解锁tRPC高性能密码:网络方案简介
Posted QcloudCommunity
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了解锁tRPC高性能密码:网络方案简介相关的知识,希望对你有一定的参考价值。
导语 |本文介绍了部分高性能网络方案,包括RDMA、HARP、io_uring等。从技术原理、落地可行性等方面,简要地做出分析,希望能对此方面感兴趣的开发者提供一些经验和帮助。
一、背景
业务中经常会有这样的场景:
随着网卡速率的提升(10G/25G/100G),以及部分业务对低延迟的极致追求(1ms/50us),目前的内核协议栈由于协议复杂、流程复杂、设计陈旧等因素,已经逐渐成为业务瓶颈。
业界已经有部分RDMA、DPDK的实践,但是对于大多数开发者而言,依然比较陌生。
那么这些方案各自的场景究竟怎样?是否能够为更多的业务赋能?以下是阶段性简要总结。
二、RDMA
(一)原理简介
相对于传统的网络协议栈,RDMA提供的关键特性即为:Kernel Bypass,也即利用专用的NIC(网卡)进行硬件层面的协议传输、编解码(Offload),通过内存映射技术直接与用户态程序交互,从而避免了复杂低效的内核中介。
基于这种设计,随之提供几个额外的重要特性:
- Zero-Copy:基于DMA操作,通信全程没有额外的CPU介入拷贝,从而降低CPU消耗。
- 稳定低延迟:由于硬件通路的可靠性,从而保证了稳定的通信延迟。
- 多种传输模式:RC、RD、UC、UD等。基于不同业务的不同可靠性和性能需求,提供类似TCP/UDP的多种传输模式。
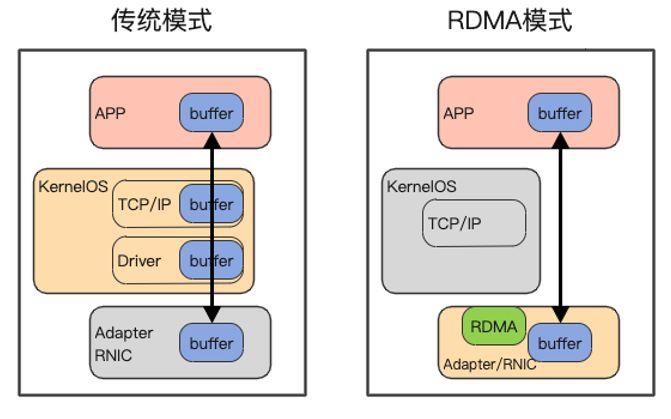
由于RDMA定位为高性能网络传输,同时也为了简化硬件的设计,一般来说,RDMA会避免如软件TCP那样复杂的可靠性设计,而是极其依赖底层传输网络的可靠性。
根据不同的传输网络,RDMA的具体实现分为几类:

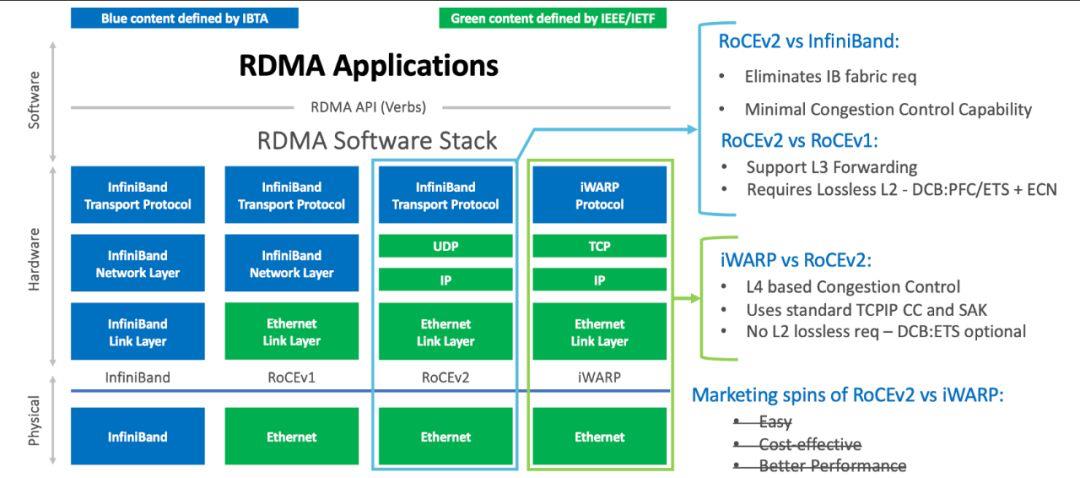
另外补充说明:
