大数据之Spark:Spark SQL
Posted 浊酒南街
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据之Spark:Spark SQL相关的知识,希望对你有一定的参考价值。
目录
1. 数据分析方式
1) 命令式
在前面的 RDD 部分, 非常明显可以感觉的到是命令式的, 主要特征是通过一个算子, 可以得到一个结果, 通过结果再进行后续计算。
sc.textFile("...")
.flatMap(_.split(" "))
.map((_, 1))
.reduceByKey(_ + _)
.collect()
| 优点 | 缺点 |
|---|---|
| 1、操作粒度更细,能够控制数据的每一个处理环节 ; | 1、需要一定的代码功底; |
| 2、操作更明确,步骤更清晰,容易维护; | 2、写起来比较麻烦; |
| 3、支持半/非结构化数据的操作。 |
2) SQL
对于一些数据科学家/数据库管理员/DBA, 要求他们为了做一个非常简单的查询, 写一大堆代码, 明显是一件非常残忍的事情, 所以 SQL on Hadoop 是一个非常重要的方向。
SELECT
name,
age,
school
FROM students
WHERE age > 10
| 优点 | 缺点 |
|---|---|
| 1、表达非常清晰,简短 | 1、多层嵌套的 SQL 维护起来比较麻烦 |
| 2、SQL 来实现机器学习算法挺难 |
3) 总结
SQL 擅长数据分析和通过简单的语法表示查询,命令式操作适合过程式处理和算法性的处理。
在 Spark 出现之前,对于结构化数据的查询和处理, 一个工具一向只能支持 SQL 或者命令式,使用者被迫要使用多个工具来适应两种场景,并且多个工具配合起来比较费劲。
而 Spark 出现了以后,统一了两种数据处理范式是一种革新性的进步。
2. SparkSQL 前世今生
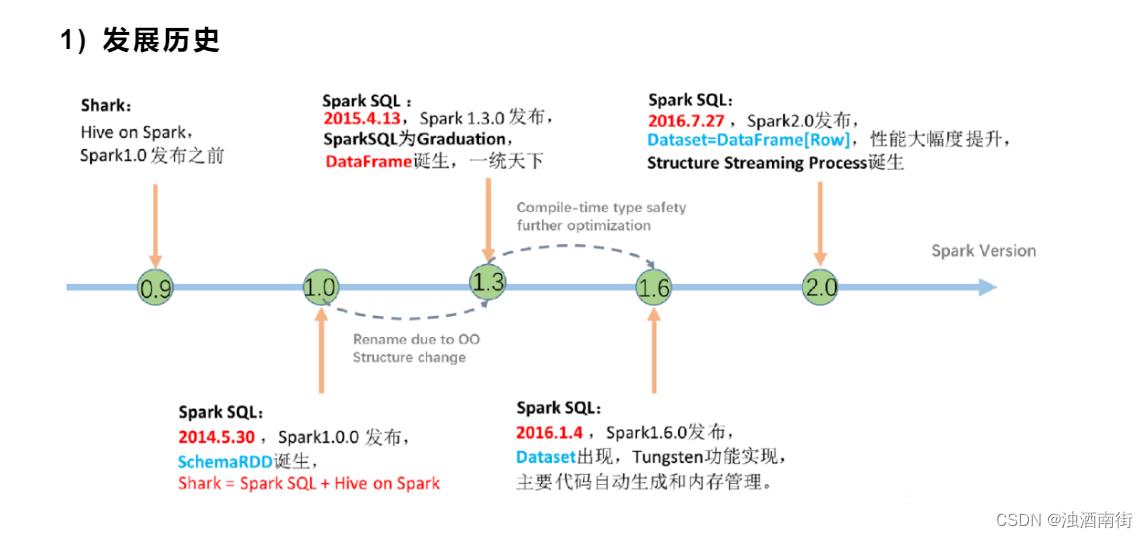
1) 发展历史
SQL 是数据分析领域一个非常重要的范式,所以 Spark 一直想要支持这种范式,而伴随着一些决策失误,这个过程其实还是非常曲折的。
| 问题 | HIVE | SHARK | SparkSQL-DataFrame | SparkSQL-Dataset |
|---|---|---|---|---|
| 解决的问题 | Hive 实现了 SQL on Hadoop,使用 MapReduce 执行任务 简化了 MapReduce 任务 | Shark 改写 Hive 的物理执行计划, 使用 Spark 代替 MapReduce 物理引擎 使用列式内存存储,查询效率高 | Spark SQL 执行计划和优化交给优化器 Catalyst;内建了一套简单的 SQL 解析器,可以不使用 HQL;还引入和 DataFrame 这样的 DSL API,完全可以不依赖任何 Hive 的组件 | SparkSQL 在 1.6 时代,增加了一个新的 API,叫做 Dataset,Dataset 统一和结合了 SQL 的访问和命令式 API 的使用,在 Dataset 中可以轻易的做到使用 SQL 查询并且筛选数据,然后使用命令式 API 进行探索式分析。 |
