端午安康SXYPython正则表达式进阶用法(以批量修改Markdown英文字体为例)
Posted 囚生CY
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了端午安康SXYPython正则表达式进阶用法(以批量修改Markdown英文字体为例)相关的知识,希望对你有一定的参考价值。
文章目录
序言
本文没有序言,但是或许会有后记。
1 问题缘起
不知道写Markdown的朋友会不会觉得编辑器默认的字体不太顺眼,比如常用的Typora编辑器,以及用于博客发布的CSDN的Markdown编辑器,这两个编辑器使用的主题都是GitHub风格主题,默认字体为Arial。倒不是说Arial字体丑,但是跟其他字体比较,比如字体Times New Roman看起来就要正式很多,再不济给Arial加个斜体(Arial)也要好看很多,当然给Times New Roman再加个斜体(Times New Roman)那将绝杀(最美字体不接受反驳)。
所以以前笔者写Markdown的时候,都要手动给英文部分修改字体(要么加粗加斜,要么用<font face=times new roman>...</font>的标签对套在英文语句上)。
这时候肯定有人要跳出来说,CY你又水博客了,你要是觉得字体丑,自己去改Typora的层叠样式表(CSS)配置文件不就完事。笔者不反对这种观点,的确找到Typora安装根目录下的resources\\app\\style\\themes\\github.css配置文件,修改其中的默认字体(比如将Times New Roman添加到配置文件的body中即可,网上也有很多人教你怎么修改Typora的默认字体),但这里有两个难以解决的问题:
- CSDN的Markdown编辑器是无法修改默认字体的,必须依赖
<font>标签来自定义字体; - 对笔者来说,我只想修改和英文相关的内容(注意并不一定都是英文字母,包括英文内容中可能出现的数字、标点符号、特殊符号,比如邮箱地址中就会出现各种特殊符号)的字体,因为默认的中文字体笔者觉得是可以接受的。因此改动配置文件就没那么容易了,网上也有关于如何在CSS文件中为中英文配置不同字体的方法,但是这就需要大改配置文件,并非简单地添加几个字段那么容易,而且如何判断标点符号、特殊符号也是一个难题。
不过有一个好消息,Time New Roman不识别中文,因此只要给Markdown中每一行的句首句尾添加<font face=times new roman>和</font>即可简单实现,这至少比一个个的给英文修改字体要简便得多,所以笔者很早之前就写过一个给Markdown配置字体的Python脚本:
# -*- coding: utf-8 -*-
# @author: caoyang
# @email: caoyang@163.sufe.edu.cn
# 为Markdown每一行首尾加一个字体标签的工具函数
# 跳过标题行, 多行公式, 多行代码, 表格区域
# 跳过每行开头的无序列表标签('- '), 有序列表标签('1. ', '2. ', '3. '), 引用部分('> ')
# 默认添加的字体模式为<font face=times new roman>...</font>
def add_font_for_each_line(import_path, export_path, font_prefix='<font face=times new roman>', font_suffix='</font>'):
with open(import_path, 'r', encoding='utf8') as f:
lines = f.read().splitlines()
export_lines = [] # 存储修改后的每一行markdown代码
is_formula = False # 判断是否处于公式范围内
is_code = False # 判断是否处于代码范围内
for line in lines:
if line.lstrip():
# 引用
if line.lstrip()[0] == '>':
suffix = ' ' * (len(line) - len(line.lstrip())) + '>'
