Flink FlinkSink 流式数据落盘 FileSink
Posted 青冬
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Flink FlinkSink 流式数据落盘 FileSink相关的知识,希望对你有一定的参考价值。
序
Flink版本: 1.15.0
内容: FileSink 的使用方法及实现。
阅读时间:9~30min,取决于是否跟着看源码。word字数5k,csdn字数1w。
前言
在 Flink 中,大多数场景都是 kafkaSource & kafkaSink,但不乏需要将数据写一部分到离线中的场景。
对此, Flink 提供了 StreamingFileSink 来处理 Steaming 写出到 FileSystem 接口的文件系统中,并且支持 Exactly-Once 语义。
基于 check point 来实现。并且很好兼容 Hive 等分区场景。今天主要讲讲 FileSink 的使用方法及实现。
FileSink 简单的示例
比如一个实时流数据落盘到本地磁盘中:
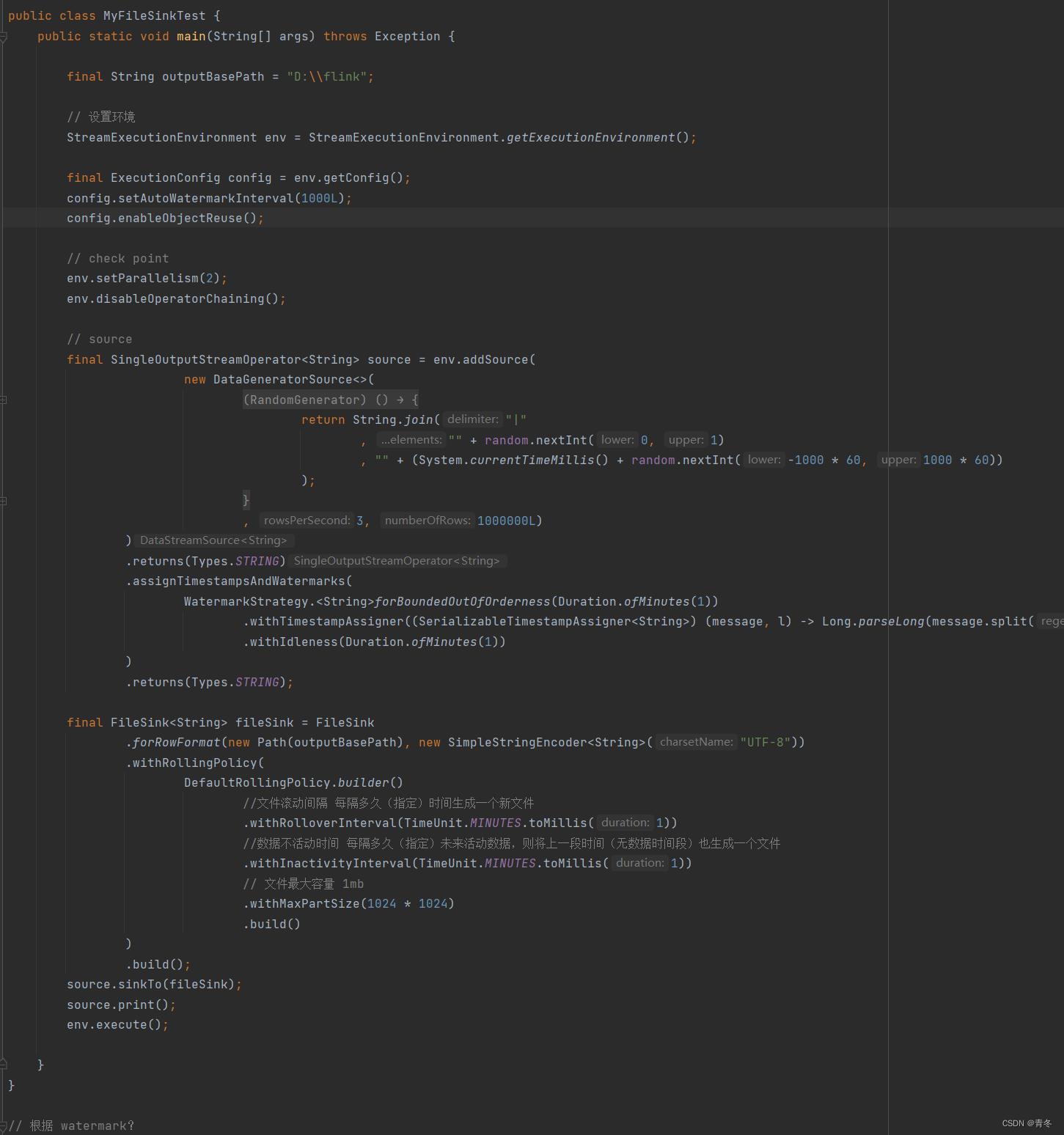
通过 DataGeneratorSource 产生一个以 "|" 分割的数据源,其中第二项为模拟数据产生时间(watermark)。这里代码并未包含 checkpoint 操作
这样将这个数据推送到了我们本地磁盘中,落盘后的样例是这样的:
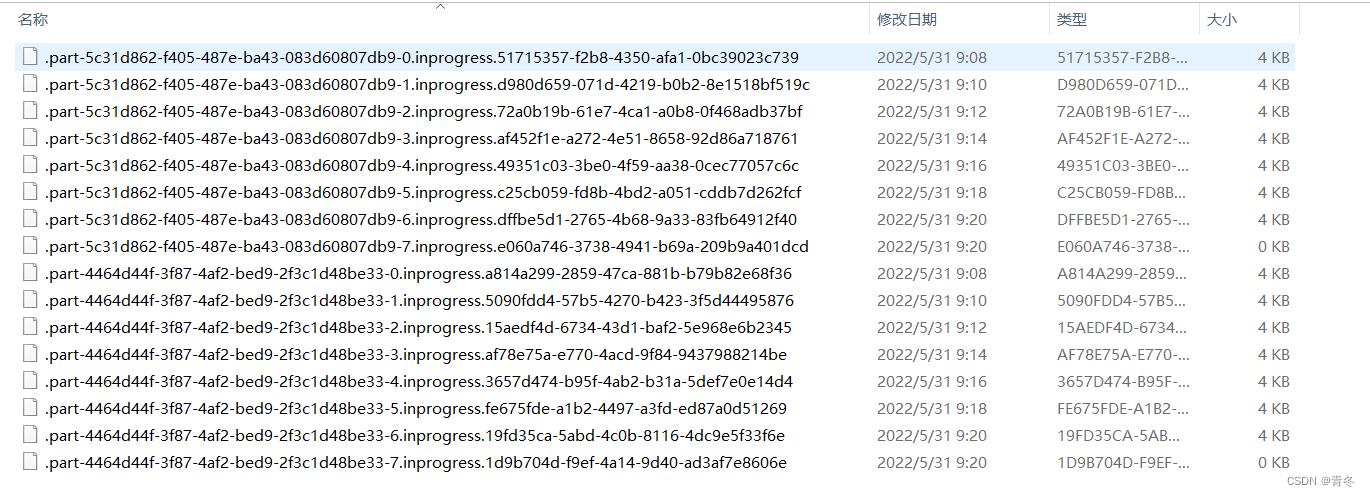
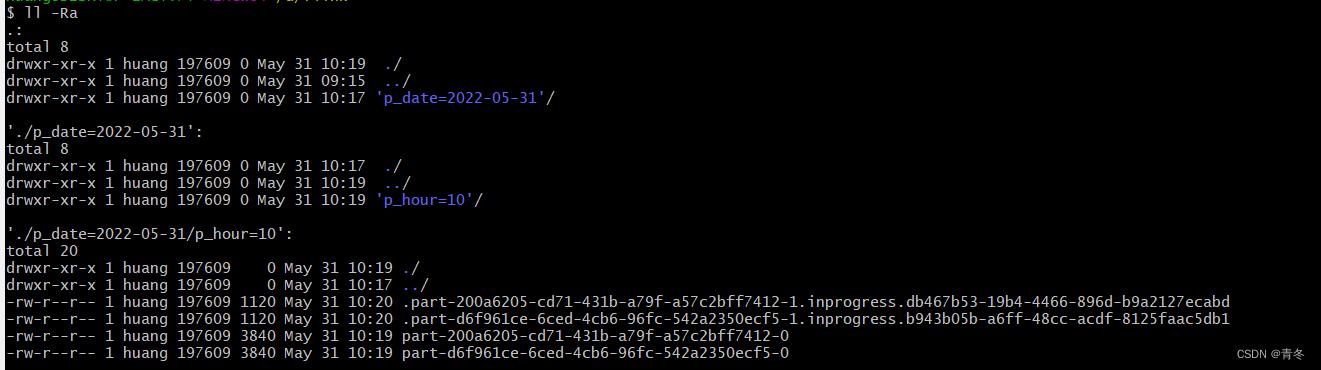
可以看到当我们并发度为 2 的时候,两个的前缀标识不同,并且分开写出文件,文夹名为:2022-05-31--09
文件命名规则:.part-<subtaskIndex>-<partFileIndex>.<status>.<UUID>
并且在输出的时候,是有数据到达就输出,而不是一个文件直接落盘。这里的文件都是 inprogress 状态,但其实已经写出完毕。但这是为什么?
