文献阅读与想法笔记14Beyond a Gaussian Denoiser: Residual Learning of Deep CNN for Image Denoising
Posted 呆呆象呆呆
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了文献阅读与想法笔记14Beyond a Gaussian Denoiser: Residual Learning of Deep CNN for Image Denoising相关的知识,希望对你有一定的参考价值。
背景与相关工作
传统方法评价
- 传统方法在测试阶段通常涉及一个复杂的优化问题,使得去噪过程比较耗时,大多数方法在不牺牲计算效率的情况下很难实现高性能。
methods generally involve a complex optimization problem in the testing stage, making the denoising process time-consuming
most of the methods can hardly achieve high performance without sacrificing computational efficiency
- 这些模型通常是非凸的,并且涉及多个手动选择的参数,为提高去噪性能提供了一定的提升空间
the models in general are non-convex and involve several manually chosen parameters, providing some leeway to boost denoising performance
深度学习方法评价
-
cnn具有与MRF模型相似甚至更好的表示能力
-
限制图像结构的完整特征的捕捉
-
通过阶段贪婪训练和各阶段间的联合微调来学习参数,并涉及大量手工参数
-
针对特定的噪声水平训练特定的模型,限制了图像盲去噪。
-
在对未知噪声进行高斯去噪时,一种常见的方法是先估计噪声级,然后使用相应噪声级训练的模型。这使得去噪结果受到噪声估计精度的影响。
-
此外,这些方法不能应用于非高斯噪声分布的情况下,如SISR和JPEG去块。
贡献
- 用于去除高斯噪声的端到端深度神经网络结构DnCNN,与现有基于深度神经网络直接估计潜在干净图像的方法不同,该网络采用残差学习策略从噪声观测中去除潜在干净图像。
- 发现残差学习和批归一化对CNN的学习有很大的好处,它们不仅可以加快训练速度,还可以提高去噪性能。对于具有一定噪声水平的高斯去噪,DnCNN在定量指标和视觉质量方面都优于最先进的方法
- DnCNN可以很容易地扩展到处理一般的图像去噪任务。我们可以训练一个单一的DnCNN模型进行盲高斯去噪,并取得比竞争的方法训练特定的噪声水平更好的性能。
- 该算法只需要一个DnCNN模型,就可以解决三个一般的图像去噪任务,
- 盲高斯去噪,噪声水平未知的高斯去噪
- SISR,多尺度因子的单图像超分辨率
- JPEG去块。不同质量因子的JPEG图像块化
DnCNN使用单个残差单元来预测残差图像在残差网络[29]之前,在一些低水平视觉问题如单图像超分辨率[38]和彩色图像反混播[39]中,已经采用了残差图像预测的策略。然而,据我们所知,目前还没有直接预测残差图像去噪的工作。
网络结构
图像退化模型(加性噪声)
y = x + v \\mathbfy=\\mathbfx+\\mathbfv y=x+v
v \\mathbfv v加性白噪声,控制 σ \\sigma σ
神经网络前馈结构
DnCNN
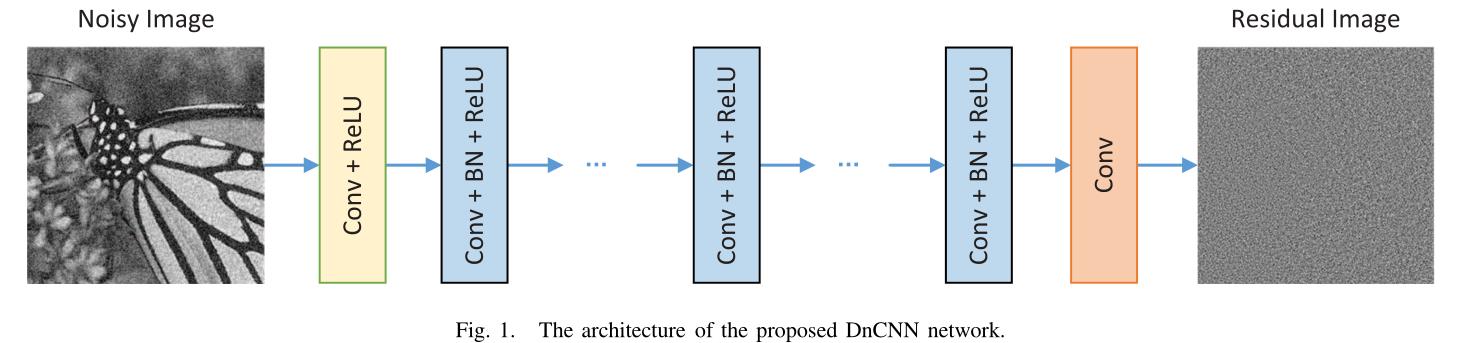
理论说明
-
通过已经成功的网络结构的理论说明(他人的前馈以及反馈公式)推导中的部分公式,去证明DnCNN有这个公式的部分功能,以此证明数学上有价值
网络细节
-
不是直接输出去噪后的图像,而是用于预测残差图像(噪声),即噪声观测图像与潜在干净图像之间的差异
-
DnCNN通过在隐藏层中的操作隐式地去除潜在的干净图像。通过隐藏层逐渐将图像结构从噪声观测中分离出来。这种机制类似于EPLL和WNNM等方法中采用的迭代去噪策略。
用来训练原始映射 f ( y ) = x f(y) = x f(y)=x进行预测,也可以训练残差映射 R ( y ) = v R(y) = v R(y)=v 进行预测。
前者更加倾向于一个恒等映射。相较于残差的噪声v,y更像潜在的干净图像x(特别是当噪声水平较低时)。残差学习公式更适合于图像去噪。
