日常关于爬虫中iframe节点处理小结(以超星课件下载为例)
Posted 囚生CY
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了日常关于爬虫中iframe节点处理小结(以超星课件下载为例)相关的知识,希望对你有一定的参考价值。
目录
序言
关于iframe节点的问题其实是很久之前遇到的一个大坑了,大约是在做中国知网CNKI的爬虫时困扰了很长时间,当时没有iframe的概念,始终没有搞明白浏览器检查元素可以查看到的节点为什么在requests请求响应甚至selenium驱动访问的情况下都消失了,没有查到关键点上所以费了很长时间都没有解决这个问题,后来感觉会不会是因为iframe节点本身具有某种特殊性,才终于弄明白这个现象。
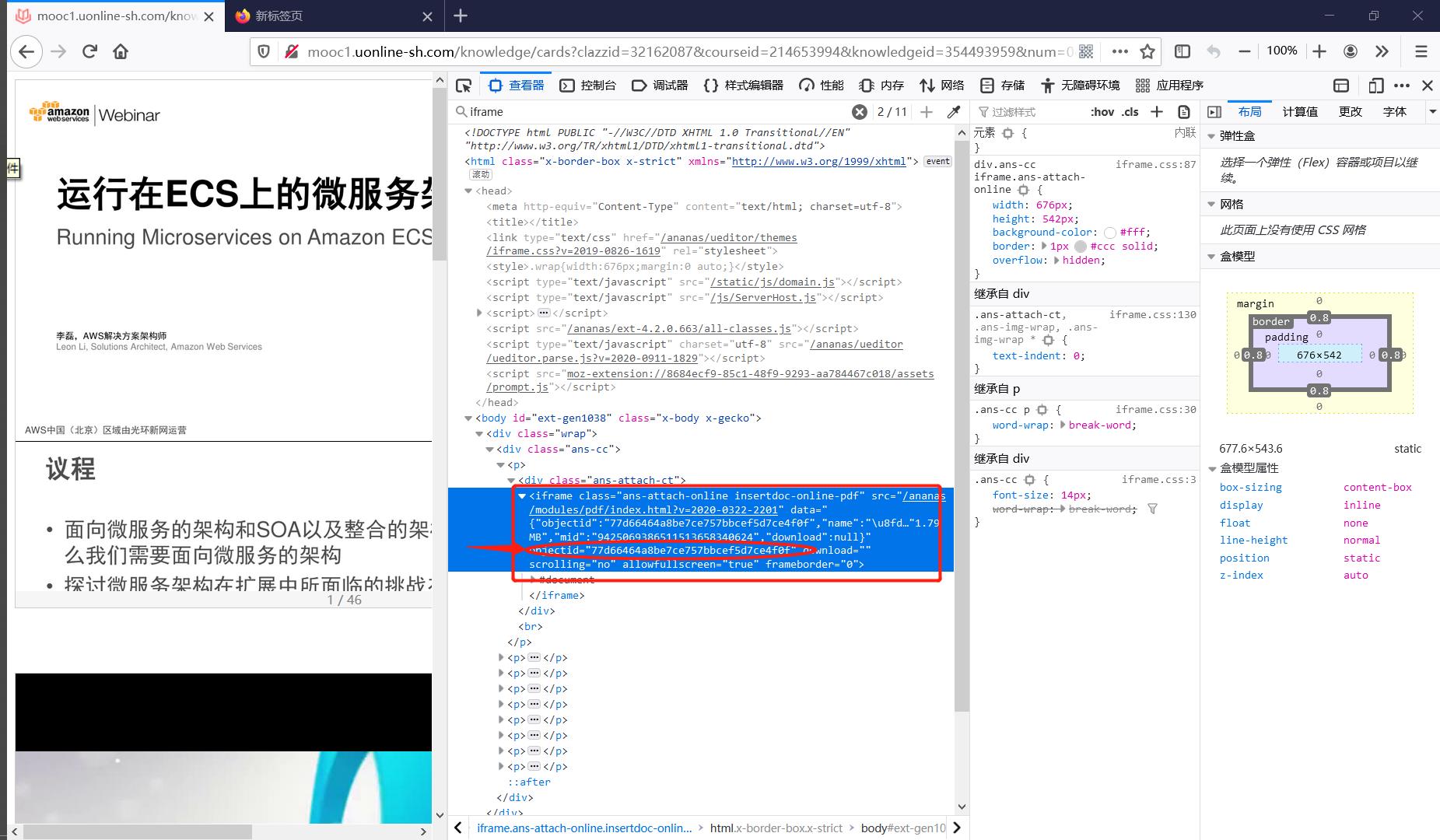
