CUDA 优化之 PReLU 性能调优
Posted AI科技大本营
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了CUDA 优化之 PReLU 性能调优相关的知识,希望对你有一定的参考价值。

作者 | OneFlow社区
来源 | OneFlow
InsightFace模型里大量使用了PReLU激活函数,而PReLU的工作模式有两种:
1. PReLU(1),此时权重alpha的形状为(1, ),等价于一个Elementwise操作。
2. PReLU(channels),此时权重alpha的形状为(channels, ),和输入特征(N, C, H, W)中C的大小是对应的。此时PReLU等价于一个Binary Broadcast操作。
InsightFace模型里的PReLU工作模式是第二种,之前已经介绍过CUDA Elementwise操作优化,而在Broadcast情形下也存在一定的优化机会。
1
朴素实现
一个朴素实现的思想就是在循环内部,根据当前元素的索引,推算出该元素对应需要使用的alpha权重的索引。然后判断当前元素x是否大于0,若大于0则返回x,小于0则返回alpha*x。对应代码如下:
template<typename T>
__global__ void PReluForwardGpu(const int32_t elem_cnt, const int32_t alpha_size,
const int32_t inner_size, const T* x, const T* alpha, T* y)
CUDA_1D_KERNEL_LOOP(i, elem_cnt)
const T x_i = x[i];
const T alpha_i = alpha[(i / inner_size) % alpha_size];
y[i] = x_i > 0 ? x_i : x_i * alpha_i;
其中:
inner_size表示的是通道维后面维度乘积,以NCHW格式为例,inner_size=H*W
alpha_size表示通道维大小
在CUDA中,整数除法的计算代价是比较昂贵的(https://docs.nvidia.com/cuda/cuda-c-programming-guide/index.html#maximize-instruction-throughput)关于计算指令耗时这一章中有提到:
Integer division and modulo operation are costly as they compile to up to 20 instructions.
整数除法,取余操作会被编译成多达20条指令。而我们这里计算alpha的索引的时候,分别用到一次除法,一次取余,占整个Kernel的主要计算量,下面我们将用向量化的思路来提高读写带宽的同时,减少整数除法,取余的计算次数。
2
Pack向量化优化
我们考虑一个比较简单的例子,输入为(1, 2, 4, 4),对应PReLU(2)
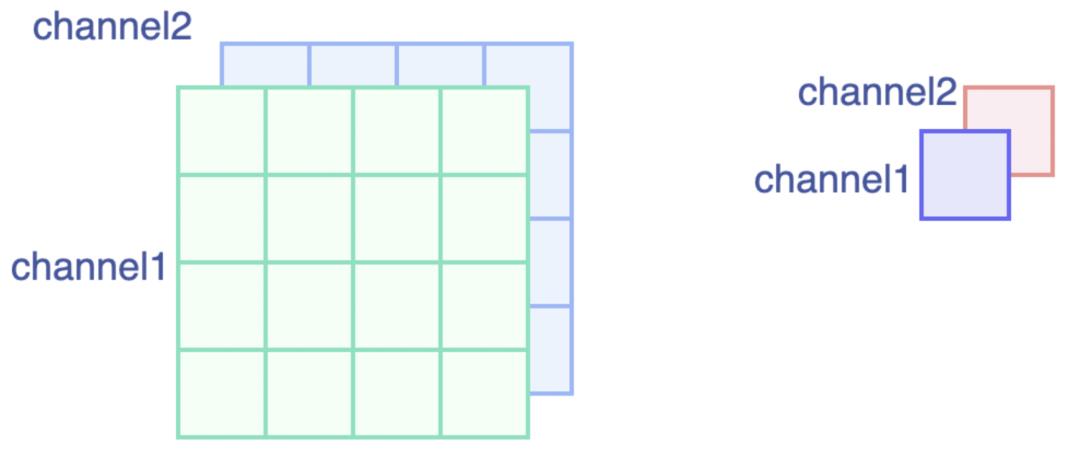
显然,输入在hw维上是连续的,在 inner_size 满足被pack整除的条件下,一个pack内的元素应用到的是同一个alpha权重**。参见下图:

这样我们就能以向量化形式去处理元素,以提升读写带宽。并且每一个pack内部只需要计算一次,向量化处理相比逐元素计算能节省不小计算量。对应代码如下:
template<typename T, typename IndexType, int pack_size>
__global__ void PReluForwardMultiAlphaGpu(const IndexType elem_cnt, const IndexType alpha_size,
const IndexType inner_size, const T* x, const T* alpha, T* y)
int32_t global_thread_id = blockIdx.x * blockDim.x + threadIdx.x;
using LoadType = cuda::elementwise::PackType<T, pack_size>;
using LoadPack = cuda::elementwise::Pack<T, pack_size>;
T zero_val = static_cast<T>(0);
for (int64_t linear_index = global_thread_id * pack_size; linear_index < elem_cnt;
linear_index += gridDim.x * blockDim.x * pack_size)
// 计算当前Pack所使用到Alpha的索引
IndexType alpha_idx = (linear_index/inner_size%alpha_size);
const LoadType* x_load = reinterpret_cast<const LoadType*>(x + linear_index);
// 以向量化的形式加载输入x
LoadPack x_vec;
x_vec.storage = *x_load;
LoadPack y_vec;
// 循环展开,逐个处理Pack内的元素
#pragma unroll
for (int i = 0; i < pack_size; i++)
y_vec.elem[i] = x_vec.elem[i] > zero_val ? x_vec.elem[i] : x_vec.elem[i] * alpha[alpha_idx];
// 以向量化的形式存储输出y
*(reinterpret_cast<LoadType*>(y + linear_index)) = y_vec.storage;
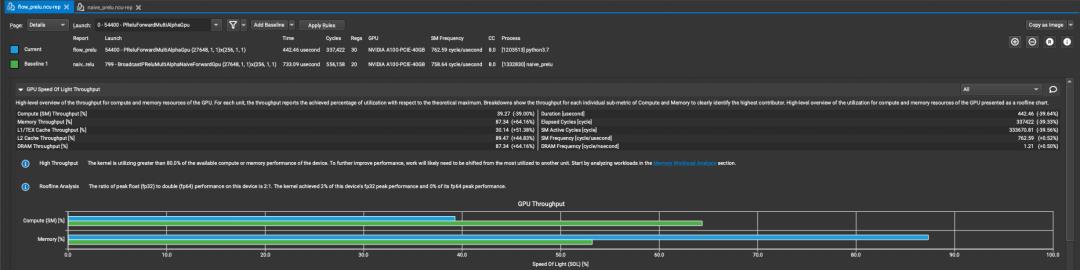
我们在Nsight Compute内简单比较下优化前后的结果,测试数据为(96, 64, 112, 112),机器为A100-40GB。蓝色一栏是使用向量化优化过的kernel,而绿色一栏是朴素实现的kernel。可以看到,经过优化后,我们计算占比降低20%-30%,吞吐提升了30+%。优化后的kernel带宽能达到1350GB/s,已经很接近A100上的理论带宽1555GB/s。
当然也不是所有形状都支持向量化操作,当inner_size无法被对应的pack_size 整除时,只能退回到朴素实现上。
3
基准测试
在A100-40GB测试机器上,我们对Insightface涉及到的Tensor形状,与PyTorch实现进行比较,测试数据如下:
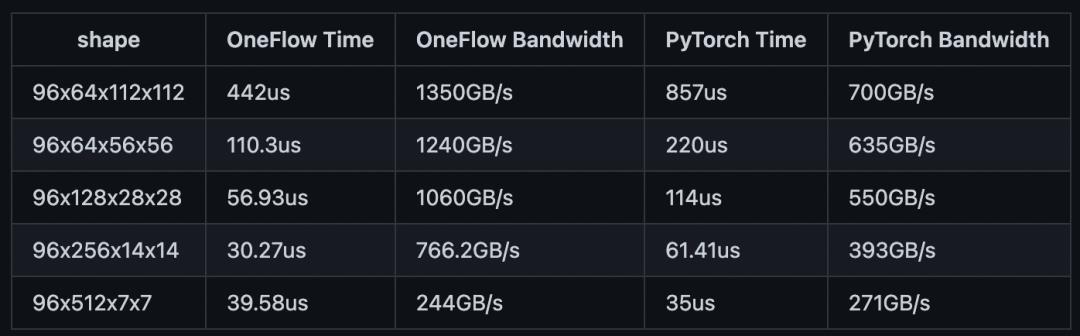
经过优化PReLU的OneFlow,在大部分情况下均有比PyTorch接近2倍的领先优势,在最后一种情况由于形状较为特殊,无法应用向量化的优化,所以表现与PyTorch持平。


往期回顾
分享
点收藏
点点赞
点在看以上是关于CUDA 优化之 PReLU 性能调优的主要内容,如果未能解决你的问题,请参考以下文章