大数据生态安全框架的实现原理与最佳实践(上篇)
Posted 明哥的IT随笔
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据生态安全框架的实现原理与最佳实践(上篇)相关的知识,希望对你有一定的参考价值。
前言
数字化转型大背景下,数据作为企业重要的战略资产,其安全的重要性不言而喻。
我们会通过系列文章,来看下大数据生态中安全框架的实现原理与最佳实践,系列文章一共两篇,包含以下章节:
- 大数据生态安全框架概述
- HDFS 认证详解
- HDFS 授权详解
- HIVE 认证详解
- HIVE 授权详解
- 金融行业大数据安全最佳实践
本片文章是上篇,包含上述前三个章节,希望大家喜欢。
1. 大数据生态安全框架概述
数据安全/网络安全领域,有个AAA框架,同样适用于大数据:
- Authentication 认证: 事中:who is trying to access
- Authorization 授权/鉴权: 事前和事中:what resources are allowed to access
- Accounting/Audit/ 审计: 事后:what is being accessed by whom at what time
1.1 Authentication 认证
认证是 AAA 中的第一步,是安全的基础,用户必须证明其身份: The system needs to make sure the person accessing a system is who they say they are.
常见的认证机制有:
- What They Know: 密码或安全问题(password, security questions);
- Who They Are: 指纹或其他生物特征;
- What They Have: Access cards, token (jwt)
在实际应用中,上述认证方法经常被结合起来使用;
1.2 Authorization 授权/鉴权
- Authorization 授权/鉴权,包括事前的授权,事中的鉴权;
- 授权一般需要遵循最小化原则;
- 鉴权确保用户没有访问该用户没有被授权访问的资源;
- 经常使用基于角色的授权与鉴权机制 Role-Based Access Control (RBAC)
1.3 Accounting/Audit 审计
- Accounting/Audit: 审计:记录什么用户在什么时间对什么资源进行了什么访问 (what is being accessed by whom at what time for how long)
- 审计是事后的安全监督措施,可以辅助判断当前的 authenticating 和 authorization 策略是否恰当,是否需要调整,从而形成安全闭环;
- HDFS 在 Audit 上,默认通过log4j在/var/log/Hadoop-hdfs目录下打印了audit日志;


1.4 Encryption 加密
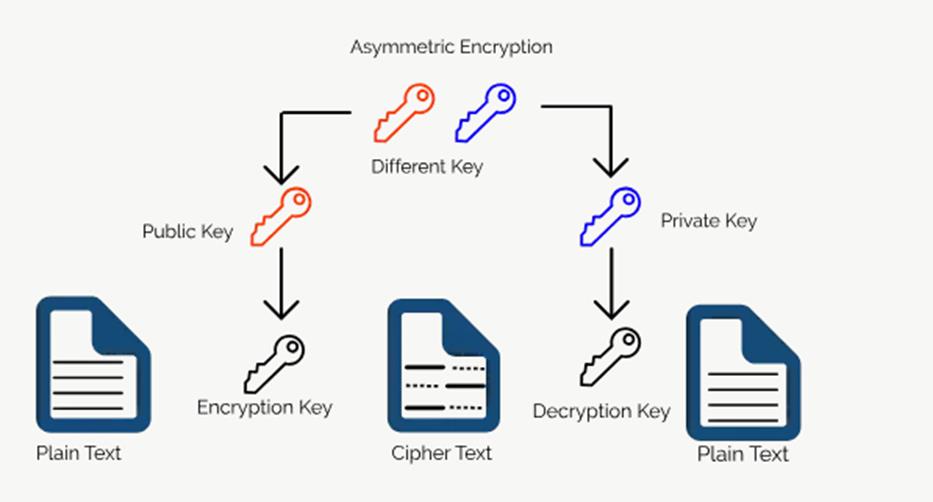
数据安全/网络安全领域,还涉及到 Encryption 加解密,经常接触到到 https, ssh 都用到了加解密算法。
- 加解密的算法,包括对称加密算法和非对称加密算法:DES, AES, RSA(ssh)
- Ssh 底层使用的 RSA加密算法是非对称加密算法;
- 大数据集群中,出于运维方便,经常需要配置 Ssh 免密码登录,此时拷贝给其它机器的是自己的公钥/root/.ssh/id_rsa.pub, /root/.ssh/authorized_keys;
- 加解密包括对静态数据的加解密,和对传输过程中的数据的加解密:data at rest, data in motion/in transit
- 常见的术语有:FDE: full disk encryption, file encryption, End-to-End (e2e) encryption