最近刚好碰到需要下载超星平台上的课件的需求,发现超星无论是在网页端还是手机客户端上都没有开放点击下载课件的按钮接口,手机端阅读课件太勉强,网页端每次都要登录也很麻烦,自然而然地会想要找到可行的下载课件方法。恰好发现包装课件的标签是一个iframe标签(Figure1),就以此为契机简单总结一下关于爬虫中iframe节点的处理方式。
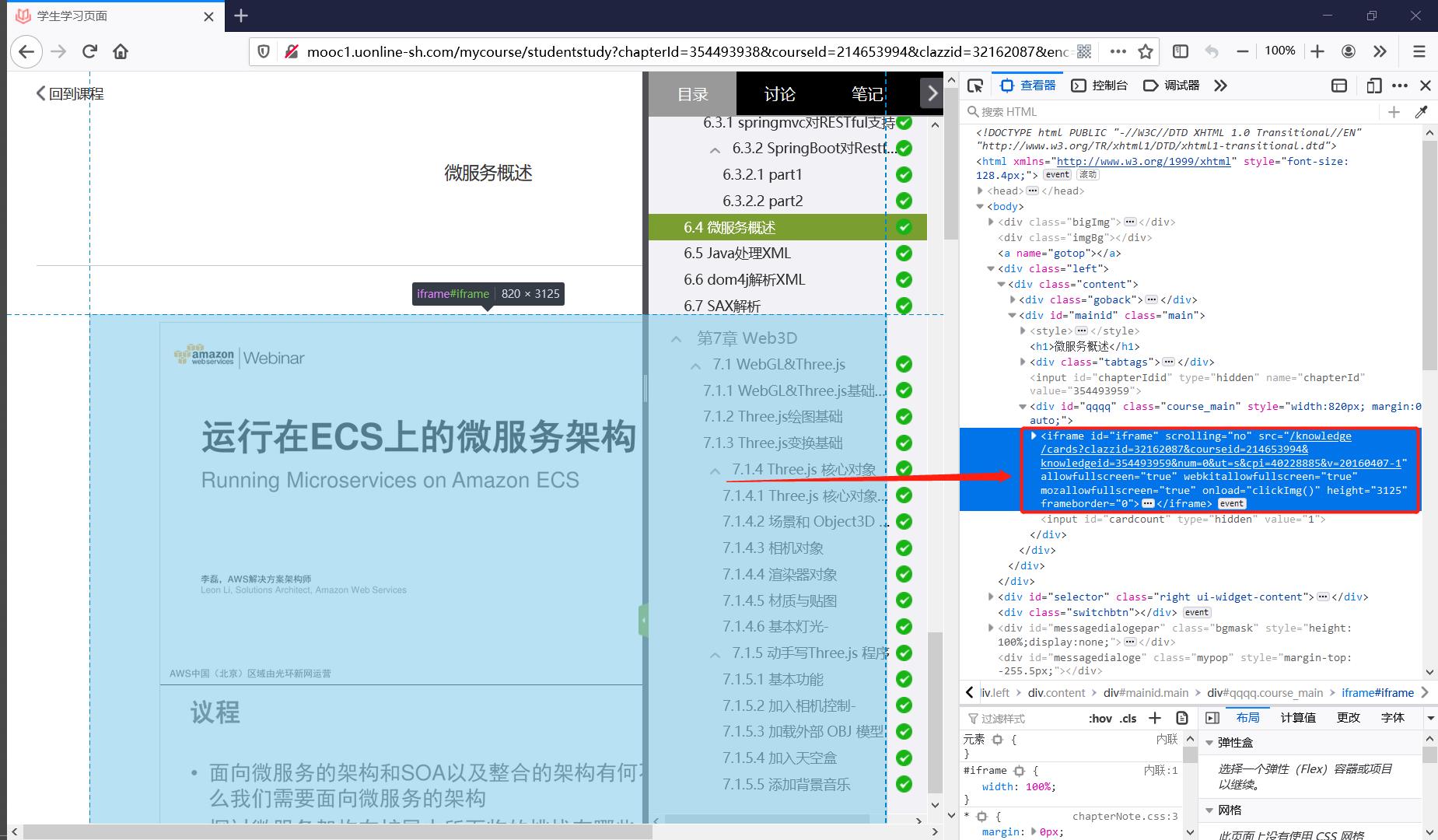
通过iframe节点我们可以将如由另一个URL指向的HTML页面(这样的URL未必存在,也可以是后端直接发来一段静态的HTML代码展示在前端界面)嵌入到当前的页面DOM中,展开Figure1的红框中可以看到这个iframe节点中内嵌了一个完整的html节点(Figure2),这意味着一个完整独立的页面被嵌入在了