怎样提高报表呈现的性能
Posted ThinkWon
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了怎样提高报表呈现的性能相关的知识,希望对你有一定的参考价值。
文章目录
报表的性能很重要,是一个总被谈及的问题,跑的慢的报表用户体验恶劣,无法忍受。解决这些慢的性能问题,也成了项目方和工程师头疼的事情。一出状况,就得安排技术好的,能力强的工程师去救火,本来利润就薄,还得不断的追加人工成本,而且工程师有时候也无能为力,并不是所有的性能问题都能靠程序员能力解决的
这个总会让人头疼的问题没办法解决吗?没有好的方法去提升性能了吗?
解决这个问题之前,我们得先理清楚问题的根源,是什么导致了报表的性能问题,找到根源,我们才能对症下药,才能治本
报表性能问题出在什么环节?
报表的呈现周期中,大致可以分为下图的4个环节,4个环节都有可能造成报表的性能问题,但概率较高的是前两个环节,数据准备和数据传输(图中黄色电池电量图,代表了出问题的程度)

所以解决报表的性能问题,就得首先重点看前两个环节,虽然说这俩环节严格意义上讲其实并不属于报表的功能范畴,而是数据源本身的问题,但是用户不会去管,也分不清楚是谁的原因导致报表慢的,所以不管是实施方还是报表工具本身,得在这两方面有优化的能力才能解决这俩问题
数据准备的问题和优化
报表中展现的数据大部分情况下并不是从数据来源中直接取就可以,大都需要经过计算处理加工,准备好以后,才能被报表工具来使用
这些数据准备,多数是用SQL或存储过程来做的,一些涉及库外数据来源和计算的,可能会用其他的高级语言去处理
当这个过程出现性能问题时,首先要做的是去优化这些数据准备的代码,比如优化SQL或存储过程,完成同样运算的SQL可能有不同的写法,有可能会有相当大的性能差异(比如把EXISTS换成JOIN就能快得多)。但仍然有不少时候,即使SQL已经做了几轮优化,性能仍然起不来,这时候通常就要考虑升级硬件了,扩容数据库做集群或者升级服务器配置等,不过这又会带来额外高昂的成本
还有个办法是使用开源的SPL来替代SQL做数据准备
上面说到的,有时候经过多轮优化的SQL仍然跑不快,这是因为SQL本身有局限性,缺乏很多数据类型和基础运算,很多高性能算法都无法描述,结果只能使用较慢的算法,用了这么多年,虽然很多数据库和大数据平台都在工程上对这些慢的算法有所优化,但也只能针对简单的场景,情况复杂之后数据库的优化器依旧会“晕”掉,并没有从根本上解决SQL局限性的问题
而SPL是一种拥有全新高效算法的计算语言,可以从根本上解决各类SQL局限性导致的性能难题
我们通过一个简单小例来看一下SPL比SQL的算法高效在哪里
比如要在 1 亿条数据中取出前 10 名,用SQL算就会涉及大排序,大排序就会影响性能, 其实我们是可以想出不用大排序的算法的,但SQL无法描述,那就只能指望数据库优化器了,简单情况下,很多商用数据库确实都能优化,使用不必大排序的算法,性能通常也很好,但情况稍微变复杂一些,比如要在每个分组中取前 10 名,要用到窗口函数和子查询,这时候优化器就又无能为力了,又得乖乖去大排序,慢慢的算了
SPL则不然,SPL离散数据集中有普遍集合的概念,TopN 这种运算被认为是和 SUM 和 COUNT 一样的聚合运算,只不过返回值是个集合,用SPL去做个这个计算的时候就不需要做大排序了
有了这样更高效的算法,那速度自然就快了,性能自然也就好了
除了新的高效的算法以外,数据的存储对于性能也非常重要,好算法要有合适的存储机制配合才能生效,SPL也有自己更高效的存储方式,高性能二进制文件存储,相对于普通的数据库存储,SPL的二进制存储和SPL的高效算法配合,性能会更好,使用SPL存储后,可以把原来需要缓存的计算过程变成不需要了,原来要遍历多遍的运算变成只遍历一次甚至不用遍历了,减少硬盘访问量也是非常有效的性能提升手段

报表涉及的数据,基本都是历史数据,必要的时候,把这些数据换一种更高效的方式存储,可行性也是很大的
下面是几个用SPL来优化数据准备的实际案例,有需要的可以详细看一下
通过这些实际案例可以看出,使用SPL实现了高效的算法后,在SQL无法解决的性能问题中,可能获得数倍以至数十甚至上百倍的性能提升
到这里我们可能会想,解决个性能问题还得把原先的SQL甚至是存储方式都舍弃,全部用新的SPL重新做,这也太费劲了,代价太大了吧
是的,小问题是没这个必要折腾,但是遇上重病那就只能用猛药来医了,当现有的SQL已经无法再继续优化,性能问题已经没办法解决时,那就只能尝试用新的办法来解决了
而且体会过更高效的算法以后,使用新技术估计也不会再是一种迫不得已的选择了,而是会变成更主动自愿的拥抱了
另外一些报表工具已经集成了开源的SPL了,比如润乾报表,直接用这样的工具来做报表,解决起问题来也更直接方便一些
数据传输的问题和优化
报表项目大部分都是JAVA应用,基本都得通过JDBC来取数、做数据传输,有时候我们会发现,SQL很简单,数据库负担也很轻,但数据传输到报表却需要很长时间,传输完成后,报表也算的很快,那就可以判定,就是有些数据库的JDBC取数太慢,导致了性能问题
这是DB本身的问题,怎么优化?
我们动不了厂商的JDBC,那就只能曲线救国,单线程取的慢,如果数据库允许,我们可以尝试多线程并行取,如果报表工具有并行取数的功能,那问题就迎刃而解了,但由于并行取数涉及的数据分段方法和数据库及取数语法需要较复杂代码控制,也不容易做成报表功能,所以目前的报表工具基本都不支持并行取数,那就又得再外围实现了
外围实现,可以是自己用java等高级语言去写,但是会复杂一些,工作量也不小,也可以用现成的计算工具去做,比如前面提到的SPL就可以轻松支持并行计算,下图就是SPL并行取数的代码,写起来还是很简单的,也容易理解