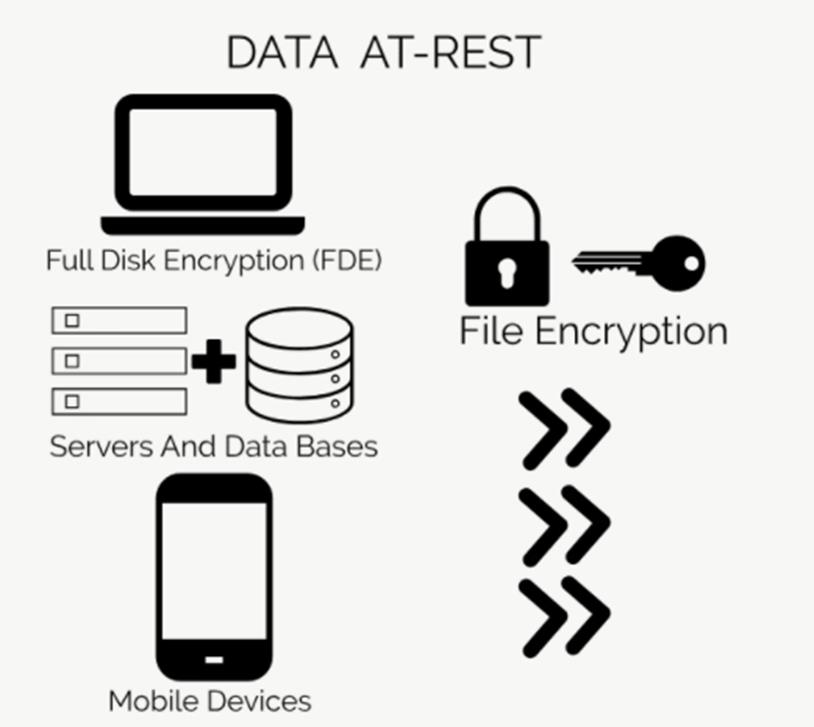
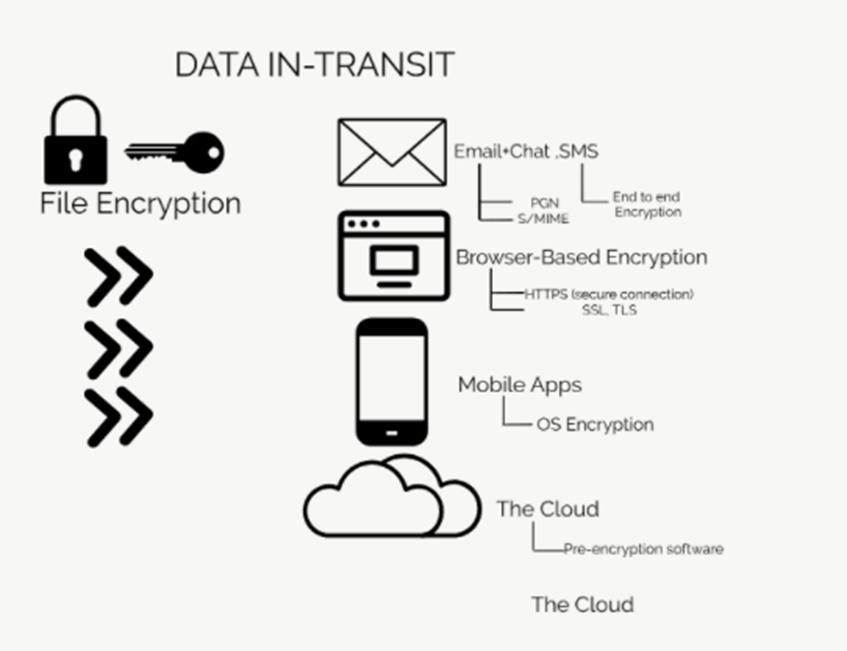
- HDFS 在 Encryption上,实现了 end-to-end Transparent Encryption, 包含了 at-rest encryption 和 in-transit encryption ,底层通过 KMS(Key Management Server) 服务支持了多个encryption zone;
1.5 总结
- AAA + Encryption 的安全框架,同样适用于大数据。
- 本次分享,我们侧重于Authentication 和 authorization, 不会过多讲述 audit 和 encryption;
- 本此分享,我们侧重于大数据存储框架的安全,主要是 HDFS 和 HIVE;
- 大数据生态中的 authentication 认证,事实上的标准是使用 Kerberos 协议, 我们后文会有详细讲述;
- 大数据生态中的各种存储系统,如HDFS/hive/hbase/zookeeper/kafka等,都支持开启Kerberos安全认证;
- 当大数据集群中的存储系统如HDFS/hive/hbase/zookeeper/kafka等开启了kerberos安全认证后,访问这些存储系统的客户端,包含各种计算引擎如 hive/hbase/spark/flink 的系统服务,和用户编写的各种应用如 spark/hive/flink等,都需要经过 kerberos 认证后才能访问对应的服务(当然还需要 authentication 鉴权!)
2. HDFS 认证详解
HDFS在认证上,支持两种方式,通过参数 hadoop.security.authentication 来进行控制,可选的参数有: simple (no authentication) 和 kerberos,该参数是服务端参数,不能在客户端覆盖!
2.1 HDFS认证详解-hadoop.security.authentication = simple
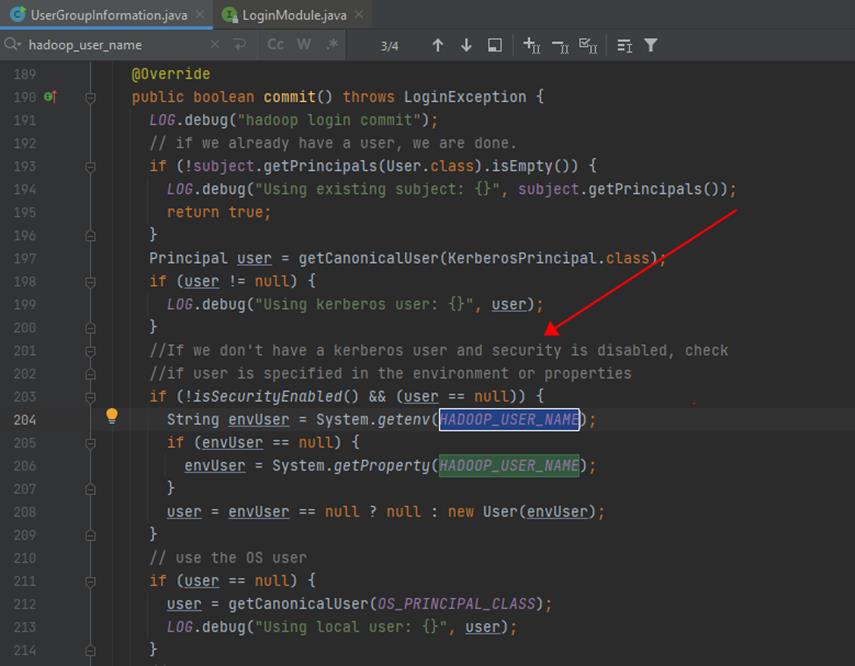
- 此时用户身份由环境变量或系统参数 HADOOP_USER_NAME 决定,当该环境变量/系统参数不存在时,由当前LINUX登录用户身份决定;
- 所以在没有开启KERBEROS时,我们可以切换到业务用户身份下提交命令,或通过以下方式指定登录用户:
- System.setProperty(UserGroupInformation.HADOOP_USER_NAME, “randomUser”);
- Export HADOOP_USER_NAME = randomUser;
2.2 HDFS认证详解-hadoop.security.authentication=kerberos
- Kerberos 是一种计算机网络授权协议(network authentication protocol),用来在非安全网络中,对个人通信以安全的手段进行身份认证;
- Kerberos 协议常见的实现有 MIT kerberos (麻省理工学院开发),ApacheDS (embedded kerberos),freeIPA 等;


kerberos 常见运维操作有:
- 查看kdc服务状态与日志:systemctl status krb5kdc/systemctl status kadmin/journalctl -u krb5kdc
- 查看kerberos配置:/etc/krb5.conf
- Kerberos 底层使用了 tcp与udp协议,主要包括88与749 端口;
- Kerberos 要求所有节点的时钟是同步的,以避免重放攻击 replay attack;

常用的 Kerberos 命令有:
- Klist/klist –kt xx