当前页面中,通过访问figure1中iframe节点的src属性所指向的URL可以访问这个被嵌入的页面(Figure3)
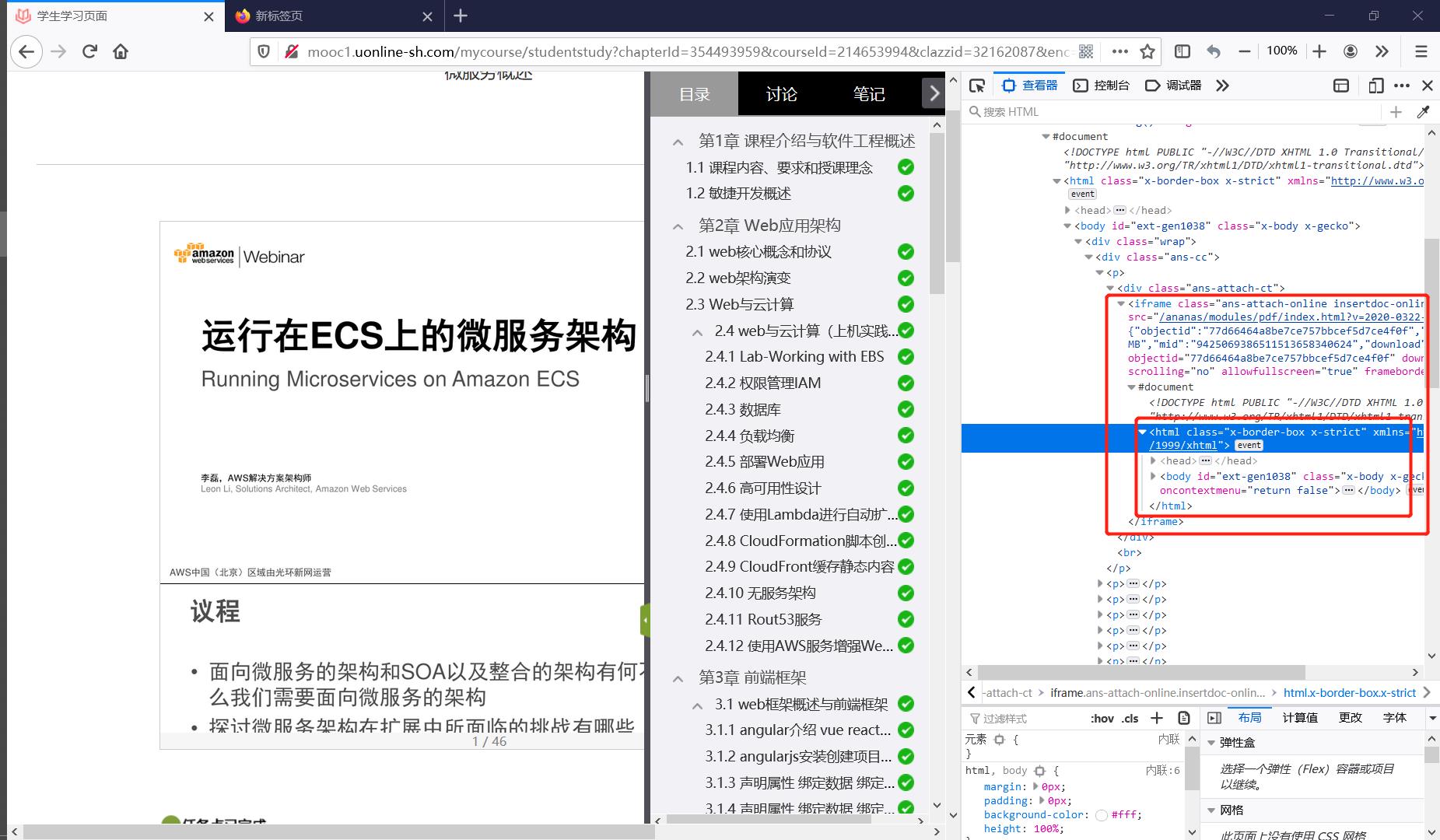

如果足够细致,继续检查这个页面的元素你会发现这个页面中仍然存在iframe节点(Figure4),这意味着iframe节点可以嵌套iframe节点,这就使得一个页面中的iframe节点的内容可以相当复杂。事实上当你使用爬虫请求某个URL路由时,iframe节点中的内容并不会加载,它只是一个空壳挂在那里(甚至你可以尝试在浏览器上复制查看器中的所有页面源代码,复制下来的结果会发现iframe是空壳,但是你仍然可以在查看器中看到iframe中的内容),只有通过JS执行或其他一些页面触发机制,主动请求了iframe包含页面所在URL路由并收到响应,才