FileSink
在 Flink 官网中,有详细介绍 FileSink 的内容: https://nightlies.apache.org/flink/flink-docs-release-1.15/docs/connectors/datastream/filesystem/
其中特别说明了,如果使用 FileSink 在 STREAMING 模式的时候,必须开启 checkpoint,不然的话会导致每个分片文件一直处于 in-progress 或者 pending 状态,不能保证整个写入流程的安全性。
所以在我们上述的示例中,我们并未开启 checkpoint 导致写出文件一直处于 inprogress 状态。如果加上 checkpoint 后:

写出的文件就会变为:
写出中:

写完毕后:

可以看到文件将 dot 去掉,并且将 inprogress 及后面的唯一标识也给去掉了。而且并不是说我们文件写完就进行 rename 操作,而是在 checkpoint 后才会将写完毕的文件进行 rename 操作。
其实整文件变化的过程为:
In-progress :当前文件正在写入中
Pending :当处于 In-progress 状态的文件关闭(closed)了,就变为 Pending 状态
Finished :在成功的 Checkpoint 后,Pending 状态将变为 Finished 状态
RollingPolicy
写出时,我们可以指定数据 part 滚动的策略,如:
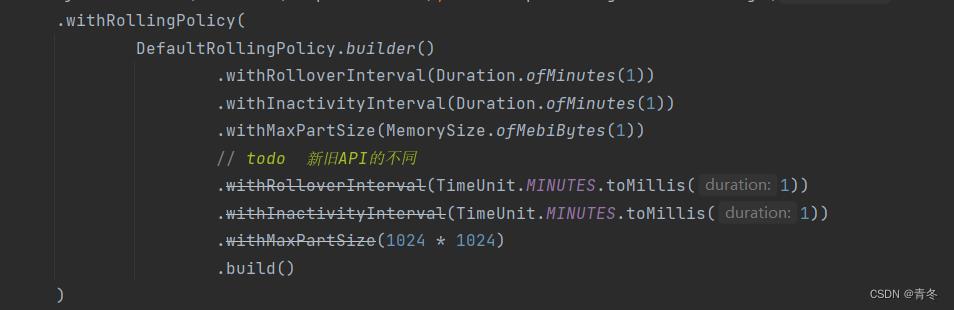
上面写了 1.15 之后的新 API 和之前的 API 的差异。
注意在 1.15之后的时候使用 FileSink 需要导入包:
之前不需要
根据 org.apache.flink.streaming.api.functions.sink.filesystem.RollingPolicy 可以查看到上面主要的需要实现的方法。
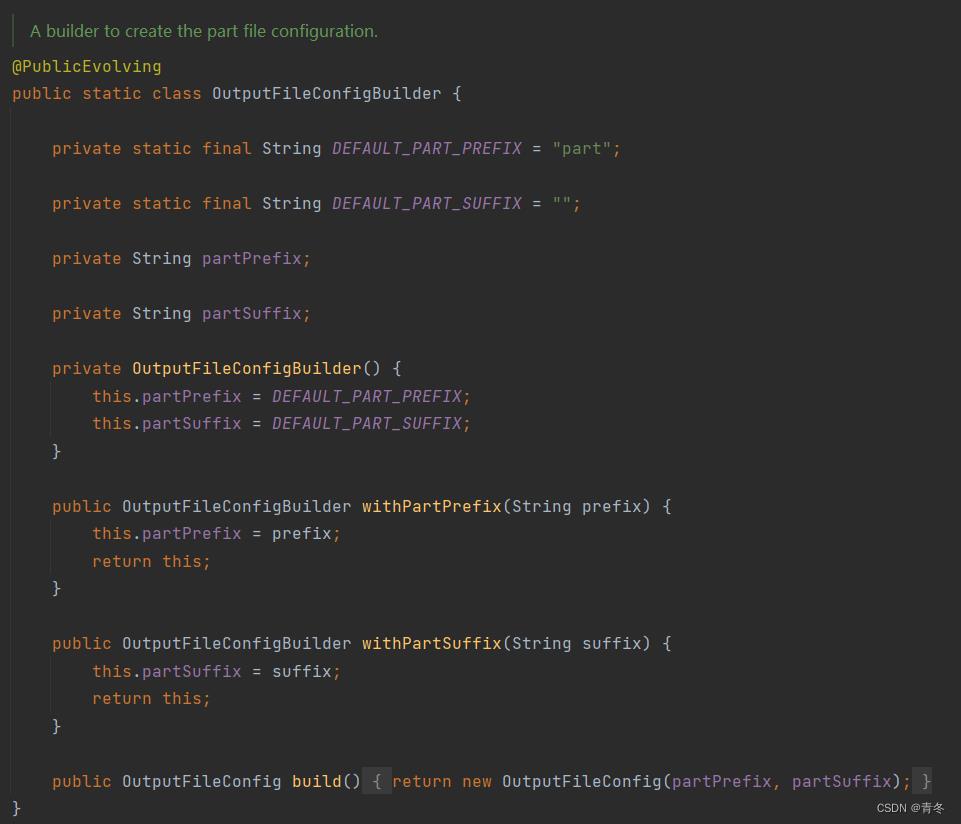
OutputFileConfig
我们的文件名还记得吗?.part-<subtaskIndex>-<partFileIndex>.<status>.<UUID>
写出完毕后变为:part-<subtaskIndex>-<partFileIndex>
但我们有时候还是想自定义文件名的嘛,有方法吗?有的,Flink 提供了一个 OutputFileConfig 来自定义前缀和后缀。
所以我们还是不能完全自定义输出的文件。
示例:
.withOutputFileConfig(new OutputFileConfig("ourPrefix","ourSuffix"))
就一行代码,然后变更后的效果:
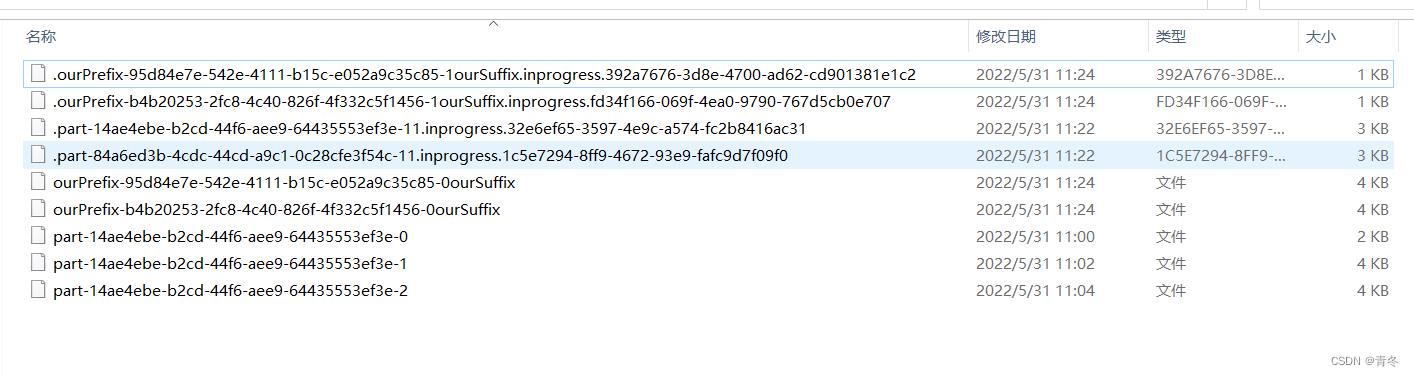
里面包含了跟之前的对比,可以看到前缀 Flink 帮我们添加了拼接字符 "-",但是在后缀的时候缺没有添加,因为默认的 OutputFileConfig 未包含后缀。
后缀一般设置为文件名后缀,比如“.txt.gz”
FileSinkBucket
在业务上我们一般会要求数据写出格式(文件夹路径,文件名,还可能包含 dot 文件的 rename 操作)。
所以我们继续看看 Flink 给我们提供怎么样的手段进行配置,或者是否可以自己写一个 FlieSinkBucket。
对于什么是 Bucket,其实官网有给一个图:
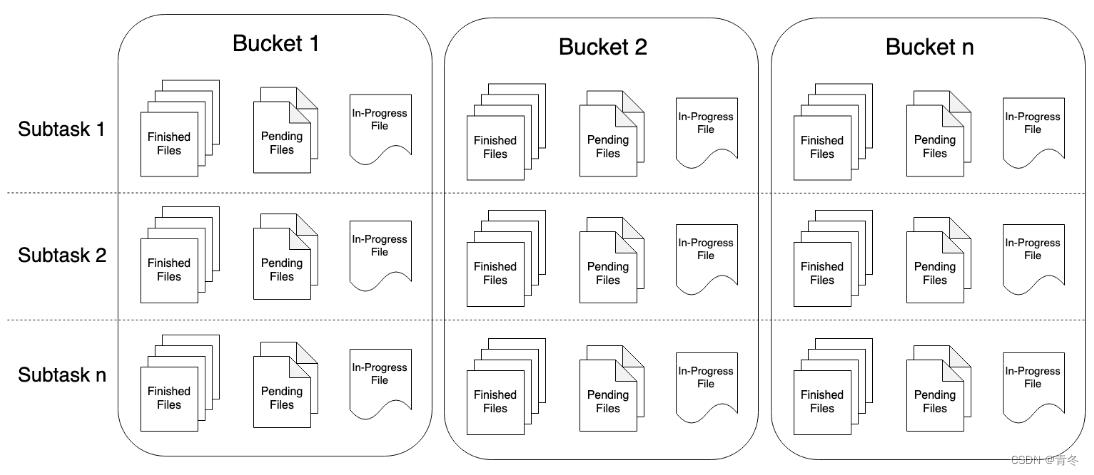
Bucket 就类似一个路径,通过路径进行 Bucket 的指定
在查看文档接口后,我们发现我们还能指定 Bucket,只需要实现接口 org.apache.flink.streaming.api.functions.sink.filesystem.BucketAssigner 就能控制 Bucket 的命名方式。
BucketAssigner
查看下 BucketAssigner 的结构:
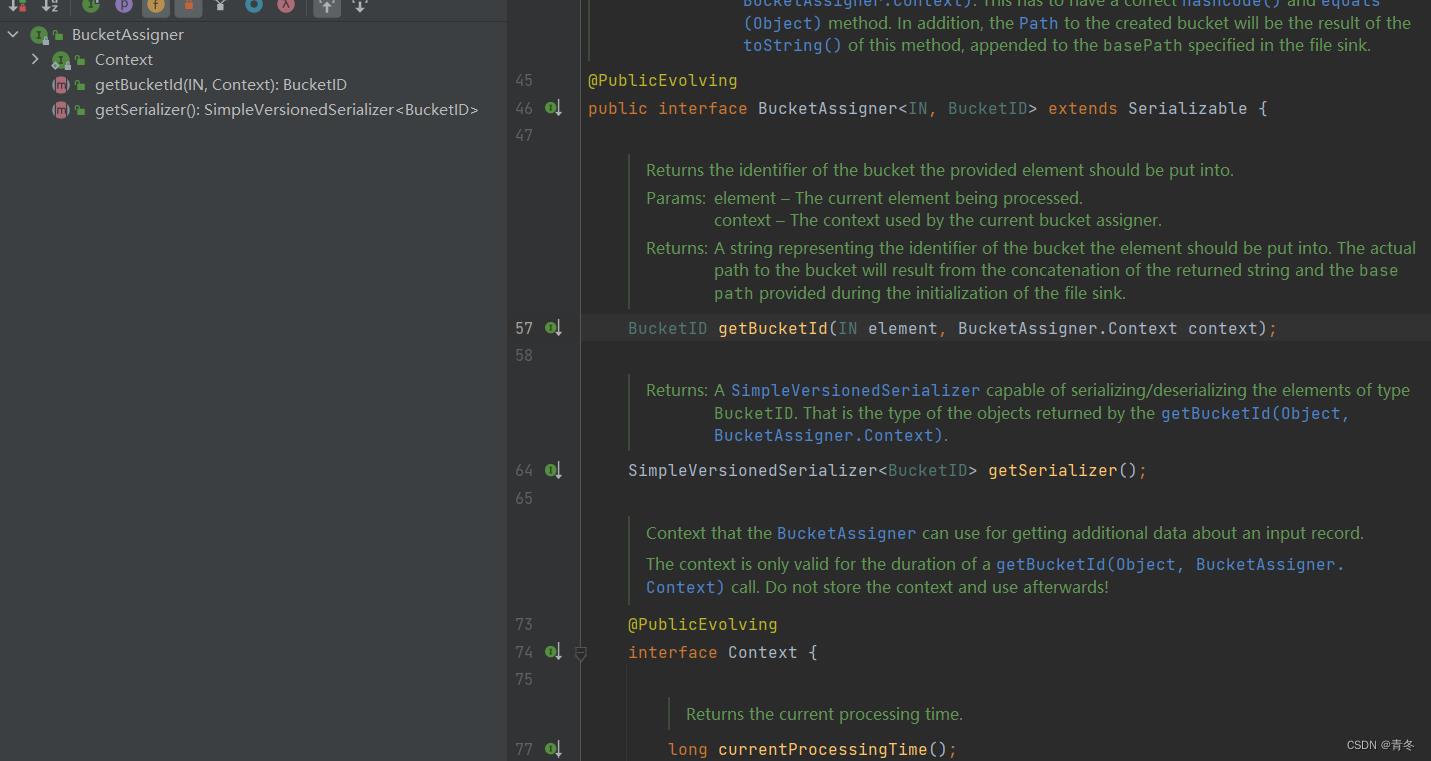
跟以前一样,传入了 Context 提供给用户调用,并且需要用户实现两个方法:getBucketId 和 getSerializer。这里直接给一个示例:
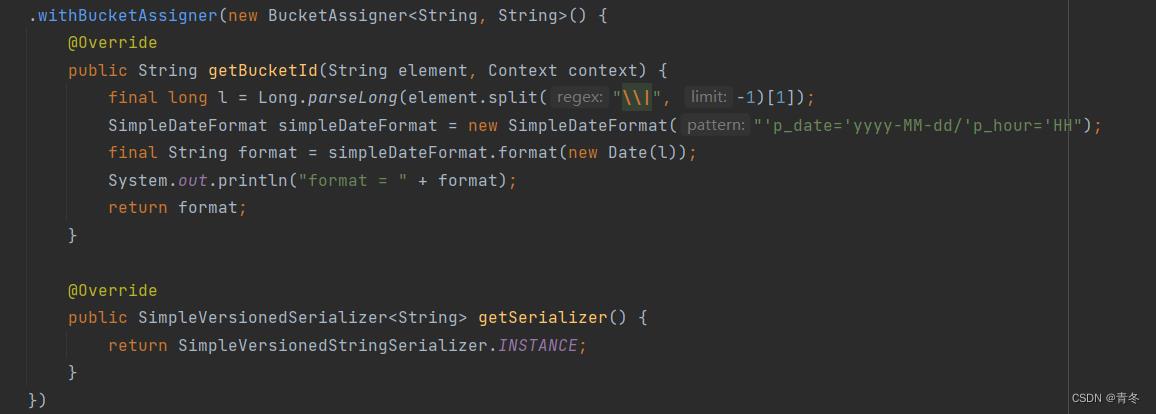
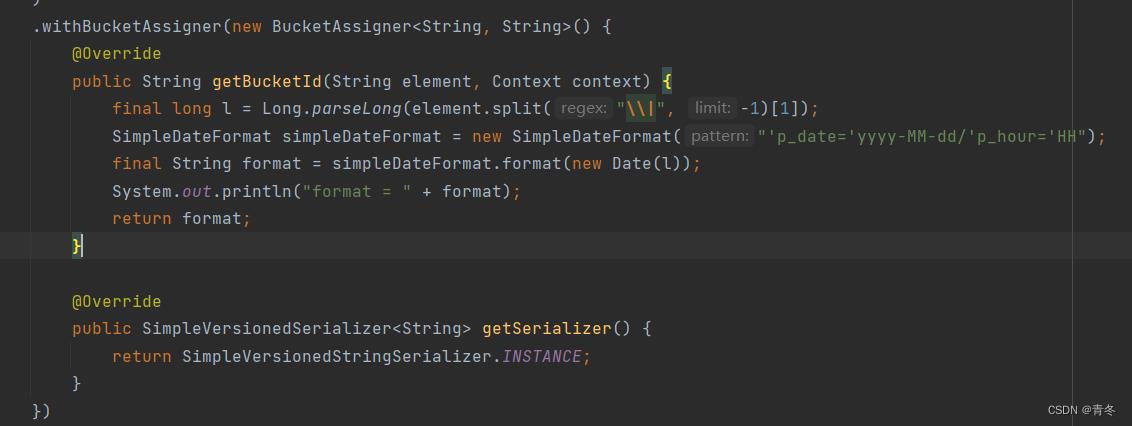
将 element 中的时间戳转换成对应的 Hive 分区后的样式进行测试,得到一下的 bucket 样式:
DateTimeBucketAssigner
上面除了看文档以外还有什么地方可以了解?一般这种时候,我们可以看他原生默认实现的当时,对于 BucketAssigner 来说有两个,DateTimeBucketAssigner 和 BasePathBucketAssigner。
其中 BasePathBucketAssigner 都是空实现,方法都返回最基础的,所以我们就来看看 DateTimeBucketAssigner的实现方法。
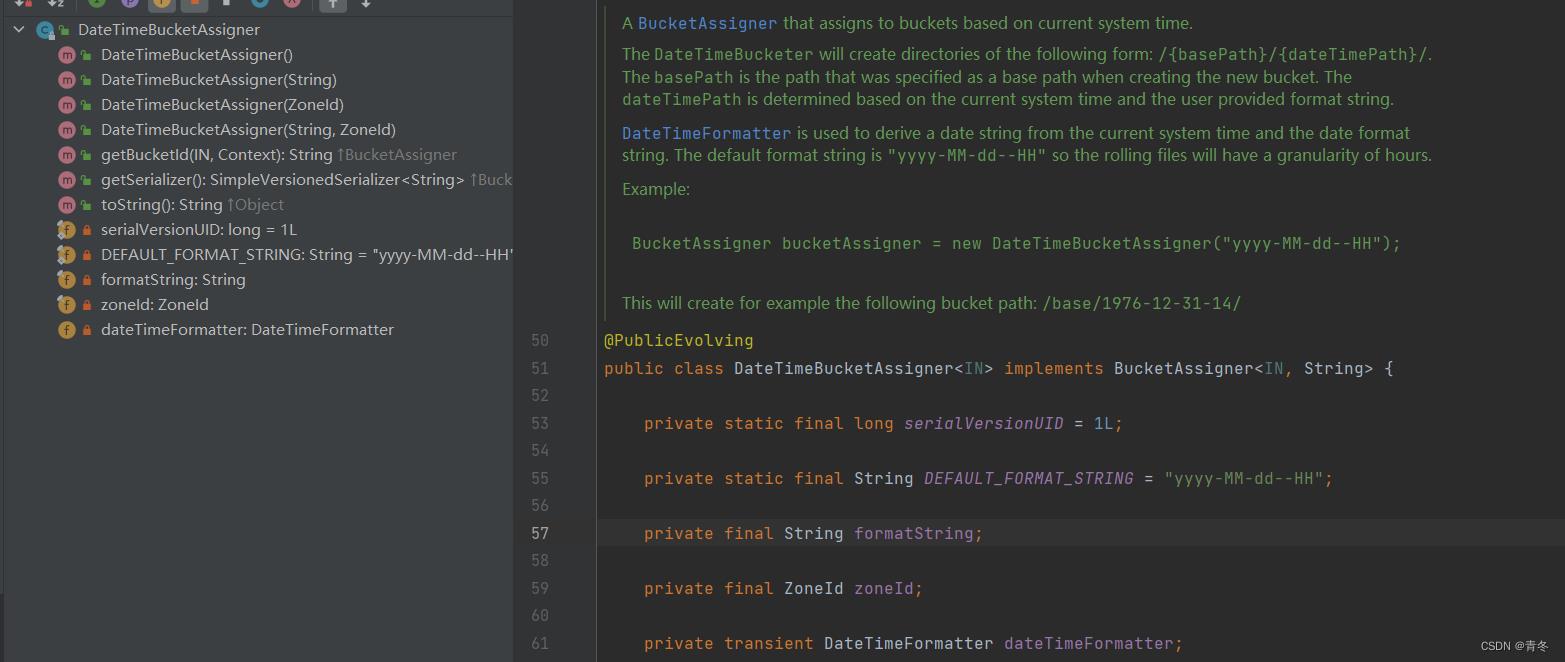
从上面可以看到,DateTimeBucketAssigner 有很多构造方法,最重要的就是两个参数 formatString 和 zoneId。
formatString 决定了我们 bucket 的生成规则,默认为 yyyy-MM-dd--HH。
zoneId 决定时间域,默认为 ZoneId.systemDefault()。
通过构造函数都可以进行更改。
然后在 BucketAssigner 中,我们更希望看到的是 getBucketId() 方法的实现:
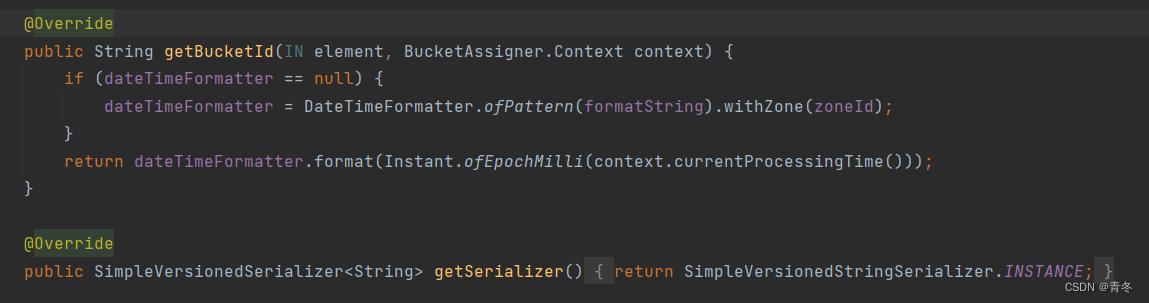
所以默认的 DateTimeBucketAssigner 是使用当前的系统处理时间来判断数据写入那个 bucket 中。与我们自定义使用的 element 中的数据的时间还是有很大出入的。但这样能减少同时写出的 bucket 的数量,避免一些其他问题。
Compaction
在 1.15 之后为了快速滚动,并且避免小文件的操作,添加了 compact 功能,可以在 checkpoint 的时候进行合并。最简单的示例为:
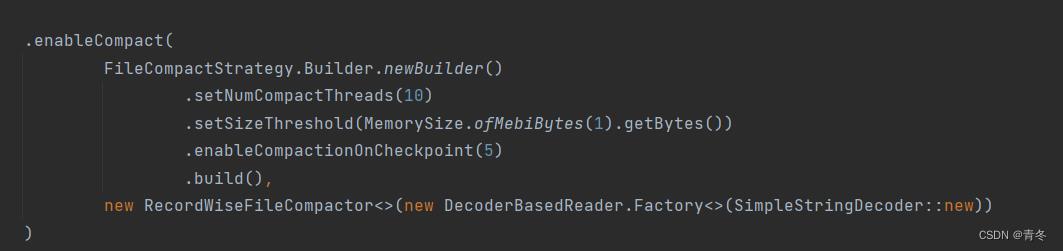
setNumcCompactThreads
设置合并的线程数
setSizeThreshold
设置大小的门限(小于这个大小的会被合并)
enableCompactionOnCheckpoint
多少个 checkpoint 信号来了,会进行一次 compact
如果开启了 Compaction,那么必须在 source.sinkTo(fileSink)的时候添加 uid:
source.sinkTo(fileSink).uid("fileSink");
写入时候的变化:
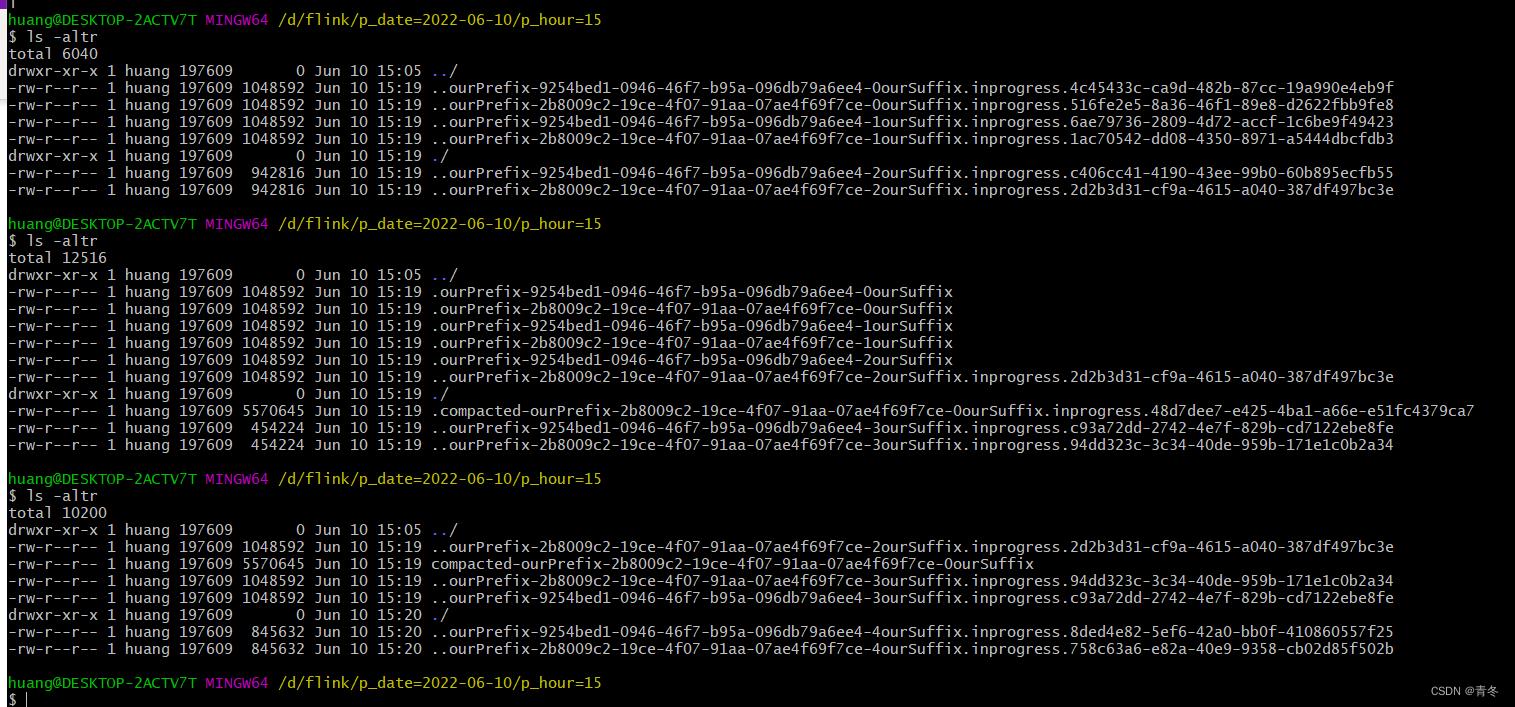
可以看到变成了..
..<prefix>-<subtaskIndex>-<partFileIndex><suffix>.<status>.<UUID>
而且文件大小是持续在增加,在开启后会生成新的压缩后的 pending 文件,然后讲这些 pending 文件发送给提交者,以提交给给正式的文件,最后删除源文件。而且除非完毕,文件将一直保持 dot 文件,意味着这会导致文件对外可见会更慢。
结合图看就是一样开始生成文件,但是 double dot 的形式,等到满足 FileSink的条件后,经过 checkpoint 会变成 dot Finished File,然后如果这个时候触发了 compact,那么就会将可以 compact 的文件进行合并,首先创建一个.compacted 的文件,然后合并完成后变为正式文件 compacted,并删除 dot Finished File。