- Kinit/kinit –kt xxx
- Kdestroy
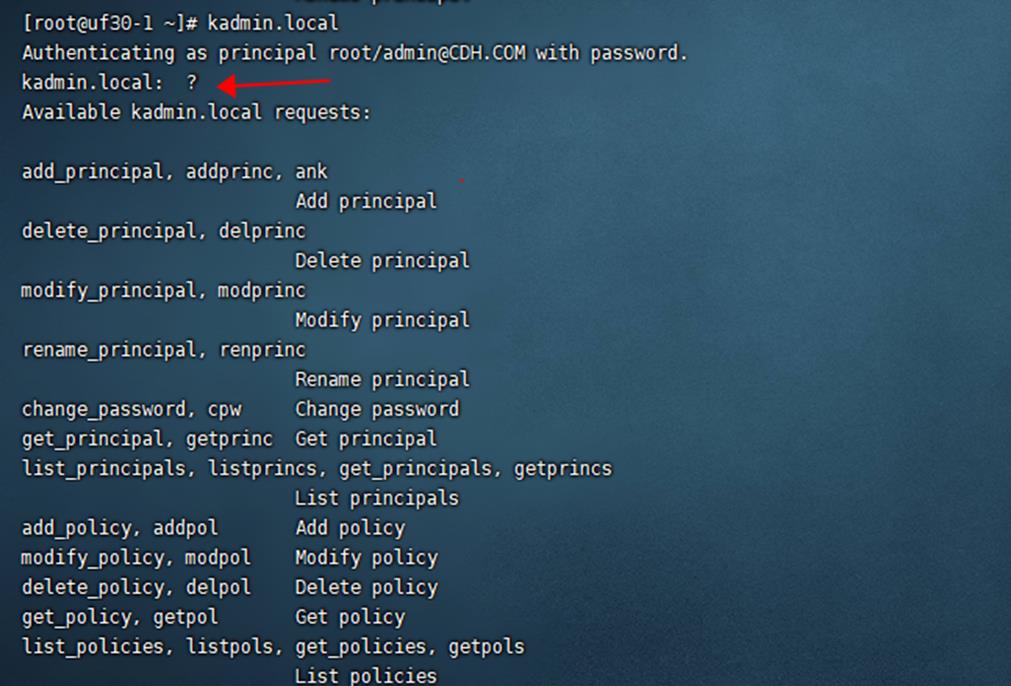
管理 principal与keytab, 经常使用 Kadmin.local:
- addprinc -randkey xx/delprinc xx/modprinc/getprinc/listprincs
- kadmin.local -q “getprinc liming@TEST.COM” | grep -i life
- xst -norandkey -k dap.keytab dap/uf30-1@CDH.COM
- Cpw/change_password,Ktadd/xst/ktremove

关于 Keytab 和 KRB5CCNAME/Ccache:
- KRB5CCNAME/Ccache: by default is /tmp/krb5cc_0 in linux;
- Kinit –R:you can use kinit -R to renew your tgt when the ticket has not expired and is still within the renewable life, after successful renew, the new KRB5CCNAME, will be modified;
2.3 HDFS认证详解-groups 如何确定
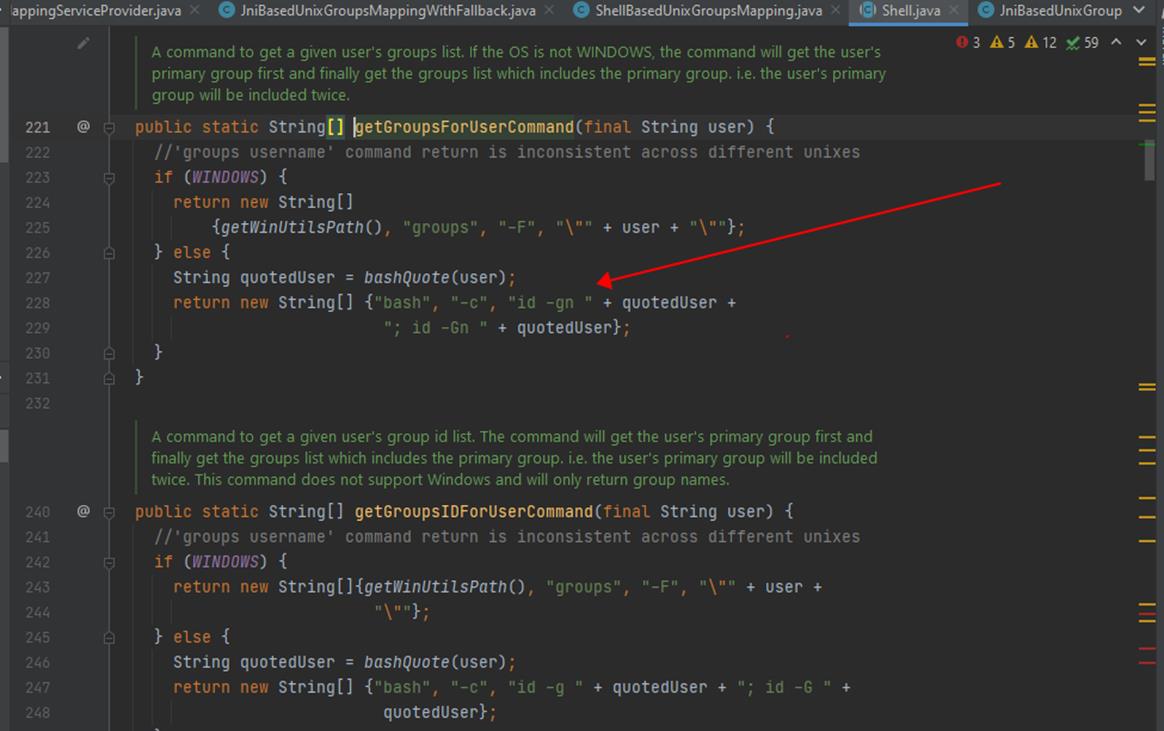
- 确定了user后,如何确定其 groups 是由参数 hadoop.security.group.mapping 决定的。
- 该参数的默认值是 org.apache.hadoop.security.JniBasedUnixGroupsMappingWithFallback;
- Hadoop also supports special group mapping mechanisms through LDAP and composition of LDAP and operating system group name resolution, which require additional configurations
- 在默认配置下,确定的groups的值,等同于LINUX 下 bash –c groups/id –gn/id -Gn

2.4 HDFS认证详解-相关参数
相关参数有:
- hadoop.security.authentication
- hadoop.security.group.mapping
- hadoop.proxyuser.xxx.groups
- hadoop.proxyuser.xxx.hosts
3. HDFS 授权详解
接下来我们看下 hdfs 的 authentication 授权和鉴权。
3.1 HDFS授权详解-posix mode
HDFS在授权上,大体上遵循了类 linux文件系统的 posix 模型机制:
- 每个文件和目录都有对应的 owner/group, 并可以针对 owner/group/others 分别进行授权;
- 对文件来说,读文件需要 R 权限,写或追加写需要 W 权限,X 权限没有意义(因为hdfs文件没有所谓的executables files 可执行文件);
- 对目录来说,查看目录下内容需要R权限,在该目录下创建和删除文件或目录需要 W 权限,访问该目录下的文件或目录需要x权限;
- Hdfs 可以对目录设置 sticky bit,防止目录下文件被误删除:The sticky bit can be set on directories, preventing anyone except the superuser, directory owner or file owner from deleting or moving the files within the directory.
