HBase入门及列式数据模型简介
Posted YaoYong_BigData
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HBase入门及列式数据模型简介相关的知识,希望对你有一定的参考价值。
一、为什么出现NoSQL
所谓NoSQL,即Not Only SQL的缩写,意思是不只是SQL。那么,为什么会兴起NoSQL数据库呢?因为WEB2.0以及大数据时代的到来,关系型数据库越来越不能满足需求。大数据、物联网、移动互联网和云计算的发展,使得非结构化的数据比例高达90%以上,关系型数据库由于模型不灵活以及扩展水平较差,在面对大数据时,暴露出了越来越多的缺陷。由此NoSQL数据库应运而生,更好地满足了大数据时代及WEB2.0的需求。
面对WEB2.0以及大数据的挑战,关系型数据库在以下几个方面表现欠佳:
- 对于海量数据的处理性能较差
WEB2.0时代,尤其是移动互联网的发展,UGC(用户生成内容,User Generated Content)以及PGC(公众生成内容,Public Generated Content)占据了我们的日常。现如今,自媒体发展遍地开花,几乎每个人都成了内容的创造者,比如博文、评论、意见、新闻消息、视频等等,不一而足。可见,这些数据产生的速度之快,数据量之大。比如微博、公众号、抑或是淘宝,在一分钟内产生的数据可能就会非常的惊人,面对这些千万级、亿级的数据记录,关系型数据库的查询效率显然是不能接受的。
- 无法满足高并发需求
WEB1.0时代,大部分是静态网页(即提供什么就看什么),从而在大规模用户访问时,可以实现较好的响应能力。但是,在WEB2.0时代,强调的是用户的交互性(用户创造内容),所有信息都需要事实动态生成,会造成高并发的数据库访问,可能每秒上万次的读写请求,对于很多关系型数据库而言,这显示是难以承受的。
- 无法满足扩展性和高可用性的需求
在当今
娱乐至死的时代,热点问题(吸引人眼球,满足猎奇心理)会引来一窝蜂的流量,比如微博曝出某明星出轨,热搜榜会迅速引来大批用户围观(俗称吃瓜群众),从而产生大量的互动交流(蹭热点),这些都会造成数据库的读写负荷急剧增加,从而需要数据库能够在短时间内迅速提升性能以应对突发需求(毕竟宕机会非常影响户体验)。但是关系型数据库通常难以水平扩展,不能够像网页服务器和应用服务器那样简单地通过增加更多的硬件和服务节点来扩展性能和负载能力。
综上,NoSQL数据库应运而生,是IT发展的必然。
二、为什么要用HBase
截至到现在,已经学了不少的组件了,比如说分布式搜索引擎「Elasticsearch」、分布式文件系统「HDFS」、分布式消息队列「Kafka」、缓存数据库「Redis」等等...
能够处理数据的中间件(系统),这些中间件基本都会有持久化的功能。为什么?如果某一个时刻挂了,那还在内存但还没处理完的数据不就凉了?
Redis有AOF和RDB、Elasticsearch会把数据写到translog然后结合FileSystemCache将数据刷到磁盘中、Kafka本身就是将数据顺序写到磁盘....
这些中间件会实现持久化(像HDFS和mysql我们本身就用来存储数据的),为什么我们还要用HBase呢?