line = line.lstrip()[1: ]
# 有序列表
elif line.lstrip()[: 3] in ['1. ', '2. ', '3. ', '4. ', '5. ', '6. ', '7. ', '8. ', '9. ']:
suffix = ' ' * (len(line) - len(line.lstrip())) + line.lstrip()[:3]
line = line.lstrip()[3: ]
else:
suffix = ''
line = line
# 多行公式
if line.lstrip().startswith('$$') and is_formula:
is_formula = False
export_lines.append(suffix + line)
elif line.lstrip().startswith('$$') and (not is_formula):
is_formula = True
export_lines.append(suffix + line)
elif is_formula:
export_lines.append(suffix + line)
# 多行代码
elif line.lstrip().startswith('```') and is_code:
is_code = False
export_lines.append(suffix + line)
elif line.lstrip().startswith('```') and (not is_code):
is_code = True
export_lines.append(suffix + line)
elif is_code:
export_lines.append(suffix + line)
# 空行
elif len(line.strip()) == 0:
export_lines.append(suffix + line)
elif line.strip() == '----' or line[0] == '#' or line.strip() == '[toc]' or line.lstrip()[0] == '|':
# 持续更新: 目前考虑分割线, 标题, 目录, 表格
export_lines.append(suffix + line)
else:
# 无序列表
index = line.find('- ')
if index > -1:
export_lines.append(suffix + line[: index + 2] + font_prefix + line[index + 2: ] + font_suffix)
else:
export_lines.append(suffix + ' ' * (len(line) - len(line.lstrip())) + font_prefix + line.lstrip() + font_suffix)
else:
export_lines.append(line)
with open(export_path, 'w', encoding='utf8') as f:
f.write('\\n'.join(export_lines))
if __name__ == '__main__':
add_font_for_each_line(import_path=r'input.md',
export_path=r'output.md',
font_prefix='<font face=times new roman>',
font_suffix='</font>')
注意上面的代码中已经充分考虑到要跳过Markdown中的多行公式、多行代码块、表格区域,以及每行开头可能出现的无序列表标签、有序列表标签、引用标签。
下面展示一个demo用于说明上述脚本的用途:
-
测试Markdown脚本(写入到
