KafKa - SpringBoot 集成 Kafka 及 消息的顺序性
Posted 小毕超
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了KafKa - SpringBoot 集成 Kafka 及 消息的顺序性相关的知识,希望对你有一定的参考价值。
一、Kafka
Kafka是由Apache软件基金会开发的一个开源流处理平台,由Scala和Java编写。Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者在网站中的所有动作流数据。 这种动作(网页浏览,搜索和其他用户的行动)是在现代网络上的许多社会功能的一个关键因素。 这些数据通常是由于吞吐量的要求而通过处理日志和日志聚合来解决。 对于像Hadoop一样的日志数据和离线分析系统,但又要求实时处理的限制,这是一个可行的解决方案。Kafka的目的是通过Hadoop的并行加载机制来统一线上和离线的消息处理,也是为了通过集群来提供实时的消息。
本文主要实践 Kafka 在SpringBoot 的中的使用,及如何手动 ack 确认消息,及保证消息的顺序性问题。
关于 Kafka 集群模式的安装,可参考下面我的博客:
下面开始 SpringBoot 集成 Kafka 的实践。
二、SpringBoot 集成 Kafka
-
pom中引入依赖
<dependency> <groupId>org.springframework.kafka</groupId> <artifactId>spring-kafka</artifactId> </dependency>
-
修改配置 application.yml
server: port: 80 spring: kafka: # kafka服务器地址(可以多个) bootstrap-servers: 192.168.159.128:9092,192.168.159.129:9092,192.168.159.130:9092 consumer: # 指定一个默认的组名 group-id: kafkaGroup # earliest:当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,从头开始消费 # latest:当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,消费新产生的该分区下的数据 # none:topic各分区都存在已提交的offset时,从offset后开始消费;只要有一个分区不存在已提交的offset,则抛出异常 auto-offset-reset: earliest # key/value的反序列化 key-deserializer: org.apache.kafka.common.serialization.StringDeserializer value-deserializer: org.apache.kafka.common.serialization.StringDeserializer producer: # key/value的序列化 key-serializer: org.apache.kafka.common.serialization.StringSerializer value-serializer: org.apache.kafka.common.serialization.StringSerializer # 批量抓取 batch-size: 65536 # 缓存容量 buffer-memory: 524288 #失败重试次数 retries: 3 # 服务器地址 #bootstrap-servers: 192.168.159.128:9092,192.168.159.129:9092,192.168.159.130:9092 -
创建Toptic,分区数为 3 ,副本数为 1
@Bean public NewTopic newTopic() return new NewTopic("mytop",3, (short) 1); -
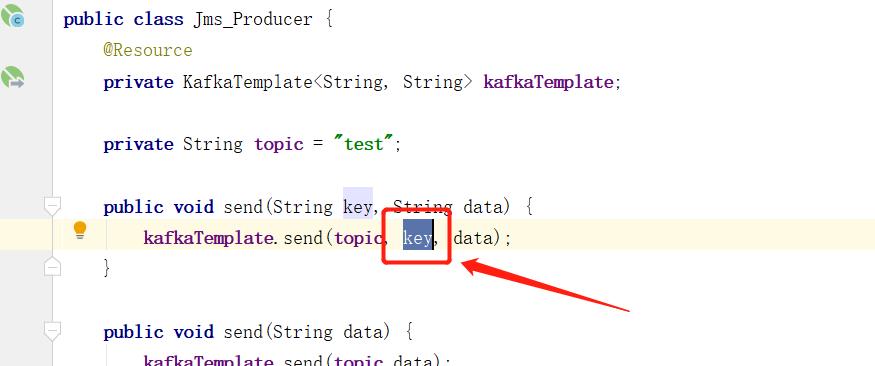
消息生产者 JmsProducer.java
@Component public class JmsProducer @Resource private KafkaTemplate<String, String> kafkaTemplate; private String topic = "mytop"; public void send(String key, String data) kafkaTemplate.send(topic, key, data); public void send(String data) kafkaTemplate.send(topic,data); -
消息消费者 JmsConsumer.java
@Slf4j @Component public class JmsConsumer @KafkaListener(topics = "mytop") public void receive(ConsumerRecord<?, ?> consumer) log.info("topic:" + consumer.topic()); log.info("key:" + consumer.key()); log.info("value:" + consumer.value()); log.info("分区位置:" + consumer.partition()); log.info("下标:" + consumer.offset()); -
