MapReduce经典案例—倒排索引
Posted 一指流沙q
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MapReduce经典案例—倒排索引相关的知识,希望对你有一定的参考价值。
目录
一、问题介绍
(一)案例分析
1. 倒排索引介绍
倒排索引是文档检索系统中最常用的数据结构,被广泛应用于全文搜索引擎。倒排索引主要用来存储某个单词(或词组)在一组文档中的存储位置的映射,提供了可以根据内容来查找文档的方式,而不是根据文档来确定内容,因此称为倒排索引(Inverted Index)。带有倒排索引的文件我们称为倒排索引文件,简称倒排文件(Inverted File)。
2. 案例需求及分析
现假设有三个源文件file1.txt、file2.txt和file3.txt,需要使用倒排索引的方式对这三个源文件内容实现倒排索引,并将最后的倒排索引文件输出。

首先,使用默认的TextInputFormat类对每个输入文件进行处理,得到文本中每行的偏移量及其内容。Map过程首先分析输入的<key,value>键值对,经过处理可以得到倒排索引中需要的三个信息:单词、文档名称和词频。
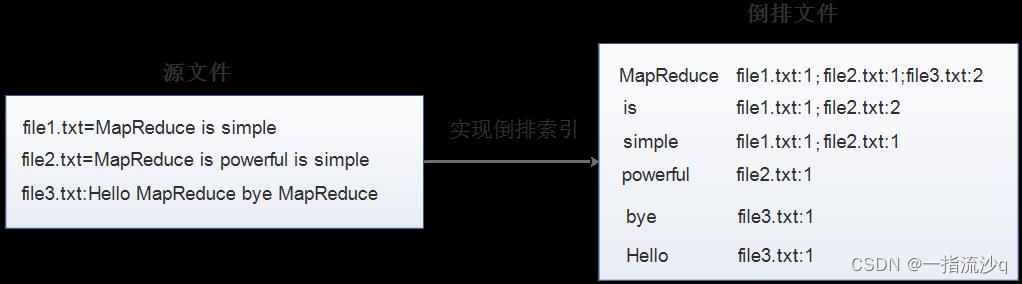
经过Map阶段数据转换后,同一个文档中相同的单词会出现多个的情况,而单纯依靠后续Reduce阶段无法同时完成词频统计和生成文档列表,所以必须增加一个Combine阶段,先完成每一个文档的词频统计。
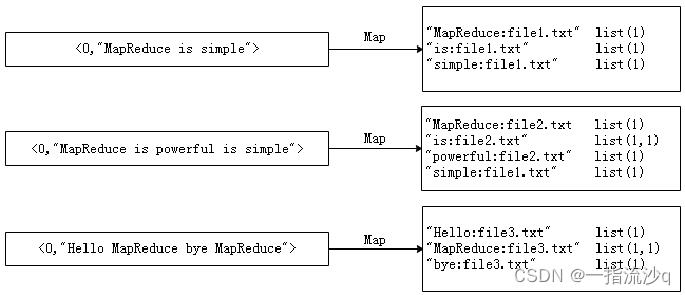
经过上述两个阶段的处理后,Reduce阶段只需将所有文件中相同key值的value值进行统计,并组合成倒排索引文件所需的格式即可。

(二)案例实现
1. Map阶段实现
首先,使用Eclipse开发工具打开之前创建的Maven项目HadoopDemo,并且新创建cn.itcast.mr.invertedIndex包,在该路径下编写自定义Mapper类InvertedIndexMapper,主要用于将文本中的单词按照空格进行切割,并以冒号拼接,“单词:文档名称”作为key,单词次数作为value,都以文本方式输出至Combine阶段。
2. Combine阶段实现
根据Map阶段的输出结果形式,在cn.itcast.mr.InvertedIndex包下,自定义实现Combine阶段的类InvertedIndexCombiner,对每个文档的单词进行词频统计。
3. Reduce阶段实现
根据Combine阶段的输出结果形式,同样在cn.itcast.mr.InvertedIndex包下,自定义Reducer类InvertedIndexMapper,主要用于接收Combine阶段输出的数据,并最终案例倒排索引文件需求的样式,将单词作为key,多个文档名称和词频连接作为value,输出到目标目录。
4. Driver程序主类实现
编写MapReduce程序运行主类InvertedIndexDriver,主要用于设置MapReduce工作任务的相关参数,由于本次演示的数据量较小,为了方便、快速进行案例演示,本案例采用了本地运行模式,指定的本地D:\\\\InvertedIndex\\\\input目录下的源文件(需要提前准备)实现倒排索引,并将结果输入到本地D:\\\\InvertedIndex\\\\output目录下
5. 效果测试
为了保证MapReduce程序正常执行,需要先在本地D:\\\\InvertedIndex\\\\input目录下创建file1.txt、file2.txt和file3.txt;然后执行MapReduce程序的程序入口InvertedIndexDriver类,正常执行完成后,会在指定的D:\\\\InvertedIndex\\\\output下生成结果文件。
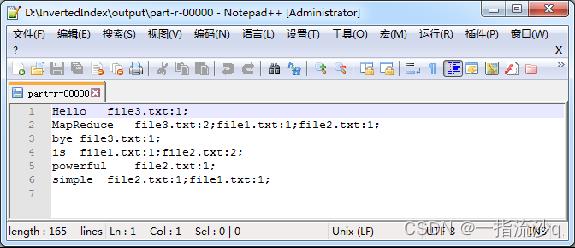
二、完整代码
package com.invert;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class InvertedIndex
public static class Map extends Mapper<Object, Text, Text, Text>
private Text keyInfo = new Text(); // 存储单词和URL组合
private Text valueInfo = new Text(); // 存储词频
private FileSplit split; // 存储Split对象
// 实现map函数
public void map(Object key, Text value, Context context) throws IOException, InterruptedException
