PolarDB-X 2.1 新版本发布 让“MySQL 原生分布式”触手可及
Posted 阿里云云栖号
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了PolarDB-X 2.1 新版本发布 让“MySQL 原生分布式”触手可及相关的知识,希望对你有一定的参考价值。
PolarDB-X 2.1 新版本发布
让“MySQL 原生分布式”触手可及
——黄贵(曲山)阿里云数据首席架构师
了解更多PolarDB-X 内容:
https://developer.aliyun.com/topic/polardbx_release
PolarDB-X 2.1 是 PolarDB-X 非常重要的版本,也是第一次 PolarDB-X 分布式数据库的产品可以作为企业级的分布式数据库真正部署到客户的生产环境使用。
一、一个好的mysql分布式数据库应该是什么样的

C++语言设计的概念 Zero Overhead Abstraction ——0负担抽象原则,它有两个重要特性:
- 无须为不用的特性付出代价: C 类用户升级到 C++ 时,如果不使用 C++里的高级特性,则无须为这些特性付出额外的代价。比如在 C 里面是 structure,到 C++ 里可能是class 。对于 C 中的 structure 和 C++ 中的 class ,如果不带 virtual function ,则在内存布局的性能消耗上是等同的,不用付出额外的代价。
- 你所使用的代码,不可能手写得更好:如果想要使用更高级的特性,用 C++ 扩展的能力,一定比手写的代码更好,即C++ 提供的语言特性能够很好地帮助到用户。
C 语言的用户升级到 C++,必然是因为它带来了更新更强的能力,比如封装、抽象的能力,可以做继承、有多态。另外,C++ 提供了多种编程范式,比如面向对象、泛型编程、函数式编程等,这些特性都可以极大地拓展语言的抽象,带来能力的提升。
同理,从单机的 MySQL 数据库升级到分布式 MySQL 数据库,我们期望它能有哪些表现?
首先是完全兼容,可以由单机平滑过渡到分布式系统,无需对应用进行改造;第二,无需对数据库的结构进行改造;第三,不使用分布式能力则无须付出额外的开销。
单机到分布式最重要的变化是数据会分布在多个节点上,对于数据库中很多操作而言,尤其是事务,是需要付出一些额外代价的。如果事务涉及到多个数据的分区,而只是想将分布式系统作为单机数据库来用,同样也可以有单表的特性,无须付出分布式事务的代价。
升级到分布式系统后能够获得自动伸缩的能力,能够天然地利用分布式的特性实现跨地域的高可用,还可以处理混合的负载类型,包括事务的负载以及分析的负载,提供了高性价比的解决方案。
二、让分布式能力透明化
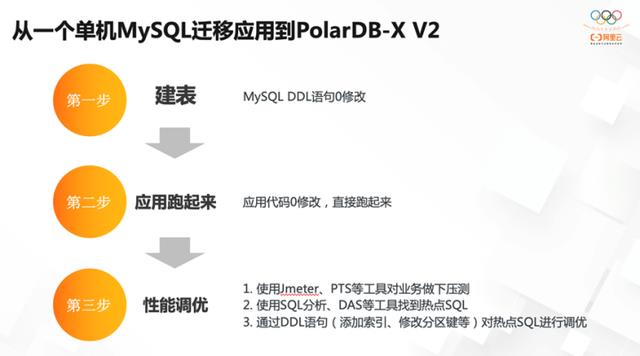
如何实现从单机到分布式完全透明化?
