PolarDB-X 高可用存储服务:基于 X-Paxos 一致性协议
Posted 阿里云云栖号
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了PolarDB-X 高可用存储服务:基于 X-Paxos 一致性协议相关的知识,希望对你有一定的参考价值。
了解更多PolarDB-X 内容:
https://developer.aliyun.com/topic/polardbx_release
一、DN 高可用方案
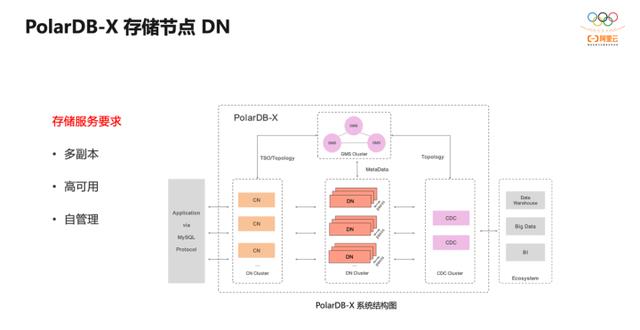
在 PolarDB-X 的系统结构中,DN 组件负责数据存储。 一个 DN 节点是 一个 mysql 实例。
为了数据安全,我们需要多副本,一个逻辑实例是由多个 DN 节点组成的集群。
为了业务连续,我们需要高可用,当部分机器或网络故障后集群依然能够持续提供服务。
这些能力都需要 DN 节点自闭环完成,如果再引入第三方组件来管理,那么第三方组件的高可用又将是新的问题。
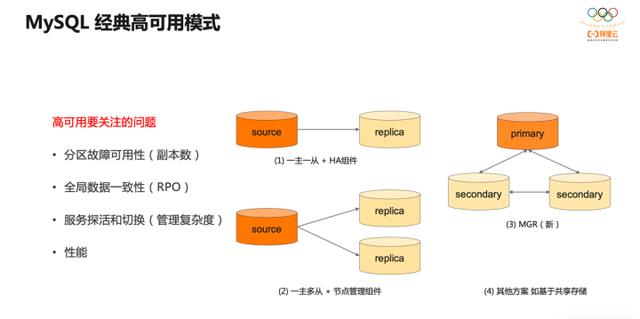
单机 MySQL,或者其他数据库,常用的高可用方案有以下几种:
第一种是经典的一主一从结构,基于 KeepAlive 进行 HA 管理;
第二种具有更高的可靠性,可以一主多从,用更复杂的节点管理器协调系统的运行;
另外还有 MySQL 社区的多主复制,有基于共享存储的部署模式等。
以上解决方案都有其各自适合的应用场景,但在设计上,需要考虑的问题是类似地,那就是:
理论上 CAP 中的分区可用性和数据一致性如何取舍?
工程上实现的复杂度、稳定性以及高可用对性能带来的损耗有多少?
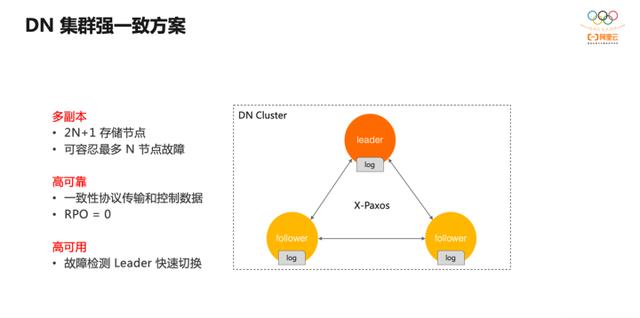
PolarDB-X 的 DN 存储集群采用了强一致方案,集群通过 X-Paxos 一致性协议进行数据复制。其特点是:
1) 在有 2n+1 节点的集群中可容忍最多 N 个节点故障; 2) 节点间数据强一致,对应用而言,RPO=0 内置了一致性协议; 3) 隐藏了复杂的节点管理逻辑。
所以,此方案的核心是一致性协议的使用。
二、X-Paxos 协议
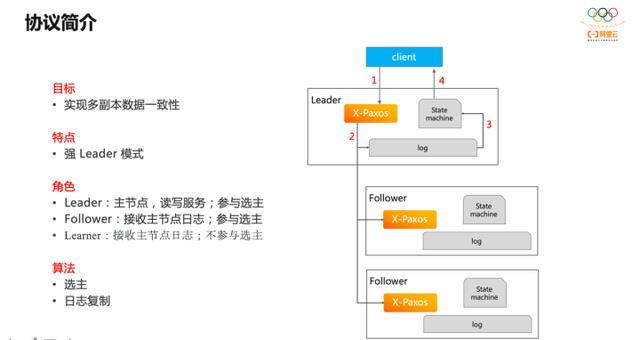
X-Paxos 是 Paxos 协议的具体实现,基于多数派理论保证数据一致性,其理论基础是经典的 Paxos 论文。
