实时音频编解码之一发声和听觉机理
Posted shichaog
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了实时音频编解码之一发声和听觉机理相关的知识,希望对你有一定的参考价值。
本文谢绝任何形式转载,谢谢。
新冠大流行使得基于IP网络的交互式实时音视频技术在更多的领域得到应用,然而由于基于包交换技术的IP网络并不是为交互式实时音视频场景而推出的技术,通过IP网络传输的音视频可能受到带宽限制,也可能存在丢包、乱序以及抖动等多种问题,ITU-T G.114中对于端到端通信场景(嘴到耳)延迟在150毫秒及以下并不容易被人察觉,然而当端到端延迟超过400毫秒时通话质量将受影响,受限于网络带宽、延迟、丢包以及抖动问题,相应的有实时音频编码器、抖动缓冲区、丢包补偿等技术从音频算法层面减弱上述问题的影响,这些技术通常和编码器都有关系,音频编码又称音频压缩是指在合理的音频质量前提下用尽量少的比特表示数字音频信号,其减少了网络带宽的占用,因而适合长距离传输场景,本书会着重介绍交互式实时场景中较为经典的Opus编码器,当音频信号以VoIP包在IP网络上传输时,VoIP语音数据包会经过不同的路由器传输,这会导致有些VoIP包相较于其它VoIP包到达接收端比较晚、或者损坏甚至根本没有成功传输到接收端,没有成功传输到接收端的VoIP称为丢包,丢包的一种可能是网络带宽(通常和资费有关)满了导致路由器根本无法传输更多数据包,另一种可能是网络拥塞导致了很大的延迟,对于VoIP实时通信场景而言,太大的延迟到达的包会被认为是丢包,VoIP场景的实时通信底层通常使用基于UDP的传输技术,并不像TCP/IP协议一样提供可靠的传输,因而在发送端重传有问题的包并不能很好的解决丢包问题,通常接收端要实现丢包隐藏技术以抗丢包,交互式实时音频应用场景语音处理协议栈如图0-1所示,语音增强和回声消除所述技术可见笔者《实时语音处理实践指南》一书,本书主要浅析非理想网络情况下的VoIP音频编解码和抖动缓冲区技术。
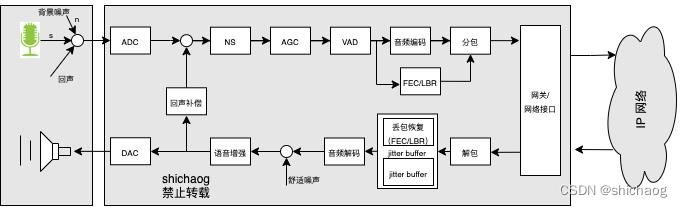
本书先介绍音频编解码内容,而后是抖动缓冲区技术,音频编解码部分,先介绍编解码涉及的传统信号处理方法,包括数字信号处理、滤波器组、信号变换、量化、熵编码、心理声学模型以及听觉模型等,然后解码Opus编码器的CELT和LPC两种核心技术,再分析Opus源码的实现,最后是基于AI方法(以开源LPCNet为例)浅析的编解码和丢包补偿,需要说明的是,对于Opus部分,其手册和代码仍是最可靠的信息来源。