input.md文件中,注意里面反引号前面的反斜杠请删除,笔者不加反斜杠的话Markdown语法容易错误识别代码区域):> 测试引用(cite): > > - 测试引用1 > - 测试引用2 测试正文(Body): 1. 测试有序列表(Formula):$a^p-1\\equiv 1(\\textmod p)$ $$ x^n+y^n=z^n\\quad x\\in\\Z^*,y\\in\\Z^*,z\\in\\Z* $$ 2. 测试无序列表(Code):`Inline code demo` \\`\\`\\`python print('Hello world!') \\`\\`\\` 任何问题可以联系我的邮箱caoyang@163.sufe.edu.cn,Thanks! -
运行上述代码,可以从
output.md中得到如下输出:> <font face=times new roman>测试引用(cite):</font> > > - <font face=times new roman>测试引用1</font> > - <font face=times new roman>测试引用2</font> <font face=times new roman>测试正文(Body):</font> 1. <font face=times new roman>测试有序列表(Formula):$a^p-1\\equiv 1(\\textmod p)$</font> $$ x^n+y^n=z^n\\quad x\\in\\Z^*,y\\in\\Z^*,z\\in\\Z* $$ 2. <font face=times new roman>测试无序列表(Code):`Inline code demo`</font> \\`\\`\\`python print('Hello world!') \\`\\`\\` <font face=times new roman>任何问题可以联系我的邮箱caoyang@163.sufe.edu.cn,Thanks!</font> -
修改前后的样式对比:
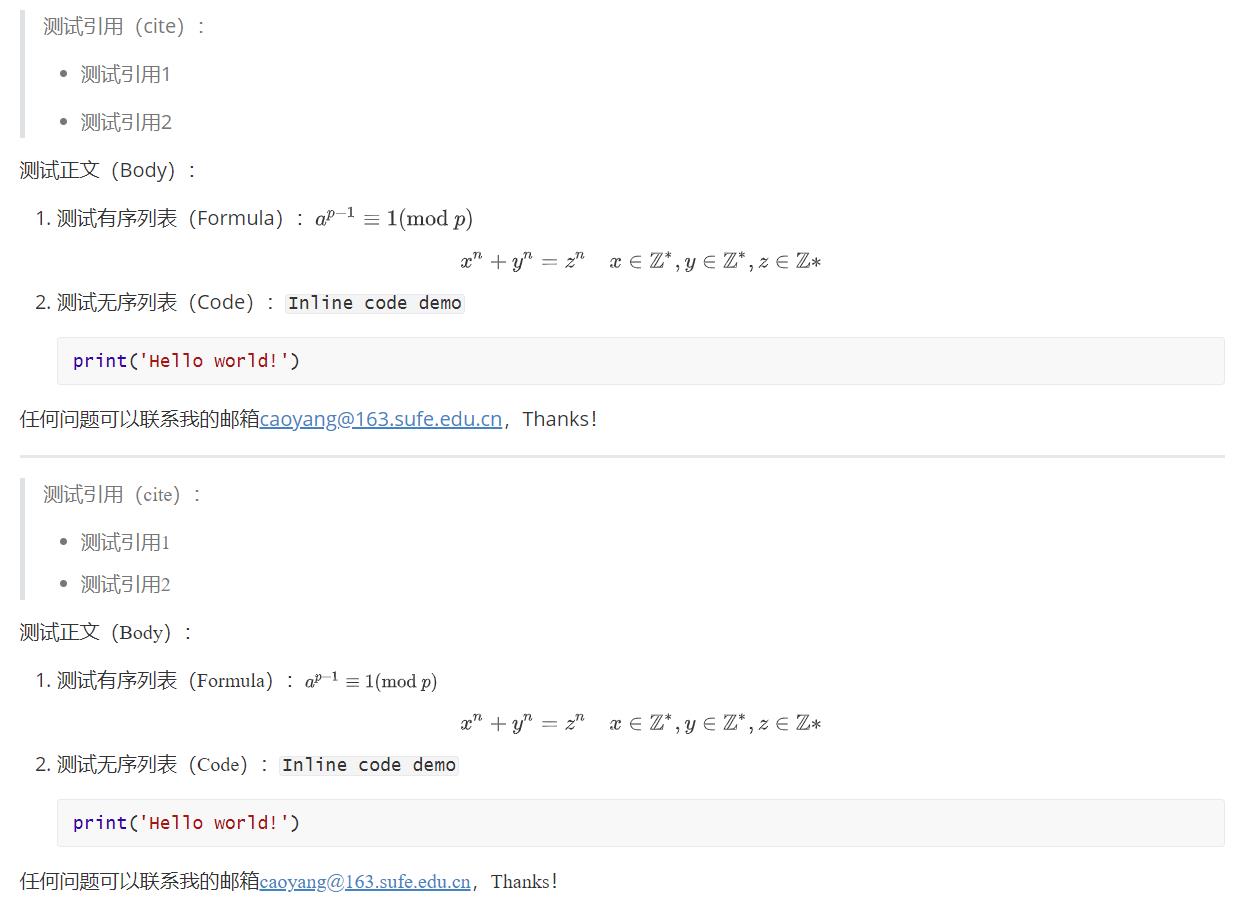
非常完美,似乎我们已经得到一个很鲁棒的字体修改脚本,但是如果只是到此为止,笔者也不会浪费时间特意水一篇博客,仔细观察上面修改前后的样式对比的图片以及修改前后的Markdown脚本,仍然存在两个问题:
-
Times New Roman只是恰好无法识别中文,因此只需要在句首句末添加
<font face=times new roman>和</font>即可实现英文字体修改,那么如果是其他能够识别中文的字体就会连着中文字体一起改动,这是笔者所不期望的。 -
有没有发现改动成Times New Roman后的英文字号相对于中文字号有点偏小?事实上
<font>标签中还有一个size属性,默认值是size=3,如果改为size=4则Times New Roman字体的英文字号与size=3的中文字号较为相配。倘若将前缀改为
<font face=times new roman size=4>是不可行的,因为这样会使得中文字号也会变为size=4,相对大小不会产生变化。(原谅笔者的强迫症)
因此最好的修改脚本是能够确切地匹配到需要修改的英文内容部分,然后添加字体标签,这样才是笔者所期望的。
口说无凭,本问第三部分的新脚本将会改动得到如下的结果(字体发生改动的部分用红色标注):

> 测试引用(<font face=times new roman size=4 color=red><i>cite</i></font>):
>
> - 测试引用1
> - 测试引用2
测试正文(<font face=times new roman size=4 color=red><i>Body</i></font>):
1. 测试有序列表(<font face=times new roman size=4 color=red><i>Formula</i></font>):$a^p-1\\equiv 1(\\textmod p)$
$$
x^n+y^n=z^n\\quad x\\in\\Z^*,y\\in\\Z^*,z\\in\\Z*
$$
2. 测试无序列表(<font face=times new roman size=4 color=red><i>Code</i></font>):`Inline code demo`
\\`\\`\\`python
print('Hello world!')