- 虽然RoCE v1/2依赖融合融合以太网,也即无损传输,不过也有部分厂商的优化实现,可以减轻对无损传输的依赖。
- Linux kernel 4.9+中,实现了Soft-RoCE,也即软件版本的RoCE v2,主要用于测试、学习。
(二)RoCE v2 v.s. iWARP
在以太网环境,主要可选项为RoCE v2和iWARP,相关对比如下:
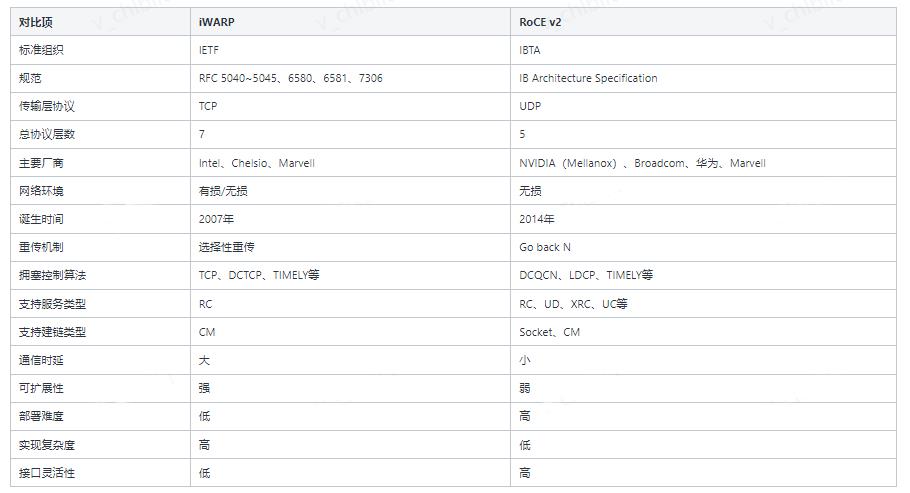
目前来看,目前的机房网络建设中,对RoCE v2的支持更好,而iWARP却仍然处于相对空白的状态。
为此,当前的调研主要针对RoCE v2,而iWARP仍然有待探索。
(三)业务落地
后台业务主流协议仍然是TCP,具有运行稳定、调试工具丰富等优势。不过对于少数期望高性能的业务,RDMA也是值得考虑的。
业务使用RDMA主要面临两方面的困难:
- RoCE v2无损网络的要求导致难以跨机房传输,当前腾讯机房的支持为module内传输(如5跳之内)。
- 全新的开发接口如libverbs、UCX等,业务软件需要进行适配。
而有些存储业务依赖多副本,网络传输需要能够跨越MAN,甚至跨城市传输。这直接导致RoCE v2难以落地。
三、io_uring/socket
(一)原理简介
io_uring是Linux 5.1+中支持的异步IO框架,其核心优势有:
- 真正的异步化设计(Proactor),而非如epoll等本质上的同步行为(Reactor)。而其关键在于,程序和kernel通过SQ/CQ两个队列进行解耦。
- 统一的异步IO框架,不仅支持存储、网络。由于良好的扩展性,甚至可以支持任何的系统调用,如openat、stat等。
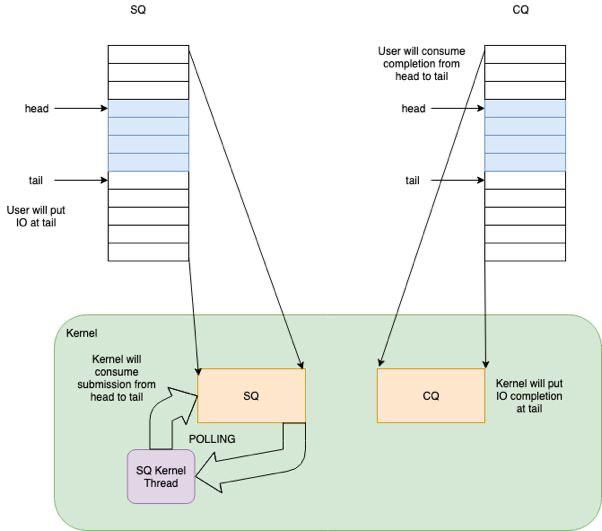
如前述,一个io_uring的实例,会建立一对内核和用户程序共享的队列,也即提交队列SQ和完成队列CQ,两者皆为SPSC范型:
- SQ:用户态线程生产,然后系统调用(io_uring_enter)通知内核(io_wq kernel
thread)消费。其中元素称为SQE。 - CQ:内核生产,然后通知(若用户程序睡眠等待则唤醒)用户态消费。其中元素称为CQE。
