Java类加载机制
Posted 364.99°
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Java类加载机制相关的知识,希望对你有一定的参考价值。
1.java源文件的运行过程
.java一步步转化成系统可执行的机器码的过程如下:

- .java 源文件 通过
javac编译成 .class 文件(字节码) - jvm 加载字节码,首先会逐条读取 IR(即时编译器的中间表达形式) 的指令来执行,这个过程就是解释执行的过程
- jvm 中的解释器(java.exe)将 .class 解释成一段段的 机器码 在计算机上运行
- 当某一方法调用次数达到即时编译定义的阈值时,就会触发即时编译
- jit 即时编译器,会将IR进行优化,并生成这个方法的机器码,后面再调用这个方法,就会直接调用机器码执行
具体流程:
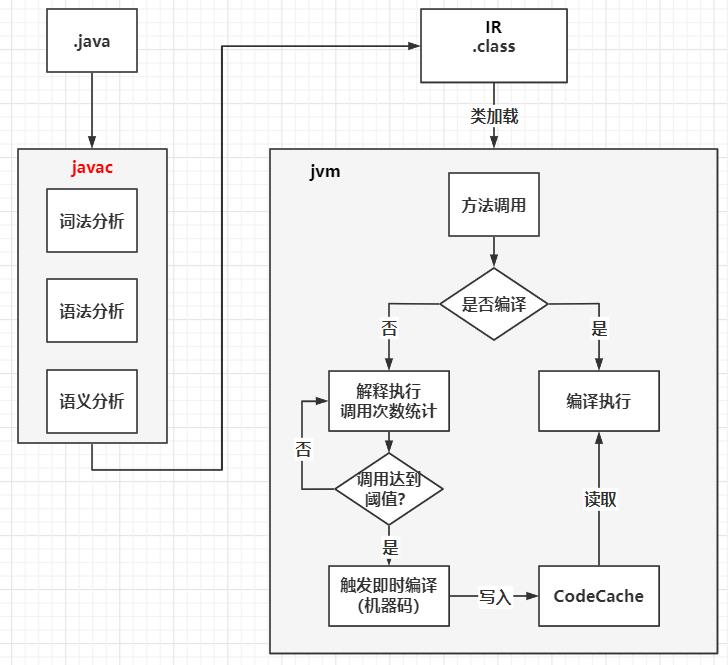
补充:
- 将字节码编译成机器码可以获得更高的执行效率
- 运行java程序时,解释器和编译器相互配合使得java程序几乎可以达到和编译性语言一样的执行速度
编译性语言: 只须编译一次就可以把源代码编译成机器语言,后面的执行无须重新编译,直接使用之前的编译结果就可以;因此其执行的效率比较高;但比较依赖编译器,因此跨平台性差一些。
解释性语言: 源代码不能直接翻译成机器语言,而是先翻译成中间代码,再由解释器对中间代码进行解释运行。运行效率一般相对比较低,依赖解释器,但跨平台性好。
通俗理解:
- 编译性相当于一下子把整篇外文文献翻译成中文,然后给我们写毕业论文的同学去读,这样读起来就很快。
- 解释性相当于我们一边一段一段地百度翻译英文文献,一边阅读,这样读起来就更慢。
java是哪种类型?