\\`\\`\\`
任何问题可以联系我的邮箱<font face=times new roman size=4 color=red><i>caoyang@163.sufe.edu.cn</i></font>,<font face=times new roman size=4 color=red><i>Thanks</i></font>!
到这里肯定又有人要跳出来说,CY你还在水博客,这不是写几个循环和条件句就能解决的问题么?
说得好!笔者本来也是这么想的,一方面应当注意到行内可能会出现行内公式$...$、行内代码块,html标签(比如<font>)、超链接和图片([链接名](链接地址)和),这些都是无需修改字体(严格说就不能套上字体标签);另一方面,循环是下策,逐字符修改效率低下,代码写起来注定也非常冗长(要判断当前字符是否属于行内公式、行内代码、HTML标签,超链接或图片)。因此笔者试图借助正则表达式的捕获元来解决这个问题,这样要高效得多,只需要在上面的Python字体修改代码中做少量调整即可(具体阅读本文第三部分)。
2 Python正则表达式中的捕获元
在解决第一部分提出的问题前,笔者首先铺垫一下所需要的知识(最好对正则有一定了解)。
2.1 re.findall与re.sub方法中使用捕获元
常规的正则表达式是为了匹配与正则相恰的字符串,比如使用正则<[^>]+>可以匹配HTML中的所有节点标签(如<html>,<header>等),然后讲匹配得到的结果替换为空字符串(即删除节点标签)即可得到HTML的纯文本信息:
# -*- coding: utf-8 -*-
# @author: caoyang
# @email: caoyang@163.sufe.edu.cn
import re
regex_compiler = re.compile(r'<[^>]+>')
string = """<html><header></header><body><h1>demo</h1></body></html>"""
print(regex_compiler.findall(string))
print(regex_compiler.sub('', string))
# 输出结果
"""
['<html>', '<header>', '</header>', '<body>', '<h1>', '</h1>', '</body>', '</html>']
demo
"""
可是有时候我们可能会有更特殊的需求:
- 我只想获得匹配结果的一部分字符串,如匹配HTML中的所有节点标签的名称(即
html,header等)? - 我只想替换匹配结果的一部分字符串,如匹配HTML中的所有节点标签,并将标签的
<与>替换为与(如<html>替换为html)?