这其实是最常规也是最经典的异步模型,在众多异步设计中可见。
一般情况下,CQE和SQE一一对应,不过io_uring支持multi-shot模式后则不一定如此。
另外,io_uring支持批量生产和消费,也即连续生产多个SQ后,一次性通知内核,或者持续消费CQ直到其空。
为了进一步优化部分场景的性能,io_uring支持众多的高级特性:
- File Registration:在反复操作同一个fd时,加速其查找映射。
- Buffer Registration:在read/write等反复需要在内核和用户程序交换数据的场景,可以重复利用预注册的一批内存。
- Automatic Buffer Selection:为Proactor
read预注册一批内存,在就绪后内核自动选择其中一块存放数据,从而减少内存分配释放,也节约内存资源。 - SQ Polling:使内核(io_wq)轮询SQ指定时间才睡眠,从而减少通知的系统调用。
- IO Polling:开启子系统(存储、网络等)的轮询模式(需要设备驱动支持),从而加速部分高速设备。另外可以配合io_uring_enter(flag:IORING_ENTER_GETEVENTS)进行忙等。
- Multi-Shot:一次提交,多次完成,如只要一次提交socket accept,后续连接到来后多次返回。
io_uring在存储IO场景,相对之前的阻塞IO、glibc aio、linux aio等,都有不错的性能提升。
那么在网络IO场景呢?是否优于epoll等方案呢?
(二)测试数据
经过调研,在知名开源软件中,暂未发现直接采用io_uring进行网络IO的方案,如seastar/nginx等都没有官方支持,既然可借鉴较少,那么就自行测试。
由于io_uring还处于完善阶段,而且对于网络IO的支持也有多种方式。目前我们梳理出其中3种:
- Proactor:io_uring直接recv/send。
- Reactor:io_uring接管socket_fd(POLL_ADD)后再recv/send。