第一章 音频信号处理方法简介
1.1人类听觉特性
编解码正是利用了人类发声和听觉系统的一些特性,因而了解发声机理和听觉机理有助于理解语音编解码的实现核心思想。
1.1.1 发声机理
人类发声涉及肌肉、肺、舌和声道等器官位置变化,这些器官在发音时变化速度是有限度的,其中声带和声道的形状相对平稳,这使得语音具有短时平稳特性,短时平稳性是很多语音算法的先决条件之一。语音发音可以分为浊音和清音两类,发浊音时大部分能量集中在低频段,且在时域上具有周期性,在频域上频谱分布具有共振峰结构,清音和白噪声类似,没有明显的时域和频域特征。
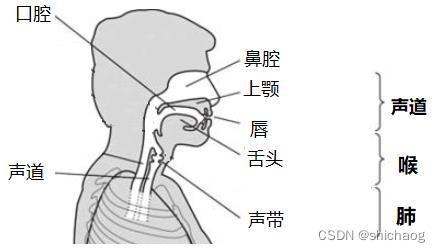
图1-1 发音器官位置分布
肺部呼气和吸气带来的气流震动是声音产生的主要来源,吸气时,胸腔变大,其内部压力比外界小,空气从声道流进气管,再到肺部。呼气时是逆过程,在这一过程中气体经气管流入喉结,喉结由肌肉、韧带和软骨组成控制着声带的功能,声带有三个状态:呼吸,发声,不发声三个状态,在呼吸状态,空气在肺部和外界自由的流动,声门处于敞开状态,在发音状态,声带和声门的伸张和收缩引起声带的周期性开闭。发声过程涉及的物理器官如图1-1所示。
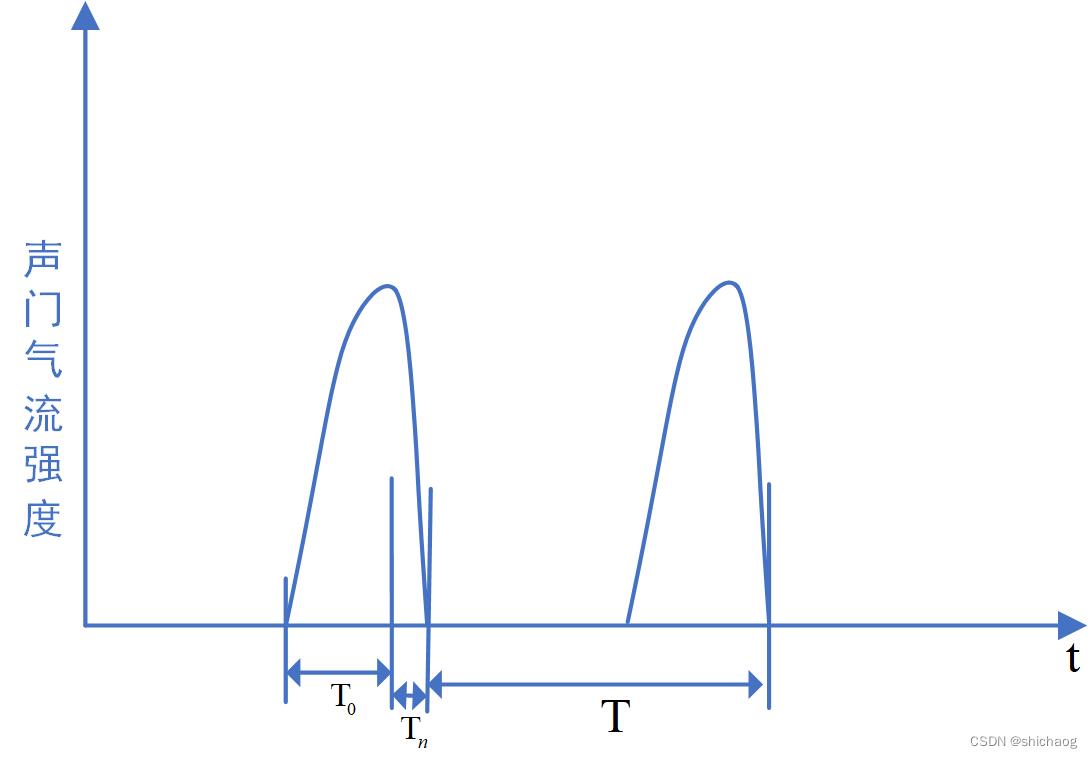
发音时,声门的气流时域波形如图1-2所示,当声带正在关闭时,气流变慢,累计达到最大值,然后迅速下降,到声带闭合时达到零。当声带闭合时,没有气流经过声道,这一过程被称为声门闭合阶段。声门的开闭周期被称为基音周期(pitch),基音周期的倒数是基频(
F
0
F_0
F0),声带的弹性和数量影响基频,当声带数量较多时,声带的伸缩将相对迟缓,类似的基音周期将相对变大,男性声带比女性的更长更多,因而男性基频(在60~150Hz)一般比女性(在200~400Hz)低。
口腔的形状和横截面积会随舌头、牙齿、嘴唇和下巴所处位置变化而变化,声道是一个声学谐振腔,其包括喉到唇之间的口腔、鼻腔以及口腔和鼻腔之间的膜。声道气流来源于声带,其作用类似于线性滤波器,对输入波形进行频谱整形,从而发出不同的声音。声道的改变(发声器官位置)会改变滤波器的特性(频响特性)。在元音产生过程中,声带可以近似为一端封闭而另一端开放的管,因为声带几乎是在发声过程中关闭而发言者的嘴是张开的。这种管共振的最低频率的波长(
λ
\\lambda
λ)是管长度的四倍。
声道的共振形成共振峰,产生共振的频率称为共振频率,第一个共振频率用F1表示,和张开的嘴型有关,嘴张开的小F1频率就低,张开的大F1的频率就高,第二共振频率F2和口腔的变化有关,如舌头的位置以及唇的动作,第三共振频率F3和口腔的前后移动有关,能量上第一共振峰比第二共振峰大,听觉上第二共振峰的影响比第一共振峰大。