| 新的问题 | 使用 MapReduce 做计算,Hive 的查询延迟比较高 | Shark 执行计划的生成严重依赖 Hive,优化非常困难;Hive 是进程级别的并行,Spark 是线程级别的并行,所以 Hive 中很多线程不安全的代码不适用于 Spark | 对于初期版本的 SparkSQL,只能支持 SQL 的使用,不能很好的兼容命令式,入口不够统一等。 |
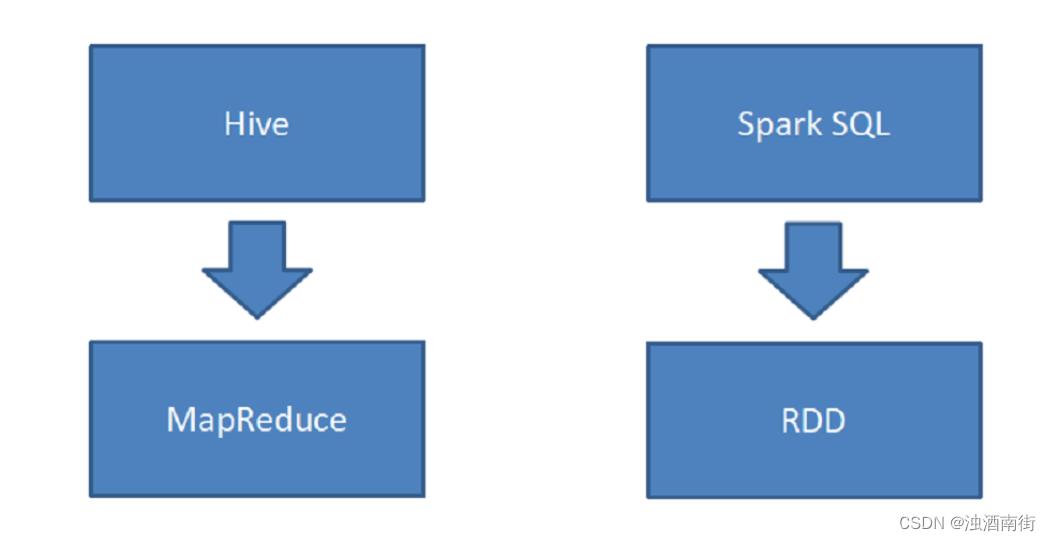
3. Hive 和 SparkSQL
Hive 是将 SQL 转为 MapReduce。
SparkSQL 可以理解成是将 SQL 解析成:“RDD + 优化” 再执行。
4. 数据分类和 SparkSQL 适用场景
1) 结构化数据
一般指数据有固定的 Schema(约束),例如在用户表中,name 字段是 String 型,那么每一条数据的 name 字段值都可以当作 String 来使用:

2) 半结构化数据
一般指的是数据没有固定的 Schema,但是数据本身是有结构的。
没有固定 Schema
指的是半结构化数据是没有固定的 Schema 的,可以理解为没有显式指定 Schema。
比如说一个用户信息的 JSON 文件,
第 1 条数据的 phone_num 有可能是数字,
第 2 条数据的 phone_num 虽说应该也是数字,但是如果指定为 String,也是可以的,
因为没有指定 Schema,没有显式的强制的约束。
有结构
虽说半结构化数据是没有显式指定 Schema 的,也没有约束,但是半结构化数据本身是有有隐式的结构的,也就是数据自身可以描述自身。
例如 JSON 文件,其中的某一条数据是有字段这个概念的,每个字段也有类型的概念,所以说 JSON 是可以描述自身的,也就是数据本身携带有元信息。
3) 总结
1、数据分类总结
| 定义 | 特点 | 举例 | |
|---|---|---|---|
| 结构化数据 | 有固定的 Schema | 有预定义的 Schema | 关系型数据库的表 |
| 半结构化数据 | 没有固定的 Schema,但是有结构 | 没有固定的 Schema,有结构信息,数据一般是自描述的 | 指一些有结构的文件格式,例如 JSON |
| 非结构化数据 | 没有固定 Schema,也没有结构 | 没有固定 Schema,也没有结构 | 指图片/音频之类的格式 |
2、Spark 处理什么样的数据?
RDD 主要用于处理非结构化数据 、半结构化数据、结构化;
SparkSQL 主要用于处理结构化数据(较为规范的半结构化数据也可以处理)。
3、总结:
SparkSQL 是一个既支持 SQL 又支持命令式数据处理的工具;
SparkSQL 的主要适用场景是处理结构化数据(较为规范的半结构化数据也可以处理)。
以上是关于大数据之Spark:Spark SQL的主要内容,如果未能解决你的问题,请参考以下文章