虽然没有什么可比性,但是在学习的时候总会有一个疑问:「既然已学过的系统都有类似的功能了,那为啥我还要去学这个玩意?」
我是这样理解的:
-
MySQL?MySQL数据库我们是算用得最多了的吧?但众所周知,MySQL是单机的。MySQL能存储多少数据,取决于那台服务器的硬盘大小。以现在互联网的数据量,很多时候MySQL是没法存储那么多数据的。
- 比如我这边有个系统,一天就能产生1TB的数据,这数据是不可能存MySQL的。(如此大的量数据,我们现在的做法是先写到Kafka,然后落到Hive中)
- Kafka?Kafka我们主要用来处理消息的(解耦异步削峰)。数据到Kafka,Kafka会将数据持久化到硬盘中,并且Kafka是分布式的(很方便的扩展),理论上Kafka可以存储很大的数据。但是Kafka的数据我们不会「单独」取出来。持久化了的数据,最常见的用法就是重新设置offset,做「回溯」操作
- Redis?Redis是缓存数据库,所有的读写都在内存中,速度贼快。AOF/RDB存储的数据都会加载到内存中,Redis不适合存大量的数据(因为内存太贵了!)。
-
Elasticsearch?Elasticsearch是一个分布式的搜索引擎,主要用于检索。理论上Elasticsearch也是可以存储海量的数据(毕竟分布式),我们也可以将数据用『索引』来取出来,似乎已经是非常完美的中间件了。
- 但是如果我们的数据没有经常「检索」的需求,其实不必放到Elasticsearch,数据写入Elasticsearch需要分词,无疑会浪费资源。
- HDFS?显然HDFS是可以存储海量的数据的,它就是为海量数据而生的。它也有明显的缺点:不支持随机修改,查询效率低,对小文件支持不友好。
HBase是基于HDFS分布式文件系统去构建的。换句话说,HBase的数据其实也是存储在HDFS上的。那肯定有好奇宝宝就会问:HDFS和HBase有啥区别阿?
HDFS是文件系统,而HBase是数据库,其实也没啥可比性。「你可以把HBase当做是MySQL,把HDFS当做是硬盘。HBase只是一个NoSQL数据库,把数据存在HDFS上」。
数据库是一个以某种 有组织的方式存储的数据集合。
扯了这么多,那我们为啥要用HBase呢?HBase在HDFS之上提供了高并发的随机写和支持实时查询,这是HDFS不具备的。
我一直都说在学习某一项技术之前首先要了解它能干什么。如果仅仅看上面的”对比“,我们可以发现HBase可以以低成本来存储海量的数据并且支持高并发随机写和实时查询。
但HBase还有一个特点就是:存储数据的”结构“可以地非常灵活(这个下面会讲到,这里如果没接触过HBase的同学可能不知道什么意思)。
三、数据模型概述
HBase 是一个稀疏、多维度、有序的映射表。
这张表中每个单元是通过由行键、列族、列限定符和时间戳组成的索引来标识的。每个单元的值是一个未经解释的字符串,没有数据类型。当用户在表中存储数据时,每一行都有一个唯一的行键和任意多的列。
表的每一行由一个或多个列族组成,一个列族中可以包含任意多个列。在同一个表模式下,每行所包含的列族是相同的,也就是说,列族的个数与名称都是相同的,但是每一行中的每个列族中列的个数可以不同,如图 1 所示。
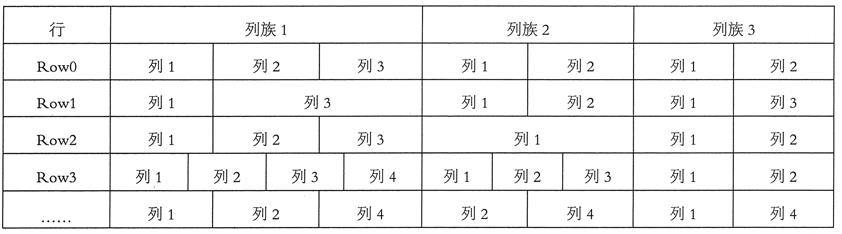
图 1 HBase 数据模型示意
HBase 中的同一个列族里面的数据存储在一起,列族支持动态扩展,可以随时添加新的列,无须提前定义列的数量。所以,尽管表中的每一行会拥有相同的列族,但是可能具有截然不同的列。正因为如此,对于整个映射表的每行数据而言,有些列的值就是空的,所以 HBase 的表是稀疏的。