对发生机理的建模常用源-滤波模型,在上世纪70年代已经使用这一模型了,LPC10、CELP、MELP等编码器的理论基础就是这一模型,当今一些高性能编码器也是基于源-滤波这一模型,该模型把语音产生分为信源和信道两个部分,信源是对声带震动建模,发清音时没有震动使用白噪声建模,发浊音时声带震动用脉冲串建模,信道是口腔、鼻腔、舌头和唇的建模,使用一个全极点的LPC滤波器建模,这是很多参数语音编码器的核心内容。
1.1.2 听觉机理
声音由耳廓收集之后,经耳道传到耳膜上,耳膜将声音从声学转换为机械振动,振动经过听骨传递到耳蜗,听骨通过减少反射以及阻抗匹配提升了声音的传播,耳蜗是充满液体类似蜗牛形的坚硬器官,撞击听骨的机械振荡会导致一种称为基底膜的内膜以不同频率振动,基底膜的特征是膜上不同点频率响应不同,可以使用滤波器组对基底膜建模,沿基底膜的运动由内毛细胞感知,并引起神经活动,这些活动通过听神经传递到大脑。
基底膜上不同点对不同频率声音有不同的响应,因此基底膜上不同位置毛细胞对不同频率声音由不同响应,这看起来人类听觉系统类似个频率分辨器。
在没有任何其他频点声音的时候,可以感受到的最小能量被称为听觉门限,图二显示了听觉门限,横轴单位是Hz,纵轴单位是dB(相对于
1
0
−
2
瓦
/
m
2
10^-2瓦/m^2
10−2瓦/m2),图二显示的是人类听觉门限的平均情况,从图中可以看到,人类对14kHz信号更为敏感,常认为人的听觉范围在20Hz20kHz,这一曲线显示在能量低于听觉曲线以下的信号可以忽略,在1~4kHz范围的信号应给以更多的编码比特率以获得尽可能好的编码质量。

图1-3 典型的听觉绝对门限曲线
掩蔽效应是指一个声音因另一个声音同时存在而被人耳朵忽略的情形,语音信号由若干频率组成,不同频率因能量大小不同而存在能量谱峰和谱谷,与此同时还有一条掩蔽效应组成的看不见的线,能量在掩蔽效应曲线之下信号人耳是听不见的,因而谱峰相对于谱谷可以承受更多的失真和噪声。
设计良好的编码器因保证谱谷得到很好的保留或没有相对失真,CELP编码器在编码时依靠感知加权滤波器对误差谱进行加权。相对于能量,相位在听觉中的作用小很多,编码过程中一定程度保留相位对语音自然度是有益的,CELP编码器编码过程中就保留了一部分相位信息。
1.2 编码器分类
语音编码涉及种类繁多的编码标准,每种标准实现又有诸多步骤,涉及诸多信号处理和数学知识。抛开具体的编码标准,从编码技术上主要分为波形编码、参数编码、混合编码以及基于深度学习的编码四大类。
