[Nutch]Hadoop单机伪分布式模式的使用(deploy)
Posted kandy_ye
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了[Nutch]Hadoop单机伪分布式模式的使用(deploy)相关的知识,希望对你有一定的参考价值。
在上一篇博文我们对Nutch进行了hadoop的配置,那么本文就对nutch的deploy模式的使用进行说明。
1. 配置抓取链接
先进入nutch的deply目录:
cd nutch/runtime/deploy和在local模式一样 ,我们先建立一个urls目录,并将抓取链接放入url.txt文件里面:
mkdir urls
echo http://www.cnbeta.com > urls/url.txt将链接文件放入hadoop的分布式文件系统上:
hadoop fs -put urls urls从web界面就可以看到里面的内容:

将本地的urls文件删除:
rm -rf urls2. 执行抓取操作
和在local模式执行同样的命令:
nohup bin/nutch crawl urls -dir data -depth 5 -threads 50 &如下图:

通过查看nohup.out就可以看到相关日志:
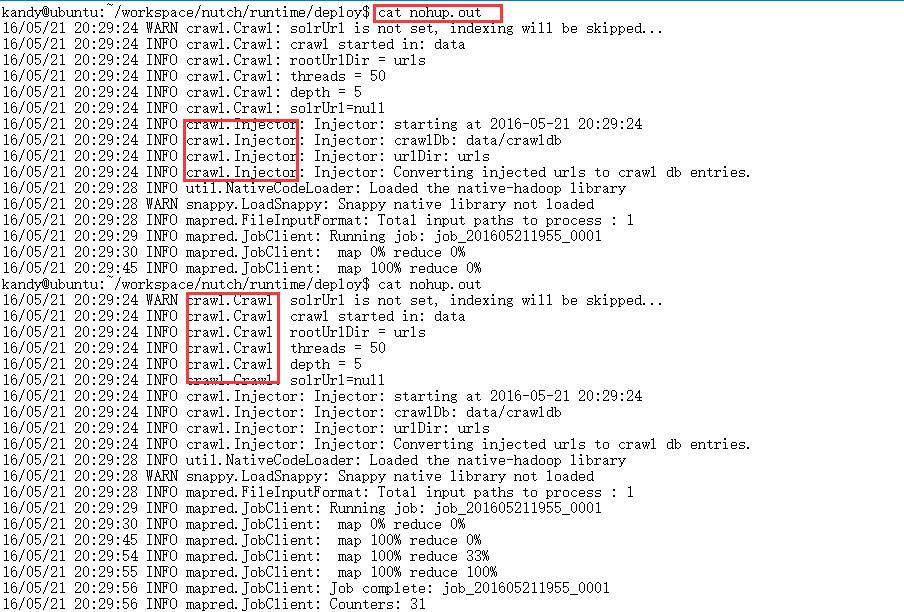
3. 通过web管理页面查看当前执行状况
3.1 jobtracker页面
