《Java8实战》 - 读书笔记 - Stream流操作2:用流收集数据
Posted 笑虾
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了《Java8实战》 - 读书笔记 - Stream流操作2:用流收集数据相关的知识,希望对你有一定的参考价值。
《Java8实战》 - 读书笔记 - Stream流用法2:收集数据
第 6 章 用流收集数据
6.1 收集器简介
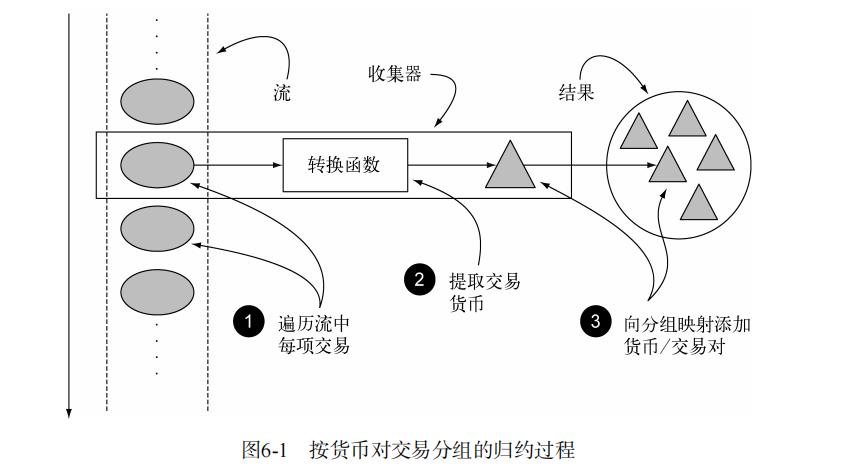
Collectors实用类提供了很多静态工厂方法,可以方便地创建常见收集器的实例,只要拿来用就可以了。最直接和最常用的收集器是toList静态方法,它会把流中所有的元素收集到一个List中:
List<Transaction> transactions = transactionStream.collect(Collectors.toList());
收集 toList
java.util.stream.Collectors.toList()
把流中所有项目收集到一个 List
List<Integer> scoreList = Hero.getList().stream()
.map(Hero::getScore)
.collect(Collectors.toList());
System.out.println(scoreList); // [23, 19, 20, 21, 25, 45]
收集 toSet
java.util.stream.Collectors.toSet()
把流中所有项目收集到一个 Set,删除重复项
Set<Integer> collect = Hero.getList().stream()
.map(Hero::getScore)
.collect(Collectors.toSet());
System.out.println(collect); // [19, 20, 21, 23, 25, 45]
收集 toMap
java.util.stream.Collectors.toMap()
简单版本
只指定key和value。这里以Name为key,以对象本身为value。
所以值这里使用了恒等函数java.util.function.Function.identity()
Hero.getList().stream()
.collect(toMap(Hero::getName, Function.identity()));
配合 Mybatis 使用,遇到了点问题
这里是配合Mybatis使用,遇到了点问题:key 和 value 能取到,但是直接类型转换报错。
分析:
处理 Key类型转换这里估计与Mybatis的返回值类型处理有关。
mybatis返回类型,接口写的是List<Map<Long, Integer>>,但读取值可以看到实际类型还是List<Map<Integer, Long>>(与Mybatis查出来的结果一至)。id字段在表中类型是int,我试着在resultMap把它定义成了Long。但到了处理key这一步,就报Error: java: 不兼容的类型: java.lang.Integer无法转换为java.lang.Long,怀疑是这个问题,但未深入验证。- 但
collection字段的转换又没问题这个字段是用count算出来的默认返回Long。
Integer与Long没继承关系不能强转,这个我能理解。但intValue()、longValue()也不好使了,我不太明白。。。
以下没有使用resultMap处理,直接使用List<Map<Integer, Long>>接收(Mybatis返回的实际类型)。
先强转为Number再输出想要的目标类型,问题解决。
collectionsMapper.selectCollection().stream()
.collect(Collectors.toMap(
// 处理 key
m -> ((Number)m.get("id")).longValue(),
// 处理 value
m -> ((Number)m.get("collection")).intValue(),
// 处理重复 key 规则 : 使用新值
(oldValue, newValue) -> newvalue,
// 想转的目标类型
LinkedHashMap<Long, Integer>::new
));
- 关于类型转换,网上看到的其它解决方案:
- 用
Object中转一下再转目标类型
m -> (Long)(Object)m.get("id")
- 用
resultMap把所有字段返回类型都改成String转map时各字段根据需要处理。
m -> Long.parseLong(m.get("id")),
- 用String中转一下,道理一样。
m -> Long.parseLong(String.valueOf(m.get("id")))
- 还看到有人是转
JSON再转回来这么实现的eeeeeeeeeeee。
收集 toCollection
把流中所有项目收集到给定的供应源创建的集合
Hero.getList().stream()
.collect(toCollection(), ArrayList::new);
利用TreeSet实现去重。
AbstractCollection<Hero> collect = Hero.getList().stream()
.collect(toCollection(
() -> new TreeSet<>(comparing(Hero::getGroupTag))
));
System.out.println(JSONObject.toJSONString(collect, SerializerFeature.PrettyFormat));
利用collectingAndThen去重,后再处理(将结果装进ArrayList)
ArrayList<Hero> collect = Hero.getList().stream().collect(
collectingAndThen(
toCollection(() -> new TreeSet<>(comparing(Hero::getGroupTag))),