- HDFS 对文件设置 sticky bit 没有任何效果:Setting the sticky bit for a file has no effect.
- 不同于标准 POSIX 模型的一点是,hdfs 的目录和文件都没有 setuid/setgid bits; (hdfs文件没有所谓的executables files 可执行文件);
- 创建目录或文件时,其默认的 owner/group 是这样决定的:its owner is the user identity of the client process, and its group is the group of the parent directory (the BSD rule);
- 创建文件或目录时,其默认的 MODE 是由 umask 参数决定的: fs.permissions.umask-mode
- Umask 默认的配置是 022,此时默认所有用户对所有目录和文件都有读权限:this is typically 755 for new directories and 644 for new files:022 is octal for u=rwx,g=r-x,o=r-x in symbolic;
- Umask 常见的配置还有007和077,其中后者默认阻止了非owner用户对所有目录和文件的访问权限,是最为严苛的授权;(007 is octal for“u=rwx,g=rwx,o=”in symbolic;)

3.2 HDFS授权详解-superuser
- HDFS 有超级用户super-user 的概念:启动 namenode 进程的用户即是超级用户,HDFS的超级用户拥有所有权限,类似 LINUX 的超级用户 ROOT;(超级用户是动态的,不需要通过参数配置,谁启动 namenode 谁就是超级用户,该用户一般是 hdfs)
- HDFS 有超级用户组 superusergroup 的概念: 超级用户组下的所有用户都是超级用户,超级用户组只能是一个而不能是多个,通过参数 dfs.permissions.superusergroup 进行配置,默认是 supergroup;
- HDFS Web Server 用户的身份: 需要通过参数进行配置,比如:dfs.web.ugi = webuser,webgroup ( 新版本是 hadoop.http.staticuser.user),当该用户不是超级用户时,通过 web server 可能不能查看到文件系统的所有内容

3.3 HDFS授权详解-posix acl
除了传统的 POSIX 权限模型,HDFS 也支持 POSIX ACLs (Access Control Lists);
- 通过 ACL,可以对目录或文件的 owner/group 之外的特定用户或用户组,授予不同于 others 的特定的权限,相比 owner/group/others 的粗粒度的授权,粒度更细也更为灵活;
- ACL 分为两种:access acl 和 default acl,其中前者用来在访问文件或目录内容时进行权限校验,后者用来确定在配置了 ACL 的目录下创建子目录或子文件时,这些自目录子文件的 access acl 和 default acl; (只有目录才有default ACL)
- 对特定的目录或文件,可以声明的 ACL entry 的个数是由上限的,最大为64:The maximum number is 32 for access and 32 for default entries which is 64 in total.
- ACL 对 namenode 造成了额外的压力:A file with an ACL incurs an additional cost in memory in the NameNode compared to a file that has only permission bits.
- 最佳实践是:Best practice is to rely on traditional permission bits to implement most permission requirements, and define a smaller number of ACLs to augment the permission bits with a few exceptional rules.
- ACL 常见命令:
- 查看 acl: hdfs dfs -ls :针对设置了ACL的文件或目录,注意输出中有‘+’ character
- 查看 acl:hdfs dfs -getfacl [-R]
- 设置 acl: hdfs dfs -setfacl [-R] [-b |-k -m |-x <acl_spec>
] |[–set <acl_spec> ]
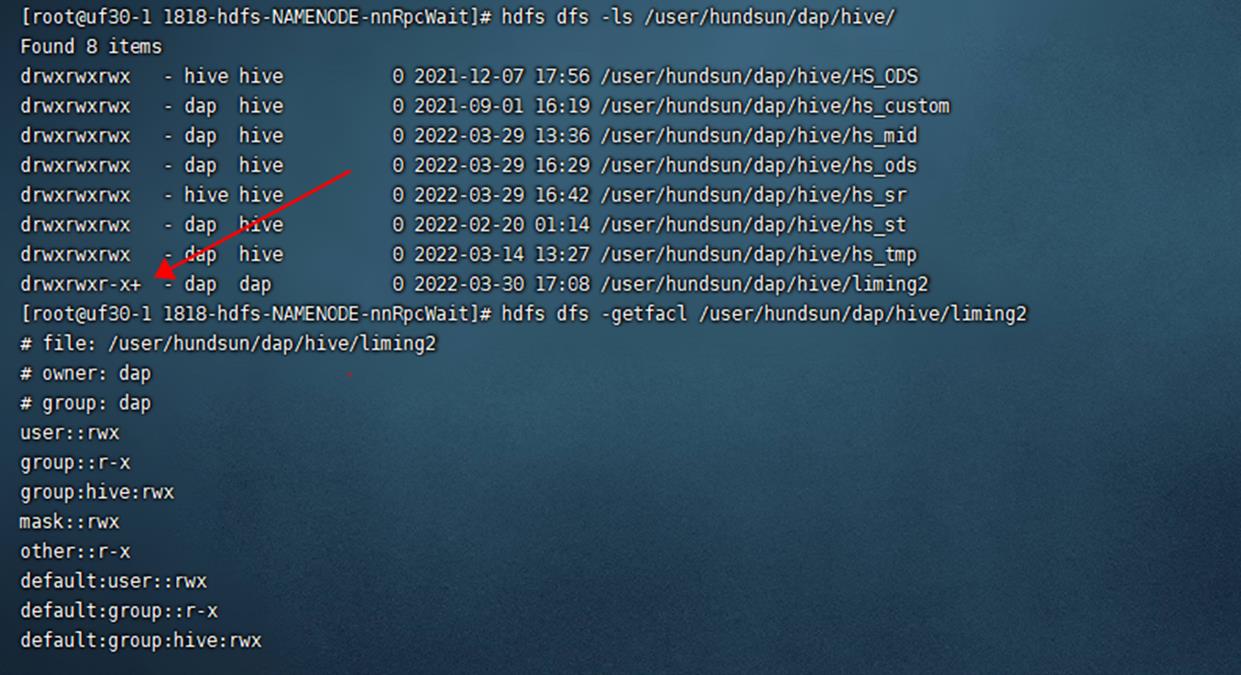
- 对HIVE外表配置ACL,示例命令如下: (access acl+default acl)
- hdfs dfs -getfacl /user/xx/dap/hive/liming2
- hdfs dfs -setfacl -R -m group:hive:rwx /user/xx/dap/hive/liming2
- hdfs dfs -setfacl -m default:group:hive:rwx /user/xx/dap/hive/liming2

- ACL 示例输出如下:(Each ACL entry names a specific user or group and grants or denies read, write and execute permissions for that specific user or group)
3.4 HDFS授权详解-鉴权-hdfs native
- HDFS在鉴权上,通过参数 dfs.permissions.enabled 来进行控制,可已配置鉴权也可以配置不鉴权 false/true;
- 该参数默认是 true,当该参数配置为 false 时,将不会进行任何 permission checking;
- 更改该参数的值,不会改变文件和目录的 mode/owner/group/acl等;
- 该参数是服务端参数,不能在客户端覆盖!
