Elasticsearch:随机采样器聚合 - Random sampler aggregation
Posted Elastic 中国社区官方博客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Elasticsearch:随机采样器聚合 - Random sampler aggregation相关的知识,希望对你有一定的参考价值。
random_sampler 聚合是一个单桶聚合,它在聚合结果中随机包含文档。 采样以准确性为代价提供了显着的速度改进。
抽样是通过在分片中提供整个文档集的随机子集来完成的。 如果在搜索请求中提供了过滤器查询,则该过滤器将应用于采样子集。 因此,如果过滤器是有限制性的,则可能只有很少的文档匹配; 因此,统计数据可能不那么准确。
警告:此功能处于技术预览阶段,可能会在未来版本中更改或删除。 Elastic 将尽最大努力解决任何问题,但技术预览版中的功能不受官方 GA 功能的支持 SLA 约束。
注意:不要将此聚合与 sampler aggregation 相混淆。 Sampler aggregation 不是针对所有文档的; 相反,它对查询匹配的前 n 个文档进行采样。
这是 Elastic Stack 8.2 发行版的一个新功能。下面,我将以 Elastic Stack 8.2 来进行展示。
准备数据
我们首先按照我之前的教程 “Kibana:Kibana 入门 (一)” 加载其中的 eCommerce 数据集。
展示
我们使用如下的一个命令来做一个查询:
GET kibana_sample_data_ecommerce/_search?track_total_hits=false
"size": 0,
"aggs":
"price_percentiles":
"percentiles":
"field": "taxful_total_price"
在上面,我们采用正常的聚合。特别指出的是我们设置了 track_total_hits 为 false。这样做的目的就是为了避免返回所有的数据。了解详情,可以阅读文章 “Elasticsearch:如何在搜索时得到精确的总 hits 数”。
上面的命令返回的结果为:
"took" : 14,
"timed_out" : false,
"_shards" :
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
,
"hits" :
"max_score" : null,
"hits" : [ ]
,
"aggregations" :
"price_percentiles" :
"values" :
"1.0" : 21.984375,
"5.0" : 27.984375,
"25.0" : 44.96875,
"50.0" : 63.96875,
"75.0" : 93.07937402037618,
"95.0" : 156.0,
"99.0" : 222.0
如果我们的数据集非常大,那么上面的聚合可能需要很长的时间才能得出一个答案。
为了能够提高聚合的速度,特别是针对大的数据集来说,我们可以采取牺牲一定的精确度来换取速度。在下面,我们使用 random sampler aggregation 来进行展示:
GET kibana_sample_data_ecommerce/_search?track_total_hits=false
"size": 0,
"aggregations":
"sampling":
"random_sampler":
"probability": 0.1
,
"aggs":
"price_percentiles":
"percentiles":
"field": "taxful_total_price"
首先,我们对上面的才是做一些说明:
- probability:必需,浮点数)文档将包含在聚合数据中的概率。 必须大于 0、小于 0.5 或正好 1。概率越低,匹配的文档越少。
- seed:(可选,整数)生成文档随机抽样的种子。 当提供种子时,文档的随机子集在调用之间是相同的。
在上面,我们设置了 probability 为 0.1,也就是一个非常小的数值,也即匹配的文档比较少。我们执行上面命令的结果为:
"took" : 1,
"timed_out" : false,
"_shards" :
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
,
"hits" :
"max_score" : null,
"hits" : [ ]
,
"aggregations" :
"sampling" :
"seed" : 241138887,
"probability" : 0.1,
"doc_count" : 456,
"price_percentiles" :
"values" :
"1.0" : 19.044375000000002,
"5.0" : 27.284375,
"25.0" : 45.96875,
"50.0" : 70.734375,
"75.0" : 97.0,
"95.0" : 152.7,
"99.0" : 204.7
显然它的结果和我们之前的结果还是有一点的差异,但是总体来说还是比较接近。我们再次运行,我们可以看到不同的结果:
"took" : 0,
"timed_out" : false,
"_shards" :
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
,
"hits" :
"max_score" : null,
"hits" : [ ]
,
"aggregations" :
"sampling" :
"seed" : -508530078,
"probability" : 0.1,
"doc_count" : 424,
"price_percentiles" :
"values" :
"1.0" : 19.984375,
"5.0" : 28.984375,
"25.0" : 43.96875,
"50.0" : 61.96875,
"75.0" : 92.0,
"95.0" : 160.0,
"99.0" : 221.15999999999985
显然,我们可以看到数据的随机性。当然为了提高统计的精确性,我们可以设置 probabilty 为一个较高一点的数值,比如 0.4:
GET kibana_sample_data_ecommerce/_search?track_total_hits=false
"size": 0,
"aggregations":
"sampling":
"random_sampler":
"probability": 0.4
,
"aggs":
"price_percentiles":
"percentiles":
"field": "taxful_total_price"
执行上面的命令:
"took" : 2,
"timed_out" : false,
"_shards" :
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
,
"hits" :
"max_score" : null,
"hits" : [ ]
,
"aggregations" :
"sampling" :
"seed" : -549167567,
"probability" : 0.4,
"doc_count" : 1858,
"price_percentiles" :
"values" :
"1.0" : 21.984375,
"5.0" : 27.984375,
"25.0" : 45.96875,
"50.0" : 64.99,
"75.0" : 93.5965909090909,
"95.0" : 154.77499999999998,
"99.0" : 219.92000000000007
显然这次的结果和之前没有使用 randon sampler aggregation 的结果非常近似。
它是如何工作的?
