一文彻底了解元数据管理与架构设计
Posted 宝哥大数据
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了一文彻底了解元数据管理与架构设计相关的知识,希望对你有一定的参考价值。
一、元数据治理在整个数据治理体系的位置
数据治理很火,在 DAMA 数据管理知识体系指南中,数据治理位于 “数据管理车轮图” 的正中央,如下图:
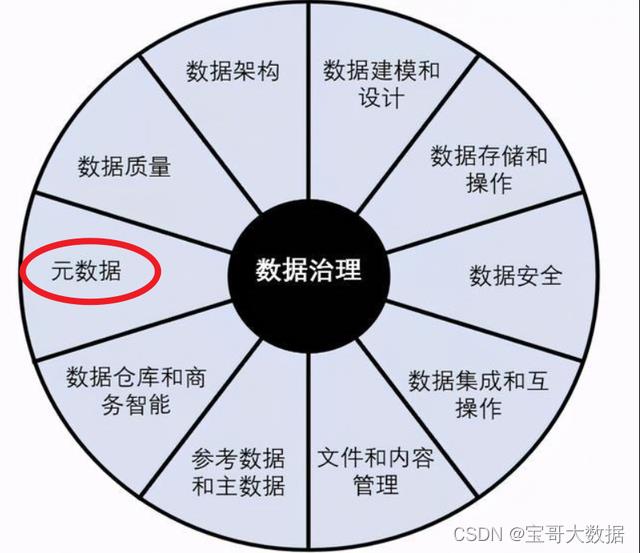
而元数据管理,正是十大数据管理领域其中很重要的一环。
数据资产治理的前提是要有数据,并且要求数据类型全、量大,并尽可能的覆盖数据流转的各个环节。元数据的采集和管理就变得尤为重要,它是数据资产治理的核心底座。
二、什么是元数据
所谓元数据,就是 “关于数据的数据”。举一个例子,比如 175 这个数字,它在特定场景下,有如下的元数据:
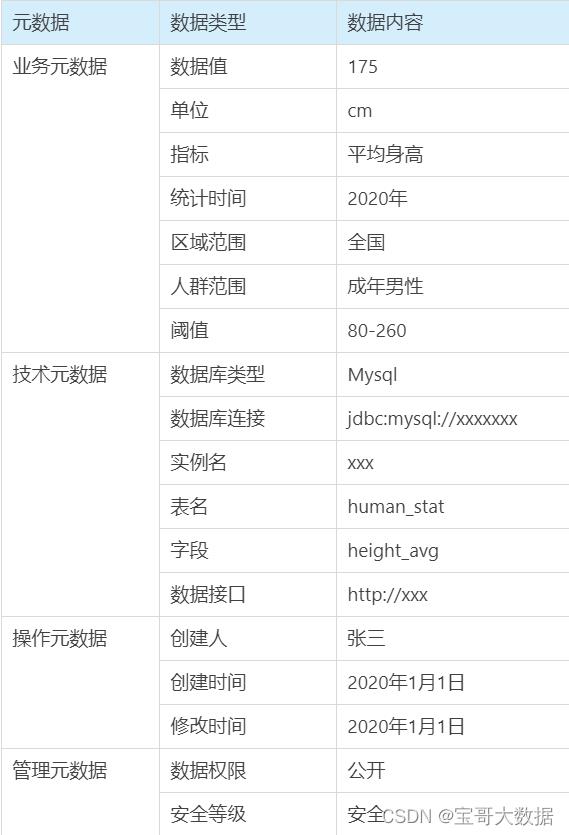
在这个表格中,175 是实体数据,而业务元数据、技术元数据、操作元数据、管理元数据,从各种不同的角度描述了 175 这个数字,他们都属于元数据。
可以再举个例子,元数据就像 “户口本”,户口本中除了有姓名、出生日期、住址、民族等信息外,还有家庭的血缘关系,父子关系,兄弟关系等。这些信息就构成了对这个人的详细描述,这些信息就是描述这个人的元数据。
对于数据平台来说,收集各类元数据可以帮助数据平台回答下面的问题:
- 我们有哪些数据?
- 数据存储是多少?
- 如何查找这些数据?
- 数据的流转是怎么样的?