以从单机 MySQL 迁移到 PolarDB-X 2.1 版本为例:
第一步:建表。使用单机 MySQL 上的建表语句、DDL语句在新的分布式数据库上建表,无须做任何修改。
第二步:让应用跑起来。应用代码也无须做任何修改,原有的 SQL 语法、原有的客户端驱动程序都可以直接使用,只需要更换新的数据库连接地址。
第三步:性能调优。可以使用很多工具做压测,包括一些可视化工具,能够提供对整个系统 SQL 性能的分析, DAS自动调优工具能够帮助找到热点SQL,还可以通过 DDL 建新的索引或对数据分区进行调整,对热点 SQL 进行调优。
实现以上整个过程的大部分操作只是诊断和适配,无须进行过多改造工作。
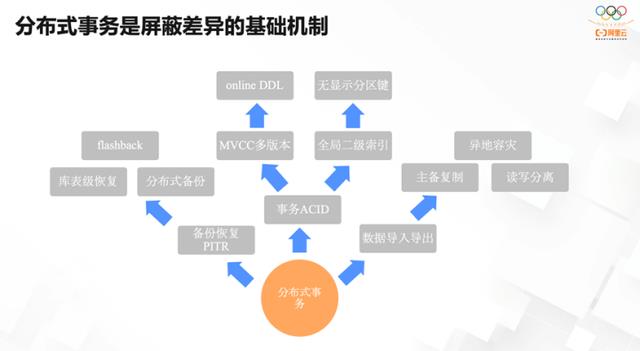
对于分布式系统而言,要做到透明,核心就是对分布式事务的支持。分布式数据库与单机数据库的关键差异在于,分布式数据库是以一定的规则将数据做分片,然后分布在多个节点上,其中核心点在于如何在事务跨了多个数据分片时,保证它的 ACID 语义。这其中会涉及到如何做事务的 ACID 保证,如何做多版本处理并发的控制。有了事务 ACID 的保证,才能在此之上建立全局二级索引。
此外,很多其他功能比如备份恢复、时间回溯的查询以及分布式的备份等,都需要依赖分布式事务提供的全局一致性能力。数据的导入和导出也需要保证数据有全局快照的能力,在任何时间点都能读到一致的版本。
有了全局二级索引和多版本的并发控制等能力的支持,即可实现透明的分布式,无须显式地指定分区键,只需要像单机数库一样创建表,即能默认做数据的分区,也无须考虑数据分区带来的跨节点事务的处理。表的修改操作和Online DDL 也不会对数据库的其他操作产生影响。
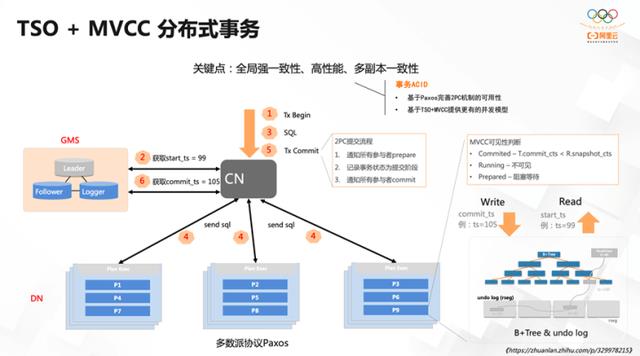
PolarDB-X 实现的是全局一致性的分布式事务
(使用 TSO全局 timestamp)+ MVCC (多版本并发控制机制)实现的分布式数据库。主要的技术原理是基于 Paxos 做事务日志的同步来保证高可用。
在事务在处理的过程中,因为使用了两阶段提交的方式来做分布式事务的处理,如果发生了节点失效,也可以利用 Paxos 带来的高可用能力保证事务继续进行下去。
另外,使用了全局唯一的时间戳以及多版本并发控制的机制来保证它的隔离性,实现了 Snapshot Isolation 的隔离级别。
具体流程如下:GMS 组件提供全局事务的时间戳,在发起事务的过程中,如果事务要做提交,则会获取提交的时间戳并将其带到所有下面存储节点的参与者上。然后结合事务当前的状态,根据时间戳判断事务的可见性。每一条数据上都有其提交的时间戳,将其与当前事务的时间戳做比较,以决定这条数据在当前的事务中是否可见。
通过上述机制即可实现分布式事务的全局一致性和快照隔离。