3.5 HDFS授权详解-鉴权-ranger
除了使用 hdfs 的 native 鉴权机制,还可以结合使用 ranger 的权限机制:
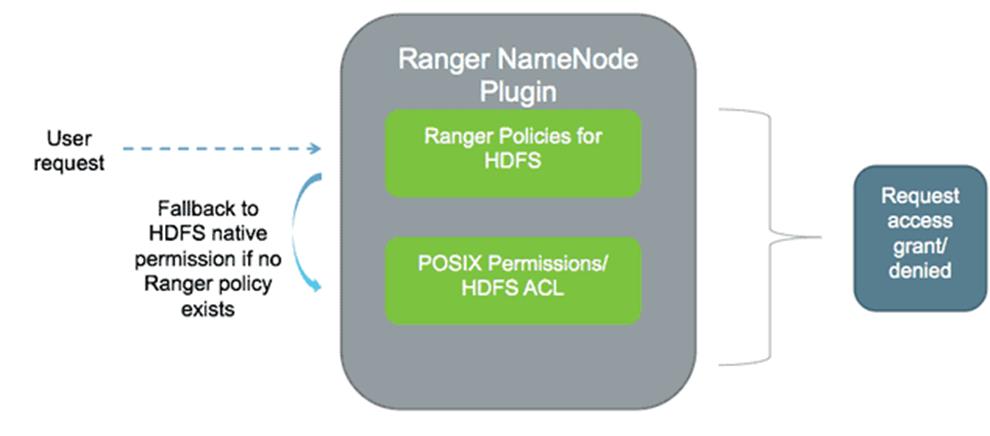
- Apache Ranger 基于插件机制,提供了对 Hadoop 生态众多组件的集中的权限管控机制:a centralized security administration solution for Hadoop;
- Ranger hdfs 插件是对 hdfs native permission model 的补充:Ranger plugin for HDFS checks for Ranger policies and if a policy exists, access is granted to user. If a policy doesn‘t exist in Ranger, then Ranger would default to native permissions model in HDFS (POSIX or HDFS ACL).
3.6 HDFS授权详解-proxy代理机制
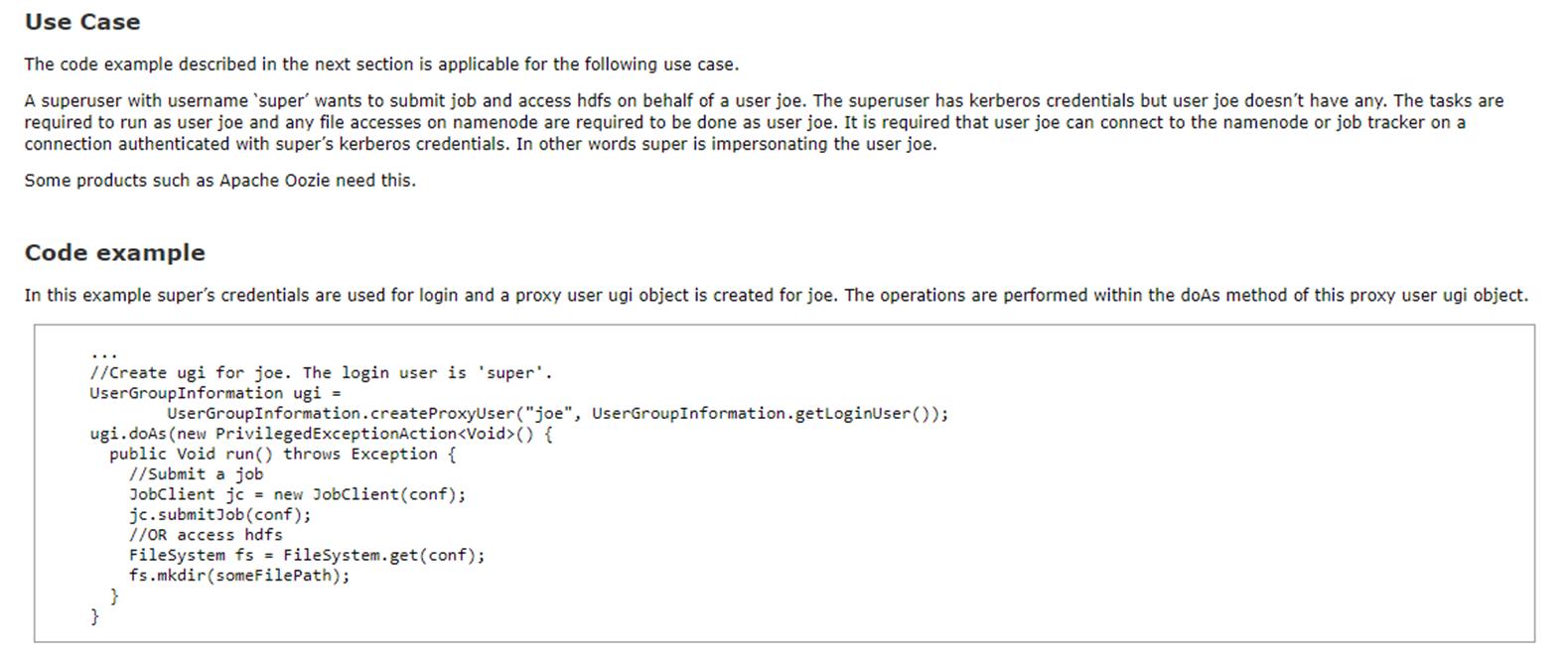
Hadoop 还有代理用户 proxyuser 的概念,一般 hue/hive/sqoop/flume 等服务的系统用户都支持代理机制。
- 所谓代理机制,是由当前的系统用户/真实用户realuser/超级用户,如 hive/sqoop 等服务的进程对应的用户,代理最终的业务用户比如dap/cic等,对底层的 hdfs进行访问;
- 经过代理后,hdfs 进行权限校验时,是针对最终业务用户比如 hundsun/dap/cic,进行权限校验;
- 没有使用代理时,hdfs 进行权限校验时,是针对系统用户比如 hive/hue/sqoop,进行权限校验;
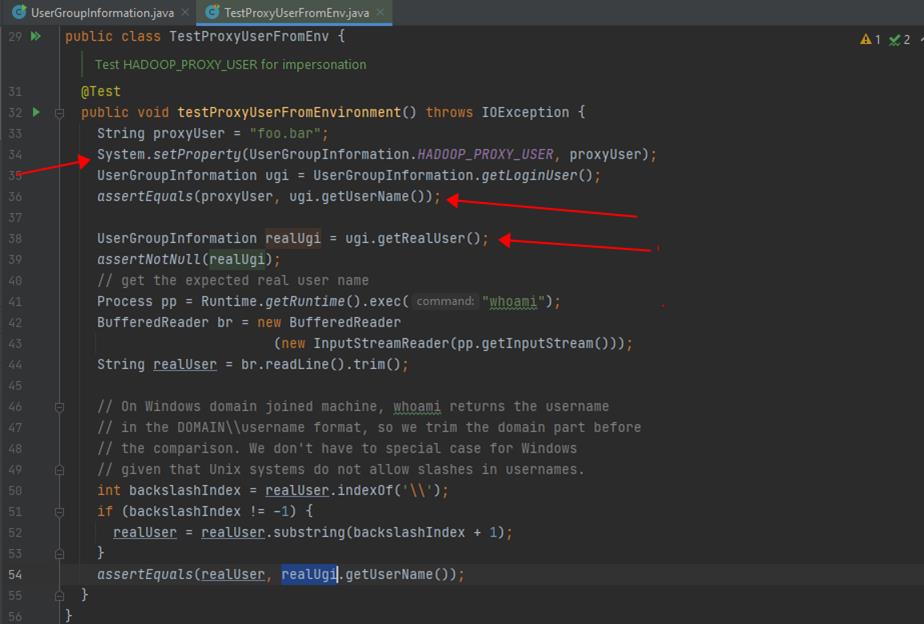
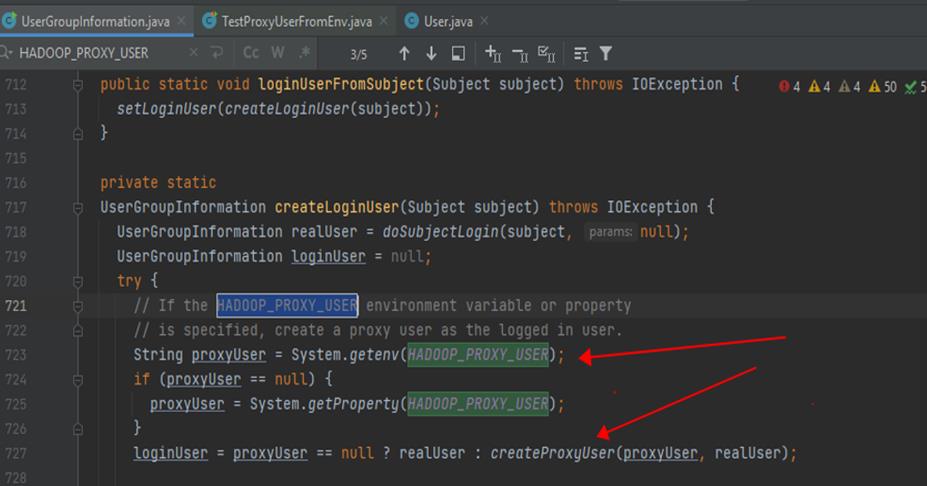
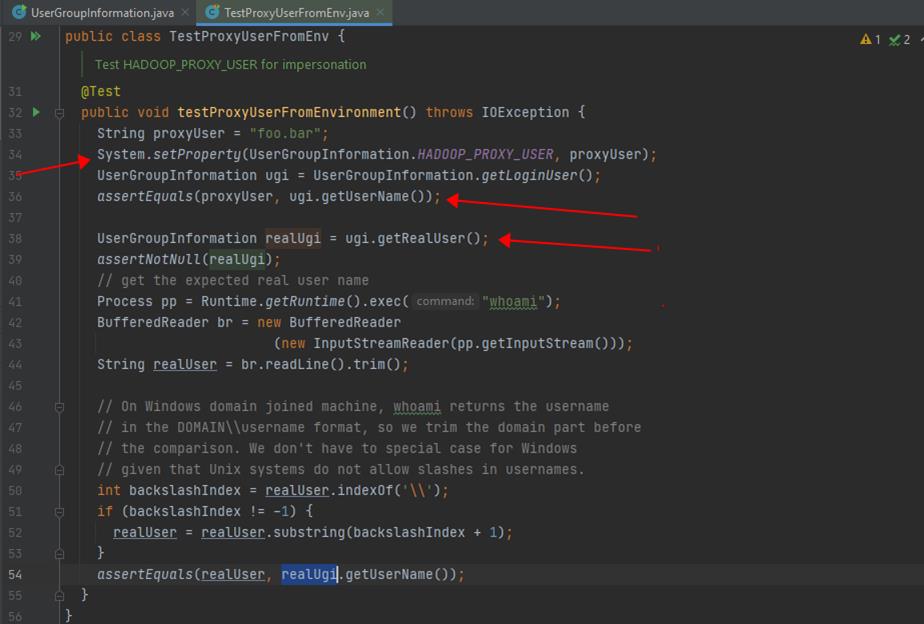