// 获得<key,value>对所属的FileSplit对象
split = (FileSplit) context.getInputSplit();
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens())
// key值由单词和URL组成,如"MapReduce:file1.txt"
// 获取文件的完整路径
// keyInfo.set(itr.nextToken()+":"+split.getPath().toString());
// 这里为了好看,只获取文件的名称。
int splitIndex = split.getPath().toString().indexOf("file");
keyInfo.set(itr.nextToken() + ":" + split.getPath().toString().substring(splitIndex));
// 词频初始化为1
valueInfo.set("1");
context.write(keyInfo, valueInfo);
public static class Combine extends Reducer<Text, Text, Text, Text>
private Text info = new Text();
// 实现reduce函数
public void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException
// 统计词频
int sum = 0;
for (Text value : values)
sum += Integer.parseInt(value.toString());
int splitIndex = key.toString().indexOf(":");
// 重新设置value值由URL和词频组成
info.set(key.toString().substring(splitIndex + 1) + ":" + sum);
// 重新设置key值为单词
key.set(key.toString().substring(0, splitIndex));
context.write(key, info);
public static class Reduce extends Reducer<Text, Text, Text, Text>
private Text result = new Text();
// 实现reduce函数
public void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException
// 生成文档列表
String fileList = new String();
for (Text value : values)
fileList += value.toString() + ";";
result.set(fileList);
context.write(key, result);
public static void main(String[] args) throws Exception
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(InvertedIndex.class);
// 设置Map、Combine和Reduce处理类
job.setMapperClass(Map.class);
job.setCombinerClass(Combine.class);
job.setReducerClass(Reduce.class);
// 设置Map输出类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
// 设置Reduce输出类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
// 设置输入和输出目录
FileInputFormat.addInputPath(job, new Path("F:\\\\InvertedIndex\\\\input"));
FileOutputFormat.setOutputPath(job, new Path("F:\\\\InvertedIndex\\\\output"));
System.exit(job.waitForCompletion(true) ? 0 : 1);
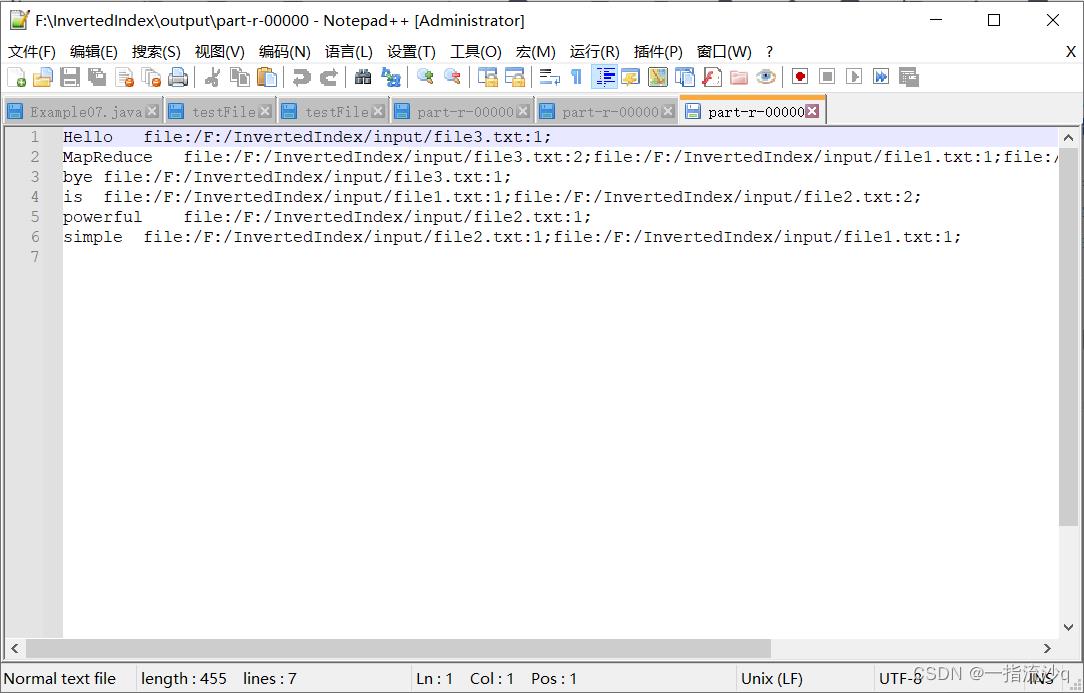
三、运行结果
以上是关于MapReduce经典案例—倒排索引的主要内容,如果未能解决你的问题,请参考以下文章