本次 2.1 版本发布的最重要的功能就是自动模式数据库的功能。PolarDB-X 在 1.0 版本时代,是利用分库分表的模式来进行数据的自动分区。 2.0 的时代引入了全新的 AUTO 模式数据库,无需指定分区键。
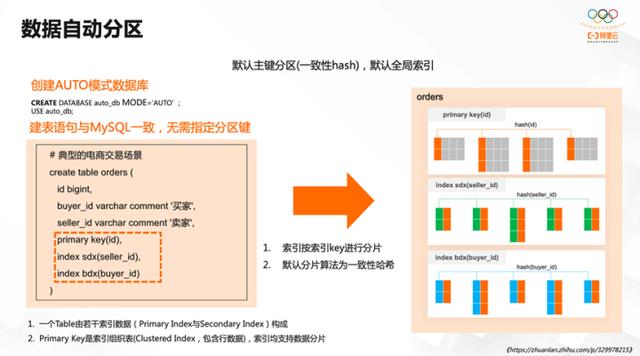
上图展示了典型的电商交易场景,有交易记录表,其主键是事务 ID ,还有买家和卖家两个重要角色。对于交易的流水而言,通常除了按交易的流水日志 ID 查询以外,也有可能从买/卖家的维度查询。
表内可能有上亿条记录,需要将它创建为分区表。对于分布式数据库 PolarDB-X 而言,无需指定特定的分区键。因为这里的分区健,如果是按照buyer_id或者seller_id去查询,无法做分区裁剪。可以像使用单机数据库一样默认按主键 ID 做数据的分片。分片的算法默认是一致性哈希,也支持很多其他算法,包括 interval 做范围的划分、 range 的分区等,此类算法也可以通过 DDL 语句根据业务特点做调整,另外还可以通过多个查询维度建全局二级索引。
上图例子中建了两个全局二级索引,分别是买家 ID 和卖家 ID 。往表里面插入数据的时候,会针对数据根据数据的分区规则,将它均匀地分布在数据节点上。上图右侧两张索引表同样也按照分区规则做了均匀的分布。
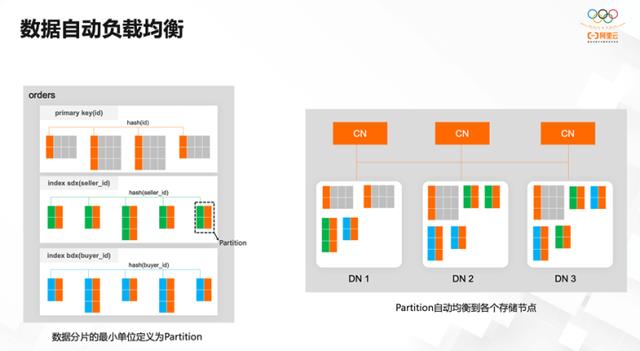
数据自动负载均衡的功能,使得用户无需关心数据具体分布在哪个数据节点上,可由系统自动完成,主表以及两张索引表都按照一定的规则做数据的拆分,分片以后按照数据的大小和容量均匀分布到各个数据节点上。
有了自动负载均衡的能力以后,也就具备了在线扩缩容的能力,而在线扩缩容是单机到分布式平滑演进的重要基础。
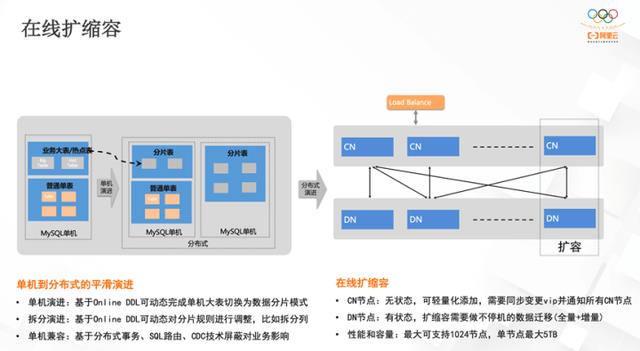
上图有计算层的 CN 节点,也有存储层的 DN 节点。 CN 节点是无状态节点,扩容和缩容非常轻量化,因为所有 CN 的能力都对等,将 SQL 发送到任意 CN 节点都可以实现同样的处理能力,得到相同的结果。出于性能的考虑,一般会将数据就近调度到临近的 CN 节点上。
因此,CN 的扩容非常方便,只需简单地将 CN 节点添加到集群上,同步到 GMS 节点里即可。
DN 是有状态的数据节点,扩缩容需要做数据的迁移。增加了一组数据节点后,调度任务管理器会根据当前数据的分布状况,将一部分数据迁移到新的数据节点上,以此保证所有节点的数据处在均衡的分布状态。
性能和容量方面,PolarDB-X 最大可以支持 1024 个节点,单节点最大存储 5TB 数据,能够满足大部分数据库的容量需求。
缩容同理,下线数据节点后,会将它缺失的副本补足,然后重新均匀分布到其他数据节点上。
从单机数据库迁移到分布式数据库,可以基于 Online DDL 的能力动态完成单机大表切换到数据分片的模式。比如原来在单机上非常大的表,希望通过分布式系统的数据分布能力对其进行拆分,可以通过一些 DDL 的能力动态地修改其分区模式,来完成单表到数据分布表的转换。