测试
@RestController public class TestController @Autowired JmsProducer producer; @GetMapping("/GetTest") public String GetTest() producer.send("mykey","哈哈哈哈哈"); return "success"; @GetMapping("/GetTest2") public String GetTest2() producer.send("哦哦哦哦哦哦"); return "success";
打印日志:
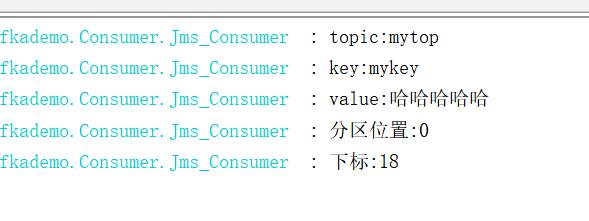

打印日志:
三、手动提交offset
默认配置是自动提交的模式,这种情况下,kafka将消息交给消费者后便提交了 offset,假如消费端处理业务报错,但是偏移量已经提交到了kafka服务端,则这条消息再无法进行处理了,这在MQ中相当于消息的丢失。
这种情况可以配置 auto.commit.enable 为false,表示kafak的offset由消费者手动维护,spring-kafka提供了通过ackMode的值表示不同的手动提交方式。
修改配置文件,增加配置:
spring:
kafka:
enable-auto-commit: false

增加配置类,指定 kafka的提交模式:
@Configuration
public class KafKaConfig
@Bean
public KafkaListenerContainerFactory<ConcurrentMessageListenerContainer<String, String>> kafkaListenerContainerFactory(ConsumerFactory<String, String> consumerFactory)
ConcurrentKafkaListenerContainerFactory<String, String> factory = new ConcurrentKafkaListenerContainerFactory<>();
factory.setConsumerFactory(consumerFactory);
factory.getContainerProperties().setPollTimeout(1500);
//配置手动提交offset
factory.getContainerProperties().setAckMode(ContainerProperties.AckMode.MANUAL);
return factory;
消费者断,通过 Acknowledgment 确认消息:
@KafkaListener(topics = "mytop")
public void receive01(ConsumerRecord<?, ?> consumer, Acknowledgment ack)
log.info("topic:" + consumer.topic());
log.info("key:" + consumer.key());
log.info("value:" + consumer.value());
log.info("分区位置:" + consumer.partition());
log.info("下标:" + consumer.offset());
// 手动提交
ack.acknowledge();
四、Kafka如何保证消息顺序性
在kafka中我们会对mq实现分区、多个消费者集群消费消息,生产者投递的消息会给多个不同的消费者分摊消费消息,无法保证每个消息执行的先后顺序问题。
在kafka 中,同一个分区中的消息,可以保证顺序性,但不同的分区无法确保顺序消费,因此生产者投递消息时,一定要存放在同一个分区中,最终被同一个消费者消费消息。
那如何保证在一个分区呢,Kafka中已经帮我们实现好了,只需要投递消息都设置相同的 key的情况下都会存放到同一个分区中,最终被同一个消费者消费消息。
消息顺序后势必降低消费的效率,因此合理设置分区就十分重要了,增加多个不同的Partition分区 实现 一个消费者对应一个Partition分区,从而减轻压力,提高效率。
四、Kafka消费组
-
消费者从kafka分区中获取消息,默认的情况下是根据该分组中对应分区已经提交的offset值开始消费。
-
当消费者消费成功之后,默认的情况下会提交该消息的offset值,下次消费者获取消息则从该提交的offset+1开始消费。
-
当分区的数量达到了消费者集群数量,无需再继续新增消费者数量,即一个分区只能对应一个消费者,同一组中当消费者数大于分区数时,多余的消费者不会接收消息,但可以作为备用消费者,当处理的消费者挂掉后,备用消费者可以继续进行处理。
以上是关于KafKa - SpringBoot 集成 Kafka 及 消息的顺序性的主要内容,如果未能解决你的问题,请参考以下文章