日常Geetest滑动验证码(三代canvas版)处理小结(以B站登录验证为例)
Posted 囚生CY
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了日常Geetest滑动验证码(三代canvas版)处理小结(以B站登录验证为例)相关的知识,希望对你有一定的参考价值。
问题描述
这个问题确实让我困扰了太长时间,今天花了半天时间,并没有找到非常完满的解决方案,只是在解决问题的过程中学会了一些其他知识,我最后还是要通过人工来判断大致的移动距离,然后根据误差做微调。大致做个总结了,并且认为网站如果真心愿意反爬虫,完全可以处理到让爬虫无懈可击。
今年四月份时B站的Geetest验证码大致情况可以通过https://blog.csdn.net/CY19980216/article/details/89074771中的知悉,当时检查元素可以发现验证图片是由一块块div包裹着的切片,并且标签中注明了该切片在原图中对应的坐标,这就对我们复原图片并寻找缺块位置带来了极大的便利(事实上可以通过抓包拿到有缺块的验证图片与无缺块的验证图片)。
但是现在的情况是下面这样的,验证码是一张canvas画布👇
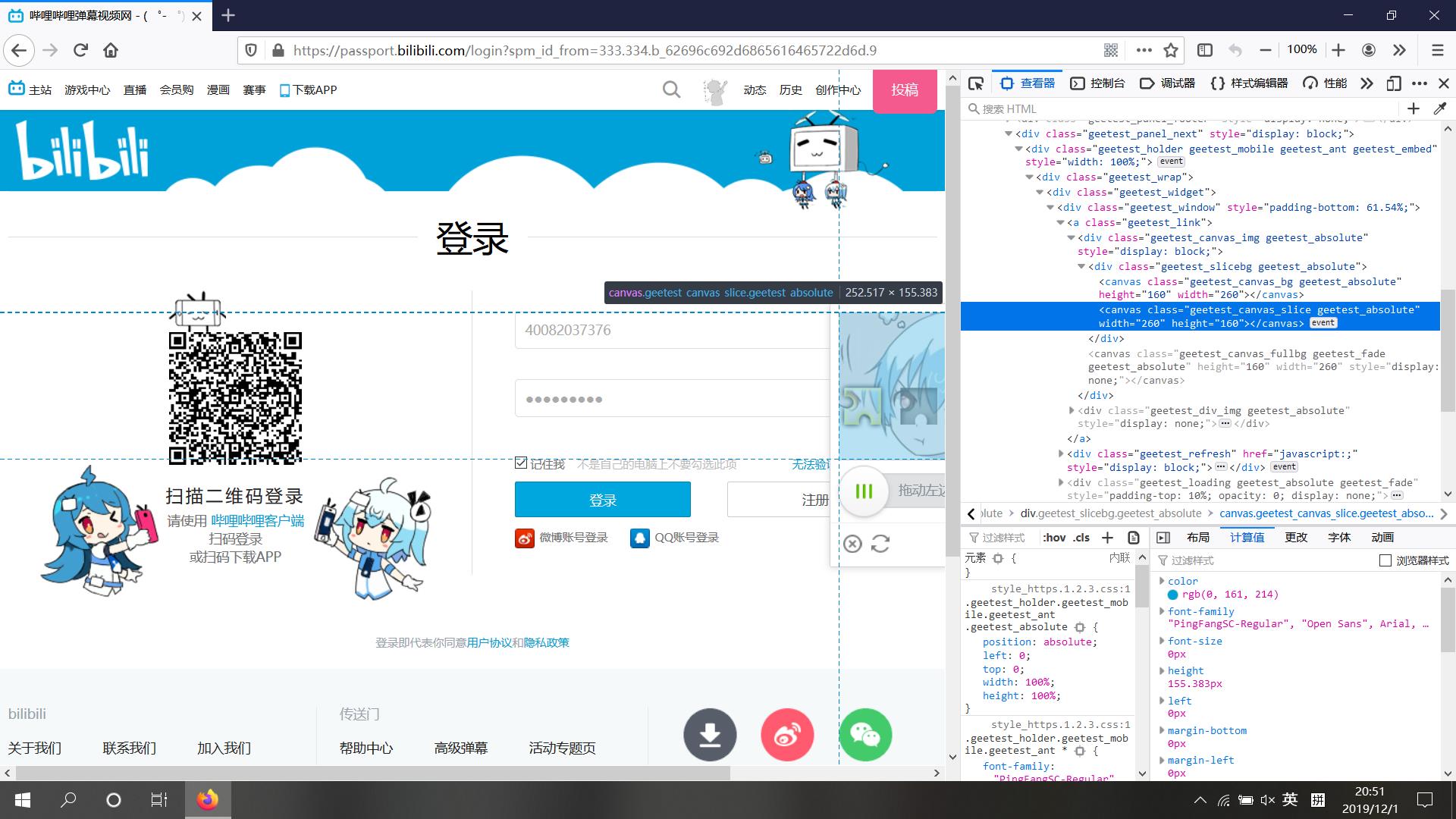
虽然在页面源代码中并不能找到验证图片的链接,但是我们通过浏览器监听抓包可以发现有👇

其实抓包依然可以发现被切分并打乱的验证图片,并且在JS监听抓包中可以看到这个图片链接的响应👇

其实看到这里我是以为问题已经解决了,显然是通过JS请求,Geetest响应了图片链接URL,然后访问图片链接就可以拿到这张验证图片。
解决设想
首先在页面源代码中可以找到这段JS响应的请求URL,经过对页源中各个script标签中的检测发现上图返回了图片链接URL的JS请求的URL如下图所示(我将页源复制到Notepad++中了):

红框中的东西就是这个👇
https://api.geetest.com/get.php?is_next=true&type=slide3&gt=b6cc0fc51ec7995d8fd3c637af690de3&challenge=ac60b064d702e4f9cc4d728eeca30764&lang=zh-cn&https=false&protocol=https%3A%2F%2F&offline=false&product=embed&api_server=api.geetest.com&isPC=true&area=%23geetest-wrap&width=100%25&callback=geetest_1575204658911这显然是一个带有查询字符串的GET请求,它的查询字符串大致是这样的👇

要命的问题来了,可以看到这里有一个chanllenge的字段,事实上这个URL只能被访问一次(即浏览器访问的这一次),二次访问就会返回给你old challenge的响应(不信你把这段URL复制到浏览器里看看),challenge字段起到验证作用,且阅后即焚,是个一次性用品,也就是说这张图片的链接URL只能被请求一次。
于是问题在于如何在利用selenium爬虫时可以顺带监听浏览器本身的抓包情况,这个便需要用到一个叫作browsermobproxy的库,这个库在安装上有个坑点,首先pip install browsermobproxy后你还需要去Github上去把它的源码下下来,因为需要源码里面的一个bat文件用来操作java,这个库具体用法Firefox用户可以参考https://blog.csdn.net/m0_37618247/article/details/85066272,它可以协作selenium把浏览器的包以json格式保存下来,经过实验,确实是可以拿到了图片的链接的了。
但是我无法复原上面截图中的那张打乱的图片,于是我干脆决定直接在网页上进行canvas元素截图。
