Object Detection系列 Fast R-CNN
Posted JeemyJohn
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Object Detection系列 Fast R-CNN相关的知识,希望对你有一定的参考价值。
作者:张 旭
编辑:黄俊嘉

该内容是目标检测系列的第三篇,系列前部分内容如下,点击可查看:
Object Detection系列(一) R-CNN
Object Detection系列(二) SPP-Net
Fast R-CNN简介
在之前的两个文章中,我们分别介绍了R-CNN与SPP-Net,于是在2015年RBG(Ross B. Girshick)等结合了SPP-Net的共享卷积计算思想,对R-CNN做出改进,于是就有了Fast R-CNN。首先简单介绍下Fast R-CNN。
相比于之前两种算法,Fast R-CNN提出了:
多任务损失函数(Multi-task loss)
感兴趣区域池化(RoI pooling layer)
它由以下几个部分组成:
ss算法
CNN网络
SoftMax
bounding box
首先在SPP-Net与R-CCN一直使用的SVM分类器被换成了SoftMax,SPP-Net中的SPP换成了
RoI pooling,多任务损失函数的引入整合了分类网络的损失函数与bounding box回归模型的损失函数,使任务不需要分阶段训练,区域建议依然使用ss算法生成,并在卷积后的特征图上提取(充分共享卷积计算),初始模型从AlexNet换成了VGG16。
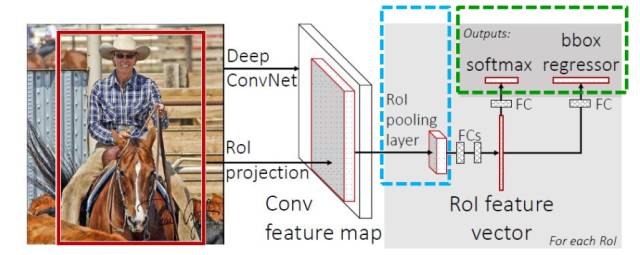
感兴趣区域池化

上面这张图说明了SPP与RoI pooling的区别,其实RoI pooling是SPP的一种简化,原本SPP是一种多尺度的池化操作,最后将三个尺度的特征做串接作为全连接层的输入,而RoI pooling只选择了其中一种尺度,将ss算法的建议框做坐标变化后的尺寸的长和宽,平均分为w份和h份,在每一份中使用最大池化,最后产生w*h个bin,这样做有下面几个好处:
1.统一输出维度,这个是必须的。
2.相比于SPP-Net,RoI pooling的维度更少,假设RoI pooling选择了4*4的话,那么维度就可以从21个bin降低为16个,虽然这样看来降低的并不多,但是不要忘了特征还有厚度,如果厚度是256的话,那么降维就比较可观了。
3.RoI pooling不再是多尺度的池化,这样一来梯度回传就会更方便,有利于Fast R-CNN实现end-to-end的训练。
感兴趣区域池化的梯度回传
在上说提到了,RoI pooling是单层的SPP,也就是只用一层金字塔并在区域内做Max pooling,所以如何说在卷积层上提取特征的时候,特征的位置没有出现重叠,RoI pooling就是一个Max pooling,梯度回传也是一样的,而出现位置重叠的时候,梯度回传才会发生变化。
那么先解释一下什么是重叠:
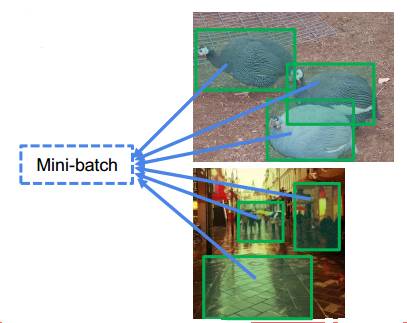
我们知道Fast R-CNN的区域建议同样是ss算法生成的,那么一幅图片在生成多个建议框时(假设是2个)可能会出现一些像素重叠的情况,就像下面这样:

而这种情况就没有重叠:

显然,重叠的区域经过相同的坐标变换之后在卷积特征图上同样是有重叠的,那么这部分重叠的像素梯度应该如何让计算呢?
是多个区域的偏导之和:
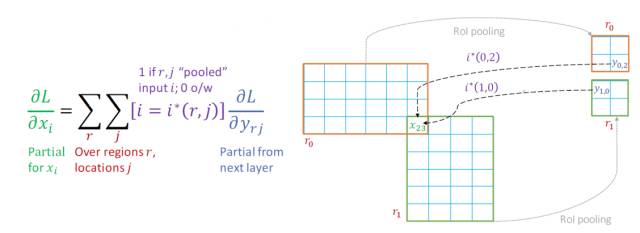
上图中有r0与r1两个区域,每个区域都通过RoI pooling之后生成4个bin,x23的意思是第23个像素,那么计算x23位置的梯度就可以根据上图中左侧的公式,其中r是包含有这一点的区域,j是某个区域内的所有位置。
但是x23的梯度计算显然不需要r0,r1内的所有位置的梯度信息,它只需要包含x23这一点的,或者说是x23这一点有贡献的点的梯度,所以这里需要一个阈值函数—i*(r,j),它的作用就是如果需要RoI pooling后的这一点的梯度,那么i*(r,j)=1,否则i*(r,j)=0。
这样一来,RoI pooling层的梯度回传只需要在Max pooling上简单修改即可。
多任务损失函数
Multi-task loss是Fast R-CNN最重要的改进了,它将分类模型的损失函数与bounding box模型的损失函数加到了一起,这样一来就不再需要分阶段的训练了,而是实现了end-to-end。
首先分类模型的loss:
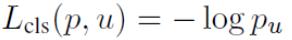
其中p是每个RoI的概率分布:
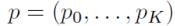
而u是Ground truth的类别,显然u的范围为(0,…,k)
显然,这就是损失函数一个交叉熵,只是它简写了,或者说换了一种形式。
Bounding box回归模型的loss:
这个loss和R-CNN中的Bounding box的loss没啥区别,都是在用实际的边界框信息与ss算法给出的边界框信息构建一个L1距离。如下:

其中平滑方程的具体形式如下:

而平滑方程里面的东西,就和R-CNN一样了。最后,组合的多任务损失函数为:

其中
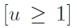
是一个指示函数,作用就是背景类不需要bounding box修正,也就没有回归loss。
Fast R-CNN训练与测试
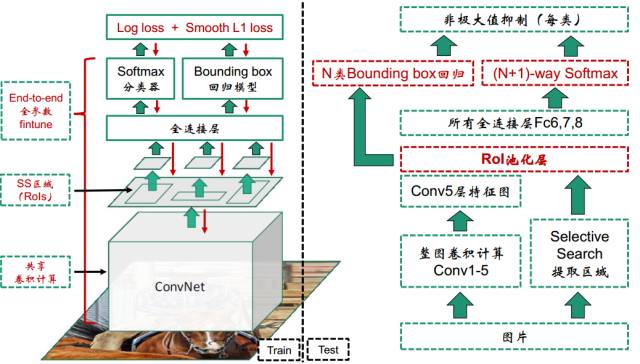
上面这张图解释了Fast R-CNN的训练与测试过程,前面两部分说明了RoI pooling层的梯度回传与多任务损失函数的构建,所以Fast R-CNN的梯度可以一直传到卷积层,实现end-to-end的训练。
此外,为了在训练事得到更好的效果,作者提出了一种分级抽样法,如果batch-size为128的话,那么这128个RoI由2张图片,各生产64个区域。
而Fast R-CNN的测试过程和之前没啥区别。
Fast R-CNN性能评价
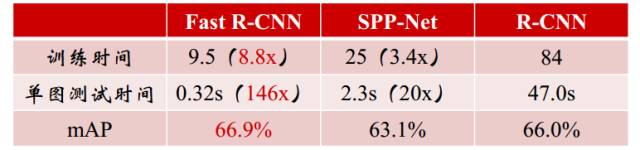
上面这张图对比了R-CNN,SPP-Net与Fast R-CNN的训练时间,单张图片的测试时间与mAP,可以看到由于Fast R-CNN可以end-to-end的训练,它的mAP比R-CNN还要高一些,这样就不会出现像SPP-Net那样mAP降低的情况,而在训练时间与测试时间上,又一次有了较大进步。
那么为什么Fast R-CNN比SPP-Net更快呢,最重要的原因就是end-to-end的训练,这样训练不再是分阶段的。
Fast R-CNN的问题
虽然上面那张图上写的,Fast R-CNN的单图测试时间为0.32s,但是其实这样说并不准确,0.32为了和R-CNN的47.0s做对比。是的Fast R-CNN依然没有脱离ss算法,但是ss算法跑一张图的时间,大概是2s,所以讲道理的话,Fast R-CNN依然是达不到实时检测的要求的,好在ss算法在Faster R-CNN中被换成RPN(区域建议网络),这个我们后面再说。

该内容是目标检测系列的第三篇,
后续还有系列连载,
~敬请期待~

2.Object Detection系列(二) SPP-Net
扫描个人微信号,
拉你进机器学习大牛群。
福利满满,名额已不多…

80%的AI从业者已关注我们微信公众号















以上是关于Object Detection系列 Fast R-CNN的主要内容,如果未能解决你的问题,请参考以下文章