从jobtracker页面可以看到当前正在执行的job和已经完成的job。
如下为正在执行的job:
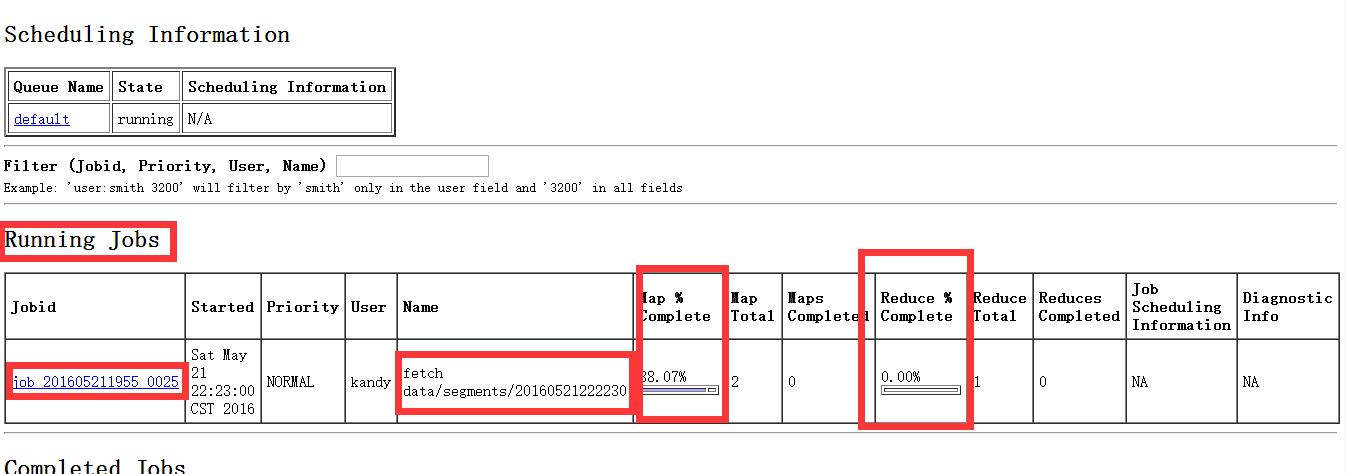
已经完成的job如下:
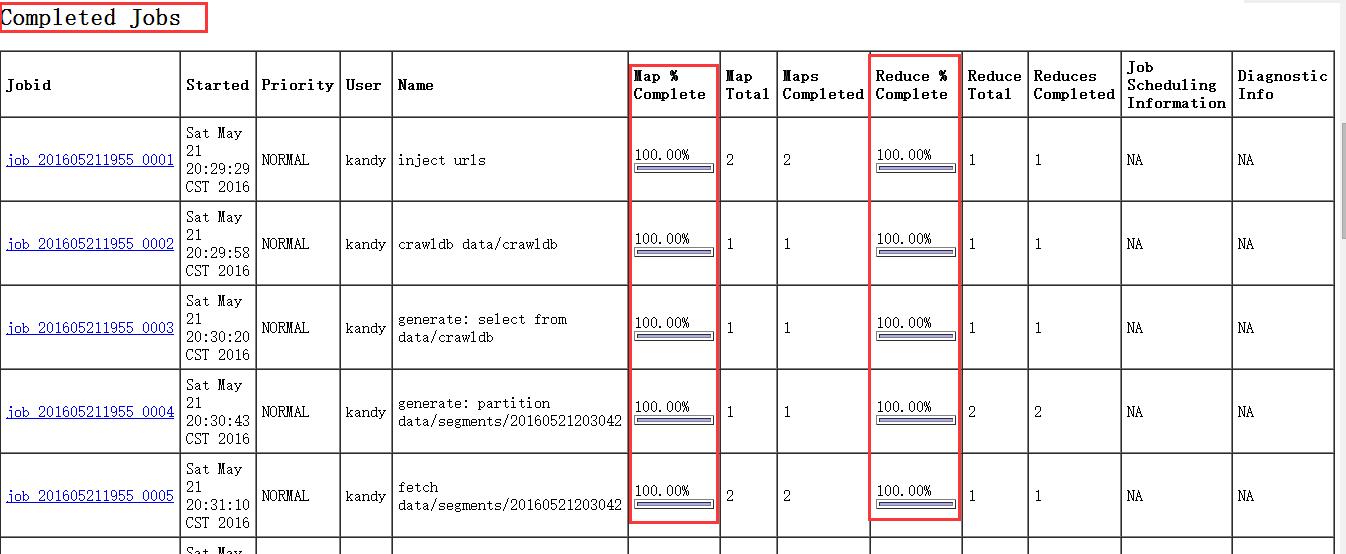
等整个任务完成之后,总体界面如下:
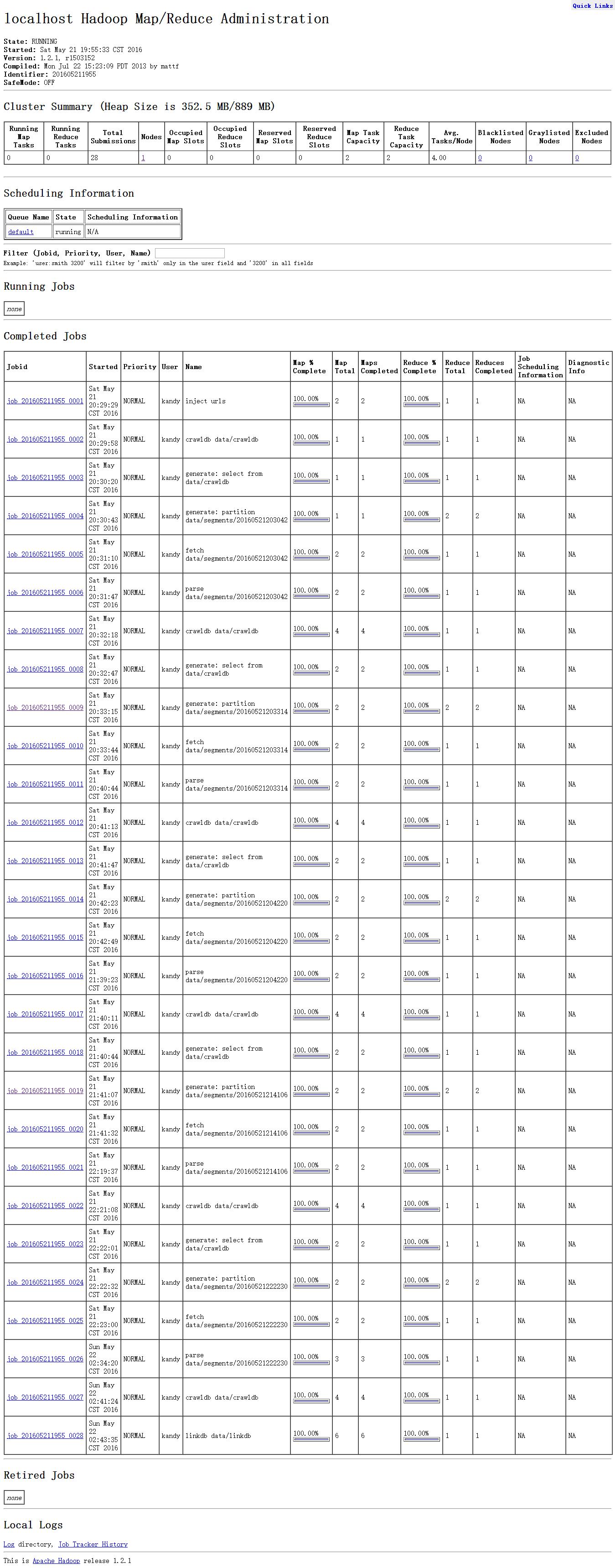
3.2 tasktracker页面
可以显示task tracker的状态,如下:

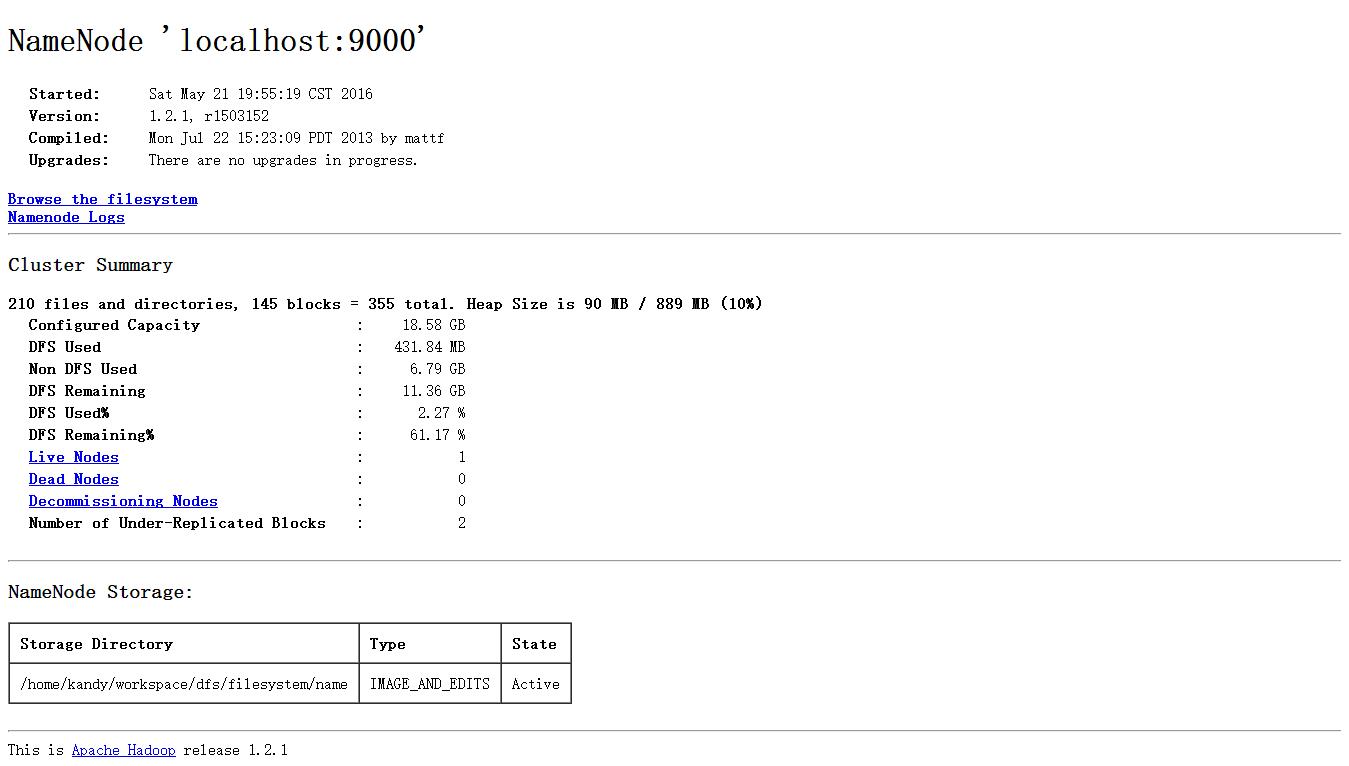
3.3 dfshealth界面
可以查看 NameNode 以及整个分布式文件系统的状态,浏览分布式文件系统中的文件以及 log 等。
