新时代内存分配器:TCMalloc
Posted 凌桓丶
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了新时代内存分配器:TCMalloc相关的知识,希望对你有一定的参考价值。
文章目录
TCMalloc
什么是 TCMalloc?
TCMalloc 全称 Thread-Caching Malloc,即线程缓存的 malloc,实现了高效的多线程内存管理,用于替代系统的内存分配相关的函数(malloc、free,new,new[] 等)。
TCMalloc 主要用于解决什么问题呢?
TCMalloc 是一种内存分配器,旨在替代系统默认分配器,其具有以下特性:
- 大多数对象的快速、非竞争分配和释放。对象会被以两种模式进行缓存,每个线程缓存或每个逻辑 CPU 缓存。大多数分配不需要使用锁,因此多线程应用程序的争用低且可扩展性好。
- 灵活使用内存,因此释放的内存可以重新用于不同大小的对象,或者返回给操作系统。
- 通过分配相同大小的对象的 page 来降低每个对象的内存开销,从而高效的利用小空间。
- 低开销采样,可以详细了解应用程序的内存使用情况。
TCMalloc 是如何对内存管理进行优化的呢?
- 通过管理特定大小的内存块(称为“页面”)从操作系统执行分配。使所有这些内存块具有相同的大小允许 TCMalloc 简化簿记。
- 将单独的页面(或在 TCMalloc 中称为“Spans”的页面运行)用于特定的对象大小。例如,所有 16 字节的对象都放置在专门为该大小的对象分配的“Span”中。在这种情况下获取或释放内存的操作要简单得多。
- 在缓存中保存内存以加快对常用对象的访问。即使在解除分配之后持有此类缓存也有助于避免在以后重新分配此类内存时进行代价高昂的系统调用。
基本概念
Page
Page 是 TCMalloc 管理内存的基本单位。默认大小为 8 KB,可在 configure 时通过选项调整为 32KB 或 64KB。