学会了配置,但流程到底是怎么样的?
上面我们走过了整体配置 FileSink 在 STREAMING 模式下的配置和使用方式,能够自定义一些方法和函数解决生产中的各类问题,但这只是开始,我们要梳理清楚整体的 Flink 调用流程才算结束。
还记得官网强调我们必须进行 checkpoint 和 watermark 的设置吗,但在哪里实现的呢?
FileSink
我们看看 FileSink 的结构:
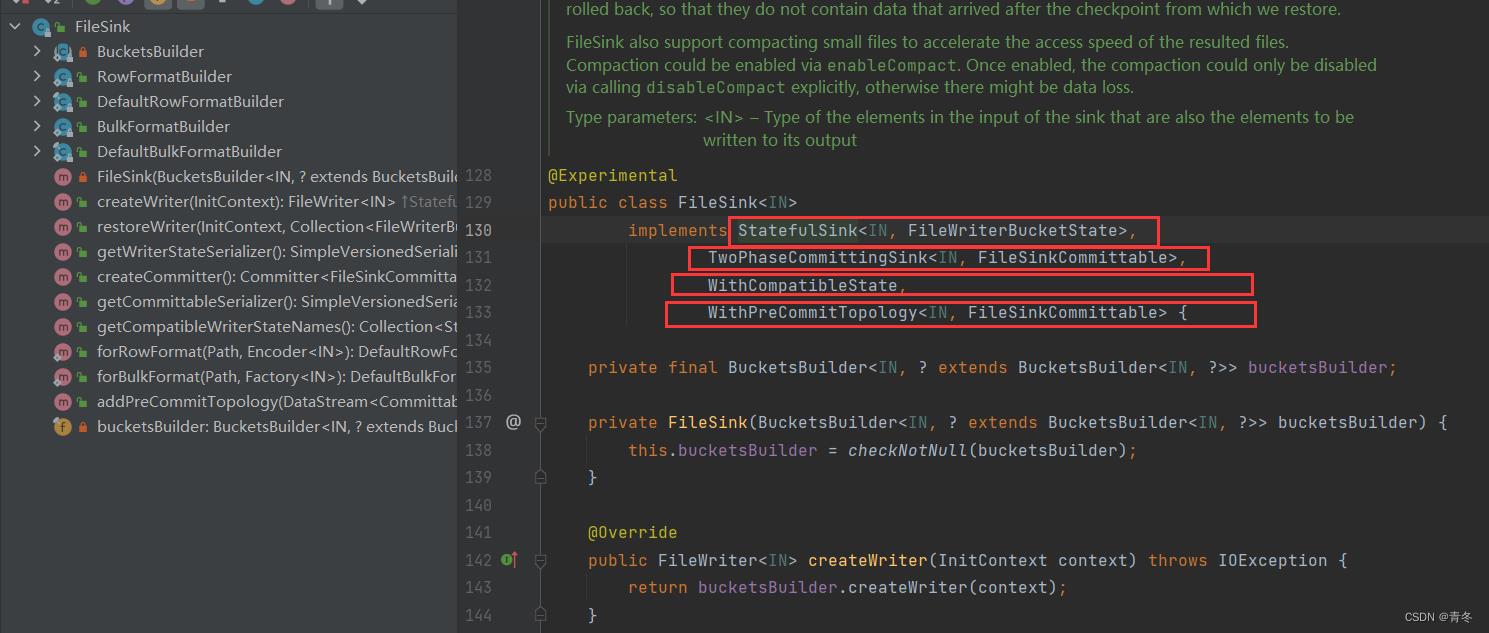
FileSink 实现了四个接口:
StatefulSink
TwoPhaseCommittingSink
WithCompatibleSink
WithPreCommitTopology
StatefulSink
一个安全的写出 Sink,需要实现 serializable;并且需要安全的配置,所有的 writers 都是在 subtasks 中创建。
实现这个接口的还有我们熟悉的: KafkaSink/RuducingUpsertSink等。

主要包含:
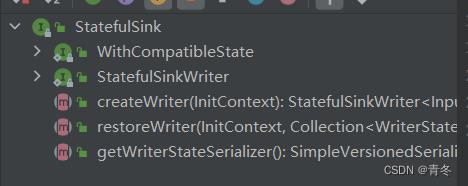
createWriter:创建一个 Writer
return bucketsBuilder.createWriter(context);
restoreWriter: 从状态中恢复一个 Writer
FileWriter<IN> writer = bucketsBuilder.createWriter(context);
writer.initializeState(recoveredState);
return writer;
getWriterStateSerializer:返回序列化方法。
try
return bucketsBuilder.getWriterStateSerializer();
catch (IOException e)
// it's not optimal that we have to do this but creating the serializers for the
// FileSink requires (among other things) a call to FileSystem.get() which declares
// IOException.
throw new FlinkRuntimeException("Could not create writer state serializer.", e);
TwoPhaseCommittingSink
使用两阶段提交的 Sink,我们也在 Kafka 中看到过了。
主要就是由一个执行预提交的 SinkWriter & 实际提交数据的 Committer 组成。
为了便于分离,SinkWriter 在检查点或者结束输入时进行创建可提交表,并发送给 Committer。
这个就需要实现他的方法进行一个 createCommitter & getCommittableSerializer 的特有方法:
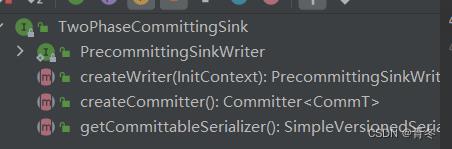
createCommitter: 创建 Committer
return bucketsBuilder.createCommitter();
getCommittableSerializer: 返回序列化方法
try
return bucketsBuilder.getCommittableSerializer();
catch (IOException e)
// it's not optimal that we have to do this but creating the serializers for the
// FileSink requires (among other things) a call to FileSystem.get() which declares
// IOException.