会使得iframe中的内容得到加载,因此浏览器驱动是天然地适用于捕获iframe节点中的内容,在selenium部分可以看到简单使用switch_to_frame函数就可以实现转入iframe内嵌页面的效果。
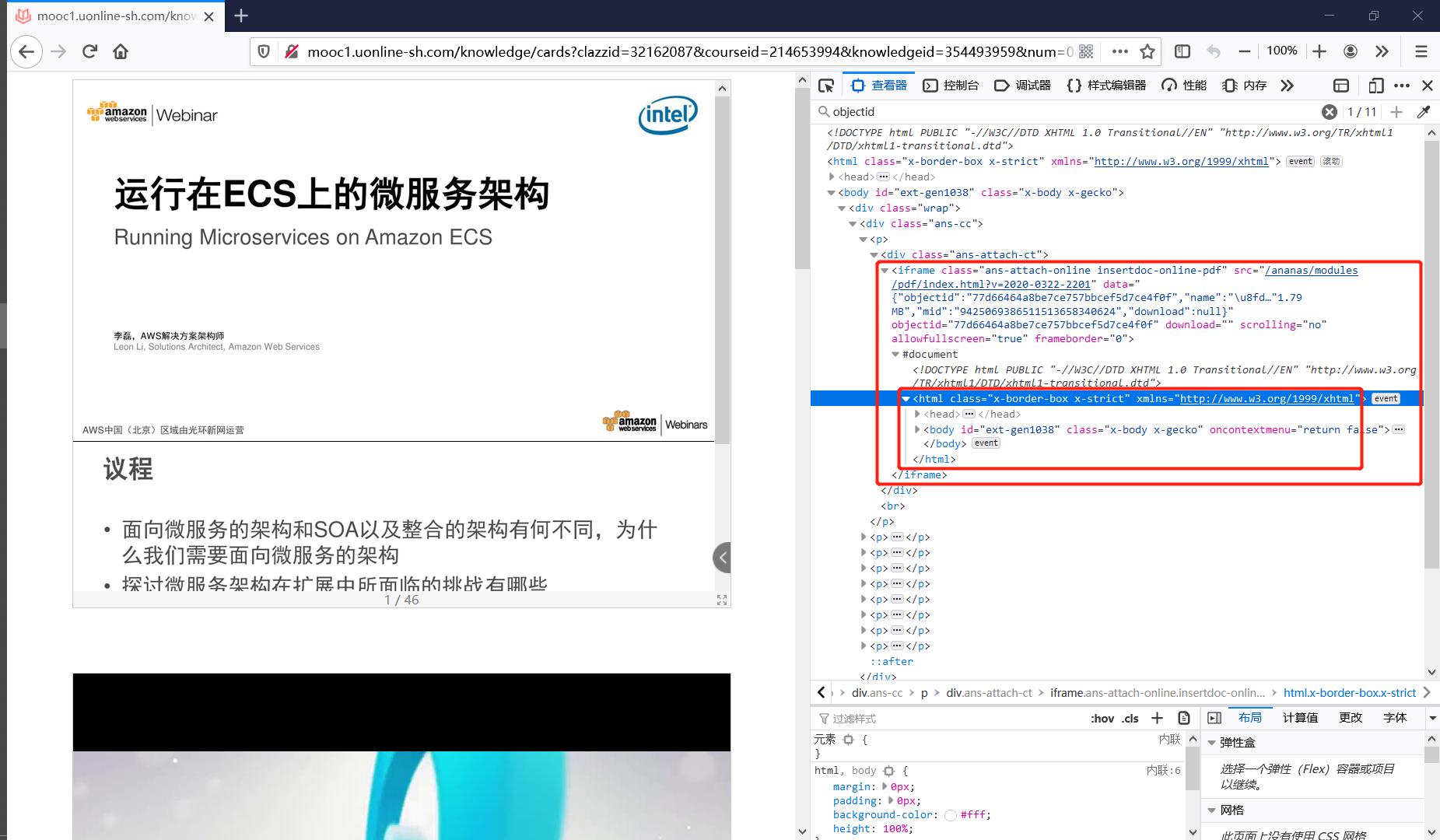
目前网络上几乎所有关于爬虫中iframe处理的都是使用selenium驱动浏览器来加载,selenium在爬取速度以及资源消耗上远劣于直接使用requests请求爬虫,一般来说方便用requests解决的爬虫不要牵扯到selenium,本文放在第二部分简略提及作为补充,这里主要就使用requests对iframe节点内容的获取的可行方法做一些总结。
Requests处理策略