Page 越大,TCMalloc 的速度相对越快,但其占用的内存也会越高。简单说,就是空间换时间。默认的 Page 大小通过减少内存碎片来最小化内存使用,但跟踪这些 Page 会花费更多的时间。使用更大的page则会带来更多的内存碎片,但速度上会有所提升。
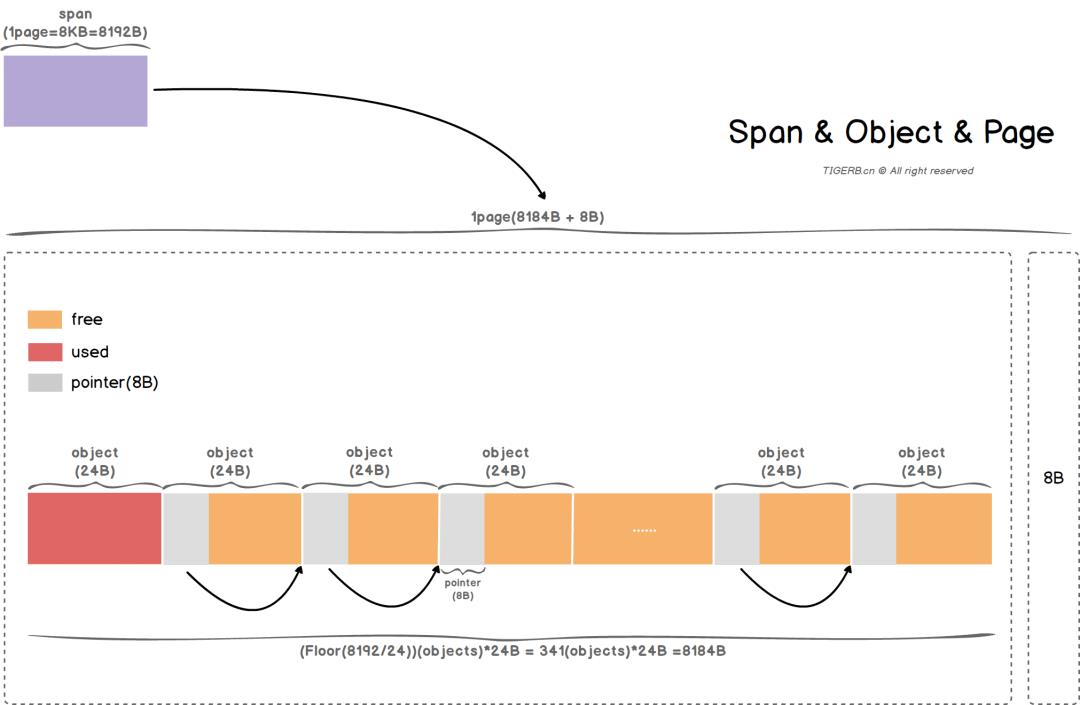
Span
一个或多个连续的 Page 组成一个 Span。TCMalloc 以 Span 为单位向系统申请内存。

以上图为例:
- 2 个 Page 构成 16KB 的 Span。
- 3 个连续 Page 构成的 24KB 的 Span。
- ……
在每个 Span 中,其通过 length 记录了包含的 page 的数量,通过 start 记录起始 page 的 PageID。
Object
一个 Span 会被按照某个大小拆分为 N 个 Objects,同时这 N 个 Objects 构成一个 FreeList。TCMalloc 以 Object 为单位给用户分配内存。
下图即为 Page、Span、Object 三者的关系
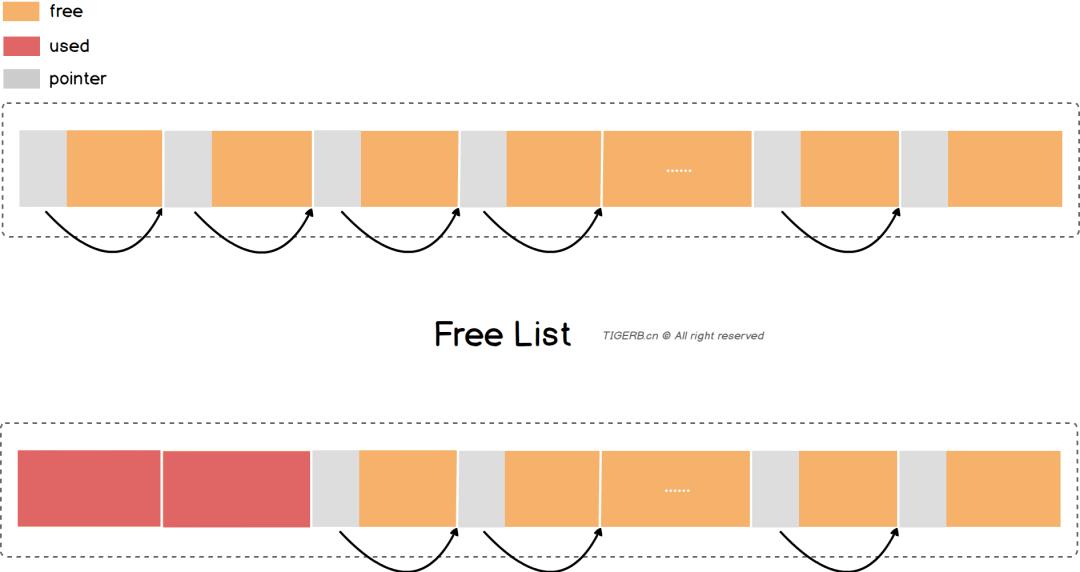
FreeList
FreeList 是 TCMalloc 用来管理 Object 的一个线性结构。其本质上是一个链表,但是与传统的链表实现又有所不同:
- FreeList 没有 Next 属性,其使用 Value 的前 8 字节存放下一个节点的指针。
- 分配出去的节点,节点整块内存空间可以被复写(指针的值可以被覆盖掉)。
结构如下图所示:
SizeClass
我们之前提到过,一个 Span 会被按照某个大小拆分为 N 个 Objects,那它是如何来确定拆分的规则呢?这就需要提到 SizeClass 了。
SizeClass 是一个映射列表,其映射了申请不同的空间时对应的 Object 大小以及 Page 数量、批量移动的 Objects 数量。
// https://github.com/google/tcmalloc/blob/master/tcmalloc/size_classes.cc
//...