ArrayList::new
)
);
System.out.println(JSONObject.toJSONString(collect, SerializerFeature.PrettyFormat));
转数组 toArray
先取出年龄,再toArray装进数组。
Hero.getList().stream().map(Hero::getAge).toArray(Integer[]::new);
6.2 归约和汇总
6.2.1 查找流中的最大值和最小值
接收一个 Comparator 参数来比较流中的元素。
按最大值 maxBy 查找
找到年龄最大的Hero:maxBy接收 Comparator<? super T> comparator 参数来比较流中的元素。
Comparator<Hero> heroAgeComparator = Comparator.comparingInt(Hero::getAge);
Optional<Hero> collect = Hero.getList().stream()
.collect(maxBy(heroAgeComparator));
Hero hero = collect.get();
System.out.println(hero); // Hero(name=重八, age=60, score=45, group=C)
按最小值 minBy 查找
找到年龄最小的Hero
Optional<Hero> collect = Hero.getList().stream()
.collect(minBy(Comparator.comparingInt(Hero::getAge)));
Hero hero = collect.get();
System.out.println(hero); // Hero(name=张三, age=10, score=23, group=A)
6.2.2 汇总
求合 summingInt、summingLong、summingDouble
接受一个返回int的函数(比如Hero::getScore),并返回一个收集器;该收集器在传递给普通的collect方法后即执行我们需要的汇总操作。
同理。
Collector<Hero, ?, Integer> heroScore = Collectors.summingInt(Hero::getScore);
int total = Hero.getList().stream().collect(heroScore );
System.out.println("分数合计:" + total);// 分数合计:153
- IntStream.sum、LongStream
List<Integer> list = IntStream.rangeClosed(1,100).boxed().collect(Collectors.toList());
int sum = list.stream().mapToInt(Integer::intValue).sum();
System.out.println(sum); // 5050
List<Long> longList = LongStream.rangeClosed(1,100).boxed().collect(Collectors.toList());
long sumLong = longList.stream().mapToLong(Long::longValue).sum();
System.out.println(sumLong); // 5050
- Stream.reduce
List<Integer> intList = IntStream.rangeClosed(1,100).boxed().collect(Collectors.toList());
Integer sum2 = intList.stream().reduce(0, Integer::sum);
System.out.println(sum2); // 5050
Integer sum1 = intList.stream().reduce(0, (a, b) -> a + b);
System.out.println(sum1); // 5050
平均 averagingInt、averagingLong、averagingDouble
参考求合,不再赘述。
综合统计 summarizingInt、summarizingLong、summarizingDouble
一次同时进行总和、平均值、最大值和最小值
Collector<Hero, ?, IntSummaryStatistics> heroScoreCollector = Collectors.summarizingInt(Hero::getScore);
IntSummaryStatistics collect = Hero.getList().stream()
.collect(heroScoreCollector);
System.out.println("合计:" + collect.getSum()); // 合计:153
System.out.println("平均数:" + collect.getAverage()); // 平均数:25.5
System.out.println("最大值:" + collect.getMax()); // 最大值:45
System.out.println("最小值:" + collect.getMin()); // 最小值:19
System.out.println("计数:" + collect.getCount()); // 计数:6
6.2.3 连接字符串 joining
String str = Hero.getList().stream()
.map(Hero::getName)
.collect(joining("|"));
System.out.println(str); // 张三|李四|王五|赵六|洪七|重八
6.2.4 广义的归约汇总 reducing
从一个作为累加器的初始值开始,利用 BinaryOperator 与流中的元素逐个结合,从而将流归约为单个值。