当协议正常运转时,集群中有一个 Leader 节点,其他为 Follower 节点。业务请求从 Leader 进入,Leader 将请求转化为一条增量日志并将日志广播到所有 Follower;等多数节点确认收到日志后,Leader 将日志应用到状态机,返回业务响应。过程中只要多数节点健康,协议就能正常运行,且能够保证集群数据的强一致。另外,在协议模型中还有 learner 角色,它不参与多数派决策,只是集群数据的订阅者。
协议的关键算法有两部分,首先是选主,选主是一个共识的过程,保证集群中同时只有一个 Leader 并且 Leader 已拥有达成多数派的所有日志;其次,日志复制,即上图中的运转过程。
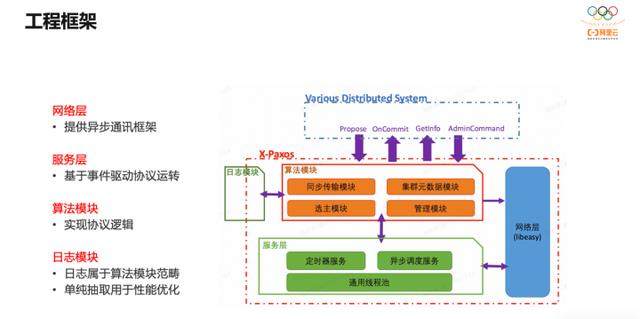
Paxos 是分布式协议,是消息或事件驱动的异步处理模型。X-Paxos 测试协议组件有四个模块:网络层提供基础的异步网络通讯框架;算法模块实现协议的业务逻辑,包括选主、日志复制、源数据管理等;服务层是调度中心,负责响应定时器和网络事件,驱动算法模块的运转;日志处理本属于算法范畴,但 X-Paxos 实现时将日志处理逻辑抽象出通用接口,在算法模块调用接口,使日志的具体实现可以在日志模块完成,并且可以单独优化。
三、DN 高可用体系
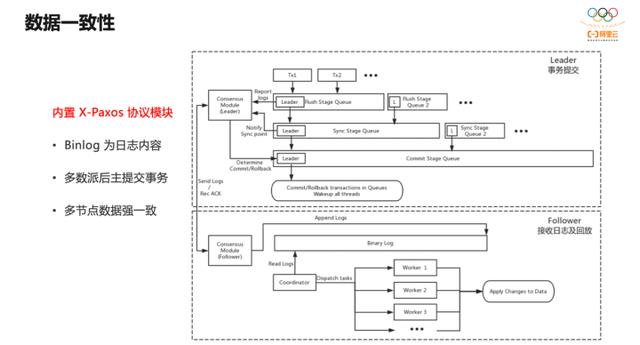
MySQL 是多引擎架构,事务提交分为两阶段,第一阶段为引擎 Prepare, 第二阶段进入 Binlog Ordered Commit。
Ordered Commit 为分组提交,又分为三个过程:Flush 将 Binlog 内容写到 Binlog 文件,Sync 将 Binlog 文件内容持久化,Commit 是引擎提交。
引入一致性协议后,Leader节点上,在 Binlog 的 Flush 和 Sync 过程中将 Binlog 内容同时广播到所有 Follower。多数派达成后,Leader 再发起最后的引擎 Commit ,以保证数据的强一致。
因为集群中只有 Leader 提供服务,所以 Leader 的状态对系统可用性至关重要。
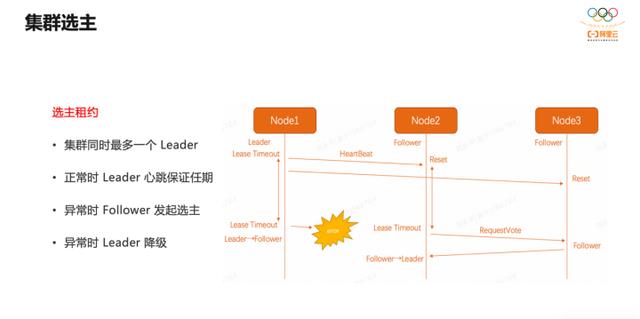
Leader 任期内,所有 Follower 都不再发起选主请求,也不投票其他节点的选主请求。但是任期过后,如果 Follower 发现 Leader 已经异常,将重新发起选主;如果 Leader 发现自己和多数 Follower 的通信异常,将自动降级,发起选主请求。
大部分情况下,集群各节点的状态都正常,Leader节点的主动心跳会保持他的 Leader 地位,集群不会发生 HA 。