- 当指定了环境变量或系统参数 HADOOP_PROXY_USER 时,HADOOP 会自动使用代理机制,且被代理用户就是该环境变量/系统参数只当的值,所以可以通过以下方式指定被代理的业务用户:
- System.setProperty(UserGroupInformation.HADOOP_PROXY_USER, “randomUser”);
- Export HADOOP_PROXY_USER = randomUser;
-
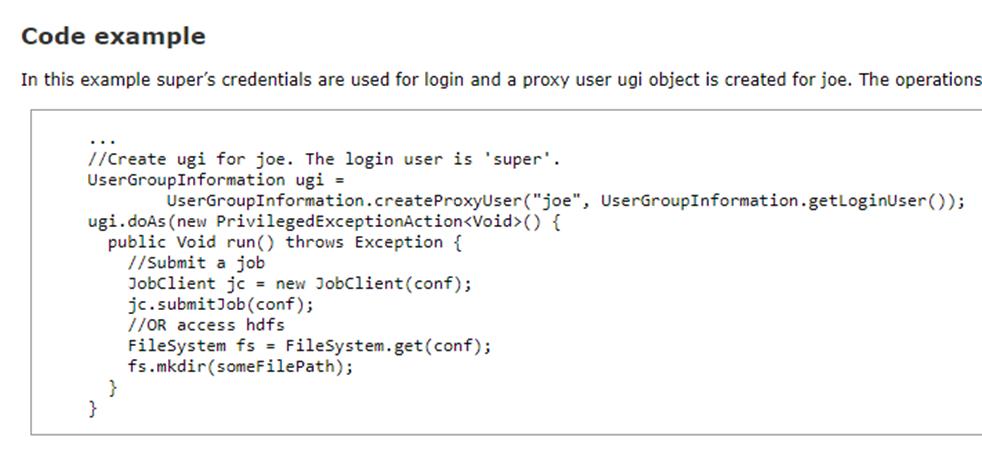
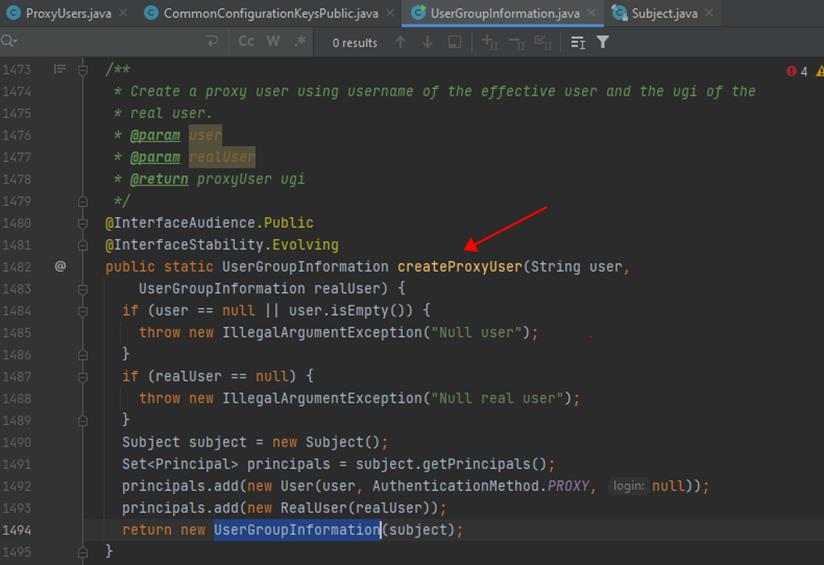
当然也可以在代码中,显示指定代理用户:UserGroupInformation.createProxyUser(“randomUser”, UserGroupInformation.getLoginUser());
hue/hive/sqoop/flume等服务的系统用户,使用代理机制时,需要进行配置,相关的配置参数如下:
- hadoop.proxyuser.xxx.groups
- hadoop.proxyuser.xxx.hosts

3.7 大数据平台 CDH/HDP/CDP 与 TDH, HDFS 授权与鉴权的差异
TDH 中,通过安全组件 Guardian 来管理各个组件的安全:
- Guardian 底层整合了 kerberos 和 ApacheDS来做认证;
- 同时Guardian 还通过 hdfs 插件机制,支持了对 hdfs 的目录和文件进行授权和鉴权,有点类似于 ranger 的插件机制;

通过访问HDFS目录时的底层日志,我们可以大胆推测,guardian hdfs plug,和 ranger hdfs plugin 的实现细节,还是有所区别的:
- Guardian是先进行hdfs posix 的权限校验,如果校验成功就允许执行对应的hdfs操作,只有在hdfs posix 权限校验失败时,才会查看 guardian 配置的权限;
- 如果guardian权限校验也是失败的,就阻止对应的hdfs 操作;如果guardian权限校验成功,就允许执行对应的hdfs操作;(底层是切换使用了 hdfs 超级用户来进行实际的 hdfs 操作)