According to [29], when the original mapping is more like an identity mapping, the residual mapping
will be much easier to be optimized. Note that the noisy observation y is much more like the latent clean image x than the residual image v (especially when the noise level is low). F(y)would be more close to an identity mapping than R(y), and the residual learning formulation is more suitable for image denoising.所提出的网络两种功能均可
The network shown in Fig. 1 can be used to train either the original mappingF(y)to predictxor the residual mapping R(y)to predict v.
-
CNN在提高利用图像特征的容量和灵活性方面是有效的
-
CNN训练的正则化和学习方法取得了长足的进展,包括ReLU[27]、批归一化[28]和残差学习[29]。在CNN中采用这些方法可以加快训练过程,提高去噪性能。结果表明,残差学习和批归一化可以相互受益,它们的融合可以有效地加快训练速度,提高去噪性能。
-
CNN非常适合在现代强大的GPU上进行并行计算,可以利用它来提高运行时性能。
-
我们在卷积前直接填零,以确保中间层的每个feature map与输入图像的大小相同。我们发现简单的零填充策略不会导致任何边界伪影。这种良好的特性可能归因于DnCNN的强大能力。
Loss
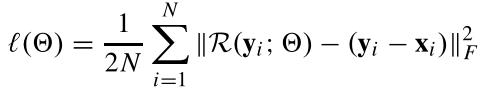
the averaged mean squared error between the desired residual images and estimated ones from noisy input
多功能的实现
- 当v为高分辨率真实图像与低分辨率图像的双线性差值上采样的差值时,用于高斯去噪的图像退化模型可以转化为单图像超分辨率(SISR)问题
- JPEG图像的分块问题也可以用相同的图像退化模型来建模,取v作为原始图像和压缩图像之间的差值。
we observe that when v is the difference between the ground truth high resolution image and the bicubic upsampling of the low resolution image, the image degradation model for Guassian denoising can be converted to a single image super- resolution (SISR) problem
when v is the difference between the ground truth high resolution image and the bicubic upsampling of the low resolution image, the image degradation model for Guassian denoising can be converted to a single image super- resolution (SISR) problem; analogously, the JPEG image deblocking problem can be modeled by the same image degradation model by taking v as the difference between the original image and the compressed image.
深度与有效感受野
3×3 but remove all pooling layers
Therefore, the receptive field of DnCNN with depth of d should be(2d+1)×(2d+1).