默认情况下,集群内所有节点都公平选主。当希望某些节点优先对外提供服务,可以对这些节点赋予更高的选主权重。权重高的节点当选 Leader 的几率大,但这是弱限制,不保证绝对按权重选主。因为选主最基本的原则还是节点需要拥有集群中已经达成共识的所有数据,这是绝对限制。
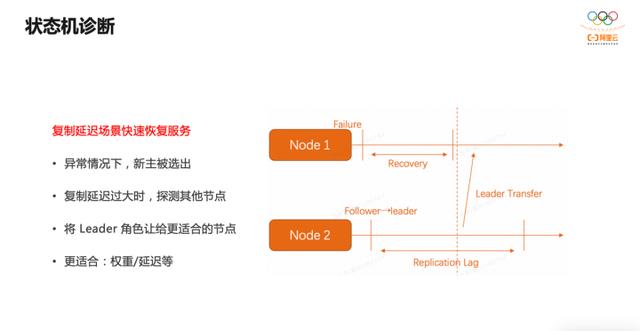
DN 集群节点间同步的数据是 Binlog ,当新主被选出后,需要完成两个步骤才能对外提供读写服务:一是将日志同步给其他落后的 Follower 节点,二是将本节点 Binlog 应用到最新位点。如果需要应用的 Binlog 很多, Leader 将迟迟无法对外提供服务,从而影响系统可用性。此时 Leader 会探测其他 Follower 节点,如果发现更合适的,则会将 Leader 角色让出。
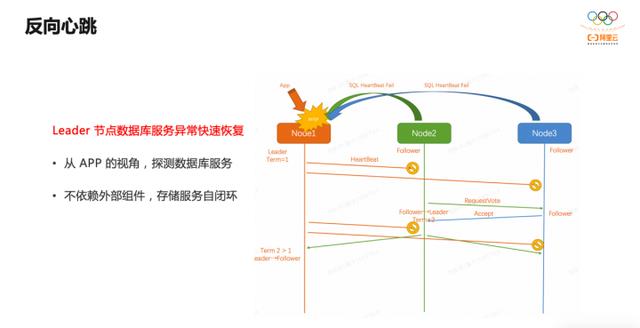
定义集群是否可用,最终还要看当前 Leader 能否够提供业务服务。有时候从协议层面看,集群是健康的,但是 Leader 节点的业务服务异常,比如磁盘满,则此时集群不可用。因此 Follower 节点会定期向 Leader 发起反向心跳,用于检测 Leader 的业务服务是否正常,如果不正常则重新选主。
四、DN部署和优化

上图为最常用的部署模式,三个节点参与集群决策,一个或多个 Learner 作为订阅者提供只读服务。此处 Logger 不是一种新角色,在协议层面,它就是 Follower ,但它不回放 Binlog ,仅保留 Binlog ,用于整个集群数据的强一致,能够减少一份 MySQL 实例的数据空间,降低存储成本。
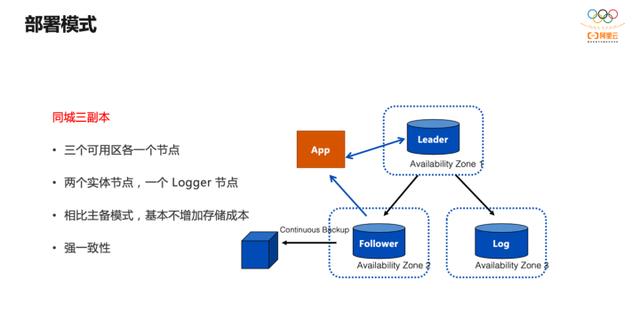
同城 3 副本部署模式实现了三个可用区各一个节点,两个实体节点, 一个Logger 节点,相比传统的主备模式,基本不增加存储成本,但是可以实现数据的强一致。

跨城 5 副本模式下,有了更多节点后,可以实现单 Region 不可用的容灾,同时配合权重选主可以定制 Region 的切换顺序。
以上就是是关于PolarDB-X 高可用存储服务的整体介绍。
本文为阿里云原创内容,未经允许不得转载。
以上是关于PolarDB-X 高可用存储服务:基于 X-Paxos 一致性协议的主要内容,如果未能解决你的问题,请参考以下文章
网络云存储技术Windows server 2012 (项目二十 一 基于Cluster的高可用企业WEB服务器的部署)