元素截图不是什么难事,元素定位可以定位到它的左上角坐标,再根据元素尺寸即可拿到元素的具体位置了。坑点在于截屏的尺寸往往与浏览器自身尺寸不一样,即实际操作时需要将selenium截屏后的图片进行放缩(我的放缩比例是1.25)
问题转化为如何寻找缺块,我确实没有能够找到很好的办法去处理缺块,先后尝试了多种方法(基于矩阵的运算,我先后测试了临近两列的列向量相似度变化曲线,缺块),另外提一句利用selenium执行JS脚本可以从canvas中抓取到图片👇
JS = 'return document.getElementsByClassName("geetest_canvas_slice geetest_absolute")[0].toDataURL("image/png");'
img_info = browser.execute_script(JS) # 执行js文件得到带图片信息的图片数据
img_base64 = img_info.split(',')[1] # 拿到base64编码的图片信息
img_bytes = base64.b64decode(img_base64) # 转为bytes类型
with open("1.png","wb") as f:
f.write(img_bytes)
我看了其他人的方法都可以用该方法去找到原图与有缺块的图(事实上页面上有一个默认不展示display:none的canvas,它理论上包含着的是不含缺块的原图),但是这里我只能拿到如下的图👇

毫无用处。。。
最后用PIL库中的ImageContrast方法进行图片对比度增强,可以使得图片中的缺块变为几乎纯黑,于是可以近似找到边界👇


但是这个方法并不对所有的图片都生效,比如下面这张👇

对比度增强后并不会出现黑团(不展示增强对比度后的图片了,实在是太惊悚了,我可怜的2233娘)。
所以最后我也懒得处理这个问题了,我就直接用肉眼看一下大概缺块的位置所占整张图片宽度的比例,然后手动输入给程序了。。。确实比较蠢,但也不想动脑子了。
最后代码大致是这样的👇
def login_20191130(self,): # 用户登录(20190712更新)
"""
目前登录方式相对于20190408的区别在于一下几点:
- 次序上是先输入用户名密码, 点击登录后才会出现验证码图片;
- 验证码图片的元素结构变化, 没有小切片因为是一个canvas画布标签, 图片链接仍然可以找到, 但是不在页面源代码中, 抓包可得, 抓包还能抓到geetest的返回结果;
- 滑动按钮并未改变, 因此看起来是极验自身升级了;
"""
def get_track(xoffset): # 获取一条路径
tracks = []
x = int(xoffset/2) # 先走一半(很关键,不走不给过)
tracks.append(x)
xoffset -= x
while xoffset>=10:
x = random.randint(5,9)
tracks.append(x)
xoffset -= x
for i in range(int(xoffset)): tracks.append(1) # 最后几步慢慢走
return tracks
while True:
browser = webdriver.Firefox() # 驱动火狐浏览器
browser.maximize_window() # 窗口最大化
browser.get(self.loginURL) # 访问登录页面
interval = 2. # 初始化页面加载时间(如果页面没有加载成功,将无法获取到下面的滑动验证码按钮,林外我意外的发现有时候竟然不是滑动验证,而是验证图片四字母识别,个人感觉处理滑动验证更有意思)
while True: # 由于可能未成功加载,使用循环确保加载成功
browser.find_element_by_id("login-username").send_keys(self.username)
browser.find_element_by_id("login-passwd").send_keys(self.password)
