (384L, 3L, 227L, 227L))
('fc6: ', (384L, 4096L))
('label: ', (384L,))
('clip_markers: ', (384L,))
('fc6_reshape: ', (16L, 24L, 4096L))
('reshape_cm: ', (16L, 24L))
('lstm1: ', (16L, 24L, 256L))
('reshape_label: ', (16L, 24L))
('fc8-final: ', (16L, 24L, 101L))
shape over...
参考文献:
- https://blog.csdn.net/mounty_fsc/article/details/53114698 [(Caffe)LSTM层分析]
- https://stackoverflow.com/questions/32225388/lstm-module-for-caffe# [代码来自于该网址]
以上是关于lstm in caffe的主要内容,如果未能解决你的问题,请参考以下文章