这时候就需要引入捕获元的概念,具体而言,使用左右圆括号在正则表达式中框出你想要匹配得到的那部分(称之为捕获),如在上面的例子中,如果我们只想匹配HTML中的所有节点标签的名称,那么这相当于是在正则<[^>]+>中获取[^>]+这一部分,那么可以改为<([^>]+)>即可实现上面的效果:
# -*- coding: utf-8 -*-
# @author: caoyang
# @email: caoyang@163.sufe.edu.cn
import re
regex_compiler = re.compile(r'<[(^>]+)>')
string = """<html><header></header><body><h1>demo</h1></body></html>"""
print(regex_compiler.findall(string))
print(regex_compiler.sub(r'\\1', string))
# 输出结果
"""
['html', 'header', '/header', 'body', 'h1', '/h1', '/body', '/html']
htmlheader/headerbodyh1demo/h1/body/html
"""
regex_compiler.sub中我们用\\1来匹配正则中的第一个捕获元,同理如果正则中存在多个捕获元,可以依次使用\\1,\\2,\\3进行匹配。但是这个与通常的正则编译器对捕获元替换的处理是有区别的!至少笔者的经验中更多使用的应该是$1,$2,$3,但是在Python的re库中如果使用$1,$2,$3来匹配捕获元是完全不起作用,大坑。(有可能是re库的版本太低,笔者使用的是2.2.1)
2.2 re.split方法中的捕获元用法
re.split方法可以将字符串中所有与正则匹配的部分删除,将剩下零碎的字符串以列表形式返回:
# -*- coding: utf-8 -*-
# @author: caoyang
# @email: caoyang@163.sufe.edu.cn
import re
print(re.__version__)
regex_compiler_1 = re.compile(r'<[^>]+>') # 不带捕获元的正则
regex_compiler_2 = re.compile(r'<([^>]+)>') # 带捕获元的正则
string = """<html><header></header><body><h1>demo</h1><h2>demo</h2></body></html>"""
print(regex_compiler_1.split(string))
print(regex_compiler_2.split(string))
# 输出结果
"""
['', '', '', '', '', 'demo', '', '', '']
['', 'html', '', 'header', '', '/header', '', 'body', '', 'h1', 'demo', '/h1', '', '/body', '', '/html', '']
"""
注意到,对于不带捕获元的正则来说,re.split与re.findall返回的结果是刚好互补的,具体而言,re.split返回的列表长度总是比re.findall列表长度多1,且将re.findall的列表元素依次插入到re.split元素的间隙中,即可得到原字符串。
如在前面的例子中:
regex_compiler.findall(string)返回结果为['<html>', '<header>', '</header>', '<body>', '<h1>', '</h1>', '</body>', '</html>'],长度为8;regex_compiler_2.findall(string)返回结果为['', '', '', '', '', 'demo', '', '', ''],长度为9;- 两者交叉拼接后可得原字符串:
"""<html><header></header><body><h1>demo</h1></body></html>"""
这是一个很有用的性质,这意味着你总是可以通过split方法过滤掉原字符串中不想处理的部分,对剩下的部分处理完后,再通过findall方法将字符串还原。
特别地,对于包含捕获元的正则,re.split方法会保留捕获元中匹配得到的部分(暂时没什么用)。
3 实战:批量修改Markdown英文字体脚本实现
那么有了第二部分的铺垫,聪明的你一定已经想到如何精确匹配Markdown中的英文内容并批量修改字体了。
具体实现如下:
# -*- coding: utf-8 -*-
# @author: caoyang
# @email: caoyang@163.sufe.edu.cn
import re
# 这种是针对英文字符, 包括一些特殊符号, 转为特定字体的方法
# 几乎完全照搬add_font_for_each_line函数
def add_font_for_english_words(import_path, export_path, font_prefix='<font face=times new roman size=4 color=red><i>', font_suffix='</i></font>'):
with open(import_path, 'r', encoding='utf8') as f:
lines = f.read().splitlines()
export_lines = [] # 存储修改后的每一行markdown代码
is_formula = False # 判断是否处于公式范围内
is_code = False # 判断是否处于代码范围内
regex_compiler_1 = re.compile(r'([a-zA-Z][a-zA-Z\\+\\@\\-\\/_=!#%\\(\\)\\d\\.:,;]*)') # 匹配英文内容
regex_1 = '`[^`]+`' # 匹配行内代码
regex_2 = '<[^>]+>' # 匹配HTML标签
regex_3 = '\\$[^\\$]+\\$' # 匹配行内公式
regex_4 = '\\[[^\\]]+\\]\\([^\\)]+\\)' # 匹配超链接和图片
regex_compiler_2 = re.compile(r'|||'.format(regex_1, regex_2, regex_3, regex_4)) # 匹配行内公式, 行内代码, HTML标签, 超链接或图片链接
def _add_font_for_line_by_regex(_line):