requests方法无法模拟执行JS来加载iframe节点中的内容,因此只能试图去找到iframe节点中的网页源所在的URL地址,可以观察Figure1中的iframe节点的src属性如下所示👇
/knowledge/cards?clazzid=32162087&courseid=214653994&knowledgeid=354493959&num=0&ut=s&cpi=40228885&v=20160407-1上面Figure3已经访问了这个链接并确实的访问到了这个页面。因此requests处理iframe节点的方法可以是去寻找iframe节点的src属性。
其实细致一点可以发现超星的课程界面的页源相对简单,页面源代码里的javascript中已经很详细地写明了src属性的值的构成👇
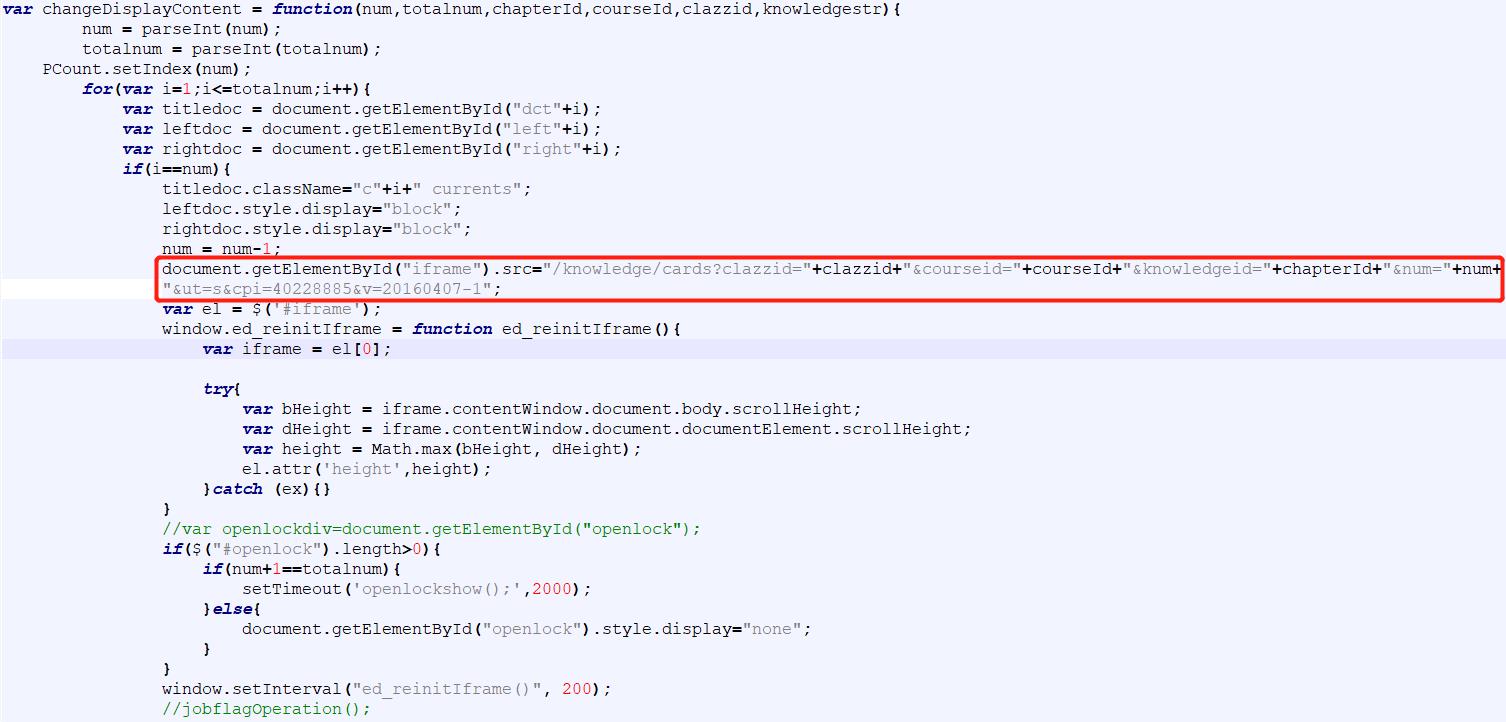