去噪神经网络的接受域大小与去噪方法的有效patch大小[30],[31]有关。此外,高噪声水平通常需要更大的有效patch大小来获取更多的上下文信息来恢复[41]。
因此,通过确定噪声水平σ=25,我们分析了几种主流去噪方法的有效patch大小,以指导我们的DnCNN的深度设计。
- 在BM3D[2]中,非局部相似patch在一个大小为25×25的局部寡妇中自适应搜索了两次,最终有效patch大小为49×49。
- 与BM3D类似,WNNM[15]使用了更大的搜索窗口,迭代执行非局部搜索,导致了相当大的有效patch大小(361×361)。
- MLP[31]首先使用一个大小为39×39的patch生成预测的patch,然后使用大小为9×9的过滤器对输出的patch进行平均,因此其有效patch大小为47×47。
- CSF[17]和TNRD[19]分为五个阶段,共涉及十层卷积层,滤光片大小为7×7,有效patch大小为61×61。
测试实验结果
DnCNN-S specific noise level
DnCNN-B blind Gaussian denoising
CDnCNN-B colour
DnCNN-3 three task trained
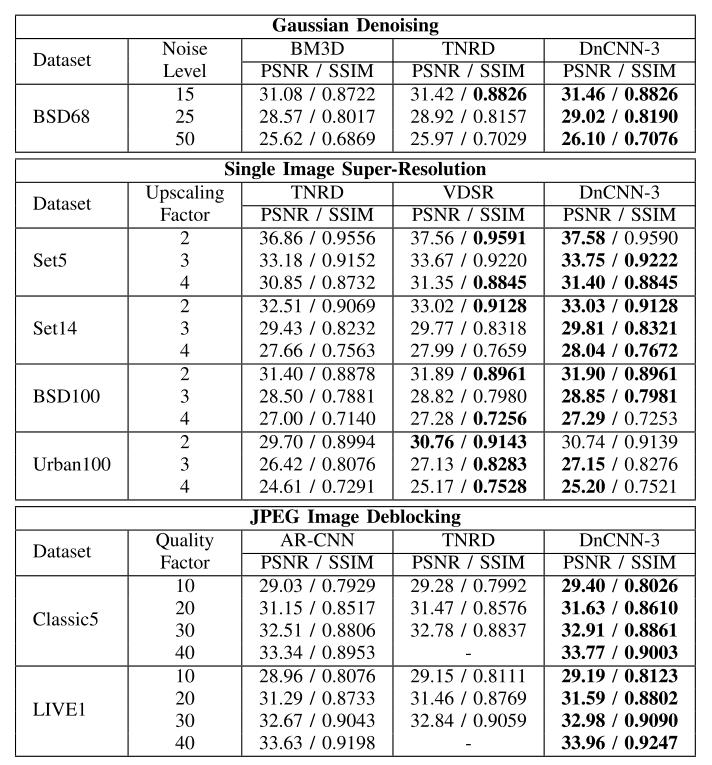
- 高斯去噪,使用最先进的BM3D和TNRD进行比较。BSD68数据集用于测试性能。对于BM3D和TNRD,假设噪声水平是已知的。
- SISR,考虑了两种最先进的方法,即TNRD和VDSR[42]。TNRD为每个升比例因子训练一个特定的模型,而VDSR[42]为所有三个升比例因子(即2,3,4)训练一个单一的模型。采用[42]中使用的四个测试数据集(即Set5 and Set14, BSD100 and Urban100[47])。先对高分辨率图像进行双三次下采样,再对图像进行双三次上采样,生成高分辨率图像的SISR输入。
- JPEG图像去块,DnCNN-3与两种最先进的方法,即AR-CNN[48]和TNRD[19]进行了比较。AR-CNN方法针对JPEG质量因子10、20、30和40分别训练了4个具体模型。对于TNRD,有三种JPEG质量模型。使用MA TLAB JPEG编码器压缩质量因子从5到99的图像生成JPEG分块输入。
常用数据集合
set5 set14 BSD68 BSD100 BSD500 Urban100 T91
优化器、BN、残差的消融实验
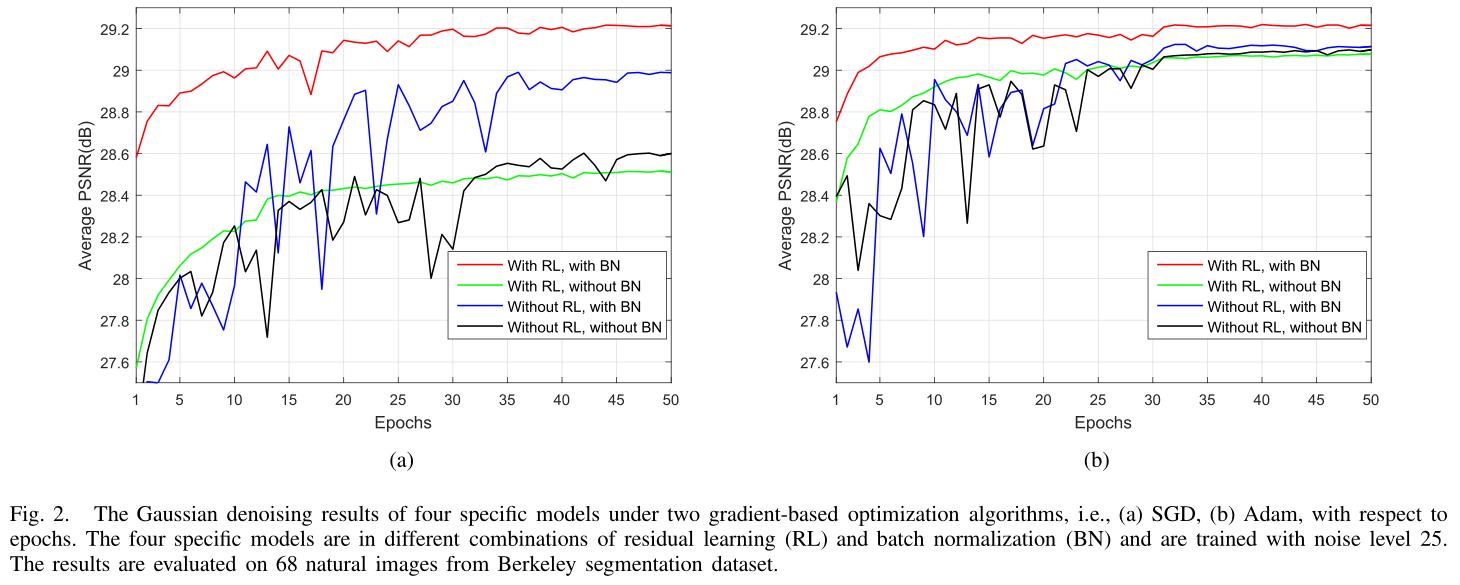
结论与分析
需要有BN 需要有残差学习,优化器的实现要求不高
在没有残差学习的情况下,批处理归一化甚至会对收敛产生一定的不利影响(蓝线)。使用残差学习,可以利用批归一化来加速训练并提高性能(红线)。