- 通过血缘关系进行溯源和问题分析。
三、元数据的分类
元数据的分类,一般来说可分为:
- 技术元数据
- 业务元数据
- 操作元数据
- 管理元数据
但其实元数据的分类并没有那么的严格,因为有些指标在不同的视角下可能属于不同的分类。
举个例子,比如数据安全等级,对于安全部门来说就是业务元数据了,但是在开发部门来看,就是一种管理元数据。
3.1、技术元数据
1、数据库对象属性;
2、物理数据库表名,备注,主键,索引
3、物理表的大小,行数,文件数,分区数,存储类型,表类型,索引名称,索引字段,索引类型,约束
4、字段属性,包括字段名,字段注释,字段类型,是否主键,是否自增,是否外键等等;
5、ETL 作业详细信息,名称,责任人,脚本,任务配置(执行时间,执行频率,是否互斥,上游依赖等),任务调度时长,产出信息等;
6、物理表和字段的访问权限、权限组、权限角色等信息;
7、物理模型和实物资产的关系;
8、文件格式定义;
9、恢复和备份规则;
10、数据集群的吞吐量,QPS,调度任务消耗 CPU,内存大小等信息;
11、数据血缘,表/字段级别的上下游依赖关系;任务输入/输出表依赖关系;
3.2、业务元数据
1、数据库表的业务域,所在的项目,所在的集群;
2、业务规则、转换规则、计算公式、推导公式等(更多是文档);
3、数据模型;
4、数据质量规则和核检结果;
5、数据标准;
6、数据的安全,隐私级别;
7、数据使用说明等
3.3、操作元数据
1、批处理的执行日志;
2、调度异常记录及处理;
3、报表和查询的访问模式,访问频率和执行时间;
4、数据产生;
5、表的访问(查询,关联,聚合等);
6、字段的访问;
7、物理表的创建时间,创建人,更新时间,更新人
3.4、管理元数据
1、人员
2、流程
3、职责、岗位
4、组织、部门;
四、元数据的架构
元数据的架构,一般分为集中式架构和分散式架构。
集中式的架构,指的是采集多种数据源的元数据到元数据自己的存储中来,再集中加工给其他场景提供服务;而分散式的架构,没有自己的元数据存储,而是在使用的时候,去即时的查询其他数据源的元数据。
这两种架构各有利弊。
集中式的架构,可以快速的检索元数据,抽取的时候,也可以自由的转换,自定义补充,提升了元数据的质量;同时也有缺点,需要保证自身存储和其他源数据的一致性,增加了流程复杂度和工作量。
分散式架构的优点是,元数据总能够保持最新,查询更加的简单;缺点也很明显,无法自定义或修改元数据项,查询也受源系统可用性的影响。
一般我们推荐使用集中式架构,定时采集源系统的元数据,通过 hook 方式捕捉各种引擎运行时数据血缘关系,并且定义通用的数据模型提供给第三方接入使用。
最后我们设计了如下的元数据架构:
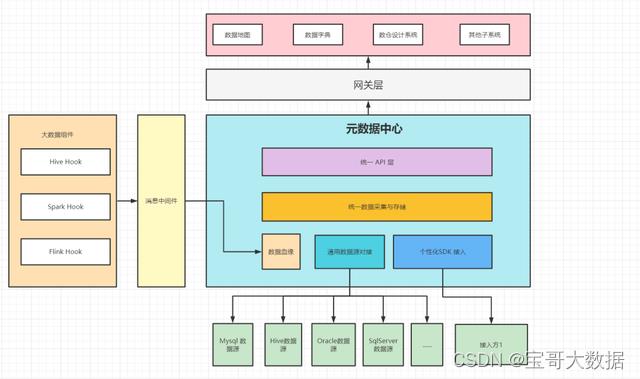
4.1、使用 Hook 方式采集作业运行时数据血缘
作业的数据血缘,有三种方式来采集:
- 静态解析 SQL;
- 实时抓取正在执行的 SQL,解析执行计划,解析输入表和输出表;
- 解析任务日志,获取输入表和输出表。
第一种方式,静态解析 SQL,可以使用 Antlr4 仿照 Hive 的 SQL 解析来实现,但是不能保证 SQL 的准确性,因为任务都没有执行。
第二种方式,实时抓取执行的 SQL,这是执行后产生的,可以保证是准确的;
第三种方式,要分析大量的日志,而且时效性很难保证。
所以,第一种方式和第二种方式都是可以的,优先选择第二种方式来做。
当前众多大数据组件都提供了 Hook 钩子的方式,相当于以插件的方式实时的捕捉执行计划。解析之后,推送到 Kafka,再去解析到分布式的图数据库中。
4.2、通用的数据源模块来对接多种数据源
一般公司肯定是存在多种不同类型的数据源的,比如 mysql,Oracle,Hive 等,可以制作一个通用的模块,提供统一的接口,来对接这些不同的数据源。
数据源模块则提供三方接口供采集模块定时采集数据源的元数据信息。
核心的技术点,就是要隔离不同数据源的驱动,这些驱动也需要以插件化来集成到数据源模块中。
4.3、还需要提供个性化的 SDK 接入
如果公司的核心业务部门比较多,公司的数据平台产品比较多,那么势必会产生一些其他的元数据。比如监控平台监控的资源使用情况、任务调度的任务运行情况等。
这种 SDK 接入,需要考虑接入时的安全校验,限流(可定时消费一批Kafka数据来实现)等问题。
4.4、后端存储的统一模型
元数据类型纷繁杂乱,需要统一整理抽象,再分类存储,并且设计之初,就要尽可能的详尽所有情况,设计出统一的表模型,预留扩展字段。
有一套模型是专门解决元数据模型通用性问题的,叫做 CWM (Common Warehouse Metamodel)标准,翻译过来是公共仓库元模型,这里提供了三层元模型来存储一切不同类型的元数据,当然设计起来比较复杂,一般超大型企业会采用这种模型。
如果可以详尽公司未来的元数据种类,可以分门别类建不同类型的元数据模型表来解决。
参考有赞这样的大公司,元数据可分为:
- 基础元数据表;
- 趋势数据表;
- 任务元数据表;
- 血缘数据表
元数据应用
最后,我们再罗列一下元数据的比较全的应用场景
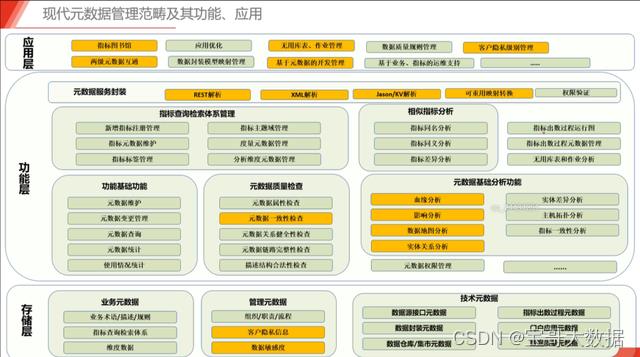
可以看到,建立好企业的元数据,便可以为数据治理打下坚实的基础,也可衍生出丰富的应用,如数据地图,血缘分析,数据冷热分析,数据资产管理等。
以上是关于一文彻底了解元数据管理与架构设计的主要内容,如果未能解决你的问题,请参考以下文章