Linux命令之文本分析工具awk
Posted 二木成林
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Linux命令之文本分析工具awk相关的知识,希望对你有一定的参考价值。
概述
awk 命令是一个强大的文本分析工具,把文件逐行的读入,以空格为默认分隔符将每行切片,切开的部分再进行分析处理。

awk 认为文件都是由单词和各种空白字符组成。 空白字符包括空格、TAB、连续的空格、连续的TAB 域。非空白部分从左到右依次是第一个域、第二个域等等。$1 表示第 1 个域,$2 表示第 2 个域,$0 表示所有域。
语法
该命令的语法如下:
# 其中 pattern 表示 awk 在数据中查找的内容,就是匹配模式,支持正则表达式
# 其中 action 表示是在找到匹配内容时所执行的一系列命令,action 中多条命令之间通过分号分隔
awk [选项] ‘/pattern1/action1 /pattern2/action2...’ 文件名
该命令支持的选项有:
| 选项 | 说明 |
|---|---|
| -F fs | 指定输入文件分隔符 |
| -v var=val | 赋值一个用户定义变量 |
| -f file | 从脚本文件中读取 awk 脚本指令,以取代直接在命令行中输入指令 |
awk 命令支持的常见内置变量(即可以直接使用的变量)有:
| 内置变量 | 说明 |
|---|---|
| FILENAME | 文件名 |
| NR | 已读的记录数,即行号 |
| NF | 浏览记录的域的个数(切割后,列的个数) |
会自动给一行中的每个数据元素分配一个变量。awk 命令默认情况下会将如下变量分配给它在文本行中发现的数据字段(在 awk 中,默认的字段分隔符是任意的空白字符,例如空格或制表符。 在文本行中,每个数据字段都是通过字段分隔符划分的。awk 在读取一行文本时,会用预定义的字段分隔符划分每个数据字段。):
$0代表整个文本行;$1代表文本行中的第 1 个数据字段;$2代表文本行中的第 2 个数据字段;$n代表文本行中的第 n 个数据字段。
awk 还提供了两种打印输出的函数 print 和 printf:
print:其中print函数的参数可以是变量、数值或者字符串。字符串必须用双引号引用,参数用逗号分隔。如果没有逗号,参数就串联在一起而无法区分。printf:其用法和c语言中printf基本相似,可以格式化字符串,输出复杂时,printf更加好用,代码更易懂。
注:只有成功匹配了
pattern的行才会执行action。
使用
示例 1
搜索 /etc/passwd 文件中以 root 关键字开头的所有行,并输出改行的第 7 列。命令如下:
awk -F ":" '/^root/print $7' /etc/passwd
说明如下:
-F ":":表示指定各列之间的分隔符是冒号:。'/^root/print $7':其中^root表示匹配以root开始的行;print $7表示对于前面查找到的行然后输出第 7 列,其中print表示打印输出,$7表示第七列。
示例 2
搜索 /etc/passwd 文件以 root 关键字开头的所有行,并输出该行的第 1 列和第 7 列,中间以 "," 号分割。命令如下:
awk -F ":" '/^root/print $1","$7' /etc/passwd
说明如下:
-F ":":表示指定各列之间的分隔符是冒号:。'/^root/print $1","$7':其中^root表示匹配以root开始的行;print $1","$7中表示输出第 1 列和第 7 列,中间用逗号进行分隔。
注意:如果要连接其他字符串,必须用双引号括起来,但是
$1这些变量又不能使用双引号。所以"$1,$7"属于错误语法。
示例 3
只显示 /etc/passwd 文件中的第 1 列和第 7 列,以逗号进行分隔,且在所有行前面添加列名 user, shell,在最后一行添加 zhangsan, /bin/csh。命令如下:
awk -F ":" 'BEGINprint "user, shell" print $1", "$7 ENDprint "zhangsan, /bin/csh"' /etc/passwd
 说明如下:
说明如下:
-F ":":表示指定各列之间的分隔符是冒号:。BEGINprint "user, shell":表示在所有行之前执行输出user, shell的操作。print $1", "$7:表示输出第 1 列和第 7 列,之间通过逗号分隔。ENDprint "zhangsan, /bin/csh":表示在最后一行执行输出zhangsan, /bin/csh。
注:
BEGIN表示在所有数据读取行之前执行;END表示在所有数据执行之后执行。
示例 4
将 /etc/passwd 文件中的用户 ID 增加数值 1 之后再输出。命令格式如下:
awk -v i=1 -F ":" 'print $3+i' /etc/passwd
 说明如下:
说明如下:
-v i=1:表示声明一个变量i并且初始值为 1。-F ":":表示指定各列之间的分隔符是冒号:。'print $3+i':表示将第 3 列的值与变量i的值相加后输出。
注:在进行变量运算时,直接使用变量名即可,不需要使用
$i的方式来引用变量值。
示例 5
统计 /etc/passwd 文件中的文件名、每行的行号和每行的列数。命令格式如下:
awk -F ":" 'print "文件名:"FILENAME", 行号:"NR", 列数:"NF' /etc/passwd
 说明如下:
说明如下:
'print "文件名:"FILENAME", 行号:"NR", 列数:"NF':表示输出文件名、行号和列数。其中FILENAME是内置变量,存放了文件名;NR是内置变量,存放了当前行号;NF是内置变量,存放了当前行的列数。注意,输出字符串必须用双引号""引起来,但是变量不能引起来。
示例 6
输出 ifconfig 命令输出结果中的空行所在行号。命令格式如下:
ifconfig | awk '/^$/print NR'
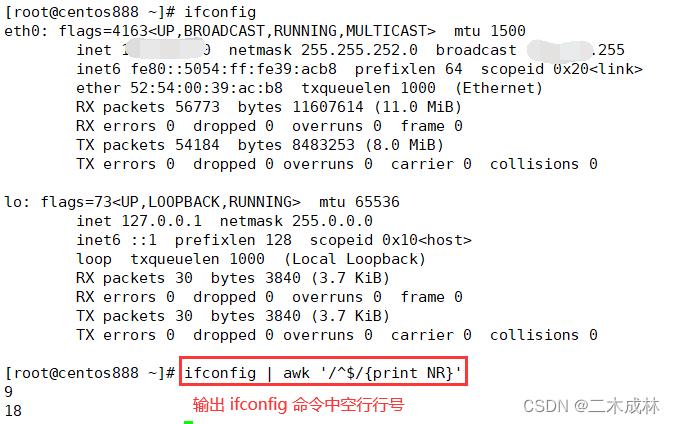 说明如下:
说明如下:
'/^$/print NR':表示找到空白行并输出空白行的行号。其中^$是正则表达式表示匹配空白行;print NR表示输出前面匹配到的行的行号。
示例 7
输出当前系统中网卡的 IP 地址。命令格式如下:
ifconfig | awk '/netmask/print $2'

说明:
ifconfig:该命令查看当前系统的网络信息。awk '/netmask/print $2':表示找到行中包含netmask的行,因为包含这个字符串的行中也包含 IP 地址;print $2表示打印第 2 列,即 IP 地址列。
示例 8
替换字符串 "I am zhangsan" 中的 zhangsan 为 lisi。命令格式如下:
echo "I am zhangsan" | awk '$3="lisi"; print $0'

以上是关于Linux命令之文本分析工具awk的主要内容,如果未能解决你的问题,请参考以下文章