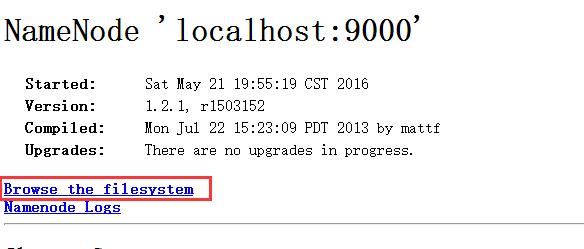
通过点击里面的“browser the filesystem”:
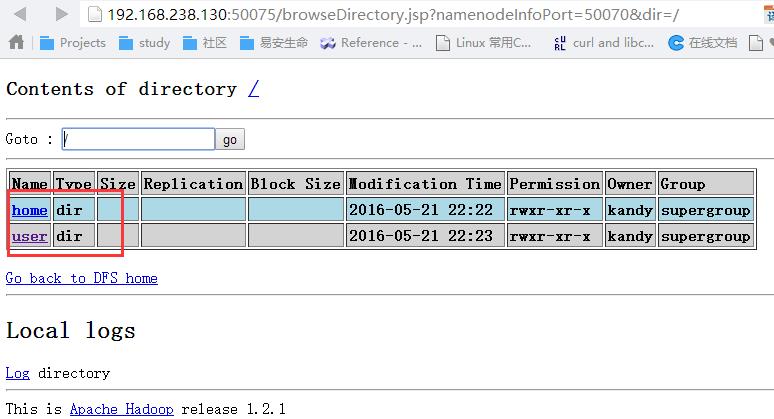
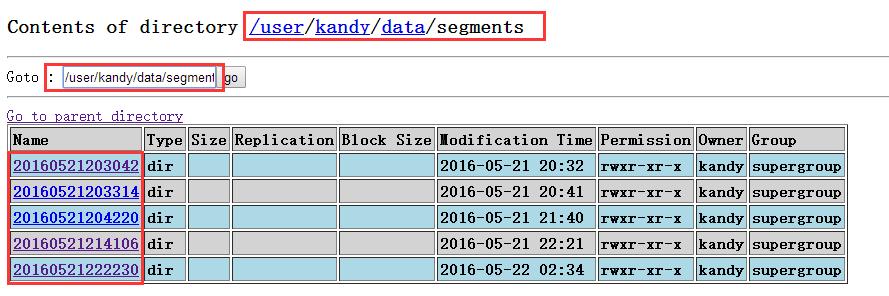
可以查看hadoop分布式文件系统里面的文件:
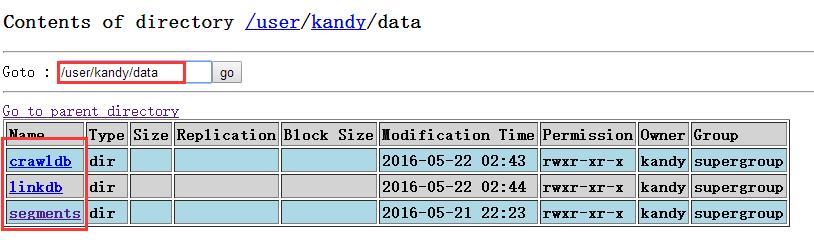
从里面可以看到segments下面的segment:
以上是关于[Nutch]Hadoop单机伪分布式模式的使用(deploy)的主要内容,如果未能解决你的问题,请参考以下文章