const SizeClassInfo SizeMap::kSizeClasses[SizeMap::kSizeClassesCount] =
// <bytes>, <pages>, <batch size> <fixed>
0, 0, 0, // +Inf%
8, 1, 32, // 0.59%
16, 1, 32, // 0.59%
24, 1, 32, // 0.68%
32, 1, 32, // 0.59%
40, 1, 32, // 0.98%
48, 1, 32, // 0.98%
56, 1, 32, // 0.78%
64, 1, 32, // 0.59%
72, 1, 32, // 1.28%
80, 1, 32, // 0.98%
88, 1, 32, // 0.68%
96, 1, 32, // 0.98%
104, 1, 32, // 1.58%
112, 1, 32, // 0.78%
120, 1, 32, // 0.98%
128, 1, 32, // 0.59%
136, 1, 32, // 0.98%
144, 1, 32, // 2.18%
160, 1, 32, // 0.98%
176, 1, 32, // 1.78%
192, 1, 32, // 2.18%
208, 1, 32, // 1.58%
224, 1, 32, // 2.18%
//...
114688, 14, 2, // 0.04%
131072, 16, 2, // 0.04%
139264, 17, 2, // 0.03%
155648, 19, 2, // 0.03%
172032, 21, 2, // 0.03%
204800, 25, 2, // 0.02%
237568, 29, 2, // 0.02%
262144, 32, 2, // 0.02%
;
//...
基本结构
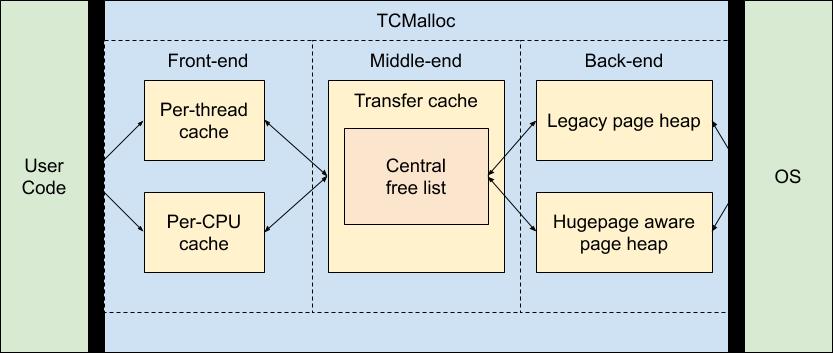
我们可以将 TCMalloc 分解为三个组件。前端、中端和后端。
- 前端是一个缓存(Thread/CPU Cache,由具体模式确定,通常为 Thread),为应用程序提供快速分配和释放内存。
- 中端 CentralFreeList 负责重新填充前端缓存。
- 后端 PageHeap 管理从操作系统获取的内存。
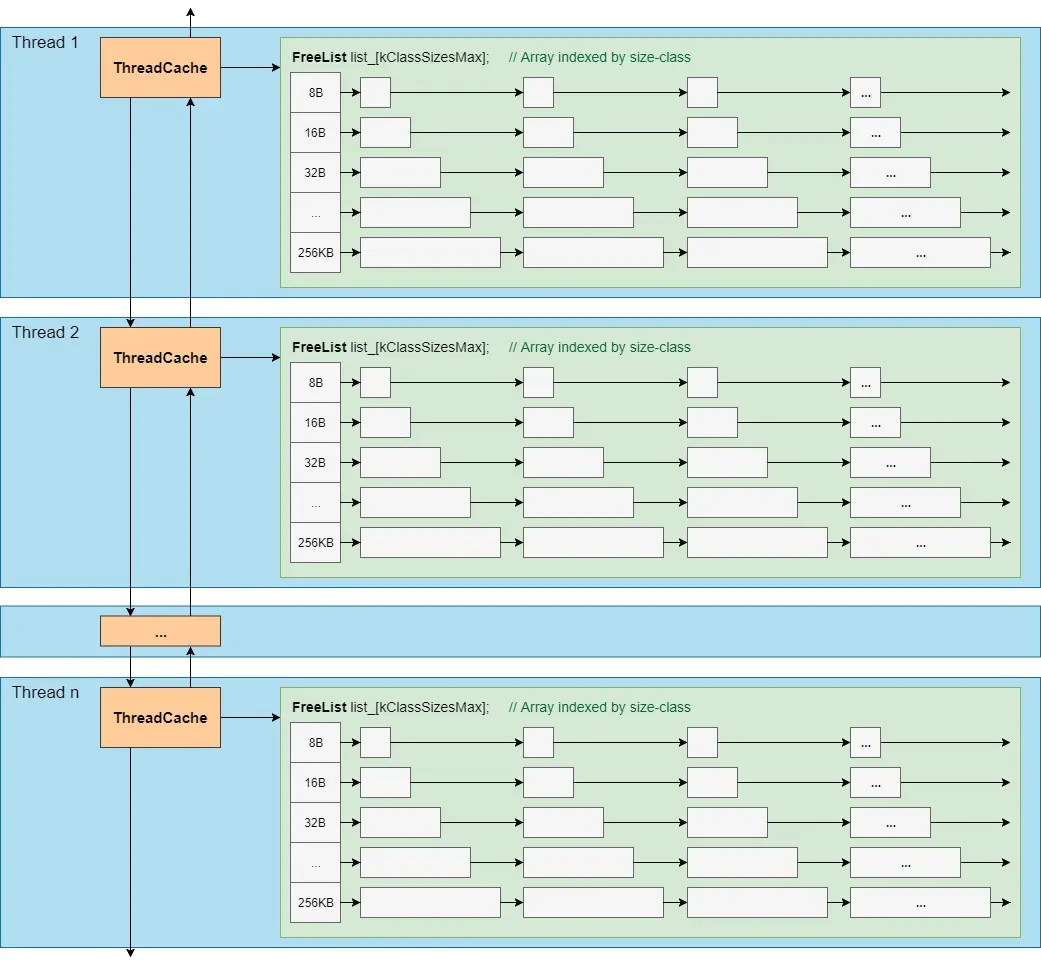
ThreadCache
为了快速分配内存,避免锁竞争,TCMalloc 中每一个线程都会持有一个 ThreadCache。每个 ThreadCache 中对于每个 size class 都有一个单独的 FreeList,缓存了 N 个还未被应用程序使用的空闲对象。
// https://github.com/google/tcmalloc/blob/master/tcmalloc/thread_cache.h
class ThreadCache
//...
FreeList list_[kNumClasses]; // Array indexed by size-class
//...
;
例如下标为 0 的 FreeList,其保存的 Object 大小为 8 byte,下标为 1 的即为 16 byte,以此类推。