聚合是索引中所有文档的随机样本。 换句话说,采样是在背景文档集上进行的。 如果提供了查询,则如果与查询匹配并且文档在随机抽样中,则返回文档。 不是对匹配的文档进行抽样。
考虑一组文档 [1, 2, 3, 4, 5]。 你的查询匹配 [1, 3, 5] 并且随机抽样的集合是 [2, 4, 5]。 在这种情况下,返回的文档将是 [5]。
这种类型的采样提供了与采样减少文档集大小的数量相关的查询延迟几乎线性的改进:
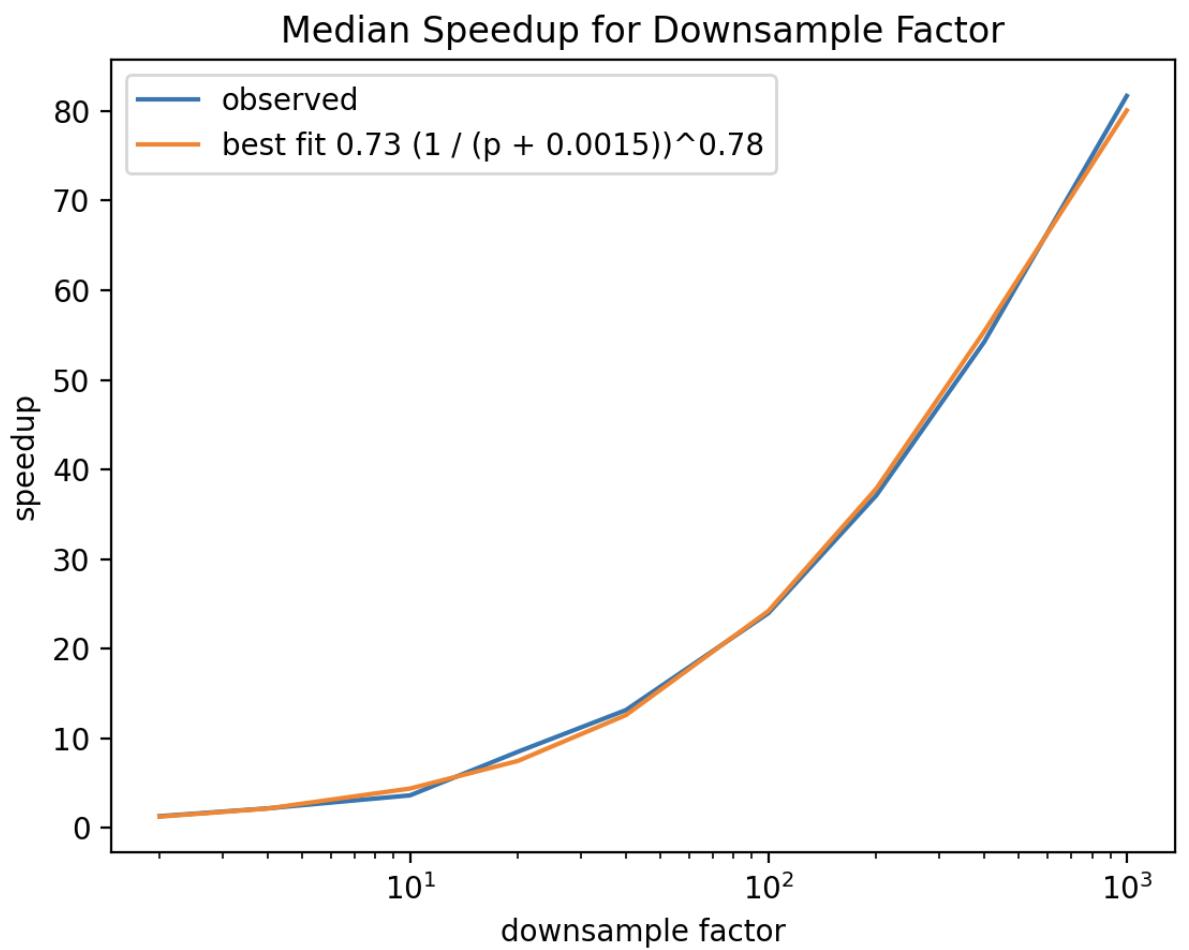
该图是 6300 万个文档的测试数据集的大多数聚合的典型加速。确切的常数将取决于数据集的大小和分片的数量,但加速和概率之间的关系形式广泛存在。对于某些聚合,加速可能没有那么显着。这些聚合具有一些与看到的文档数量无关的恒定开销。即使对于这些聚合,速度改进也可能很显着。
样本集是通过使用几何分布 ((1-p)^(k-1)*p) 跳过文档生成的,成功概率是提供的概率(分布方程中的 p)。从分布返回的值指示在后台跳过多少文档。这相当于随机均匀地选择文档。