对于单机分布式而言,PolarDB-X 完全兼容了 MySQL 的语义及其行为,包括上下游对接的生态,比如全局 CDC 可以生成全局一致的 Binlog,可以将其作为单机 MySQL 的日志流来使用。不管是同步到下游大数据系统,还是作为 MySQL 的备份,都可以通过 CDC 来对接。

Online DDL 最大的特点就是在做 DDL 的过程中对当前数据库正在处理的业务 DML 语句没有任何影响,极大减轻了数据库运维人员的负担。数据库难免会遇到一些修改表结构、增加点索引等诉求,如果每次都要在业务的低峰期去进行,对运维会造成很大困扰,而且不够及时。有了 Online DDL的支持以后,可以在任意时间点做变更。这些变更包括了创建索引、加减列、变更分区算法。
值得一提的是,加列操作使用了 Instant DDL 机制,可以只修改元数据,无须对全部数据进行修改,操作性能极高,为毫秒级,对业务的影响可以缩减到最小。
此外,可以将数据库由单表变成分区表。在分区表上还可以修改分区数、表组以及分区算法等。同时也可以将它修改成广播表,在每个数据节点上都有同样的复制表,对于频繁做 join 的小表非常有用。这些能力也使得用户可以灵活调整数据表的数据分布方式,以满足不同业务负载的需求。
三、分布式是一种全新数据库的模式
分布式是一种全新的数据库模式,它不仅是对单机数据库的完全兼容,更大的作用是带来了更多更强的能力。PolarDB-X 2.1版本带来了以下卓越的能力:
1. 高可用容灾能力
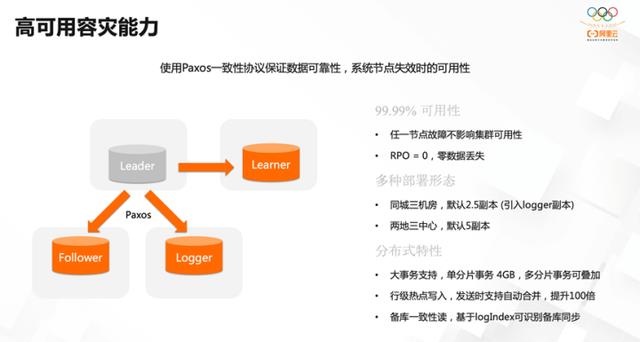
2.1 版本正式引入了 X-Paxos, 使用 Paxos 一致性协议保证数据的可靠性以及系统节点失效时的可用性。
它实现了 99.99% 可用性:任意节点的故障都不会影响集群的可用,数据 0 丢失。
提供了多种部署形态:
① 同城三机房,默认 2.5 副本。在 Paxos 协议框架下有几种角色,包括 leader节点(数据事务的主节点),它带有两个副本,分别是 follower 节点和 logger 节点。logger 节点为了节省成本,不存储全量数据,只存储日志来保证数据的一致性,同时也减少了数据副本的存储;另外还有 learner 节点,可以做只读的副本。
② 两地的三中心,默认五副本。
拥有分布式特性:用 Paxos 协议做一致性同步时,需要传输日志,而在网络上保证大量的日志传输的一致性较为困难。2.1版本支持日志分片的拆分,也做了行级热点的写入,支持自动合并,为很多电商的秒杀业务场景提供了保障;另外,通过对 follower 节点开放读,在 follower 节点上可以将全局 TSO 带过去,做一致性版本的读,利用 follower 节点的处理能力来提升整个系统的吞吐。