但是问题是并非所有的iframe节点都与超星课程界面这样可以找到可用的src属性,事实上很多实际遇到的iframe节点都不能用上面的方法来解决,随便找个网易云网页端首页的页源,它同样包含iframe节点,会发现这里的src属性的值为about:blank即为空,是不可用的。
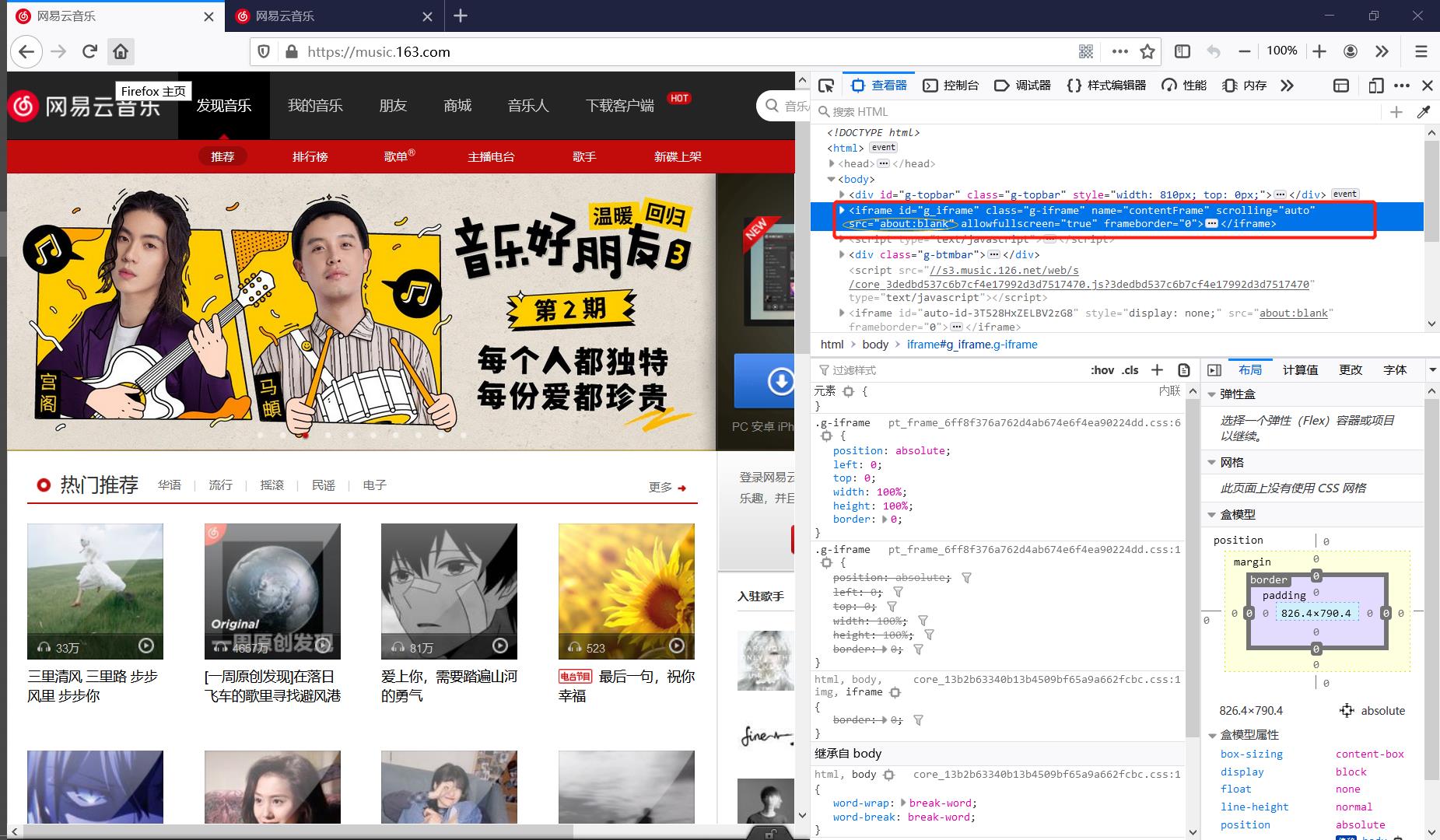
5
为了解决这个问题我们监听首页加载时HTML抓包结果发现访问了https://music.163.com/discover👇
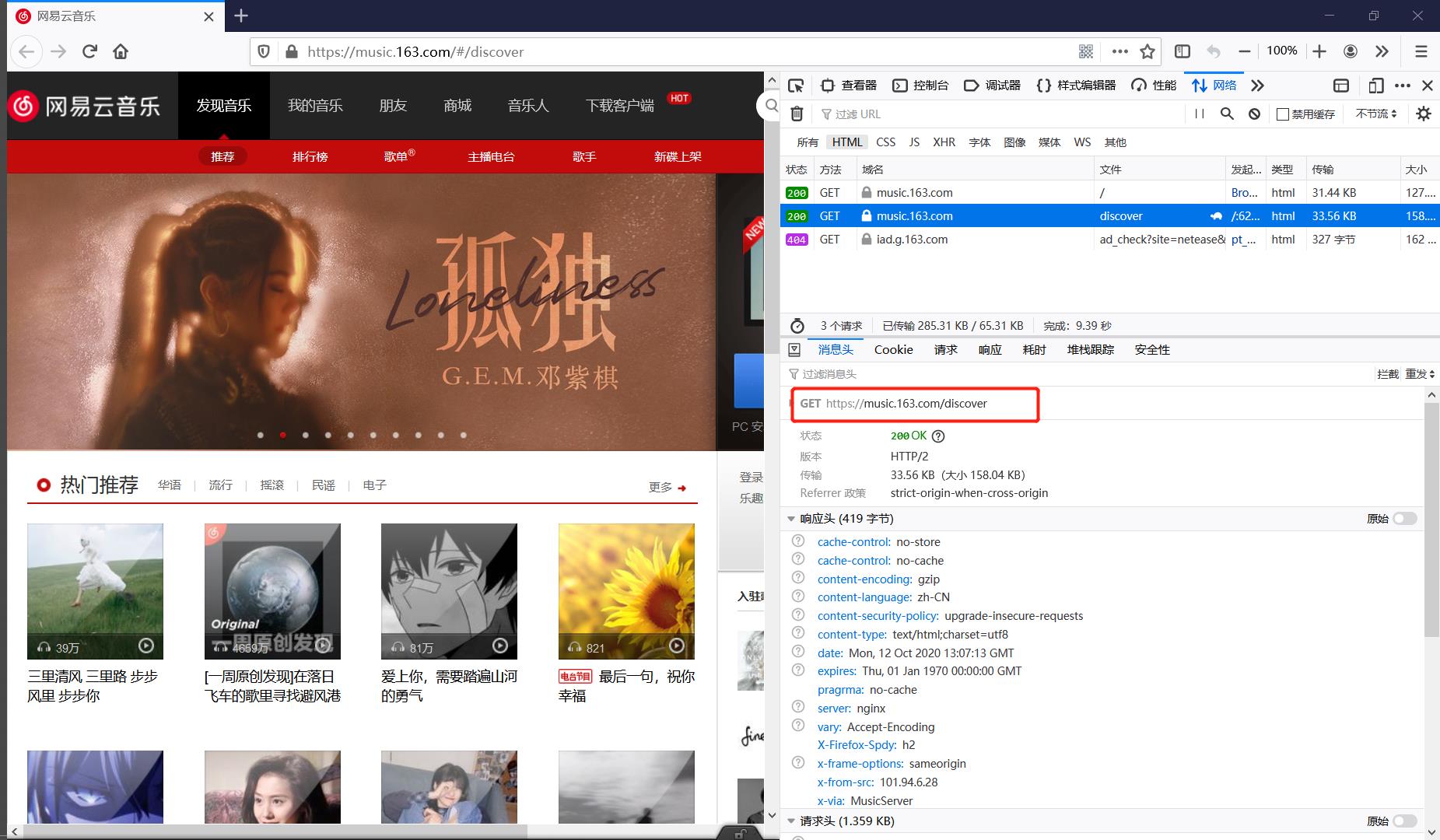
但是如果你直接访问 https://music.163.com/discover 会发现被重定向到了 https://music.163.com/#/discover 是一个与首页一模一样的页面,iframe节点依然存在,这是怎么回事呢?
