Sql Server Always On 读写分离配置方法
Posted Gallen!
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Sql Server Always On 读写分离配置方法相关的知识,希望对你有一定的参考价值。
使用了Sqlserver 2012 Always on技术后,假如采用的配置是默认配置,会出现Primary server CPU很高的情况发生,比如默认配置如下:
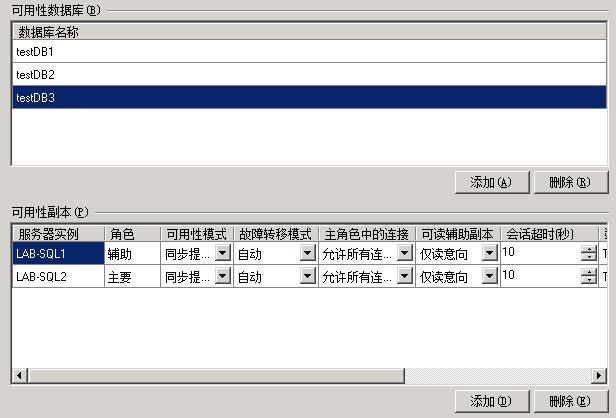
需要自定义来解决这个问题。
我们先来看看上图中的这些选项的意义
主角色中的连接
- 允许所有连接
- 如果当前server是primary角色时,primary instance允许所有连接(如:读/写/管理)
- 允许读/写连接
- 如果当前server是primary角色时,primary instance只允许读/写连接(如果通过ssms连接,将报错、sqlcmd也是报错)
可读辅助副本
- 是
- 如果当前server是primary角色时,所有的secondary servers都是可以看的(通过ssms能看结构、数据,但不能更改)
- 仅读意向
- 如果当前server是primary角色时,所有的secondary servers只允许读连接(需要在建立连接时加入key来标明为只读连接:ApplicationIntent=ReadOnly)
- 否
- 如果当前server是primary角色时,所有的secondary servers都不可以看(通过ssms能连接,但是看不了,会报错,如下)

建立读写分离的方法:
第一种
- 设置某具体“可用性组”的属性为:可读副本为“是”
- 客户端通过直连副本方式实现将select的流量转发过去
- 暴露出去的ip地址至少2个:侦听器ip和副本ip(如果副本多个,则可用ip哈希来进行更多的自定义)
第二种
- 设置某具体“可用性组”的属性为:可读辅助副本为“仅读意向”

- 执行sql脚本,建立read指针
- 执行sql脚本,建立primary, read db ur list关系
- 暴露出去的ip地址只有1个:侦听器IP
第一种方式能够进行更多地自定义,但是已经脱离sqlserver always on技术了,因此不讨论了
第二种方式对于客户端来讲更傻瓜点,但是自定义力度小,全依托于ms未来怎么改进这块了,而且这里有些坑。。。
下面来说说这些坑:
坑1:UI图形界面设置后,还需要执行脚本来建立读写分离支持
建立read指针 - 在当前的primary上为每个sqlserver instance建立[instance name=>instance tcp url] Map

--由于这里有2个instance(包括了primary角色的), 因此在primary上分别为这2个instance建立关系 ALTER AVAILABILITY GROUP [alwayson] MODIFY REPLICA ON N\'LAB-SQL1\' WITH (SECONDARY_ROLE (READ_ONLY_ROUTING_URL = N\'tcp://LAB-SQL1.lab-sql.com:1433\')) ALTER AVAILABILITY GROUP [alwayson] MODIFY REPLICA ON N\'LAB-SQL2\' WITH (SECONDARY_ROLE (READ_ONLY_ROUTING_URL = N\'tcp://LAB-SQL2.lab-sql.com:1433\'))
建立primary, read db ur list关系 - 在当前的primary上为各个primary建立对应的read only url 列表(有优先级概念)
--为每个可能成为primary角色的server,建立相应的只读列表,下面的代码由于互为readonly server,因此优先级都是1 ALTER AVAILABILITY GROUP [alwayson] MODIFY REPLICA ON N\'LAB-SQL2\' WITH (PRIMARY_ROLE (READ_ONLY_ROUTING_LIST=(\'LAB-SQL1\'))); ALTER AVAILABILITY GROUP [alwayson] MODIFY REPLICA ON N\'LAB-SQL1\' WITH (PRIMARY_ROLE (READ_ONLY_ROUTING_LIST=(\'LAB-SQL2\'))); --假如又增加了一台lab-sql3的secdonary,则sql可变为 ALTER AVAILABILITY GROUP [alwayson] MODIFY REPLICA ON N\'LAB-SQL2\' WITH (PRIMARY_ROLE (READ_ONLY_ROUTING_LIST=(\'LAB-SQL1\', \'LAB-SQL3\'))); ALTER AVAILABILITY GROUP [alwayson] MODIFY REPLICA ON N\'LAB-SQL1\' WITH (PRIMARY_ROLE (READ_ONLY_ROUTING_LIST=(\'LAB-SQL2\', \'LAB-SQL3\'))); --上述语句中的列表是有优先级关系的,排在前面的具有更高的优先级
可以通过如下语句查看这个关系,以及相应的优先级:
select ar.replica_server_name, rl.routing_priority,
(select ar2.replica_server_name
from sys.availability_read_only_routing_lists rl2
join sys.availability_replicas AS ar2 ON rl2.read_only_replica_id = ar2.replica_id
where rl.replica_id=rl2.replica_id and rl.routing_priority =rl2.routing_priority
and rl.read_only_replica_id=rl2.read_only_replica_id) as \'read_only_replica_server_name\'
from sys.availability_read_only_routing_lists rl join sys.availability_replicas AS ar ON rl.replica_id = ar.replica_id

这里的routing_priority就是优先级
坑2:客户端需要指定访问的数据库以及加入ReadOnly关键字
C#连接字符串
-
- server=侦听器IP;database=testDB3;uid=sa;pwd=111111;ApplicationIntent=ReadOnly
SSMS方式



坑3:Hosts文件设置
由于sql server always on依赖于windows集群,而windows集群依赖于活动目录,而客户端程序所在server很可能没有加入域,因此这里的解析存在问题
由于这种读写分离的方式,实际上是客户端先连接到侦听器ip,然后通过协商后,让客户端再连接到具体的副本上(用tcp url,使用了全名的,如:sql1.ad.com这种格式,在ad外部默认无法解析),因此需要修改hosts文件,为每个可能成为read的全名增加记录,如下:
192.168.0.1 LAB-SQL1.lab-sql.com 192.168.0.2 LAB-SQL2.lab-sql.com
总结
- 简单情况下的读写分离比较适用
- 只适用于粗粒度的读写分离,因为增加了一个额外的ConnectionString,而不是建立在普通连接字符串上的
- 如果读写分离的分发规则复杂,则不适用
以上是关于Sql Server Always On 读写分离配置方法的主要内容,如果未能解决你的问题,请参考以下文章
Windows Server 2012搭建SQL Server Always On踩坑全记录
SQL SERVER ALWAYS ON 之 添加新的同步数据库
Configure Always On Availability Group for SQL Server on RHEL——Red Hat Enterprise Linux上配置SQL Server