CentralFreeList
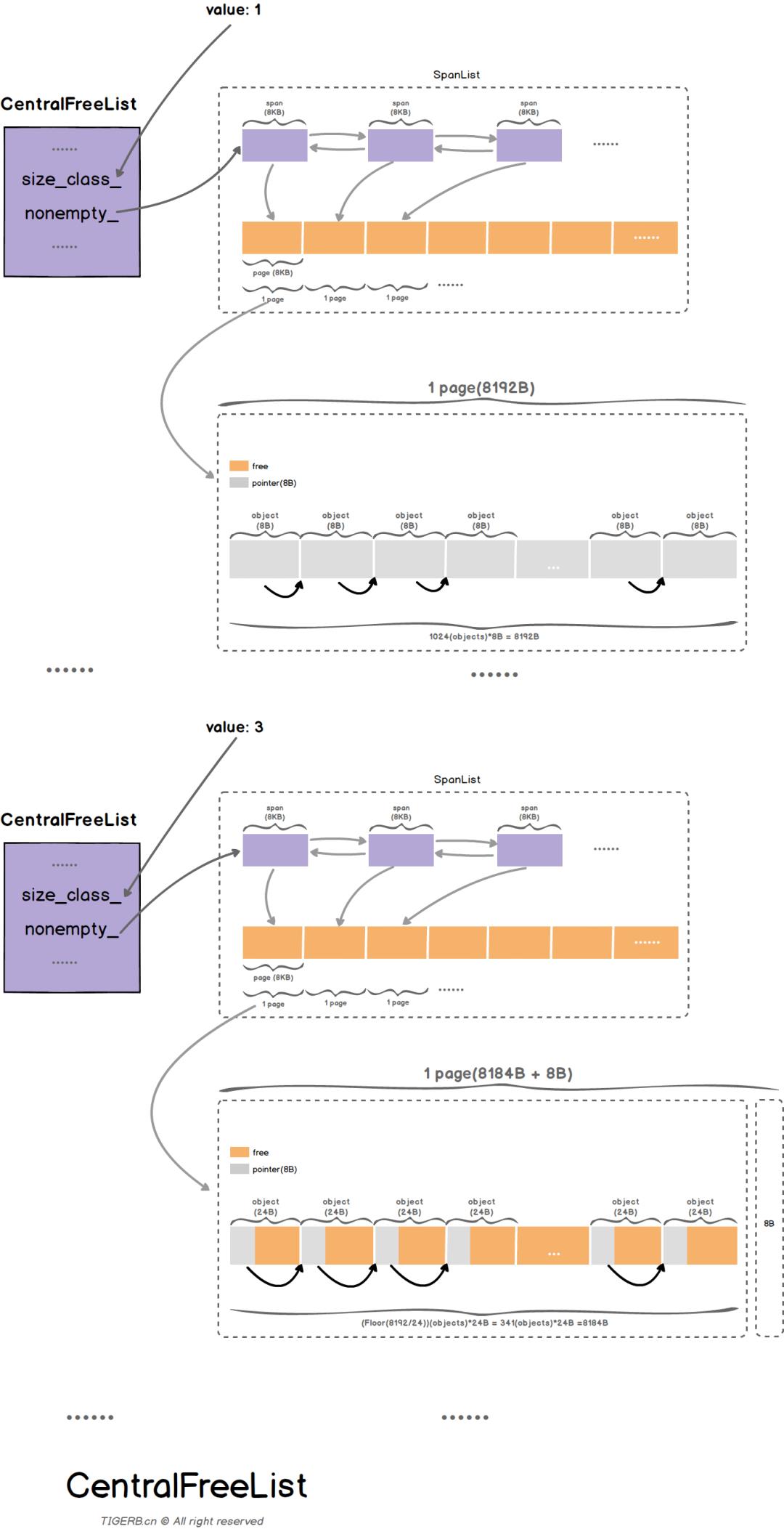
那么 ThreadCache 中的空闲对象从何而来呢?答案是 CentralFreeList,其是所有线程公用的中央缓存。
由于所有线程共享 CentralFreeList,因此当线程从 CentralFreeList 处获取缓存时需要通过加锁保证线程安全。而为了避免大量的加锁开销,通常 ThreadCache 会批量进行缓存的取用/回收。
// https://github.com/google/tcmalloc/blob/master/tcmalloc/central_freelist.h
template <typename ForwarderT>
class CentralFreeList
//...
private:
absl::base_internal::SpinLock lock_; // span锁,保证并发安全
size_t size_class_; // SizeClass,用于找到SizeMap中对应的大小
size_t object_size_; // object的总数量
size_t objects_per_span_; //一个Span持有的object的数量
Length pages_per_span_; //一个Span持有的page的数量
HintedTrackerLists<Span, kNumLists> nonempty_ ABSL_GUARDED_BY(lock_);
//保存了还有空闲对象可用的span:
//...