- io_uring接管epoll_fd后再epoll_wait再RECV/SEND:路径繁琐,推测性能不佳,直接略过。
为此,我们针对前两种io_uring模型,以及常用的epoll模型,进行测试对比。
为了利用更多的io_uring特性,测试采用当前最新kernel(5.15)。测试模型如下:
- 通信协议:tcp echo
- 服务模型:单线程,异步并发
- 压测客户端:多线程,每个线程一个连接同步测试
- 数据:包大小为512B
- 测试环境:本机通信loopback接口
epoll
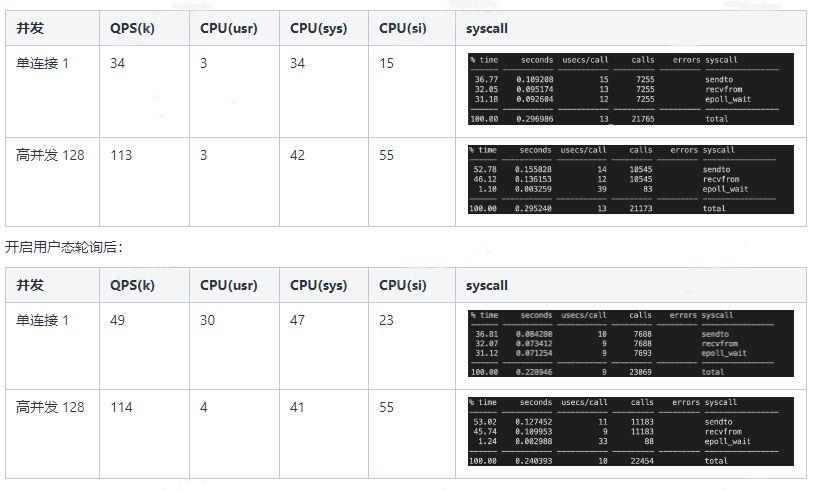
- io_uring(Proactor)
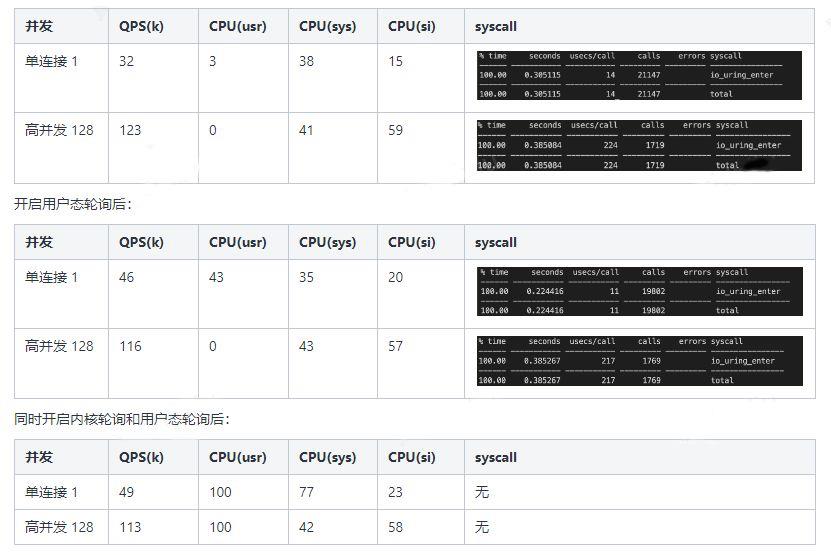
- io_uring(Reactor)
目前网上的很多程序采用此方式。不过从理论上分析,应该epoll性能接近,故暂未测试。
(三)数据分析
通过对比、分析以上的测试数据,可以得到以下结论:
- io_uring在网络IO方面,并不比epoll性能强大。网络IO的主要瓶颈还是在于内核协议栈的开销。
- io_uring即使开启内核轮询,在负载低时可降低延时,而满载性能提升不明显,反而浪费了CPU资源。
(四)业务落地
在Linux网络IO场景中,io_uring并不比epoll带来额外的性能提升。这与存储IO不同。
不过值得思考的是,如果一个系统中同时存在网络IO和存储IO,对比以下两种方式:
- 网络IO采用epoll,存储IO采用io_uring(可结合eventfd与epoll配合)
- 网络IO、存储IO都采用io_uring。
从理论上分析,方式2可以依赖io_uring批量提交等优化,从而进一步减少系统调用,是否可以带来性能提升呢?
这部分需要进一步测试分析。
四、总结
以上简单介绍了RDMA、io_uring/socket等方案,各有优缺点以及场景限制。后续将介绍DPDK的方案,敬请期待。
作者简介
quintonwang,腾讯后台开发工程师。
以上是关于解锁tRPC高性能密码:网络方案简介的主要内容,如果未能解决你的问题,请参考以下文章