波形编码是对语音波形信号经过采样、量化、编码方法,编码的主要信息是语音信号的波形,这类编码器在编码比特率较高时编码质量高,随着编码比特率降低编码质量迅速下降,PCM和ADPCM属于此类编码方法。
参数编码是基于对人类发声机理建模的方法,核心思想是从语音中提取人类发生模型需要的参数,这些参数包括激励模型参数和声道模型参数,解码端根据这些参数通过模型方法逆向合成语音声波,编码端声道参数的估计通过声波包络估计实现,声门激励参数的估计是通过激励信号估计实现,对估计出的参数采用数学方法进行量化压缩,其特点是压缩率低,较为适合基于网络的实时语音应用场景,这类编码方法并不保留原始信号波形,因为SNR并不适用于性能评估,解码后感知的语音质量和模型的复杂度以及准确性有关,线性预测编码(LPC)及MELP均属于这类方法,这类方法将人类听觉系统建模成系数是通过线性预测获取的时变滤波器。
混合编码是基于参数编码和波形编码的一种新的编码方法,编码中既包括语音特征参数又包括波形编码信息,其在中等比特率编码上具有较大优势,CELP属于此类编码方法,Opus编码器对语音部分使用了CELP编码方法,混合编码在高码率时更像是波形编码,低比特率时更像是参数编码。
基于深度学习的方法分为结合信号处理方法(pitch、LPC、LSF等特征)和直接基于频谱的特征(MFCC等)方法,深度学习和信号处理相结合的方法思想是通过信号处理方法先提前少量的语音参数以减小模型的输入特征长度,进而减小计算量,而直接基于频谱类的特征类似于语音合成一类的语音生成方法,这类方法的计算量大但是压缩率可以很高,这里的模型都是运行在解码端。此外还有一些小的模型可用于丢包恢复、语音检测分类等子任务。
包络估计方法包括如下几种:
1.同态声码器(Homomorphic vocoder),使用短时到普表示包络信息;
2.共振峰声码器(Formant Vocoder)
3.线性预测编码器(Linear Predictive vocoder),线性预测器因其压缩率和编码质量高而被主流编码器所采用,其使用全零点滤波器描述谱包络,通常线性预测误差比原始信号能量小10dB以上,
激励模型
Buzz-Hiss模型及其改进,用于LPC10e,其使用脉冲串或白噪声模拟声门激励,Hormonic excition用一组正弦波组合模拟声门激励,码本激励则使用码本模拟声门激励。
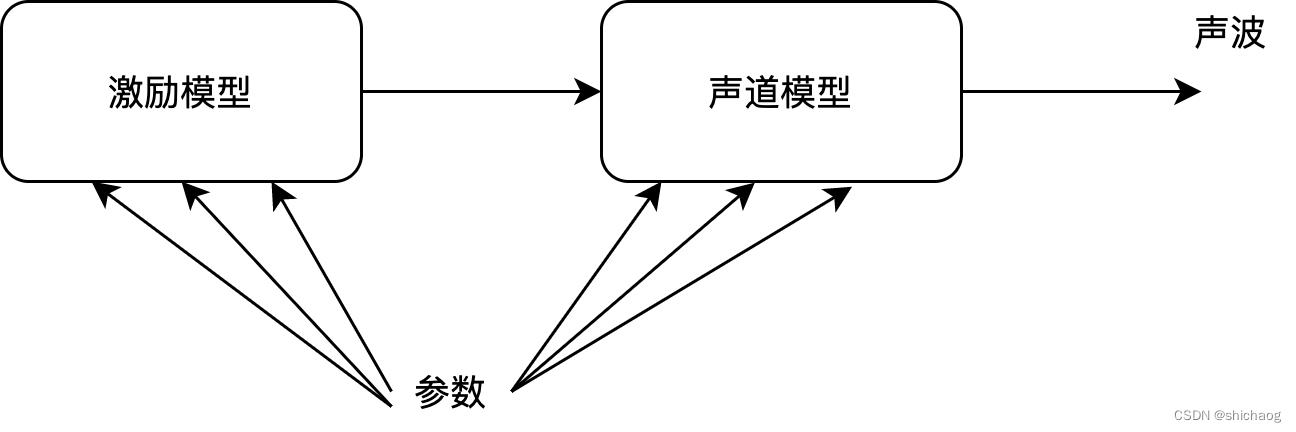
图1-4 参数编码器框架
以上是关于实时音频编解码之一发声和听觉机理的主要内容,如果未能解决你的问题,请参考以下文章