在数据库负担不重时,并行取数几乎可以让传输效率得到线性的提升
附上一个并行取数和单线程取数的性能测试对比,感兴趣的同学可以去看看
同样的,如果报表工具中集成了SPL,那也就可以通过并行取数来提升性能了

其他环节的问题和优化
报表内计算和呈现
前两个重点的环节看完了,大头已经解决了,不过还是有些报表的性能问题出在后面的环节中,我们来看下,后两个环节是报表内的计算和呈现
先看计算
报表内的计算,首先要看报表工具的基本功,另一方面也要看外围计算引擎,基本功好,可以保证大部分表内计算都不出问题,有外部计算引擎,可以保证特殊情况也运行无恙
我们以业界性能口碑比较好的润乾报表为例,即使它在相同条件下各类报表,各种计算的性能都优于同类产品,但由于报表工具本身定位的局限性,再好的工具也不可能任何情况下都跑的快,遇到跑不快的情况,工具本身没有优化空间时,那就还得借助外部计算引擎的能力才行
举个最简单的例子,比如要在报表里做多源关联,我们需要写一个类似这样的表达式ds2.select(ID==ds1.ID),表达式很简单,但是计算复杂度却是平方级的,数据量不大时,都没问题,数据量稍大时,到几千行,那性能就会急剧下降了,再好的工具处理这样的运算也会有问题
但如果把这个关联放到报表外来做,利用外部的计算引擎计算能力,可以使用低复杂的HASH算法(而在报表工具中无法对多个数据源先统一处理,实现不了这种算法),那性能就会大幅度的提升了
以下是我们在数据量比较大时,用润乾报表单独运算和SPL+润乾报表协同运算的性能对比,可以看出,报表内的计算性能问题,如果挪到外部计算引擎解决,效果是非常好的
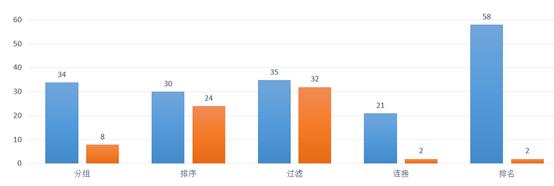
(蓝色是润乾报表单独运算的时间,橙色是SPL+润乾报表协同运算的时间)
再看呈现
这个就完全看报表本身的能力了,没有其他外围方式可以协助和利用了,如果呈现环节总出问题,那就得考虑换工具了
附上一个如何考察报表工具本身计算和呈现性能的帖子,有需要的可以参考:
大报表
报表性能问题们还有一个场景需要注意,就是大清单式报表,比如电信行业,要查看当月所有的充值记录,这样的报表,格式简单,但是数据量极大,有的可达到千万级以上,这类大数据量的报表呈现时如果等着把这些记录全部检索出来再生成报表,那会需要很长时间,用户体验自然会非常恶劣,而且报表一般采用内存运算机制,大多数情况下内存里也装不下这么多数据,所以我们一般都会使用分页呈现的方式,尽量快速地呈现出第一页,之后再通过翻页来加载后面的
这种分页呈现的方式通常是利用数据库的分页机制来实现,但数据库分页不仅有如下这些弊端,而且程序代码和对应的数据库是强耦合的,万一换了数据源,那还得重新做一遍

更好的方式是,取数和呈现做成两个异步线程,取数线程发出 SQL 后就不断取出数据后缓存到本地存储中,呈现线程根据页数计算出行数到本地缓存中去获取数据显示,如下图所示
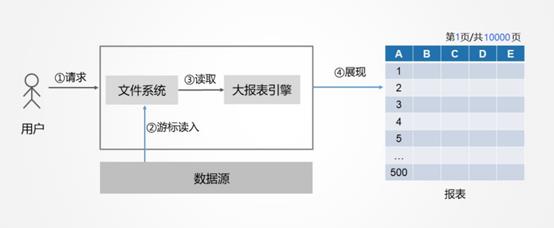
通过这样的方式,就可以很好的解决大数据量清单式报表的性能难题了具体如何实现可以参考:大清单报表该怎么做?
总结
从前面所述的几个优化过程中可以看出,大部分性能问题,都是在报表工具外做的优化,数据准备在报表外,数据传输在报表外,表内计算慢时,大部分也可以挪到报表外,只有呈现这一个环节是报表内的
所以单凭一个报表工具想完全解决报表的性能问题是不太可能的,要真正彻底的解决性能难题,除了看报表本身的性能外,更需要重点看工具有没有外围的计算引擎来协助,报表本身能力强,又有计算引擎帮忙(类似内置了开源SPL的润乾报表),一套组合拳打下来,报表性能问题才能真正解决
如果报表工具本身性能就很普通,还没有其他计算引擎辅助,那是谁也不可能把老爷车的发动机优化到F1赛车的马力的
润乾报表资料
欢迎对润乾报表有兴趣的加小助手(VX号:RUNQIAN_RAQSOFT),进技术交流群
以上是关于怎样提高报表呈现的性能的主要内容,如果未能解决你的问题,请参考以下文章