throw new FlinkRuntimeException("Could not create committable serializer.", e);
WithCompatibleSink
就是在 StatefulSInk 中的安全保证,要求返回一个接收器的状态名称列表。将新的 FileSink 可以从旧的 StreamingFileSink 的状态中回复,并且作为 checkpoint/savepoint 回复直接的替换。
这里 FileSink 直接指定为:
return Collections.singleton("bucket-states");
WithPreCommitTopology
可以让用户进行提交信息的更改:
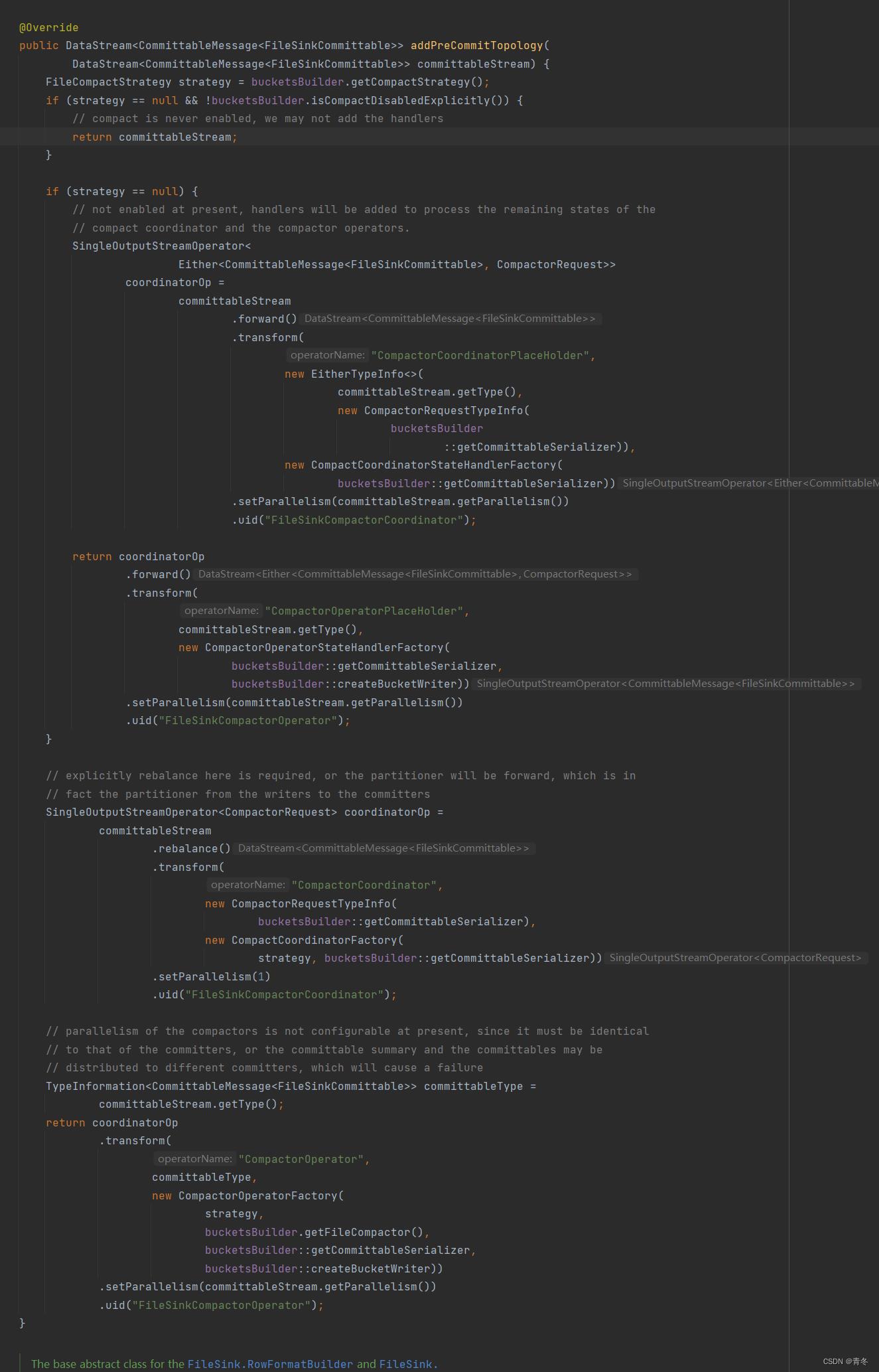
CreateWriter
org.apache.flink.connector.file.sink.FileSink.RowFormatBuilder#createWriter
org.apache.flink.connector.file.sink.FileSink.BulkFormatBuilder#createWriter
在 FileSInk 中的 CreateWrite 有两种实现方式,我们这里看我们示例中的 BulkFormatBuilder。
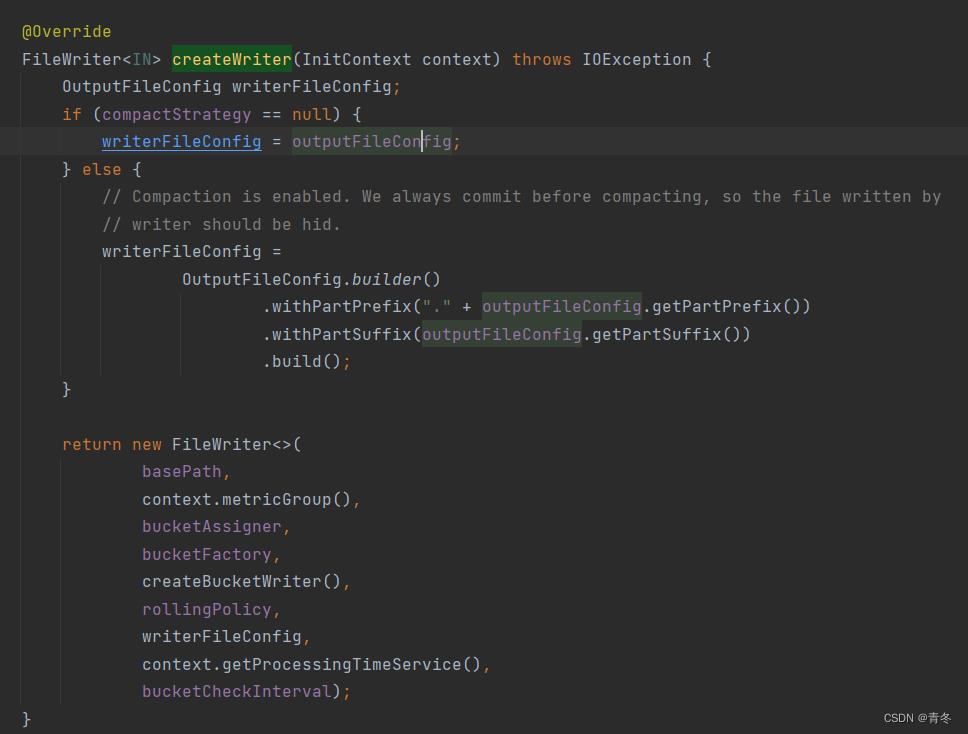
可以看到,根据我们的各种参数,最终返回了一个 FileWriter。那么这个 FileWriter 大概率就是我们最终的实现了。
FileWriter
org.apache.flink.connector.file.sink.writer.FileWriter#FileWriter
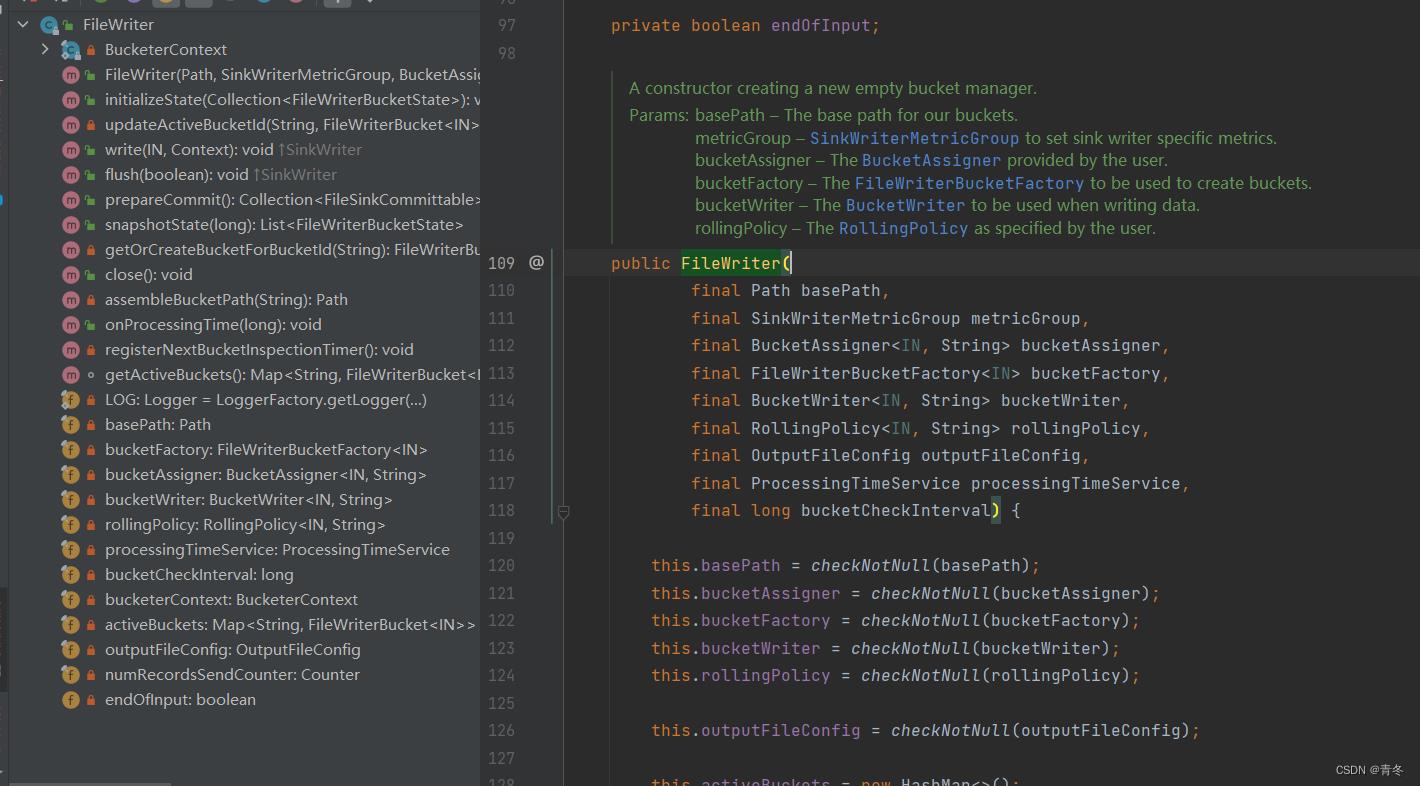
通过注释可以看到,这个类实现两个功能:
- 写数据。
- 管理存活的 buckets。
实现了四个接口:
- StatefulSinkWriter
- TwoPhaseCommittingSink.PrecommittingSinkWriter
- SinkWriter
- ProcessingTimeService.ProcessingTimeCallback
重要方法讲一下。
initializeState
当从故障中恢复后,怎么加载状态。
updateActiveBucketId
如果单个 bucket 有多个状态,那么会进行合并操作。
其实这个大多数时候是因为两次Flink任务的并发不同导致的,其实我们在实现各种 state 后端的时候都应该考虑这个状态合并问题。
write
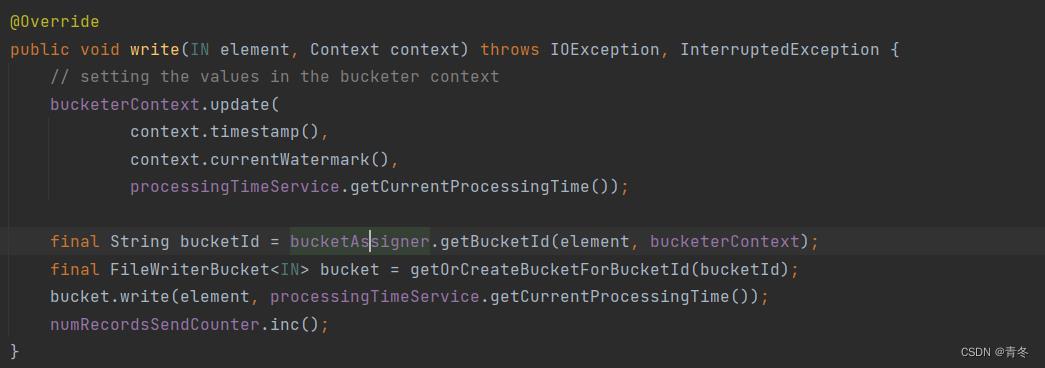
从 SinkWriter 实现的方法,写数据使用。
首先计算进来的 element 对应的 BucketId,然后通过 Id 获取/创建对应的 bucket,调用 bucket 的写方法来写入数据。
并且将 numRecordsSendCounter + 1。
所以目标更明确了,我们通过这个方法就能了解到 element 可以计算出 bucketId,然后找到对应 bucket 来写入数据,整个操作有两个重要的对象: bucketAssigner & FileWriterBucket。后续我们专门讲讲这两个对象。
flush
这个方法从 SinkWriter 实现,当输入结束或者 checkpoint 时调用,用来将 pending 的文件刷新。
为什么要 checkpoint ?