time.sleep(interval)
browser.find_element_by_xpath("//a[@class='btn btn-login']").click()
xpath = "//canvas[@class='geetest_canvas_slice geetest_absolute']"
#WebDriverWait(browser,15).until(lambda driver: driver.find_element_by_xpath(xpath).is_displayed())
try:
time.sleep(interval) # 等待加载
canvas = browser.find_element_by_xpath(xpath)
except:
browser.refresh() # 刷新页面
interval += .5 # 每失败一次让interval增加0.5秒
print("验证图片加载失败!页面等待时间更新为".format(interval))
continue
browser.save_screenshot("/screen.png".format(self.tempFolder))
location = canvas.location
size = canvas.size
left = location["x"] # 获取图片左边界
top = location["y"] # 获取图片上边界
right = left + size["width"] # 获取图片右边界
bottom = top + size["height"] # 获取图片下边界
image = Image.open("/screen.png".format(self.tempFolder))
image = image.crop(( # 缩放及对右下边界要多取一格像素, python向来都是包左不包右
left*self.layout,
top*self.layout,
right*self.layout+1,
bottom*self.layout+1
))
image.save("/canvas.png".format(self.tempFolder)) # 保存图片
break
while True:
div = browser.find_element_by_class_name("geetest_slider_button")
ActionChains(browser).click_and_hold(on_element=div).perform()
ratio = input("请输入肉眼可见的比例: ")
xoffset = 260*float(ratio) # 寻找缺块位置的横坐标
tracks = get_track(xoffset)
total = 0
for track in tracks:
print(track)
total += track
ActionChains(browser).move_by_offset(xoffset=track,yoffset=random.randint(-5,5)).perform()
time.sleep(random.randint(50,100)/100)
ActionChains(browser).move_by_offset(xoffset=5,yoffset=random.randint(-5,5)).perform()
ActionChains(browser).move_by_offset(xoffset=-5,yoffset=random.randint(-5,5)).perform()
time.sleep(0.5)
ActionChains(browser).release(on_element=div).perform()
time.sleep(3)
html = browser.page_source
time.sleep(1.)