java具有两者的共性——解释器(java.exe)、即时编译器(jit)
2.java类的生命周期
java类的生命周期如下:
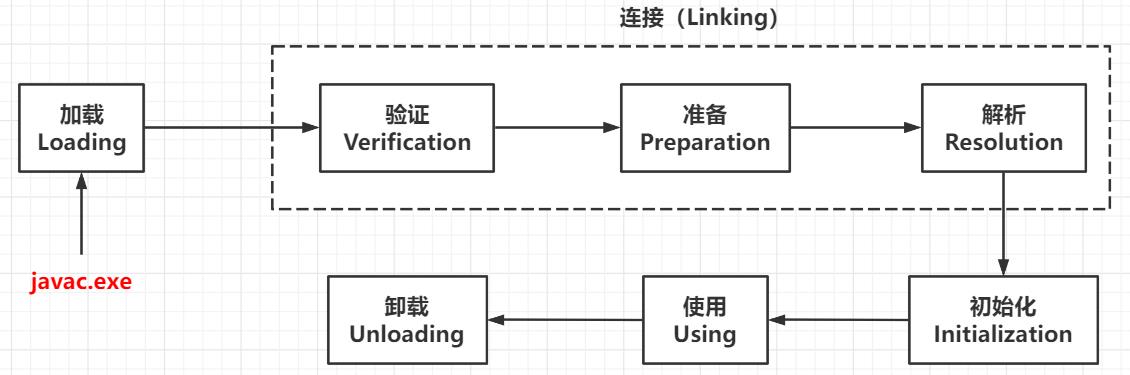
其中,只有 加载阶段的读取二进制流 的部分 和 初始化阶段 是由用户进行主导的,而其他阶段都是由jvm来掌控的。其中的细节全由 jvm开发人员处理 ,对于外部开发人员来说是个黑盒。
以上设计是一种符合 面向对象的封装思想 的设计,将内部复杂的实现封装,拒绝外部非修改,只提供了一个拓展接口以供外界的读取。
- 类加载过程: 加载、连接、初始化
- 加载: 类加载的第一个环节
- 解析部分: 它是一个比较灵活的流程,可以在初始化环节之前执行、也可以在初始化之后再执行(后期绑定)
1.Loading
Loading: 读取 .class ,并将其转化为某种 静态数据结构 存储在 方法区 内,并在堆中生成一个便于用户调用的 java.lang.Class 类型的对象 的过程。
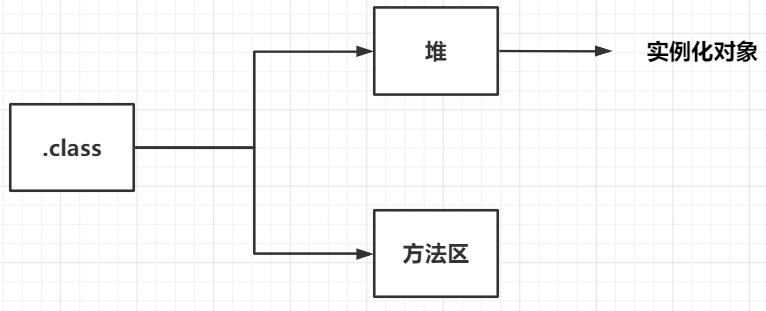
.class 文件是:各种来源的二进制流,并不一定是本地的字节码文件,也可以是来源于网络、数据库或者即时生成的字节码文件。
2.Verification
Verification: 分为以下三个步骤
- 文件格式验证: 发生在加载阶段,只有当源文件通过验证才能顺利加载
顺利加载之后,方法区中就有了该 class的静态结构 ,堆中也存在了 该class类型的对象 ,但是这时候jvm并没有完全认可这个类
想要让程序使用这个类,就必须进行连接。连接的第一步:进一步对这个类进行验证,即元数据,字节码的验证 - 元数据、字节码的验证: 对 class静态结构 进行语法和语义上的分析,保证其符合 jvm规范
经过上述两步验证,这时候的 jvm 已经基本认可了这个类,但是这并不意味着验证已经结束,还需要对其的符号引用进行验证 - 符号引用验证: 发生在 解析阶段