事实上,我们已经讨论的所有收集器,都是一个可以用reducing工厂方法定义的归约过程的特殊情况而已。Collectors.reducing工厂方法是所有这些特殊情况的一般化。可以说,先前讨论的案例仅仅是为了方便程序员而已。(但是,请记得方便程序员和可读性是头等大事!)例如,可以用reducing方法创建的收集器来计算你菜单的总热量,如下所示:
int totalCalories = menu.stream().collect( reducing(0, Dish::getCalories, (i, j) -> i + j) );它需要三个参数。
- 第一个参数是归约操作的起始值,也是流中没有元素时的返回值,所以很显然对于数值和而言0是一个合适的值。
- 第二个参数就是你在6.2.2节中使用的函数,将菜肴转换成一个表示其所含热量的int。
- 第三个参数是一个BinaryOperator,将两个项目累积成一个同类型的值。这里它就是对两个int求和。
同样,你可以使用下面这样单参数形式的reducing来找到热量最高的菜,如下所示:Optional<Dish> mostCalorieDish = menu.stream().collect( reducing( (d1, d2) -> d1.getCalories() > d2.getCalories() ? d1 : d2) );你可以把单参数reducing工厂方法创建的收集器看作三参数方法的特殊情况,它把流中的第一个项目作为起点,把恒等函数(即一个函数仅仅是返回其输入参数)作为一个转换函数。这也意味着,要是把单参数reducing收集器传递给空流的collect方法,收集器就没有起点;正如我们在6.2.1节中所解释的,它将因此而返回一个Optional对象。
收集与归约
在上一章和本章中讨论了很多有关归约的内容。你可能想知道,Stream接口的collect和reduce方法有何不同,因为两种方法通常会获得相同的结果。例如,你可以像下面这样使用reduce方法来实现toListCollector所做的工作:Stream<Integer> stream = Arrays.asList(1, 2, 3, 4, 5, 6).stream(); List<Integer> numbers = stream.reduce( new ArrayList<Integer>(), (List<Integer> l, Integer e) -> l.add(e); return l; , (List<Integer> l1, List<Integer> l2) -> l1.addAll(l2); return l1; );这个解决方案有两个问题:一个语义问题和一个实际问题。语义问题在于,reduce方法旨在把两个值结合起来生成一个新值,它是一个不可变的归约。与此相反,collect方法的设计就是要改变容器,从而累积要输出的结果。这意味着,上面的代码片段是在滥用reduce方法,因为它在原地改变了作为累加器的List。你在下一章中会更详细地看到,以错误的语义使用reduce方法还会造成一个实际问题:这个归约过程不能并行工作,因为由多个线程并发修改同一个数据结构可能会破坏List本身。在这种情况下,如果你想要线程安全,就需要每次分配一个新的List,而对象分配又会影响性能。这就是collect方法特别适合表达可变容器上的归约的原因,更关键的是它适合并行操作,本章后面会谈到这一点。
6.3 分组
| groupingBy | 说明 | 参数 |
|---|---|---|
| 单参数版本 | groupingBy(分组条件) | 收集器,默认Collectors.toList()结果容器,默认 HashMap::new |
| 两参数版本 | groupingBy(分组条件, 收集器) | 收集器:分组后每组的内容如何收集。 |
| 单参数版本 | groupingBy(分组条件, 结果容器工厂, 收集器) | 容器工厂:分组后整个结果怎么存放。 |
按条件分组 groupingBy
groupingBy 根据项目的一个属性的值对流中的项目进行组,并将属性值作为结果 Map 的键。
注意:单参数groupingBy(f)(其中f是分类函数)是groupingBy(f, toList())的简写。
按groupTag分组,结果收集到List。
Map<String, List<Hero>> collect = Hero.getList().stream().collect(
groupingBy(Hero::getGroupTag, toList())
);
System.out.println(JSONObject.toJSONString(collect, SerializerFeature.PrettyFormat));
//
// "A":[
// "age":10, "groupTag":"A", "name":"张三", "score":23 ,
// "age":20, "groupTag":"A", "name":"李四", "score":19
// ],
// "B":[
// "age":30, "groupTag":"B", "name":"王五", "score":20 ,
// "age":40, "groupTag":"B", "name":"赵六", "score":21
// ],
// "C":[
// "age":50, "groupTag":"C", "name":"洪七", "score":25 ,
// "age":60, "groupTag":"C", "name":"重八", "score":45
// ]
//
6.3.1 多级分组 groupingBy 嵌套
groupingBy(条件, groupingBy(条件, 收集))。
先按照Age分组,再按照GroupTag分组
Map<String, Map<String, List<Hero>>> collect = Hero.getList().stream().collect(
groupingBy(
h -> h.getAge() > 30 ? "老兵" : "新兵",
groupingBy(Hero::getGroupTag, toList())
)
);
System.out.println(JSONObject.