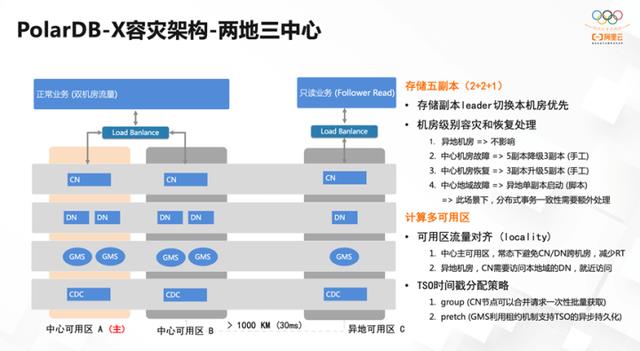
高可用的架构帮助我们提供了一个很好的基础。使得PolarDB-X 在容灾方面也提供了强有力的支撑,比如两地三中心的部署方式。采用5 副本(2+2+1)的机制,设置了很多规则,比如存储副本leader 节点失效重新选主的时候,会优先选择同机房的主节点,对整个系统服务的可靠性和延时不会带来太大的影响;另外,机房失效时,可以做五副本到三副本的降级操作,保证强一致性、持续的处理能力。
主可用区的概念是为了保证在同机范围内做网络访问时,最大可能地减小延时。
2. 冷热分离存储
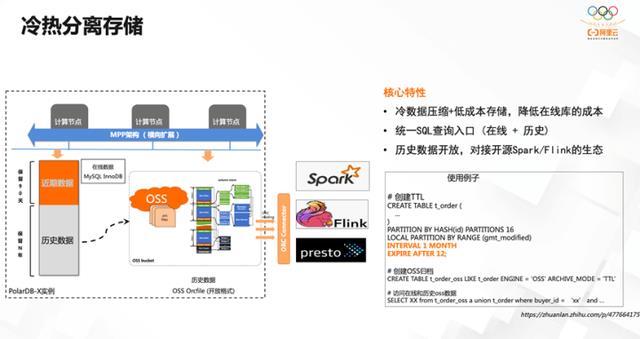
冷热分离存储是基于分布式数据库做的成本上的优化。利用 TTL 机制,在创建表的时候指定其过期时间,将已经过期的数据归为冷数据,做归档的存储。归档存储于 OSS 里,相对于本地的在线存储,极大降低了成本。与此同时, OSS 上的存储格式进行了高度压缩,进一步降低了成本。
归档到 OSS 时采用了开放的格式,优点在于可以对接很多开源生态,比如Spark、Flink 的生态,然后做分析、查询。同时,其自身的查询引擎也支持快速查询在 OSS 归档的数据。
3.可观测性
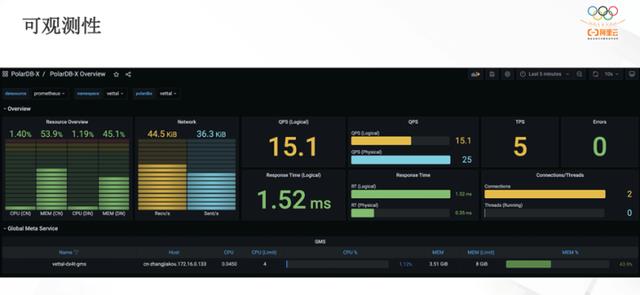
PolarDB-X 的 Dashboard 集成了开源的 Prometheus 等工具做监控、告警,分析当前系统的运行状态。另外还建了一套做 performance 的 insight 工具,分析数据在各个节点上的分布状况以及他们在分区上的访问频率,帮助用户更好地发现系统的性能瓶颈,并进行调优。
四、未来往何处去
未来我们会持续在 PolarDB-X 开源版本上做更多投入。

我们会将开源的 codebase 与当前的商业版本对齐,所有能力在内核层面完全开源。也会继续做更多企业级能力的增强,使 PolarDB-X 完全变为企业级的分布式数据库。
全新的 HTAP 引擎使得 PolarDB-X 同时能够处理事务型和分析型的负载。另外还会做国产化适配调优,实现国产化替代的工作,包括深度诊断、自动化调优工具以及各种生态的对接等。
本文为阿里云原创内容,未经允许不得转载。
以上是关于PolarDB-X 2.1 新版本发布 让“MySQL 原生分布式”触手可及的主要内容,如果未能解决你的问题,请参考以下文章
二solidity 基础进阶(2.1)—— library 库合约《实战NFT web3 solidity(新版本0.8.+)》
二solidity 基础进阶(2.1)—— library 库合约《实战NFT web3 solidity(新版本0.8.+)》
二solidity 基础进阶(2.1)—— library 库合约《实战NFT web3 solidity(新版本0.8.+)》