soup = BeautifulSoup(html,"lxml")
title = soup.find("title")
if str(title.string[4])=="弹":
print("登录失败!准备重新登录!")
else:
print("登录成功!")
return browser这是个类函数,原类在https://blog.csdn.net/CY19980216/article/details/89074771
总之这次经历之后我觉得只要WEB开发者愿意,绝对可以做到让你什么东西也拿不到。
推荐一篇别人做成功的https://blog.csdn.net/z434890/article/details/93631888,但是我用这个方法确实不管用,唉算了,没必要跟自己过不去。
分享学习,共同进步!
20191202更新
好吧,我承认是我蠢了,页面上其实有三个canvas,其中一个是默认不展示的(即原图),一个是展示的有缺块的图,一个是滑块的图,我之所以用browser.execute_script()拿到的只有滑块是我太蠢了,这样问题其实就转化为前一篇模拟登录里面的情况了,很容易就可以找到边界了:
重新附上代码
def login_20191202(self,):
"""
页面上有三个canvas, 原图与缺块图都可以很容易拿到的;
这三个canvas的class属性分别为:
"geetest_canvas_fullbg geetest_fade geetest_absolute" # 无缺块的图片
"geetest_canvas_slice geetest_absolute" # 滑块图片
"geetest_canvas_bg geetest_absolute" # 有缺块的图片
问题由此转化为20190408的情况;
"""
def download_verifying_picture(canvas_class,name): # 下载滑动验证图片(从canvas标签中转化得到)
JS = 'return document.getElementsByClassName("")[0].toDataURL("image/png");'.format(canvas_class)
image_data = browser.execute_script(JS) # 执行js代码得到带图片信息的图片数据
image_base64 = image_data.split(",")[1] # 摘取base64编码的图片信息
image_bytes = base64.b64decode(image_base64) # 将base64代码转为bytes类型
with open("\\\\\\\\.png".format(self.workspace,self.tempFolder,name),"wb") as f: f.write(image_bytes)
def find_block_space(width=64,zoo=1.0,plot=True): # 寻找缺块位置(默认参数width为缺块的列宽像素,zoo这边用1.15基本上大概率能过了,但是我查了一下两个图片的属性应该是1.2,设为1.2应该要改常数项了)
image1 = numpy.asarray(Image.open("\\\\\\\\1.png".format(self.workspace,self.tempFolder)))
image2 = numpy.asarray(Image.open("\\\\\\\\2.png".format(self.workspace,self.tempFolder)))
Xaxis,Yaxis,Zaxis = image1.shape # 获取图片三维信息(160×15×3)
errors = [] # 记录260列宽上每个列向量的非相似度值
for i in range(Yaxis):
total = 0
for j in range(Zaxis):
X = numpy.array([image1[:,i,j]]).astype("int64")
Y = numpy.array([image2[:,i,j]]).astype("int64").T
normX = numpy.linalg.norm(X,2)
normY = numpy.linalg.norm(Y,2)
dotXY = numpy.dot(X,Y)[0,0]
error = 1.- (dotXY/normX/normY) # 这里我选择累积RGB在(1-余弦相似度)上的值
total += error
errors.append(total)
tempErrors = errors[:]
tempErrors.sort(reverse=True)
index = [errors.index(i) for i in tempErrors[:width]] # 计算排序后对应的索引排序(根据图像的结果来看应该前width的索引是至少近似连续的自然数)
if plot:
plt.plot([i for i in range(len(errors))],errors)
plt.savefig("\\\\\\\\error.jpg".format(self.workspace,self.tempFolder))
return min(index[:10])/zoo-10
def get_track(xoffset): # 获取一条路径(给定需要移动的距离)