prepareCommit
准备 commit 阶段方法。
将不活跃的 buckets 遗弃。
特别是使用了 OnCheckpointingRollingPolicy,避免每次都创建 bucket。
然后将活跃的调用 FileWriterBucket#prepareCommit() 方法,这个类后面我们会重点说说。
可以理解为,FileWriter 管理了所有 buckets,这里准备提交所有 buckets,然后调用每个一个 bucket 的 prepareCommit()。
snapshotState
对 活跃的 buckets 进行 state 存储。
getOrCreateBucketForBucketId
通过 bucketId 来获取或创建 bucket。
Id 是通过每个 element 来获得的。
其实在我们的示例中,创建了一个 BucketAssigner,重写了 getBucketId, 这个路径 String 就是 bucketId:
close
关闭所有 bucket,停止写入。
将 所有 bucket
onProcessingTime
调用每个活跃 buckets 的 onProcessingTime。
org.apache.flink.connector.file.sink.writer.FileWriterBucket#onProcessingTime
最后会调用 FileWriteBucket 的 onProcessingTime 方法,来判断是否需要进行滚动了。
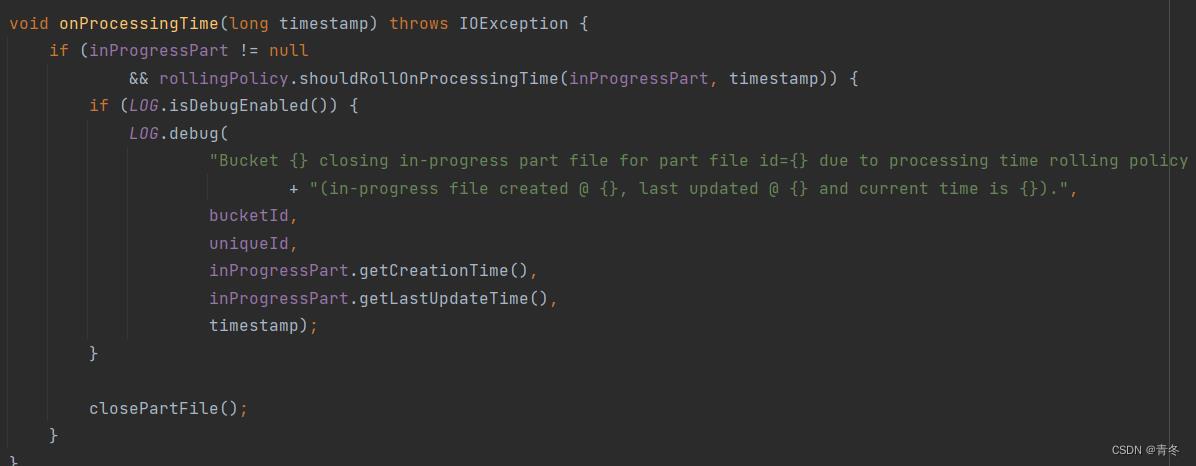
并且注册下一次视察的 timer。
activeBuckets
活跃的 buckets。
装载在 HashMap 中,key 为 bucketId,value 为 FileWriterBucket。
BucketAssigner
org.apache.flink.streaming.api.functions.sink.filesystem.BucketAssigner
现在我们已经差不多完全理解 Bucket 的含义了,其实就是一个包装盒,盒子里可以有多个文件,包装盒有 Id,可以根据 element 和 context 计算出 Id。
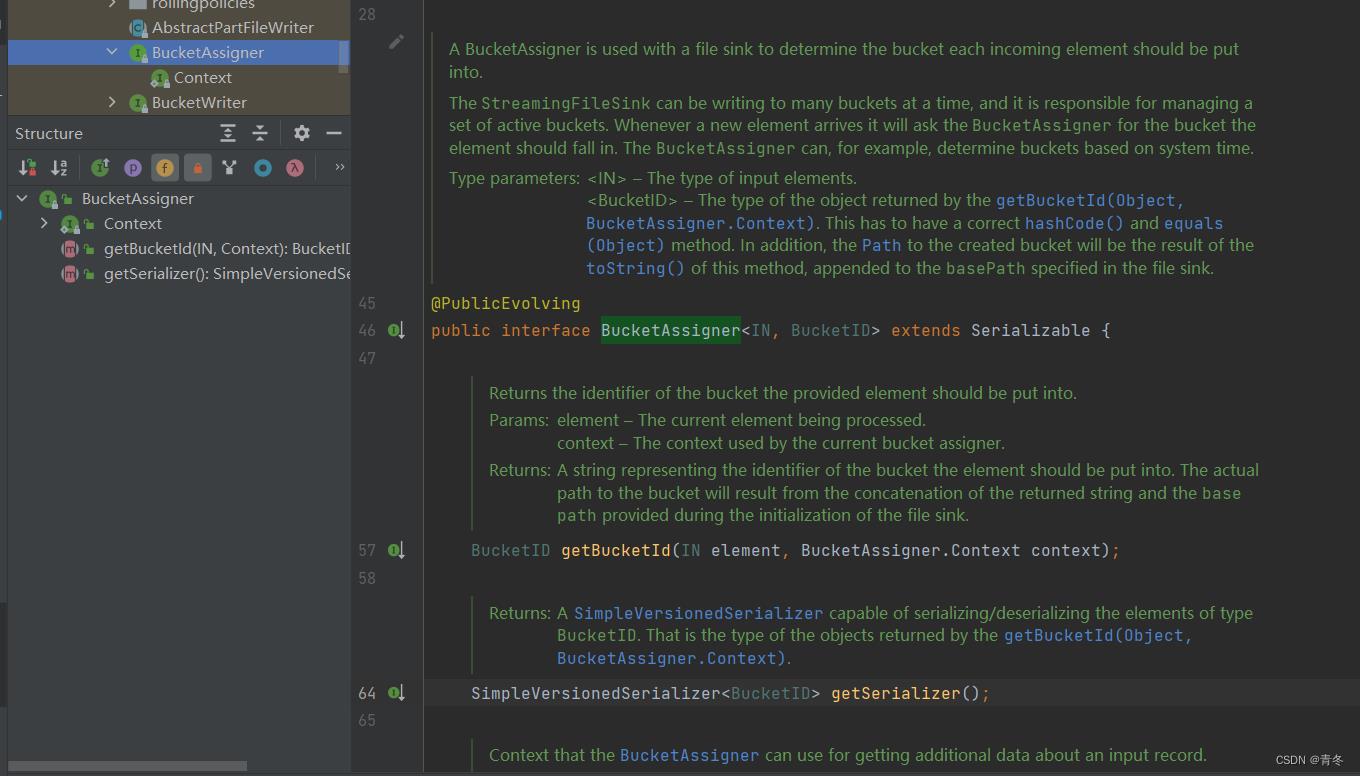
所以一共有两个方法和一个 context 对象。
getBucketId & getSerializer
对于不同的实现有不同的作用:
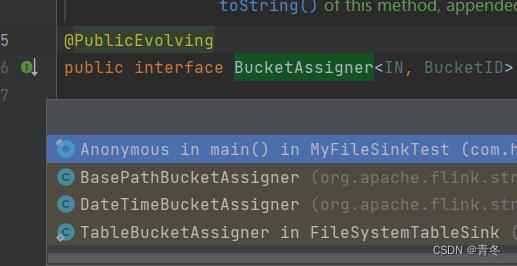
自身一共有三种实现: BasePathBucketAssigner & DateTimeBucketAssigner & TableBucketAssigner。
其中 BasePath 的 Id 只有一种为 ""。
DataTime 的 Id 通过处理数据的当前时间转换为 yyyy-MM-dd-HH 的 Id。
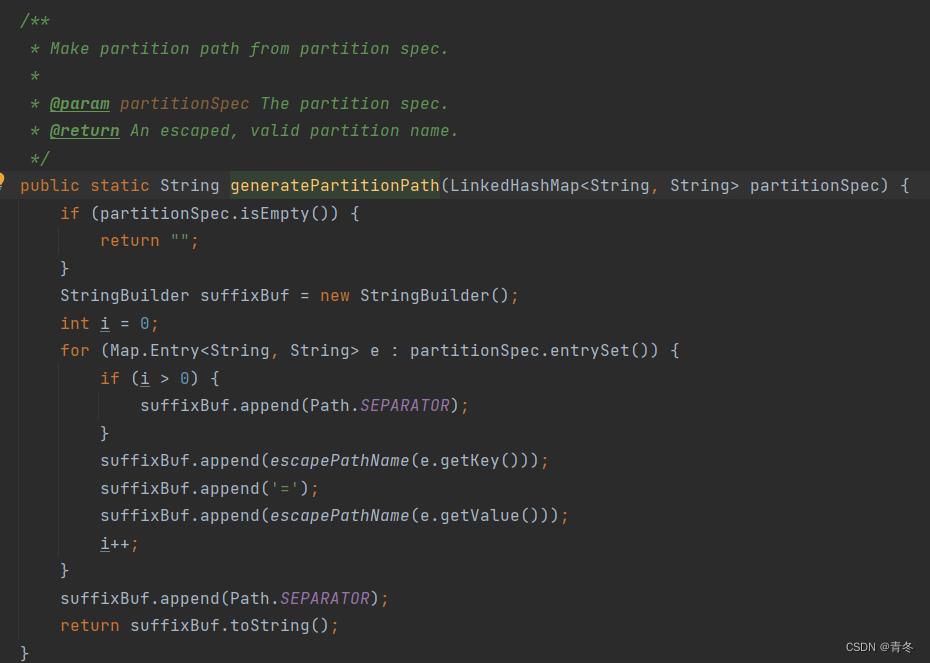
Table 的 Id 是通过 rowData 获取 partitionSpec 拼接获得:
FileWriterBucket
org.apache.flink.connector.file.sink.writer.FileWriterBucket
真正的 bucket 载体,被管理在 FileWriter 中,可以通过 bucketFactory 构建。先讲讲 bucketFactory 的实现。
bucketFactory
org.apache.flink.connector.file.sink.writer.FileWriterBucketFactory
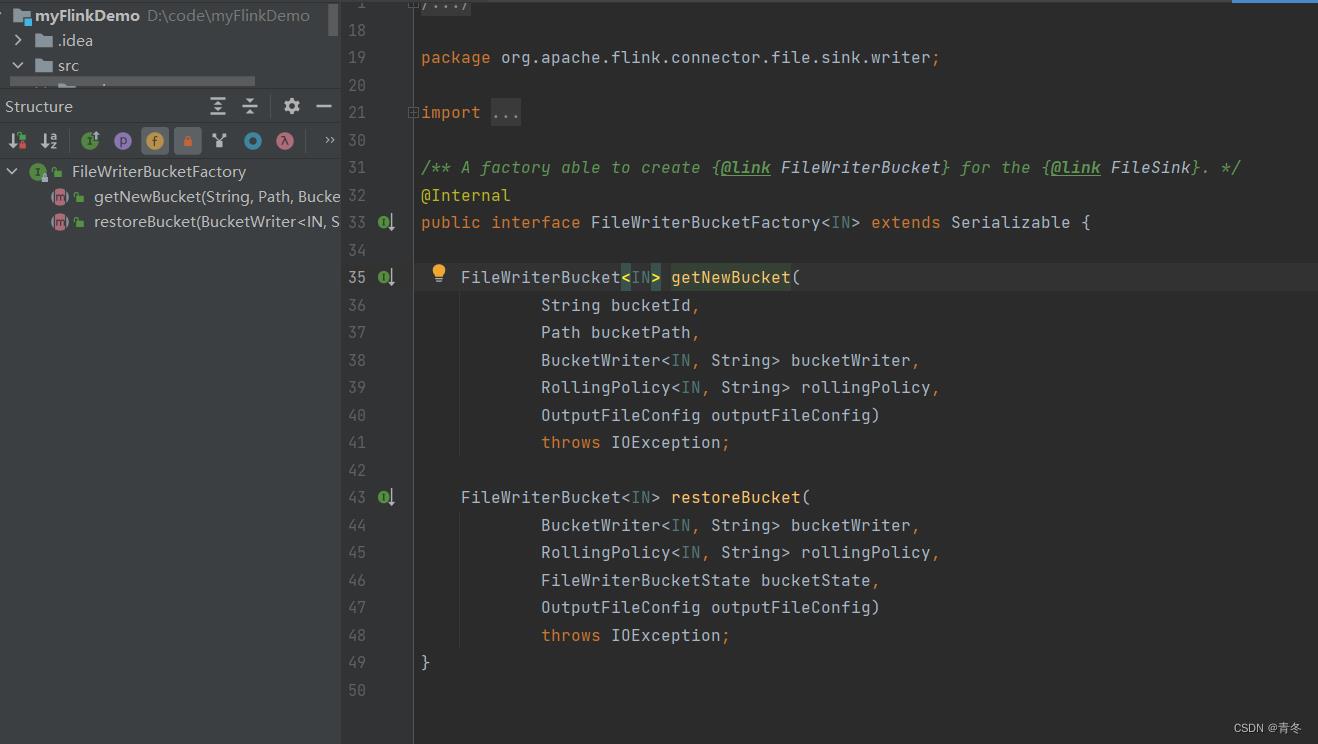
主要申明了两个接口,getNewBucket & restoreBucket。
目前实现只有 DefaultFileWriterBucketFactory,直接使用 FileWriterBucket#getNew() & restore() 两个方法对应。
所以跟我们指定 watermark 规则基本一致,通过 FileSink.forRowFormat() 构建了一个基本的 FileSink,然后不断 .withXXX() / .enbaleXXX() 来附加各种属性,来构建一个 bucketFactory,通过 bucketFactory 来创建附带各种属性的 FileWriteBucket 供 FileWriter 使用,也被 FileWriter 所管理。
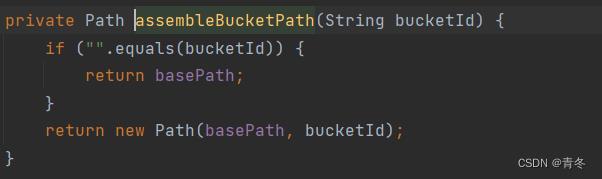
其中 bucketPath 是由两部分组成 basePath + bucketId,当 bucketId 为空时,直接返回 basePath。
FileWriterBucket 构造方法

这里面参数基本我们都已经很熟悉了,除了一个 bucketWriter。 这个参数通过 FileSink.createBucketWriter() 来传递,这个后面再说。
FileWriterBucket 属性
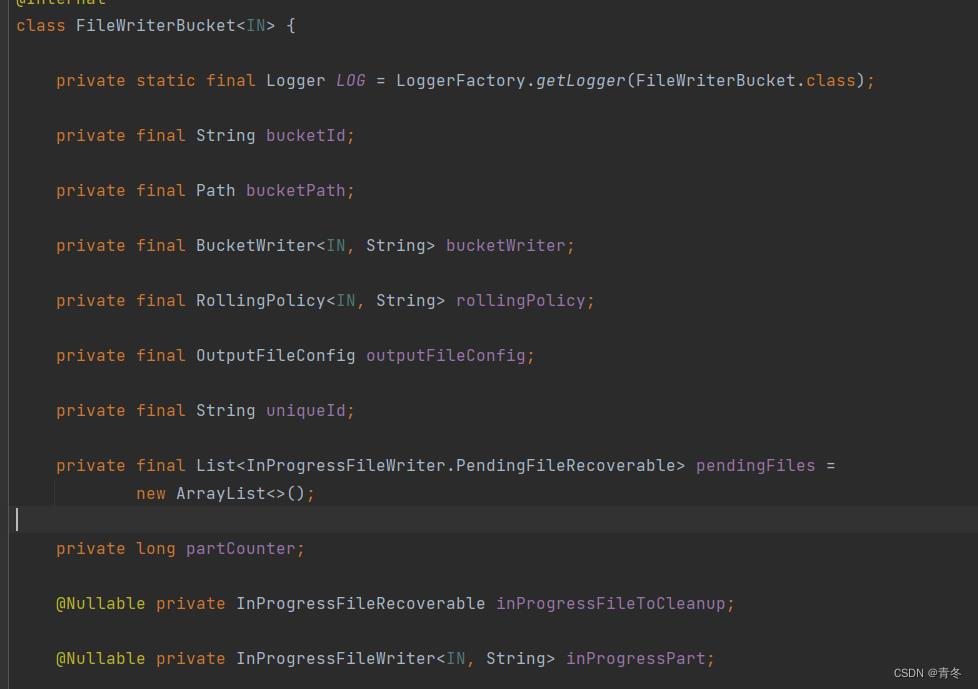
重点关注 rollingPolicy,uniqueId,pendingFiles,partCounter,inProgressFileToCleanup,inProgressPart。
rollingPolicy