_rest_list = regex_compiler_2.split(_line) # 去除掉行内公式, 行内代码, HTML标签, 超链接或图片链接剩下的字符串列表
_mask_list = regex_compiler_2.findall(_line) # 匹配到的内公式, 行内代码, HTML标签, 超链接或图片链接剩下的字符串列表
assert len(_rest_list) - len(_mask_list) == 1
_rest_list = list(map(lambda _x: regex_compiler_1.sub(font_prefix + r'\\1' + font_suffix, _x), _rest_list))
_result = _rest_list[0]
for i in range(len(_mask_list)):
_result += _mask_list[i]
_result += _rest_list[i + 1]
return _result
for line in lines:
if line.lstrip():
if line.lstrip()[0] == '>':
suffix = ' ' * (len(line) - len(line.lstrip())) + '>'
line = line.lstrip()[1: ]
elif line.lstrip()[: 3] in ['1. ', '2. ', '3. ', '4. ', '5. ', '6. ', '7. ', '8. ', '9. ']:
suffix = ' ' * (len(line) - len(line.lstrip())) + line.lstrip()[:3]
line = line.lstrip()[3: ]
else:
suffix = ''
line = line
# 公式三联动
if '$$' in line and is_formula:
is_formula = False
export_lines.append(suffix + line)
elif '$$' in line and (not is_formula):
is_formula = True
export_lines.append(suffix + line)
elif is_formula:
export_lines.append(suffix + line)
# 代码三联动
elif '```' in line and is_code:
is_code = False
export_lines.append(suffix + line)
elif '```' in line and (not is_code):
is_code = True
export_lines.append(suffix + line)
elif is_code:
export_lines.append(suffix + line)
# 空行
elif len(line.strip()) == 0:
export_lines.append(suffix + line)
# 持续更新: 目前考虑分割线, 目录, 表格, 标题
elif line.strip() == '----' or line.strip() == '[toc]' or line.lstrip()[0] == '|' or line.lstrip()[0] == '#':
export_lines.append(suffix + line)
else:
index = line.find('- ')
if index > -1:
# 没有列表符
# export_lines.append(suffix + line[: index + 2] + font_prefix + line[index + 2: ] + font_suffix)
export_lines.append(suffix + line[: index + 2] + _add_font_for_line_by_regex(line[index + 2: ]))
else:
# export_lines.append(suffix + ' ' * (len(line) - len(line.lstrip())) + font_prefix + line.lstrip() + font_suffix)
export_lines.append(suffix + ' ' * (len(line) - len(line.lstrip())) + _add_font_for_line_by_regex(line.lstrip()))
else:
export_lines.append(line)
with open(export_path, 'w', encoding='utf8') as f:
f.write('\\n'.join(export_lines))
if __name__ == '__main__':
add_font_for_english_words(import_path=r'input.md',
export_path=r'output.md',
font_prefix='<font face=times new roman size=4><i>',
font_suffix='</i></font>')
上面的代码与第一部分中的add_font_for_each_line几乎完全相同,仅仅是修改了最后一个条件分支中的处理,即自定义了子函数_add_font_for_line_by_regex,其中共使用两个正则:
-
regex_compiler_1 = re.compile(r'([a-zA-Z][a-zA-Z\\+\\@\\-\\/_=!#%\\(\\)\\d\\.:,;]*)')这个正则即匹配英文内容,要求以字母开头(
[a-zA-Z]),后面可以接任意数量的字母数字,或者+,@,-,/,_,=,!,#,%,(,),.,:,,,;(可以继续添加,目前只想到这么多)的特殊字符。注意整体的正则用左右圆括号框起,所以整体都是一个捕获元,因为在替换的时候是要在英文内容的左右添加字体标签,因此必须完全保留匹配到的结果,具体可见在子函数中使用了
regex_compiler_1.sub(font_prefix + r'\\1' + font_suffix, _x); -
regex_compiler_2 = re.compile(r'|||'.format(regex_1, regex_以上是关于端午安康SXYPython正则表达式进阶用法(以批量修改Markdown英文字体为例)的主要内容,如果未能解决你的问题,请参考以下文章