tracks = []
x = int(xoffset/2) # 先走一半(很关键,不走不给过)
tracks.append(x)
xoffset -= x
while xoffset>=10:
x = random.randint(5,9)
tracks.append(x)
xoffset -= x
for i in range(int(xoffset)): tracks.append(1) # 最后几步慢慢走
return tracks
while True:
browser = webdriver.Firefox() # 驱动火狐浏览器
browser.maximize_window() # 窗口最大化
browser.get(self.loginURL) # 访问登录页面
interval = 2. # 初始化页面加载时间(如果页面没有加载成功,将无法获取到下面的滑动验证码按钮,林外我意外的发现有时候竟然不是滑动验证,而是验证图片四字母识别,个人感觉处理滑动验证更有意思)
class_bg = "geetest_canvas_bg geetest_absolute"
class_fullbg = "geetest_canvas_fullbg geetest_fade geetest_absolute"
xpath_slice = "//canvas[@class='geetest_canvas_slice geetest_absolute']"
xpath_bg = "//canvas[@class='']".format(class_bg)
xpath_fullbg = "//canvas[@class='']".format(class_fullbg)
while True: # 由于可能未成功加载,使用循环确保加载成功
browser.find_element_by_id("login-username").send_keys(self.username)
browser.find_element_by_id("login-passwd").send_keys(self.password)
time.sleep(interval)
browser.find_element_by_xpath("//a[@class='btn btn-login']").click()
try: # 我担心加载不出来
time.sleep(interval) # 等待加载
canvas = browser.find_element_by_xpath(xpath_slice)
break
except: # 验证图片canvas未加载出来
browser.refresh() # 刷新页面
interval += .5 # 每失败一次让interval增加0.5秒
print("验证图片加载失败!页面等待时间更新为".format(interval))
continue
html = browser.page_source
soup = BeautifulSoup(html,"lxml")
download_verifying_picture(class_bg,1) # 有缺块
download_verifying_picture(class_fullbg,2) # 无缺块
xoffset = find_block_space() # 寻找缺块位置的横坐标
tracks = get_track(xoffset) # 生成轨迹
div = browser.find_element_by_class_name("geetest_slider_button")
ActionChains(browser).click_and_hold(on_element=div).perform()
total = 0
for track in tracks:
print(track)
total += track
ActionChains(browser).move_by_offset(xoffset=track,yoffset=random.randint(-5,5)).perform()
time.sleep(random.randint(50,100)/100)
ActionChains(browser).move_by_offset(xoffset=5,yoffset=random.randint(-5,5)).perform()
ActionChains(browser).move_by_offset(xoffset=-5,yoffset=random.randint(-5,5)).perform()
time.sleep(0.5)
ActionChains(browser).release(on_element=div).perform()
time.sleep(3)
html = browser.page_source
time.sleep(1.)
soup = BeautifulSoup(html,"lxml")
title = soup.find("title")
if str(title.string[4])=="弹":
print("登录失败!准备重新登录!")
browser.quit()
else:
print("登录成功!")
return browser
以上是关于日常Geetest滑动验证码(三代canvas版)处理小结(以B站登录验证为例)的主要内容,如果未能解决你的问题,请参考以下文章