org.apache.flink.streaming.api.functions.sink.filesystem.RollingPolicy
就是我们的滚动策略,这个策略指的是在 bucket 中文件的滚动策略,主要包含三种模式: oncheckpoint/onEvent/onProcessingTime
比如我们的经常使用的 DefaultRollingPolicy.builder().withXXX().build() 返回的就是 DefaultRollingPolicy。
uniqueId
生成的唯一 UUID。
partCounter
当前 bucket 的文件数。
初始化为 0。
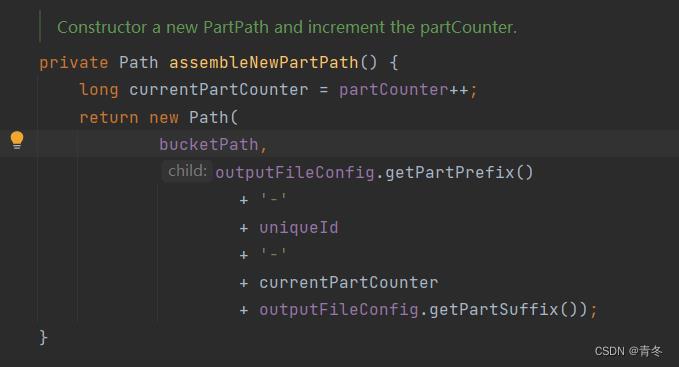
这个主要就是我们写出文件的时候的标识:<prefix>-<subtaskIndex>-<partFileIndex><suffix> 中的 partFileIndex 就是 partCounter 这个值:
pendingFiles
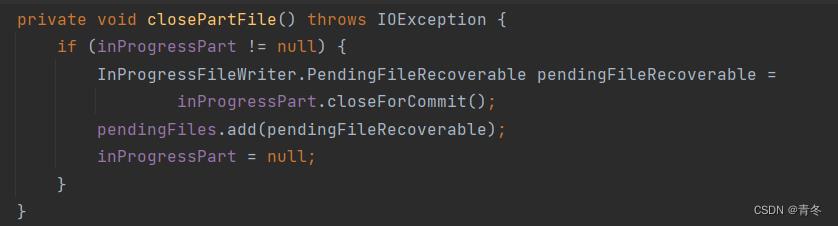
pending 文件列表,
当 closePartFile 的时候,会将 inProgressPart 中已经写完待成为 pending 的文件 add 到 pendingFiles 中:
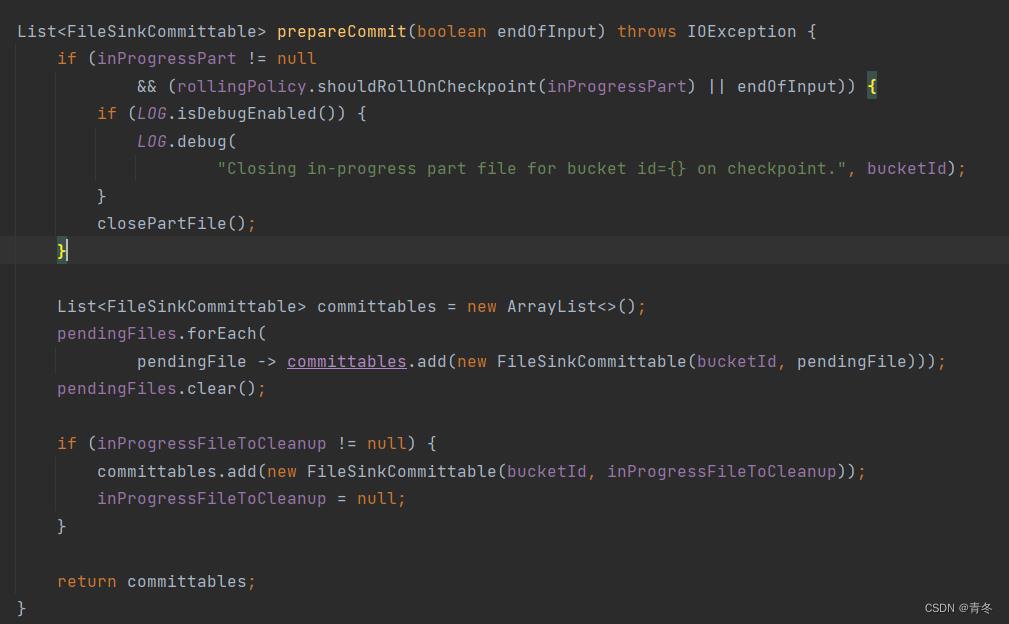
在 prepareCommit 阶段,会将所有 pendingFiles 中的文件提交出去,并进行 clear() 操作:
inProgressFileToCleanup
主要是在状态恢复的时候使用。
当状态恢复了,将之前的 inProgressPart 文件进行清理转换。
inProgressPart
org.apache.flink.streaming.api.functions.sink.filesystem.InProgressFileWriter
当前正在写入的 Part 文件,包含 bucketId,path,outpuStream,creationTime, BulkWriter(以BulkPartWriter为例)。
在写入数据时,会判断是否有正在写入的文件,如果不存在,或者当前需要进行 shouldRollOnEvent 的时候,就会关闭当前 Part文件,并创建新的 InProgressPart进行写入
org.apache.flink.connector.file.sink.writer.FileWriterBucket#write
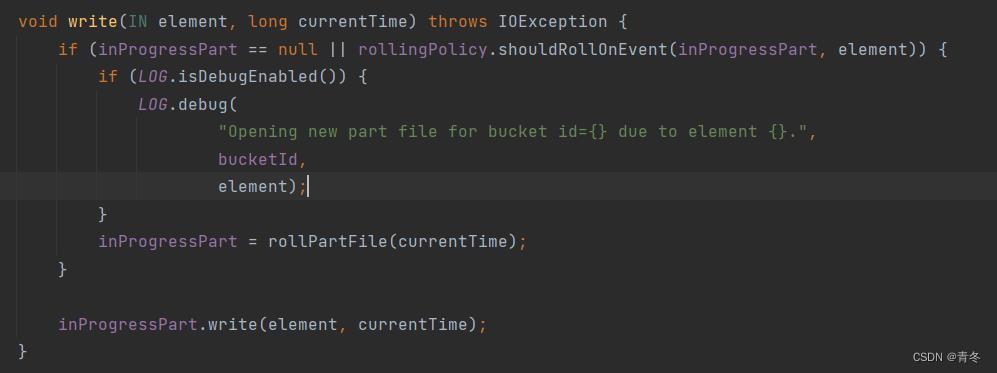
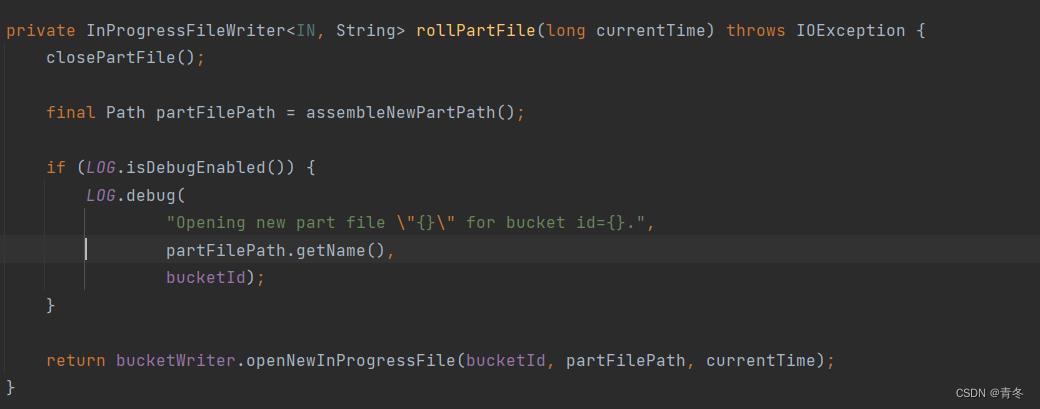
当调用 closePartFile 的时候,org.apache.flink.connector.file.sink.writer.FileWriterBucket#closePartFile 会将当前 Part 文件进行 closeForCommit() 操作,并且将结果添加到 pendingFiles 中。
总结
所以, Flink 使用 FileSink 来对外进行一整套 conf 的配置,包括基础的输出设定、bucketAssigner、RollingPolicy、outputFileConfig 和 Compact 相关的配置。
本文中 Compact 部分没有讲解实现。
然后在流程实现中包含:
- FileSink 实现的四个接口分别的作用,然后发现 FileSink 通过 FileWriter 来写入文件数据。
- 而在 FileWriter 中最重要的就是 write 方法,这个方法通过传入的 element 来获取 bucketId(bucketAssigner), 又使用 bucketId 来获取或创建 bucket(FileWriterBucket),获取是使用 activeBuckets 这个 HashMap 对象获取,创建是使用 bucketFactory 进行创建。最后调用 bucket 的 write 方法将这个 element 写入。
- FileWriter 管理了所有 activeBuckets,并且也进行着所有 buckets 的转换操作。
- FileWriterBucket 就是最小的 bucket 操作对象,包含这个 bucket 的所有 partFile,其中管理的包含 pending 的对象存在 pendingFiles 中, 正在写入的 在 inProgressPart 中。
- FileWriterBucket 的 write 方法直接调用 inProgressPart#write() 是 InProgressFileWrite 接口,最终还是由 BulkWriter 对象进行写入(如果是 Bulk实现的话)。这个方法上的注释说明,并不是一次性进行写入,可能会有缓冲区进行,实际写入还是调用 writer.flush 方法进行触发。
Demo代码
public class MyFileSinkTest
public static void main(String[] args) throws Exception
final String outputBasePath = "D:\\\\flink";
// 设置环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