;
我们看到,CentralFreeList 使用 size_class_ 来对应 SizeMap 中的每一个 SizeClass。并使用 nonempty_ 来存储所有可用的 span。其架构如下图所示:
那么这些 CentralFreeList 在哪里被管理呢?答案就是 TransferCacheManager。
// https://github.com/google/tcmalloc/blob/master/tcmalloc/transfer_cache.h
class TransferCacheManager : public StaticForwarder
//...
private:
CentralFreeList freelist_[kNumClasses];
//...
;
TransferCacheManager 中维护了一个 freelist_ 数组,其每一个下标即对应着每个 SizeClass 的 CentralFreeList。
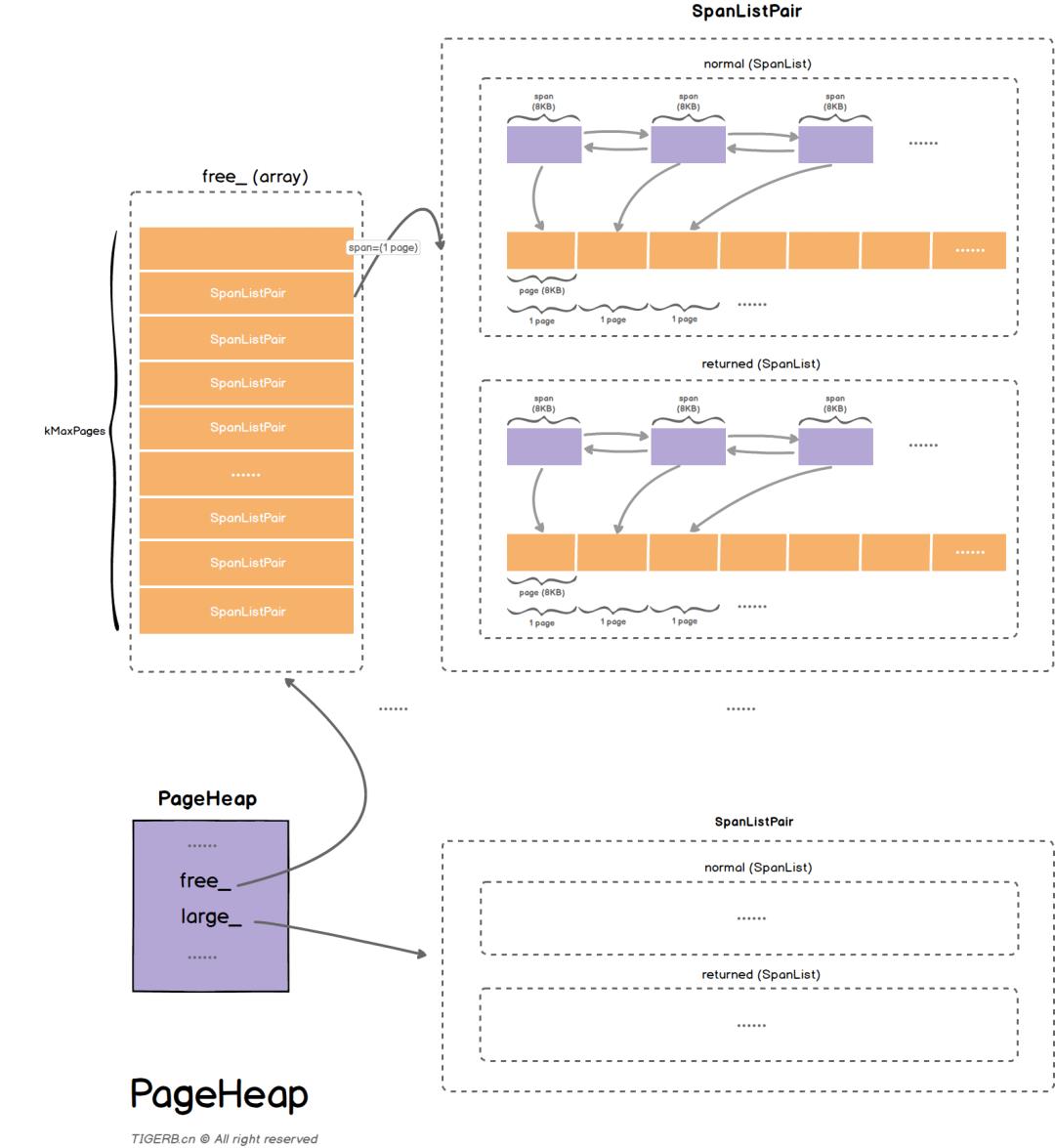
PageHeap
前面介绍的 ThreadCache 与 CentralFreeList 都是缓存,那么实际的内存是在哪里进行获取与管理的呢?这就需要提到 PageHeap 了。
当 CentralFreeList 中的空闲对象不够用时,CentralCache 会向 PageHeap 申请一块内存(可能来自PageHeap的缓存,也可能向系统申请新的内存),并将其拆分成一系列空闲对象,添加到对应 size class 的 CentralFreeList中。
PageHeap 主要负责管理从操作系统获取的不同规格的 Span,相同规格(持有相同 Page 数目)的 Span 会构成 SpanList。
https://github.com/google/tcmalloc/blob/master/tcmalloc/page_heap.h
class PageHeap final : public PageAllocatorInterface
//...