通过观察首页页源的script👇
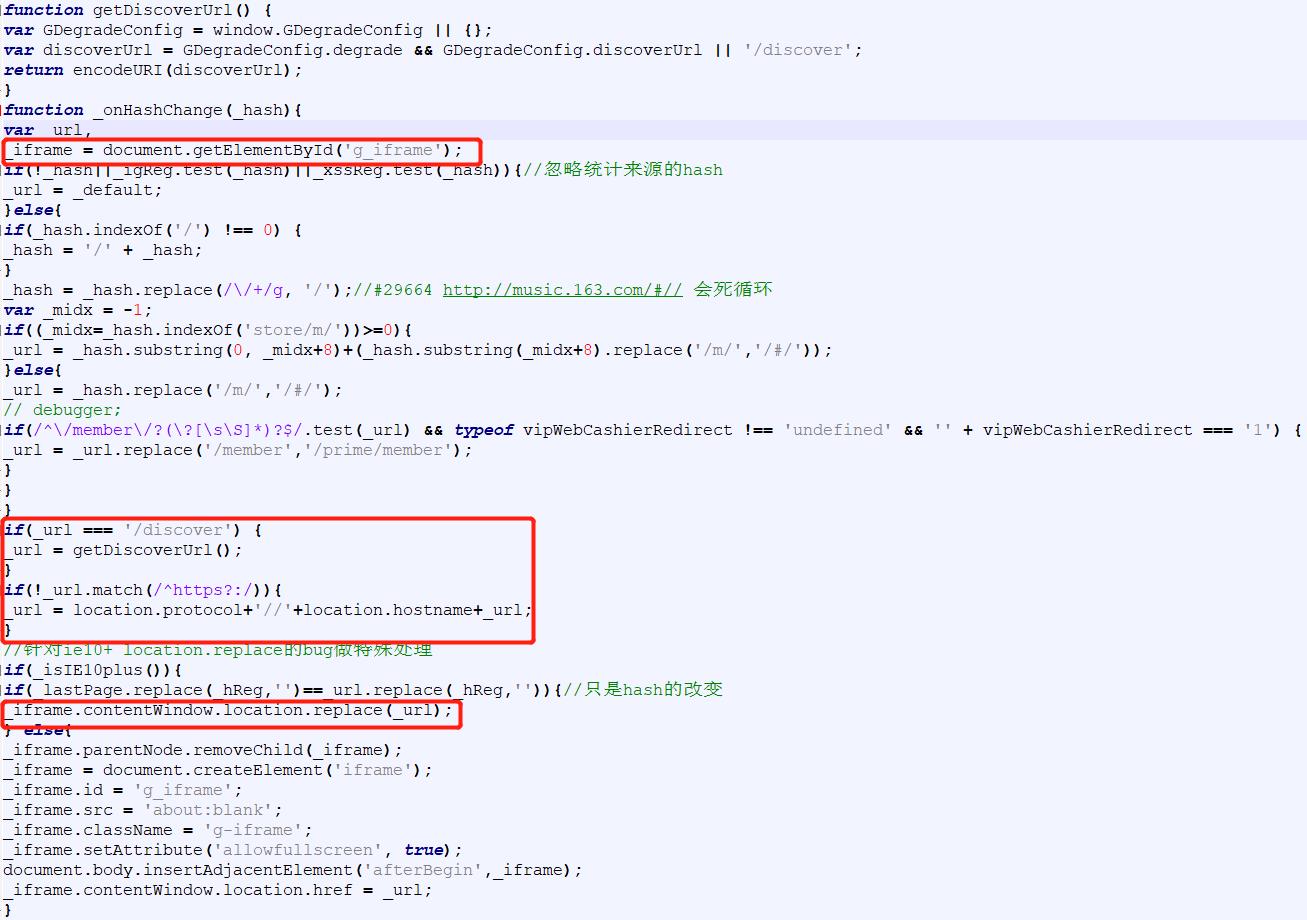
可以发现确实是使用https://music.163.com/discover 的内容填充iframe,只是我们无法直接在浏览器中访问而已,使用requests.get("https://music.163.com/discover") 就可以访问到与iframe中嵌入的HTML相同的页源了。
总结来说有src属性是最好,如果没有,监听网络中的HTML一栏(一般来说iframe都是加载HTML,极少可能在XHR中),一般来说可以找到iframe所包含的页面,验证方法要通过requests访问,而非直接在浏览器中打开,因为可能被重定向。
Selenium处理方法
当确然难以使用requests解决iframe节点捕获时,可以使用selenium作为兜底的解决方案。
事实上如果用selenium访问某个带有iframe节点的网页时,在获取driver.page_source变量会发现iframe节点是一个空节点,但是这并不影响使用driver.find_element_by_xpath或其他方法来定位到这个iframe节点,在获取这个iframe节点元素后直接切换到其中即可,代码模板如下所示(以Firefox的selenium驱动为例)👇
from selenium import webdriver
driver = webdriver.Firefox()
driver.get("需要访问的网址")
iframe = driver.find_element_by_xpath("//iframe") # 可以修改xpath, 这里默认获取到第一个iframe节点
driver.switch_to_frame(iframe) # 切换到iframe中
print(driver.page_source) # 可以查看到iframe中的网页源代码注意如果需要定位的iframe节点嵌套在上层iframe节点中,则需要依次switch👇
from selenium import webdriver
driver = webdriver.Firefox()
driver.get("需要访问的网址")
# 第一层iframe
iframe1 = driver.find_element_by_xpath("//iframe") # 可以修改xpath, 这里默认获取到第一个iframe节点