final ExecutionConfig config = env.getConfig();
config.setAutoWatermarkInterval(1000L);
config.enableObjectReuse();
// check point
env.enableCheckpointing(20000L, CheckpointingMode.AT_LEAST_ONCE);
env.getCheckpointConfig().setMaxConcurrentCheckpoints(1);
env.getCheckpointConfig().setMinPauseBetweenCheckpoints(20000L);
env.getCheckpointConfig().setCheckpointTimeout(120000L);
env.setParallelism(2);
env.disableOperatorChaining();
// source
final SingleOutputStreamOperator<String> source = env.addSource(
new DataGeneratorSource<>(
new RandomGenerator<String>()
@Override
public String next()
return String.join("|"
, "" + random.nextInt(0, 1)
, "" + (System.currentTimeMillis() + random.nextInt(-1000 * 60, 1000 * 60))
);
, 10000, 1000000L)
)
.returns(Types.STRING)
.assignTimestampsAndWatermarks(
WatermarkStrategy.<String>forBoundedOutOfOrderness(Duration.ofMinutes(1))
.withTimestampAssigner((SerializableTimestampAssigner<String>) (message, l) -> Long.parseLong(message.split("\\\\|", -1)[1]))
.withIdleness(Duration.ofMinutes(1))
)
.returns(Types.STRING);
final FileSink<String> fileSink = FileSink
.forRowFormat(new Path(outputBasePath), new SimpleStringEncoder<String>("UTF-8"))
.withRollingPolicy(
DefaultRollingPolicy.builder()
.withRolloverInterval(Duration.ofMinutes(1))
.withInactivityInterval(Duration.ofMinutes(1))
.withMaxPartSize(MemorySize.ofMebiBytes(1))
.build()
)
.withBucketAssigner(new BucketAssigner<String, String>()
@Override
public String getBucketId(String element, Context context)
final long l = Long.parseLong(element.split("\\\\|", -1)[1]);
SimpleDateFormat simpleDateFormat = new SimpleDateFormat("'p_date='yyyy-MM-dd/'p_hour='HH");
final String format = simpleDateFormat.format(new Date(l));
System.out.println("format = " + format);
return format;
@Override
public SimpleVersionedSerializer<String> getSerializer()
return SimpleVersionedStringSerializer.INSTANCE;
)
.withOutputFileConfig(new OutputFileConfig("ourPrefix", "ourSuffix"))
.enableCompact(
FileCompactStrategy.Builder.newBuilder()
.setNumCompactThreads(1)
.setSizeThreshold(MemorySize.ofMebiBytes(5).getBytes())
.enableCompactionOnCheckpoint(5)
.build(),
new RecordWiseFileCompactor<>(new DecoderBasedReader.Factory<>(SimpleStringDecoder::new))
)
.build();
source.sinkTo(fileSink).uid("fileSink");
source.print();
env.execute();
以上是关于Flink FlinkSink 流式数据落盘 FileSink的主要内容,如果未能解决你的问题,请参考以下文章