索引下推如何进行数据过滤
Posted 老叶茶馆_
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了索引下推如何进行数据过滤相关的知识,希望对你有一定的参考价值。
* GreatSQL社区原创内容未经授权不得随意使用,转载请联系小编并注明来源。
实验环境
GreatSQL 8.0.25-15, InnoDB表
1.索引下推介绍
1.索引下推,英文全称(Index Condition Pushdown)简称 ICP 。
2.mysql5.6 版本推出的用于优化查询的功能。
3.某些特定索引条件下,ICP 可减少存储引擎查询回表的次数。
2.适用条件
1.当需要访问全表记录时,ICP 用于 range、ref、eq_ref 和 ref_or_null 访问方法。
2.ICP 可以用于 InnoDB 和 MyISAM 表,包括分区 InnoDB 和 MyISAM 表。
3.对于InnoDB表,ICP 仅用于二级索引。ICP 的目标是减少整行记录读取的次数,从而减少I/O操作。对于InnoDB 聚集索引,完整的记录已经被读取到 InnoDB 缓冲区,在这种情况下使用 ICP 就不会减少I/O。
4.虚拟列上创建的二级索引,不支持 ICP。
5.使用子查询的SQL 不支持 ICP。
6.调用存储过程的SQL 不支持 ICP,因为存储引擎无法调用位于 MySQL Server 层中的存储过程。
7.触发器 不支持 ICP。
3.如何启用
ICP 默认是开启的,可以通过下列命令进行关闭、启用、查看
# 关闭ICP
SET optimizer_switch = 'index_condition_pushdown=off';
# 开启ICP
SET optimizer_switch = 'index_condition_pushdown=on';
# 查看ICP当前状态
show VARIABLES like '%optimizer_switch%'4.ICP 如何工作
不使用 ICP 优化时的查询步骤
1.获取下一行,首先读取索引信息,然后根据索引将整行数据读取出来。
2.然后通过where条件判断当前数据是否符合条件,符合返回数据。
使用 ICP 优化时的查询步骤
1.获取下一行的索引信息。
2.检查索引中存储的列信息是否符合索引条件,如果符合将整行数据读取出来,如果不符合跳过读取下一行。
3.用剩余的判断条件,判断此行数据是否符合要求,符合要求返回数据
5.实验测试
表结构如下
CREATE TABLE `student` (
`id` int NOT NULL AUTO_INCREMENT COMMENT '自增id',
`uid` int NOT NULL COMMENT '学号',
`age` int NOT NULL COMMENT '年龄',
`name` char(32) NOT NULL COMMENT '姓名',
`sex` char(4) NOT NULL COMMENT '性别',
`grade` int NOT NULL COMMENT '年级',
`class` varchar(32) NOT NULL COMMENT '班级',
`major` varchar(64) NOT NULL COMMENT '专业',
PRIMARY KEY (`id`),
KEY `idx_anm` (`age`,`name`,`major`)
) ENGINE=InnoDB AUTO_INCREMENT=4 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci现有一个需求,查询年龄16、姓陈、学习软件工程的同学信息
# 启用ICP
[root@GreatSQL][test]>explain select * from student where age=16 and name like '陈%' and major='软件工程';
+----+-------------+---------+------------+-------+---------------+---------+---------+------+------+----------+-----------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+-------+---------------+---------+---------+------+------+----------+-----------------------+
| 1 | SIMPLE | student | NULL | range | idx_anm | idx_anm | 390 | NULL | 1 | 33.33 | Using index condition |
+----+-------------+---------+------------+-------+---------------+---------+---------+------+------+----------+-----------------------+
1 row in set, 1 warning (0.00 sec)
# 不启用ICP
[root@GreatSQL][test]>explain select /*+ no_icp (student) */ * from student where age=16 and name like '陈%' and major='软件工程';
+----+-------------+---------+------------+-------+---------------+---------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+-------+---------------+---------+---------+------+------+----------+-------------+
| 1 | SIMPLE | student | NULL | range | idx_anm | idx_anm | 390 | NULL | 1 | 33.33 | Using where |