3.Preparation
Preparation: 为该类型中定义的 静态变量 赋0值
注意: 在 jdk1.8 前后,类的信息存储位置不同
- jdk1.8之前 类的元信息、常量池、静态变量等 类的静态结构 都存在永久代这种具体实现之中
- 而在jdk1.8之后,类的元信息存在元空间等具体实现中,而常量池和静态变量则存在了堆中
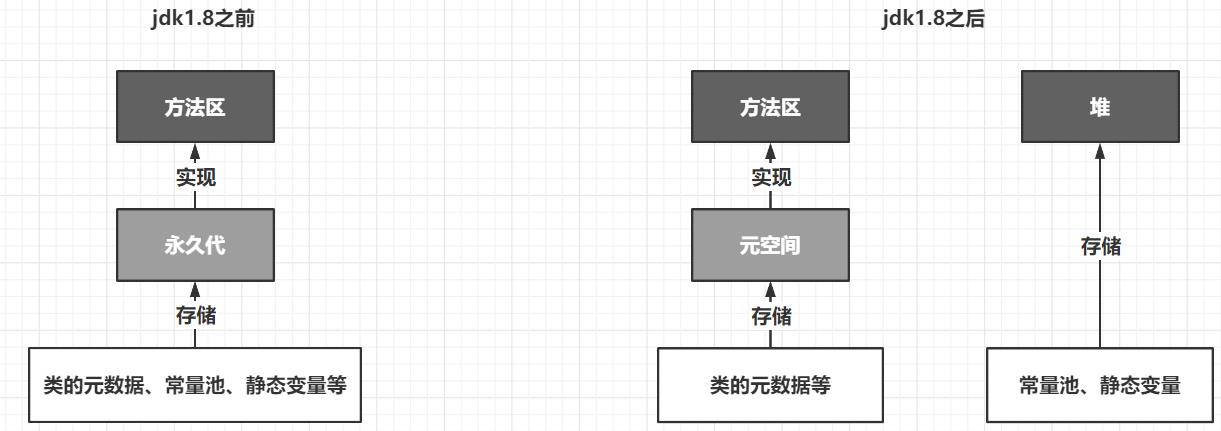
补充: - 方法区是抽象概念,元空间是具体实现
- 所谓的元数据是指用来描述数据的数据,更通俗一点就是描述代码间关系,或者代码与其它资源(例如数据库表)之间内在联系得数据
4.Resolution
Resolution: 主要是将 符号引用 替换为 直接引用。
当一个 java类A(A中引用了类B) 被编译成 字节码 文件之后,那么在编译阶段,A并不知道B是否被编译,且此时B一定没有被加载,所以A就不知道B的实际地址。
这时候的A该如何找到B呢?
- 在此时的A.class中,将使用一个字符串S来代表B的地址,这个S就被叫做 符号引用
- 在运行时,如果这个A被加载了,到了解析阶段就会发现B还未被加载,这时就会触发B的类加载,将B加载到虚拟机中,此时A中关于B的符号引用将会被替换成B的 实际地址 ,这就被称为 直接引用
- 至此,A就能真正地调用B了
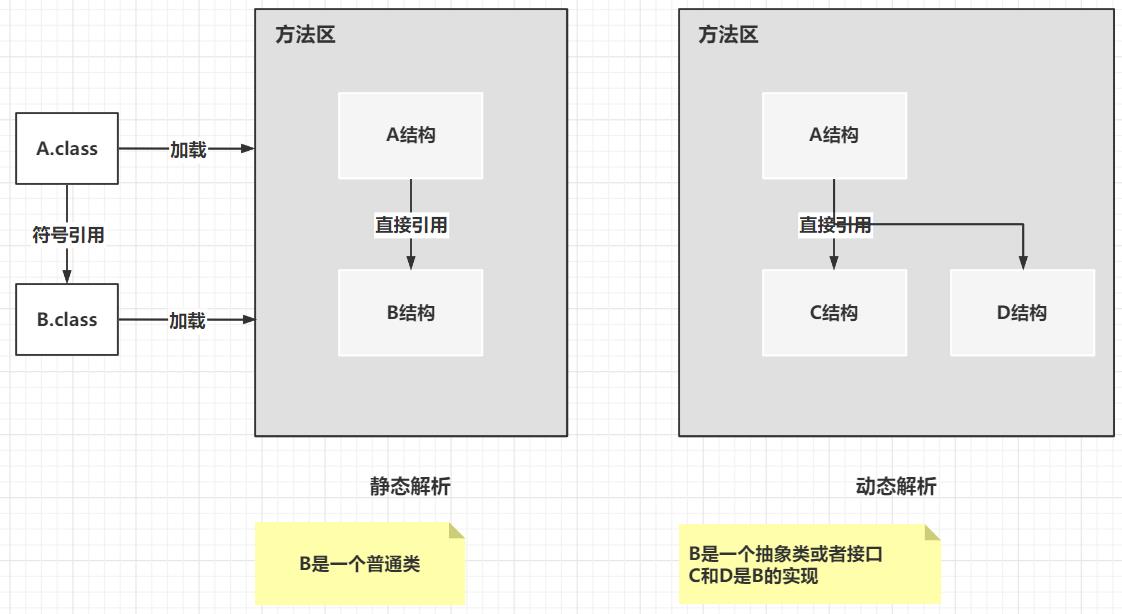
补充:
java通过后期绑定(初始化后解析)来实现多态。
静态解析: A调用的是一个具体的实现类(解析的目标类很明确),那么就叫做静态解析
动态解析: A调用B,B是一个接口或者抽象类,那么B的实现就不明确,A并不知道该调用哪个类直接引用来替换符号引用。而这个时候就只有等着程序运行过程中进行了调用,这是 jvm 调用栈中将会得到B具体的类型信息 ,这时候再进行解析,就能使用明确地 符号引用 来替换 直接引用。