private:
struct SpanListPair
SpanList normal; //正常的spanlist
SpanList returned; //物理内存已经回收 但是虚拟内存还被持有
;
// 存储大对象
SpanListPair large_ ABSL_GUARDED_BY(pageheap_lock);
// 存储小对象
SpanListPair free_[kMaxPages.raw_num()] ABSL_GUARDED_BY(pageheap_lock);
//...
PageHeap 通过 SpanListPair 维护两种 SpanList,一种是普通的 SpanList,一种是物理内存已经回收,但是虚拟内存还被持有的 SpanList(其虚拟内存地址依然是可访问的,只是对这些内存的修改丢失了而已,在下一次访问时会通过请求分页机制重新分配物理内存)。
其中小对象的获取访问 free_,大对象(length >= kMaxPages)的获取访问 large_。
执行流程
我们把 TCMalloc 中分配的对象分为两类:
- 小块内存(<= 256 KB)
- 大块内存(> 256 KB)
其中小块内存的分配与释放由 ThreadCache、管理,而大块内存由 PageHeap 管理。
内存分配
首先根据分配的 size,判断是给小对象分配内存还是给大对象分配内存。
小块内存分配
-
将要分配的内存大小映射到对应的 size_class_ 。
-
查看 ThreadCache 中该 size_class_ 对应的 FreeList 是否为空。
-
如果不为空,则直接分配后返回。
-
如果为空,则尝试去 CentralFreeList 中为 ThreadCache 填充对象。
-
-
根据对应的 size_class_,在 TransferCacheManager 中找到对应的 CentralFreeList。
-
判断 CentralFreeList 是否为空
- 如果不为空,此时在 CentralFreeList 中为 ThreadCache 申请 batch_size 个对象,其中一个用于分配,另外的缓存到 ThreadCache 中,完成后返回。
- 如果为空,则需要去 PageHeap 中根据对应的 size_class_ 申请 Span。
-
在 PageHeap 中获取需要的 Span。
- PageHeap 先从对应 npages 的 Span 链表里面查找空闲的 Span(优先查 normal 链、然后 returned链 ),有则直接返回。
- 如果没有,则在更大的 npages 的 Span 里面查找空闲的 Span,有则将其拆小,并返回所需要的span。
- 如果空间还是不够,此时需要向操作系统申请空间,返回所需要的 Span,其他的 Span 放回 PageHeap;
-
此时 CentralFreeList 从 PageHeap 中申请到需要的 Span,并将 Span 拆分为 N 个 object,然后返回前面所需要的object。
大块内存分配
直接向 PageHeap 去申请一个刚好大于等于请求 size 的 Span。接下来的步骤与小对象分配一致。
内存释放
首先根据内存的首地址在 PageHeap 维护的映射关系中,找到对应 Span 的 size_class_。判断是大块内存还是小内存。
小块内存释放
-
首先将内存释放到 CentralFreeList 中,判断 CentralFreeList 是否超出容量。
- 容量未超,返回。
- 容量超出,触发 ThreadCache 到 CentralFreeList 的回收流程。
-
此时根据 size_class_ 查询 TransferCacheManager,找到对应的 CentralFreeList。
-
此时将 Object 回收到 CentralFreeList 中对应的 Span 中。此时判断 Span 中的 Object 是否全部回收:
- Span 回收未满,返回。
- Span 回收已满,此时触发 CentralFreeList 到 PageHeap 的回收流程。
-
在 PageHeap 中回收 Span:
-
在 radix tree 中找到 Span 之前和这后的 Span,如果它们空闲且也在 normal 上,则进行合并。
-
PageHeap 将多余的 Span 回收到其对应的 returned 上,然后继续考虑 Span 之间的合并(要求 Span 都在 returned 上)。
-
大块内存释放
对应的直接就是一个 Span,直接将其释放回 PageHeap 即可。
内存回收
每一个层次在空闲量达到一定阈值的时候,会向下做一次释放。
ThreadCache 到 CentralFreeList
ThreadCache 在以下两种情况会触发回收:
- FreeList 长度超过限额。
- ThreadCache 容量超过限额。
考虑到应用程序的多样性,这两个限额不能是定死的,所以它们都是自适应的。
对于单个 ThreadCache 的限额
其首先为每一个 ThreadCache 初始化一个比较小的限额,然后每当 ThreadCache 由于 cache 超限而触发 Object 到 CentralFreeList 的回收时,就增大该 ThreadCache 的限额。
有限额增大,就应该有限额回收。TCMalloc 预设了一个所有 ThreadCache 的总容量,当 ThreadCache 需要增大容量时,如果总容量尚有余额,则使用这些余额。否则需要增大的容量就从其他线程的 ThreadCache 里面去收刮(轮询)。
当到达 ThreadCache 的容量限额时,会对它下面的每一个 FreeList 进行回收,回收的数目是该 Freelist.lowator_的一半。(lowator_ 为该 Freelist 在 ThreadCache 超限的两次回收周期之间内,FreeList 的最小长度)
对于单个 FreeList 的限额
采用慢启动策略,每个 FreeList 初始时长度限额为 1。在限额为 1~batch_size 之间时,为慢启动状态。此时的 alloc 会给限额加 1。如果限额增加达到 batch_size,则慢启动状态结束。此时,限额会按 batch_size 的整数倍进行扩展。而如果 free 超限,则限额将按照 batch_size 的整数倍进行缩减。
FreeList 的回收机制十分简单,直接回收 batch_size 个 Object 即可(不足 batch_size 个,则有多少回收多少)。 可见,处于慢启动状态下的 FreeList 限额超限,将导致 FreeList 被清空。
CentralFreeList 到 PageHeap
只要一个 Span 里面的 Object 都空闲了,就将它回收到 PageHeap。
PageHeap 中的 normal 到 returned
每当 PageHeap 回收到 N 个 Page 的 Span 时,触发一次 normal 到 returned 的回收,只回收一个 Span。
这个 N 值初始化为 1G 内存的 Page 数,每次回收 Span 到 returned 之后,可能还会增加 N 值,但是最大不超过 4G。
触发回收的过程也比较简单,每次进来轮询伙伴系统中的一个 normal 链表,将链尾的 Span 回收即可。
这里面没有判断 normal 链是否应该被回收,如果回收了不该回收的 Span,后续的分配过程会把 Span 从returned 链里面捞回来。否则 span 将长期呆在 returned 链里面。
参考内容
- http://goog-perftools.sourceforge.net/doc/tcmalloc.html
- https://www.jianshu.com/p/11082b443ddf
- https://mp.weixin.qq.com/s/8sWt9bML8KkmF_6FD0J5FQ
- https://github.com/google/tcmalloc/blob/master/docs/design.md
- https://developer.aliyun.com/article/6045
以上是关于新时代内存分配器:TCMalloc的主要内容,如果未能解决你的问题,请参考以下文章