残差学习的意义 为了去除隐藏在有噪声图像中的干净图像 这使得每一层的输入都是高斯分布的,相关性较小,与图像内容的相关性较小。
因此,残差学习也可以帮助批处理归一化,减少内部协变量移位。这使得每一层的输入都是高斯分布的,相关性较小,与图像内容的相关性较小。因此,残差学习也可以帮助批处理归一化,减少内部协变量移位。
固定噪声等级

个人想法:效果一般尤其是在考量计算量的情况下
- 原因一:他使用的是Titan X GPU系列。理论上来说应该是属于最快的性能
- 原因二:个人想法部分有另外一个叙述

比较试验

一个例子来展示提出的模型对三个不同任务的能力。
输入图像由噪声等级为15(左上)和25(左下)的噪声图像、上标度因子为2(中上)和3(中下)的双三次插值低分辨率图像、质量因子为10(右上)和30(右下)的JPEG图像组成。
需要注意的是,输入图像中的白线只是用来区分这六个区域,而残差图像则被归一化到[0,1]的范围内进行可视化。即使输入图像在不同的区域有不同的失真,恢复后的图像看起来很自然,没有明显的伪影。
(1)输入图像(2)输出残留图像(3)恢复图像。
我觉得存在的问题
- 缺少一个有价值的实验过程
需要证明的问题是,本网络结构有较强的网络适应能力,可以实现盲噪声的降噪,对他人网络也应该进行如下多等级噪声训练,并且展示训练结果,如果他人的网络结构,在实现这个任务的时候如果他人的网络结构是有缺陷或者不可以实现的,也应该进行指出。
- 批处理的问题
基本上大部分图像处理的网络结构中都不会有这个部分,为什么这里有实际的价值是实现多种噪声问题或者可能存在的不同的噪声类型,让他们属于到同一分布。
残差学习的意义 为了去除隐藏在有噪声图像中的干净图像 这使得每一层的输入都是高斯分布的,相关性较小,与图像内容的相关性较小。
因此,残差学习也可以帮助批处理归一化,减少内部协变量移位。这使得每一层的输入都是高斯分布的,相关性较小,与图像内容的相关性较小。因此,残差学习也可以帮助批处理归一化,减少内部协变量移位。
- 网络结构的深度原理
高噪声需要更深的网络更加打的有效感受野获取上下文纹理信息
如果所有的噪声等级或者针对所有的模糊都进行相同的网络结构深度的处理的话,大概率可能会出现人工伪影。
- 关于恒等变换的问题
恒等变换那一段 是不是最重要的原因在于:如果非常趋近于恒等变换就会出现一些问题,网络训练趋近于恒等式。而恒等变换强行把所有输入固定位一个弱化的恒等表达式,不能比较敏感的察觉到比较低水平的噪声。
以上是关于文献阅读与想法笔记14Beyond a Gaussian Denoiser: Residual Learning of Deep CNN for Image Denoising的主要内容,如果未能解决你的问题,请参考以下文章