这也就是,解析 为什么会发生在初始化阶段之后的原因。这就是动态解析,用来实现后期绑定。
其底层对应了invokeVirtual这条字节码指令
至此,外部加载的java类已经成功地引入到程序中
5.Initialization
Initialization: 此时会判断代码中是否存在主动的资源初始化操作,如果有就执行。
这些操作指代的是类层面的操作:成员变量、静态变量的赋值操作,以及静态代码块的逻辑等。
而不是对象层面的操作。
3.类加载器
类加载器: 属于一种 jvm的规范 ,是一种抽象的概念。
- 类加载启动器
- 非类加载启动器

- Extension ClassLoader: 主要用来加载 <JAVA_HOME>/lib/ext 或者由系统变量指定的路径中的类库。
希望加载的是 javaAPI 的拓展,是对 java类库 的一些补充。 - Application ClassLoader: 主要用来加载 classpath/java.class.path ,即环境变量classpath,或者系统属性指定下的类库。
希望加载的是上层程序员编写的一些代码,以及一些第三方的类库(即,我们编写的代码几乎都是这个加载的)。 - User ClassLoader: 用户自定义的类加载器。
这也就提供了程序员自定义一个类加载器的方案,然后就可以获取任意来源的二进制字节流,当然,这些流要符合java虚拟机规范才能被加载。
实现大概方案:继承java.lang.ClassLoader → 单独实现获取二进制流的逻辑 → 后续都交由 java.lang.ClassLoader 的内置逻辑来处理(用户无权干涉)
那么,对于不同的类加载器,除了二进制流的动作和范围不一样,后续的加载逻辑是否也不一样?
遇到了限定名一样的类,那么多类加载器会不会产生混乱?