driver.switch_to_frame(iframe) # 切换到iframe中
# 第二层iframe
iframe2 = driver.find_element_by_xpath("//iframe")
driver.switch_to_frame(iframe)
print(driver.page_source) # 可以查看到iframe中的网页源代码想要切回到前一个iframe则可以使用👇
driver.switch_to.parent_frame()也可以直接切回到最一开始的页面👇
driver.switch_to.default_content()基本掌握上面的方法就可以从容的处理iframe节点了。
超星课件下载方法
最后笔者简要提一下超星课件的下载方法,让我们先回到Figure3展示的iframe中的独立页面上,重新加载监听网络👇
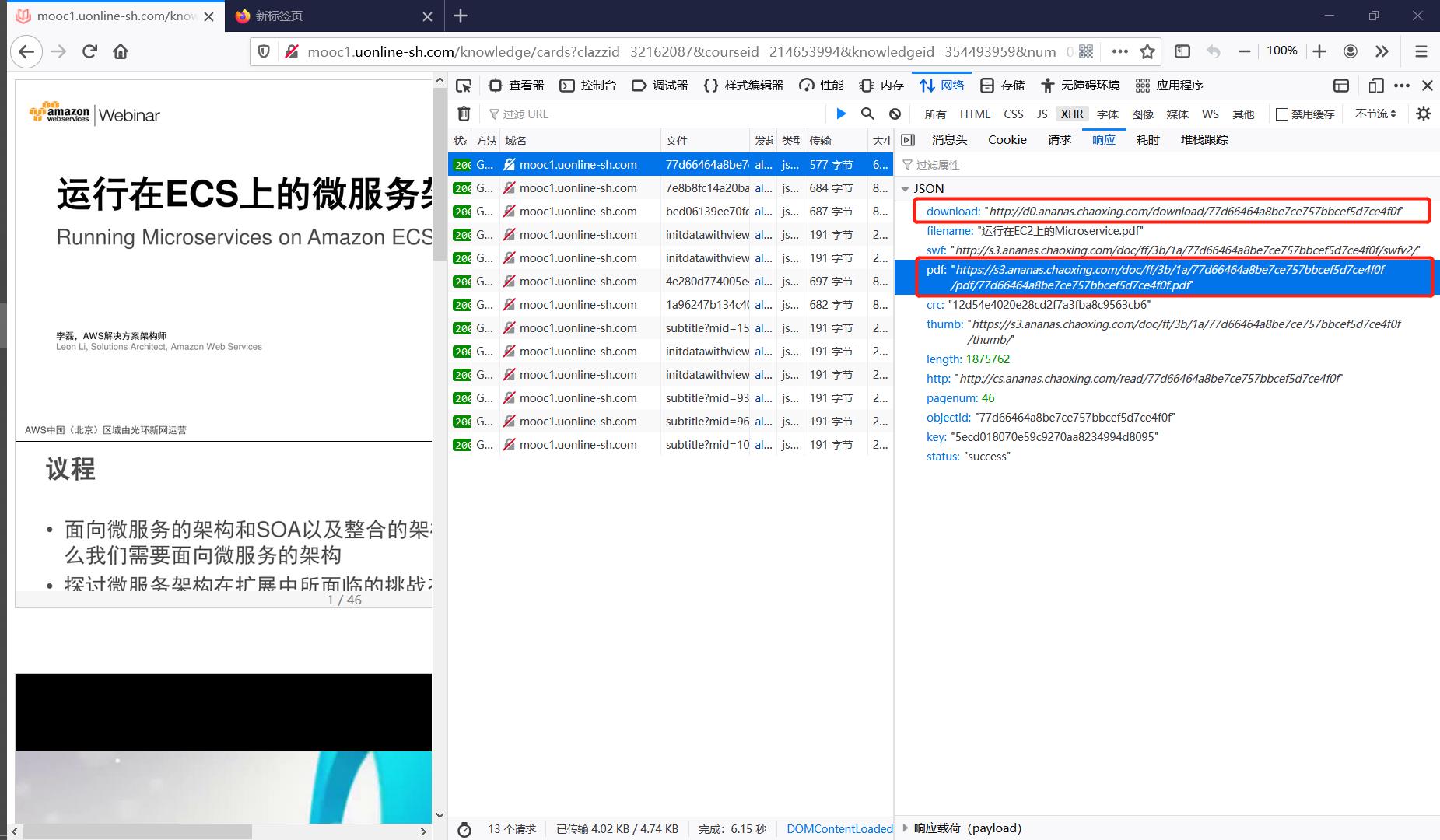
直接说结论:Figure7中红框中的两个链接都是pdf课件的下载地址
可以发现它们虽然长得差很多,但是同时出现了77d66464a8be7ce757bbcef5d7ce4f0f这串字符,这不由得让人想要知道这段字符串是从何而来的👇
检查元素看到iframe节点中存在77d66464a8be7ce757bbcef5d7ce4f0f这串字符,它是data属性中objectid键的值,事实上如果iframe节点如果包含data属性,一般都可以很容易获取到这个iframe节点所包含的资源。事实上超星中的网课视频也可以用相同的方法下载。
到此为止其实已经可以编写一个脚本来下载超星上的课件,当前前提你需要有这门课访问的权限,超星用户登录问题可以在requests头中加入cookie解决,本质难点只在于获取到课件的objectid,就可以直接下载课件,方法只需要用上面requests处理iframe节点的办法即可,有兴趣的朋友可以试试,笔者自己就是用这种方法一次性把这门课100多份课件全部下载下来的,毕竟手动下载实在是很慢。
结语
其实大约主要处理iframe节点的方法可能还是以selenium为主,但是requests方法应该是更有效率并且在切实可行的情况下,一定是优于selenium的。
分享学习,共同进步!
以上是关于日常关于爬虫中iframe节点处理小结(以超星课件下载为例)的主要内容,如果未能解决你的问题,请参考以下文章