HBase 执行更新操作时,并不会删除数据旧的版本,而是生成一个新的版本,原有的版本仍然保留。
用户可以对 HBase 保留的版本数量进行设置。在查询数据库的时候,用户可以选择获取距离某个时间最近的版本,或者一次获取所有版本。如果查询的时候不提供时间戳,那么系统就会返回离当前时间最近的那一个版本的数据。
HBase 提供了两种数据版本回收方式:一种是保存数据的最后个版本;另一种是保存最近一段时间内的版本,如最近一个月。
四、数据模型的基本概念
HBase是一个稀疏、多维、持久化存储的映射表,采用的row key、列族、列限定符合时间戳进行索引,每个cell的值都是字节数组byte[]。了解HBase需要先知道下面的一些概念:
1. 表(Table)
HBase采用表来组织数据,表由许多行和列组成,列划分为多个列族。
2. 行(Row)
HBase的表由若干行组成,每个行由行键(row key)标识。在表里面,每一行代表着一个数据对象。每一行都是由一个行键(Row Key)和一个或者多个列组成的。行键是行的唯一标识,行键并没有什么特定的数据类型,以二进制的字节来存储,按字母顺序排序。
因为表的行是按照行键顺序来进行存储的,所以行键的设计相当重要。设计行键的一个重要原则就是相关的行键要存储在接近的位置,例如,设计记录网站的表时,行键需要将域名反转(例如,org.apache.www、org.apache.mail、org.apache.jira),这样的设计能使与 apache 相关的域名在表中存储的位置非常接近。
访问表中的行只有 3 种方式:通过单个行键获取单行数据;通过一个行键的区间来访问给定区间的多行数据;全表扫描。
3.列族(Column Family)
HBase中,列是由列族进行组织的。在定义 HBase 表的时候需要提前设置好列族,表中所有的列都需要组织在列族里面。列族一旦确定后,就不能轻易修改,因为它会影响到 HBase 真实的物理存储结构,但是列族中的列限定符及其对应的值可以动态增删。
表中的每一行都有相同的列族,但是不需要每一行的列族里都有一致的列限定符,所以说是一种稀疏的表结构,这样可以在一定程度上避免数据的冗余。
HBase 中的列族是一些列的集合。一个列族的所有列成员都有着相同的前缀,例如,courses:history 和 courses:math 都是列族 courses 的成员。“:”是列族的分隔符,用来区分前缀和列名。列族必须在表建立的时候声明,而列则可以在使用时进行声明。在物理上,一个的列族成员在文件系统上都是存储在一起。
4.列限定符(Column Qualifier)
列蔟中包含一个个的列限定符,这样可以为存储的数据提供索引。
列限定符不需要事先定义,也不需要在不同行之间保持一致。列限定符没有特定的数据类型,以二进制字节来存储。
5.列(Column)
列由列族(Column Family)和列限定符(Column Qualifier)联合标识,由“:”进行间隔,如 family:qualifiero。
6. 单元(Cell)
由rowkey, column Family:column Qualifier, time Stamp 唯一确定的单元。cell 中的数据是没有类型的,全部是字节码形式存储。
7.时间戳(Timestamp)
由于HBase的表数据是具有版本的,这些版本是通过时间戳进行标识的。每次对一个单元格进行修改或删除时,HBase会自动为其生成并存储一个时间戳。一个单元格的不同版本是根据时间戳降序的顺序进行存储的,即优先读取最新的数据。