jvm规范:每个类加载器都有属于自己的命名空间
即使使用了不同的加载器加载了同一个限定名的类,jvm也会认为这是不同的类。
1.双亲委派
目的: 默认情况下,一个限定名的类只会被一个类加载器加载并解析使用,这样在程序中,它就是唯一的,不会产生歧义。
双亲委派模型:
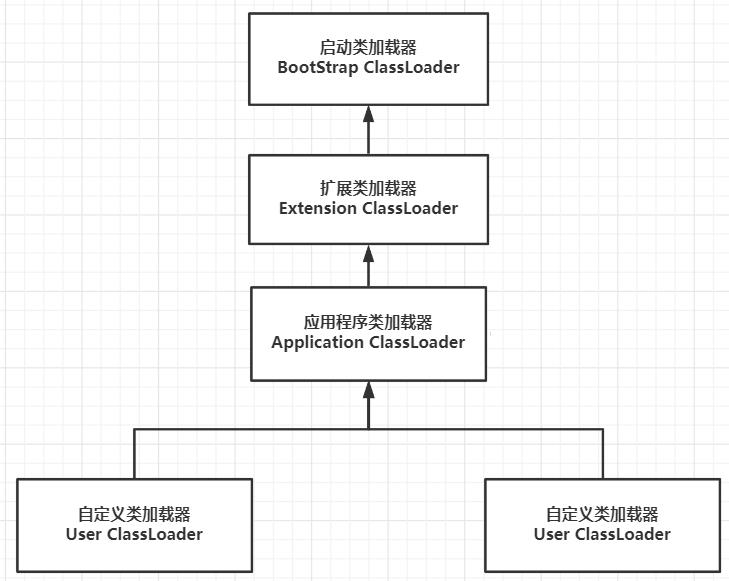
图解:上述箭头并不表示继承关系,而是一种组合关系
- 在被动的情况下,当一个类加载器收到了加载请求,它不会自己先去加载,而是传递给父加载器去加载,这样类都会被上传给最顶层的 BootStrap ClassLoader ,只有父加载器不能完成加载,才会传给子加载器去加载
- 无法加载:根据类的限定民,类加载器没有在自己负责的加载路径中找到该类
protected Class<?> loadClass(String name, boolean resolve)
throws ClassNotFoundException
synchronized (getClassLoadingLock(name))
// First, check if the class has already been loaded
//检查该类是否已经被类加载
Class<?> c = findLoadedClass(name);
if (c == null)
long t0 = System.nanoTime();
try
//有上级的话,就委托上级去进行加载,递归方式去加载
if (parent != null)
c = parent.loadClass(name, false);
else
//parent == null,则委派BootstrapClassload加载
c = findBootstrapClassOrNull(name);
catch (ClassNotFoundException e)
// ClassNotFoundException thrown if class not found
// from the non-null parent class loader
if (c == null)
// If still not found, then invoke findClass in order
// to find the class.
//说明parent(BootStrap ClassLoader)加载不了,当前loader尝试findclass
long t1 = System.nanoTime();
c = findClass(name);
// this is the defining class loader; record the stats
//记录耗时
sun.misc.PerfCounter.getParentDelegationTime().addTime(t1 - t0);
sun.misc.PerfCounter.getFindClassTime().addElapsedTimeFrom(t1);
sun.misc.PerfCounter.getFindClasses().increment();
if (resolve)
resolveClass(c);
return c;
findclass 表示如何去找到该限定名的class,需要各个类加载器自己去实现
那么,对于不同的类加载器,除了二进制流的动作和范围不一样,后续的加载逻辑是否也不一样?
除了 BootStrap ClassLoader ,其他的类加载器都继承了 java.lang.ClassLoader ,都由这个类的 defineClass 进行后续处理
遇到了限定名一样的类,那么多类加载器会不会产生混乱?
越核心的类库就被越顶层的类加载器加载,而某限定名的类一旦被加载过,被动情况下,就不会再加载相同限定名的类。这样能有效避免混乱。
当然,java的双亲委派是可以被破坏的,虽然jvm规范要求别去破坏。
可以看看 https://blog.csdn.net/m0_37556444/article/details/81912283、https://zhuanlan.zhihu.com/p/257122662
请问:能不能自己写一个限定名为 java.lang.String 的类,并在程序中调用它?
https://blog.csdn.net/liubenlong007/article/details/88574544
不可以加载自定义的java.开头的任何类
因为JDK已经在loadClass方法中帮我们实现了ClassLoader搜索类的算法,当在loadClass方法中搜索不到类时,loadClass方法就会调用findClass方法来搜索类,所以我们只需重写该方法即可。如没有特殊的要求,一般不建议重写loadClass搜索类的算法。
如果想打破双亲委派模型,那么就重写整个loadClass方法
如果不想打破双亲委派模型,那么只需要重写findClass方法即可
以上是关于Java类加载机制的主要内容,如果未能解决你的问题,请参考以下文章