+----+-------------+---------+------------+-------+---------------+---------+---------+------+------+----------+-------------+
1 row in set, 1 warning (0.00 sec)启用 ICP 解析出来的 Extra 是 Using index condition ,不启用 ICP 解析出来的 Extra 是 Using where
其他查询结果基本一样,看不出有效率差别,可以通过开启profiling进行查看
[root@GreatSQL][test]>set profiling=1;
Query OK, 0 rows affected, 1 warning (0.00 sec)
[root@GreatSQL][test]>select * from student where age=16 and name like '陈%' and major='软件工程';
+----+--------+-----+--------+-----+-------+-------+--------------+
| id | uid | age | name | sex | grade | class | major |
+----+--------+-----+--------+-----+-------+-------+--------------+
| 1 | 100001 | 16 | 陈红 | 男 | 4 | 3 | 软件工程 |
+----+--------+-----+--------+-----+-------+-------+--------------+
1 row in set (0.00 sec)
(Tue Jan 4 15:51:50 2022)[root@GreatSQL][test]>select /*+ no_icp (student) */ * from student where age=16 and name like '陈%' and major='软件工程';
+----+--------+-----+--------+-----+-------+-------+--------------+
| id | uid | age | name | sex | grade | class | major |
+----+--------+-----+--------+-----+-------+-------+--------------+
| 1 | 100001 | 16 | 陈红 | 男 | 4 | 3 | 软件工程 |
+----+--------+-----+--------+-----+-------+-------+--------------+
1 row in set (0.00 sec)
[root@GreatSQL][test]>show profiles\\G;
*************************** 1. row ***************************
Query_ID: 1
Duration: 0.00043725
Query: select * from student where age=16 and name like '陈%' and major='软件工程'
*************************** 2. row ***************************
Query_ID: 2
Duration: 0.00048500
Query: select /*+ no_icp (student) */ * from student where age=16 and name like '陈%' and major='软件工程'
2 rows in set, 1 warning (0.00 sec)
ERROR:
No query specified使用了 ICP 的 Duration 要比没有使用的时间稍短一些,多次测试效率对比结果都一样,从测试来看,使用 ICP 优化的查询效率会好一些。
6.查询流程
没有开启 ICP
1.根据最左原则先找到 age=16 的记录。
2.然后找出所有符合like '陈%'的行记录,回表再根据步骤1查出来的数据,根据主键过滤符合条件的记录
3.然后找出所有符合 major='软件工程' 再根据步骤2查出所有符合条件的记录
4.步骤1查询过程,每个符合 age=16 的记录都要先进行回表操作。
开启 ICP
1.根据最左原则先找到 age=16 的记录。
2.查看索引过滤掉不符合 like '陈%' 的数据
3.查看索引过滤掉不符合 major='软件工程' 的数据
4.步骤1查询过程,先不进行回表操作,先通过索引找出符合2、3条件的情况,如何不符合则直接进行下一个步骤查询,故回表次数会少一些。
7.ICP 图解
插图来源 mariadb.com ,仅做笔记分享,非商业用途。
图1:没有启用ICP查询过程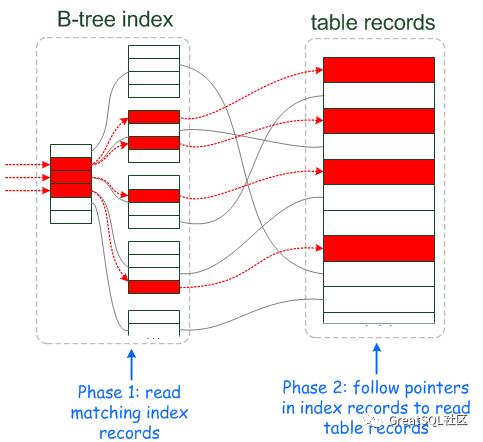
图2:启用ICP查询过程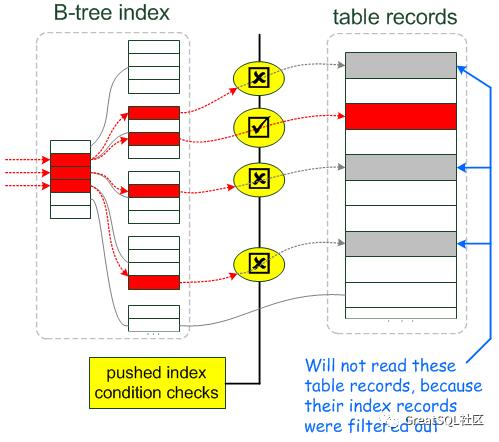
说明:图2的几个X是由于在索引层就进行数据过滤了,故不需要再进行回表。
8.更多内容查看官网
https://dev.mysql.com/doc/refman/8.0/en/index-condition-pushdown-optimization.html
Enjoy GreatSQL :)
《深入浅出MGR》视频课程
戳此小程序即可直达B站
https://www.bilibili.com/medialist/play/1363850082?business=space_collection&business_id=343928&desc=0
文章推荐:
想看更多技术好文,点个“在看”吧!
以上是关于索引下推如何进行数据过滤的主要内容,如果未能解决你的问题,请参考以下文章