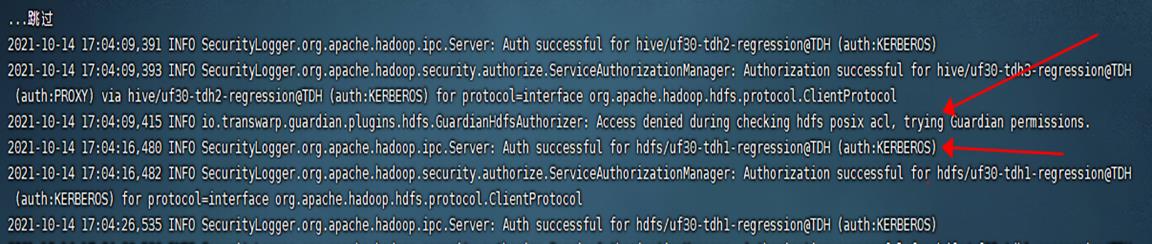
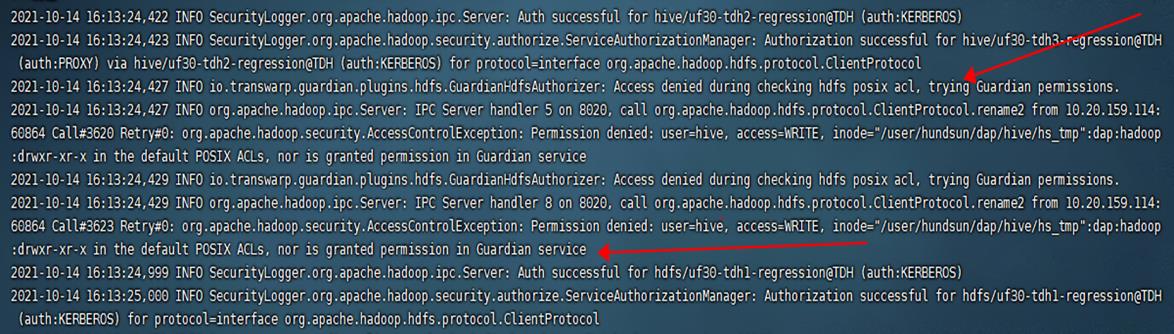
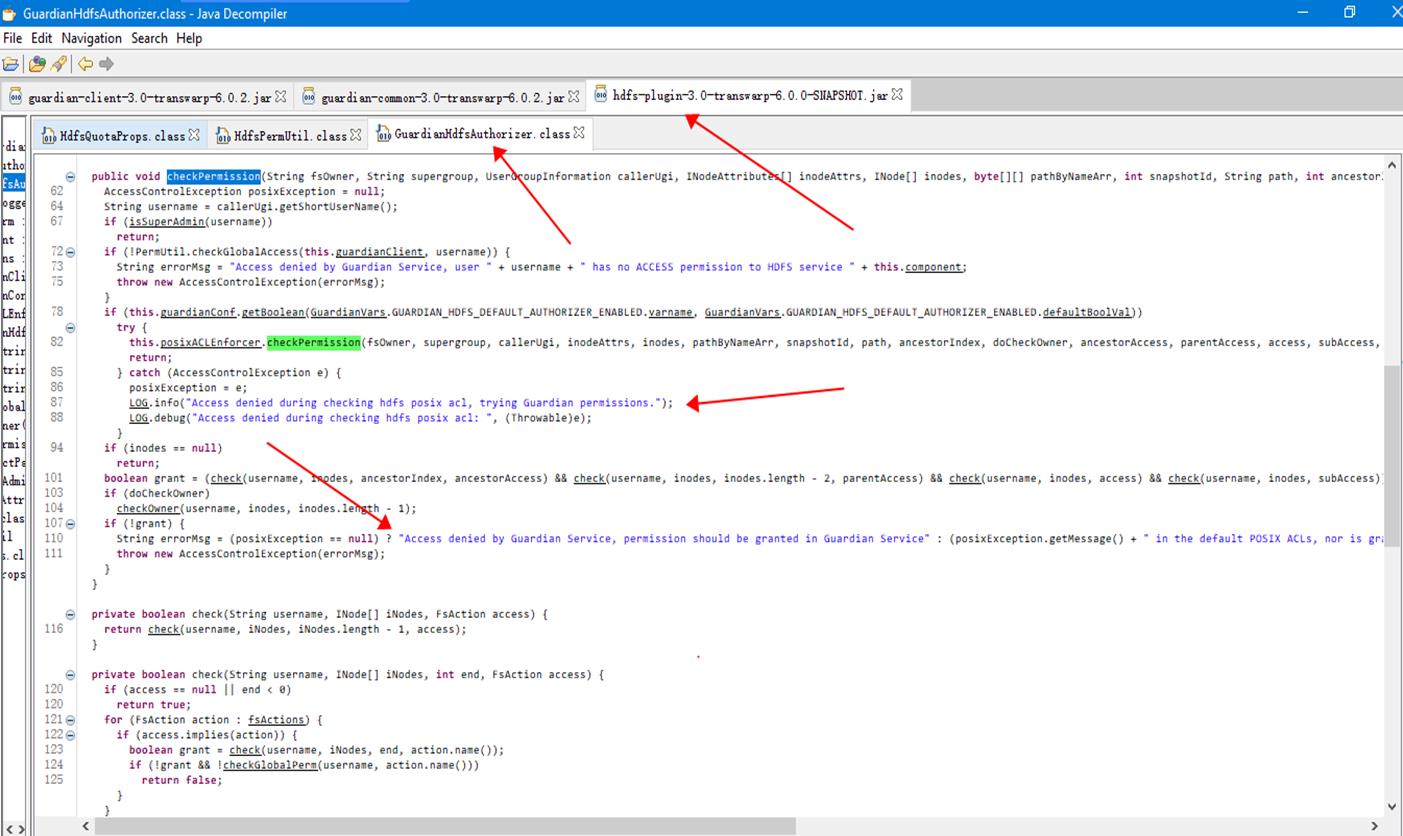
- 通过查看反编译的 Guardian hdfs plugin 的源码,印证了我们上述推测:其底层使用了java 的 try-catch 捕获了 HDFS native 权限校验抛出的异常,并进一步通过guardian进行权限校验:
3.8 HDFS授权详解-Best practices for HDFS authorization
权限管理最佳实践:
- 通过配置 umask 控制所有新创建的目录和文件的 posix mode, umask 默认022,常用的还有 007,077;
- 如果需要更改特定目录的权限,应该遵循权限最小化原则,按照 posix mode 对目录和文件的 owner/group/other 进行赋权;
- 如果需要对特定目录赋予特定用户的权限,应该遵循权限最小化原则,通过 posix acl 对 posix mode 进行补充;
- 当结合ranger hdfs 插件对hdfs进行权限管理时,ranger 推荐的最佳实践:
- Change HDFS umask to 077
- Identify directory which can be managed by Ranger policies
- Identify directories which need to be managed by HDFS native permissions
-Enable Ranger policy to audit all records
3.9 HDFS授权详解-相关参数
总结下,HDFS授权相关参数有:
- dfs.permissions.enabled = true:If yes use the permissions system as described here. If no, permission checking is turned off, but all other behavior is unchanged;
- dfs.web.ugi = webuser,webgroup;
- dfs.permissions.superusergroup = supergroup:The name of the group of super-users;
- fs.permissions.umask-mode = 0022;
- dfs.cluster.administrators = ACL-for-admins;
- dfs.namenode.acls.enabled = true: Set to true to enable support for HDFS ACLs (Access Control Lists). By default, ACLs are enabled. When ACLs are disabled, the NameNode rejects all attempts to set an ACL;
- dfs.namenode.posix.acl.inheritance.enabled: Set to true to enable POSIX style ACL inheritance. Enabled by default. When it is enabled and the create request comes from a compatible client, the NameNode will apply default ACLs from the parent directory to the create mode and ignore the client umask. If no default ACL is found, it will apply the client umask;
- hadoop.proxyuser.xxx.groups/hosts;
 开发者涨薪指南
开发者涨薪指南
 48位大咖的思考法则、工作方式、逻辑体系
48位大咖的思考法则、工作方式、逻辑体系
以上是关于大数据生态安全框架的实现原理与最佳实践(上篇)的主要内容,如果未能解决你的问题,请参考以下文章