读取单元数据时,如果时间戳没有被指定,则默认返回最新的数据;写入新的单元数据时,如果没有设置时间戳,则默认使用当前时间。每一个列族的单元数据的版本数量都被 HBase 单独维护,默认情况下,HBase 保留 3 个版本数据。
关于HBase的数据模型,详见下图:
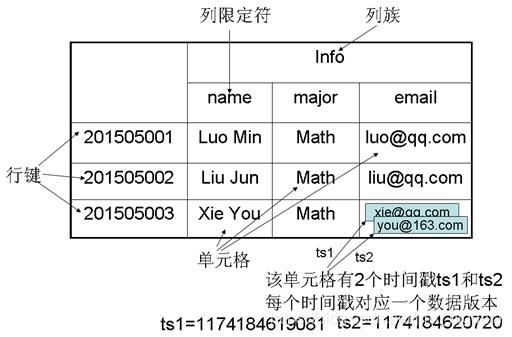
五、概念视图
在 HBase 的概念视图中,一张表可以视为一个稀疏、多维的映射关系,通过“行键+列族:列限足符+时间戳”的格式就可以定位特定单元的数据。因为 HBase 的表是稀疏的,因此某些列可以是空白的。
图 2 是 HBase 的概念视图,是一个存储网页信息的表的片段。行键是一个反向 UKL,如 www.cnn.com 反向成 com.cnn.www。
反向 URL 的好处就是,可以让来自同一个网站的数据内容都保存在相邻的位置,从而可以提高用户读取该网站的数据的速度。contents 列族存储了网页的内容;anchor 列族存储了引用这个网页的链接;mime 列族存储了该网页的媒体类型。

图 2 HBase的概念视图
图 2 给出的 com.cnn.www 网站的概念视图中仅有一行数据,行的唯一标识为“com.cnn.www”,对这行数据的每一次逻辑修改都有一个时间戳关联对应。表中共有四列:contents:html、anchor:cnnsi.com、anchor:my.look.ca 和 mime:type,每一列以前缀的方式给出其所属的列族。
从图2 可以看出,网页的内容一共有 3 个版本,对应的时间戳分别为 t3、t5 和 t6。网页被两个页面引用,分别是 my.look.ca 和 cnnsi.com,被引用的时间分别是 t8 和 t9。网页的媒体类型从 t6 开始为“text/html”。
从图 2 可以看出,在 HBase 表的概念视图中,每个行都包含相同的列族,尽管并不是每行都需要在每个列族里都存储数据。例如,在图2的前两行数据中,列族 contents 和列族 mime 的内容为空。后 3 行数据中,列族 anchor 的内容为空。后两行数据中,列族 mime 的内容为空。
上表中可以通过一个四维坐标定位一个单元格数据:[row key,列族,列,时间戳],比如[com.cnn.www,contents,contents:html,t6]。
六、物理视图
虽然从概念视图层面来看,HBase 的每个表是由许多行组成的,但是在物理存储层面来看,它是采用了基于列的存储方式,而不是像关系型据库那样用基于行的存储方式。这正是 HBase 与关系型数据库的重要区别之一。
图 2 的概念视图在进行物理存储的时候,会存为图 3 中的 3 个片段。也就是说,这个 HBase 表会按照 contents、anchor 和 mime 3 个列族分别存放。属于同一个列族的数据保存在一起,同时,和每个列族一起存放的还包括行键和时间戳。
在图 2 的概念视图中,可以看到许多列是空的,也就是说,这些列上面不存在值。在物理视图中,这些空的列并不会存储成 null,而是根本不会被存储,从而可以节省大量的存储空间。当请求这些空白的单元的时候,会返回 null 值。
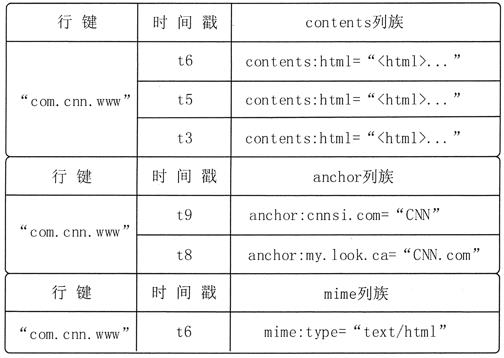
图 3 HBase 的物理视图
以上是关于HBase入门及列式数据模型简介的主要内容,如果未能解决你的问题,请参考以下文章