因此,成功之前的预期失败次数为 (1-p)/p。例如,使用 “probability”:0.01,预期的失败数(或跳过的平均文档数)将为 99,方差为 9900。因此,如果你的索引中只有 80 个文档或与你的过滤器匹配,你很可能不会收到任何结果。
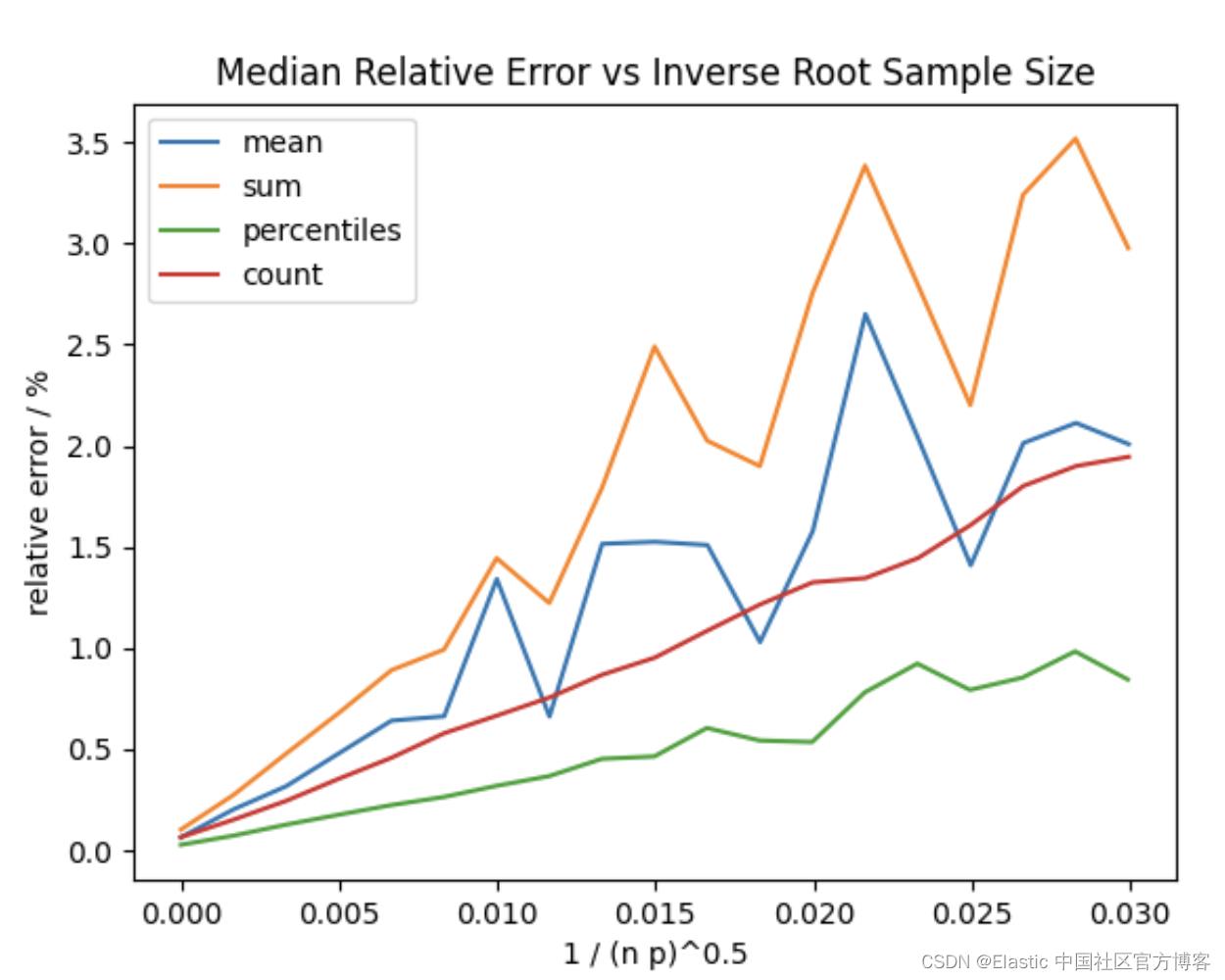
在上图中,p 是提供给聚合的概率,n 是提供的任何查询匹配的文档数。 你可以看到异常值对 sum 和 mean 的影响,但是当许多文档仍然以较高的采样率匹配时,相对误差仍然很低。
参考:
【1】Random sampler aggregation | Elasticsearch Guide [master] | Elastic
 开发者涨薪指南
开发者涨薪指南
 48位大咖的思考法则、工作方式、逻辑体系
48位大咖的思考法则、工作方式、逻辑体系
以上是关于Elasticsearch:随机采样器聚合 - Random sampler aggregation的主要内容,如果未能解决你的问题,请参考以下文章