MySQL 8.0 BACKUP LOCK浅析及其在xtrabackup的应用(深度好文)
Posted 老叶茶馆_
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MySQL 8.0 BACKUP LOCK浅析及其在xtrabackup的应用(深度好文)相关的知识,希望对你有一定的参考价值。
本文首发于「mysql学习」,欢迎关注
能力有限,有误请后台告知,仅为浅析,仅供参考。
最近遇到多次阻塞备份的问题,对8.0 xtrabackup备份方式也一直不太了解,因此做了一下学习。
我们知道8.0过后加入了新的备份锁,主要包含下面2个部分:
lock instance for backup(WL#9451 Backup Lock)
pfs.log_status (WL#9452: Log Position Lock)
这里先从以往的文章中看一下FTWRL的原理和其阻塞的场景,然后集中分析一下新的备份锁大体的实现方式。
一、FTWRL的原理
实际上这部分我们可以在函数mysql_execute_command寻找case SQLCOM_FLUSH 的部分,实际上主要调用函数为reload_acl_and_cache,其中核心部分为:
if (thd->global_read_lock.lock_global_read_lock(thd))//加 MDL GLOBAL 级别S锁
return 1; // Killed
if (close_cached_tables(thd, tables, //关闭表操作释放 share 和 cache
((options & REFRESH_FAST) ? FALSE : TRUE),
thd->variables.lock_wait_timeout)) //等待时间受lock_wait_timeout影响
/*
NOTE: my_error() has been already called by reopen_tables() within
close_cached_tables().
*/
result= 1;
if (thd->global_read_lock.make_global_read_lock_block_commit(thd)) // MDL COMMIT 锁
/* Don't leave things in a half-locked state */
thd->global_read_lock.unlock_global_read_lock(thd);
return 1;
更具体的关闭表的操作和释放table缓存的部分包含在函数close_cached_tables中,我就不详细写了。但是我们需要明白table缓存实际上包含两个部分:
table cache define:每一个表第一次打开的时候都会建立一个静态的表定义结构内存,当多个会话同时访问同一个表的时候,从这里拷贝成相应的instance供会话自己使用。由参数table_definition_cache定义大小,由状态值Open_table_definitions查看当前使用的个数。对应函数get_table_share。
table cache instance:同上所述,这是会话实际使用的表定义结构是一个instance。由参数table_open_cache定义大小,由状态值Open_tables查看当前使用的个数。对应函数open_table_from_share。
这里我统称为table缓存。
好了下面是我总结的FTWRL大概步骤:
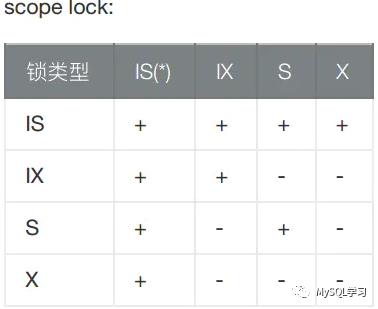
第一步: 加MDL LOCK类型为GLOBAL 级别 S 锁。如果出现等待状态为‘Waiting for global read lock’。注意SELECT语句不会上GLOBAL级别锁,但是DML/DDL/FOR UPDATE语句会上GLOBAL级别的IX锁,IX锁和S锁不兼容会出现这种等待。下面是这个兼容矩阵:
| Type of active |
Request | scoped lock |
type | IS(*) IX S X |
---------+------------------+
IS | + + + + |
IX | + + - - |
S | + - + - |
X | + - - - |第二步:推进全局表缓存版本。源码中就是一个全局变量 refresh_version++。
第三步:释放没有使用的table 缓存。可自行参考函数close_cached_tables函数。
第四步:判断是否有正在占用的table缓存,如果有则等待,等待占用者释放。等待状态为'Waiting for table flush'。这一步会去判断table缓存的版本和全局表缓存版本是否匹配,如果不匹配则等待而等待的结束就是占用的table缓存的占用者释放,这个释放操作存在于函数close_thread_table中,如下:
if (table->s->has_old_version() || table->needs_reopen() ||
table_def_shutdown_in_progress)
tc->remove_table(table);//关闭 table cache instance
mysql_mutex_lock(&LOCK_open);
intern_close_table(table);//去掉 table cache define
mysql_mutex_unlock(&LOCK_open);
最终会调用函数MDL_wait::set_status将FTWRL唤醒,也就是说对于正在占用的table缓存释放者不是FTWRL会话而是占用者自己。不管怎么样最终整个table缓存将会被清空,如果经过FTWRL后去查看Open_table_definitions和Open_tables将会发现重新计数了。下面是唤醒函数的代码,也很明显:
bool MDL_wait::set_status(enum_wait_status status_arg) open_table
bool was_occupied= TRUE;
mysql_mutex_lock(&m_LOCK_wait_status);
if (m_wait_status == EMPTY)
was_occupied= FALSE;
m_wait_status= status_arg;
mysql_cond_signal(&m_COND_wait_status);//唤醒
mysql_mutex_unlock(&m_LOCK_wait_status);//解锁
return was_occupied;
第五步:加MDL LOCK类型COMMIT 级别 S 锁。如果出现等待状态为‘Waiting for commit lock’。如果有大事务的提交很可能出现这种等待。
二、FTWRL阻塞和被阻塞场景
(1)被什么阻塞
长时间的DDL\\DML\\FOR UPDATE会阻塞FTWRL,因为FTWRL需要获取 GLOBAL的S锁,而这些语句都会对GLOBAL持有IX(MDL_INTENTION_EXCLUSIVE)锁,根据兼容矩阵不兼容。等待为:Waiting for global read lock 。
长时间的SELECT会阻塞FTWRL,因为FTWRL会释放所有空闲的table缓存,如果有占用者占用某些table缓存,则会等待占用者自己释放这些table缓存。等待为:Waiting for table flush 。即便KILL FTWRL会话也不行,除非KILL掉长时间的select操作才行。实际上flush table也会存在这种阻塞情况。
长时间的commit(如大事务提交)也会阻塞FTWRL,因为FTWRL需要获取COMMIT的S锁,而commit语句会对commit持有IX(MDL_INTENTION_EXCLUSIVE)锁,根据兼容矩阵不兼容。
(2)阻塞什么
FTWRL会阻塞DDL\\DML\\FOR UPDATE操作,阻塞点为 GLOBAL级别 的S锁,等待为:Waiting for global read lock 。
FTWRL会阻塞commit操作,阻塞点为COMMIT的S锁,等待为Waiting for commit lock 。
FTWRL不会阻塞SELECT操作,因为SELECT不会在GLOBAL级别上锁。
最后提醒一下很多备份工具都要执行FTWRL操作,包含mysqldump和5.7的xtrabackup ,一定要注意它的阻塞/被阻塞场景和特殊场景,当然xtrabackup 8.0有所改善,我们后面进行分析。
三、慢查询对FTWRL的记录方式
通常来讲DML(SELECT FOR UPDATE)和SELECT都会阻塞FTWRL,具体参见上面,而且我们知道这都是MDL LOCK阻塞。
在以往的慢查询认知中,MDL LOCK阻塞是计入到慢查询的LOCK time,但是FTWRL却不一样。因为FTWRL不会过接口mysql_lock_tables,因此MDL LOCK阻塞时间不会被慢查询记录,正常的语句关于慢查询的部分大概如下:
1、语句开始, 记录开始时间点为 X
2、获取MDL LOCK -> 正常语句如果本处超时(超过lock_wait_timeout)直接退出,也不会记录到下面一步记录的lock time时间中,因此lock time为0。
3、上MySQL层锁(比如MyISAM,记录lock time时间差量(1-3的时间差量Y)
4、优化器优化语句。
5、执行器开始执行语句,与InnoDB层交互, 如果每行需要等待InnoDB行锁,记录每次获取的lock time时间差量(第5步的每次等待InnoDB行锁的时间差量综合为Y)
6、语句结束,触发记录慢查询接口,并且获取当前时间点为(Z)判定记录慢查询如下。
如果(Z-X)-Y > 慢查询设置的时间则需要记录
也就是慢查询 query time:Z-X lock time为:Y
需要注意的是语句异常结束也会记录慢查询。但是FTWRL不记录Y这个时间,因此慢查询中对于FTWRL 统计的方式变为了(Z-X),也就是它执行了多久就是多久,且lock time为0。
超时(lock_wait_timeout设置为120)
# Time: 2022-05-04T16:26:35.226862+08:00
# User@Host: root[root] @ localhost [] Id: 10534
# Query_time: 120.004726 Lock_time: 0.000000 Rows_sent: 0 Rows_examined: 0
SET timestamp=1651652675;
flush table with read lock;
kill FTWRL
# Time: 2022-05-04T16:27:22.215598+08:00
# User@Host: root[root] @ localhost [] Id: 10534
# Query_time: 30.727657 Lock_time: 0.000000 Rows_sent: 0 Rows_examined: 0
SET timestamp=1651652811;
flush table with read lock;上面两个例子表明了这一点,我们注意到Lock_time为0。
还需要注意的是如果正常语句遇到lock_wait_timeout超时记录的慢查询的Lock_time也是0,原因一致(不过接口mysql_lock_tables),如下:
# Time: 2022-05-06T11:06:29.665024Z
# User@Host: root[root] @ localhost [] Id: 257
# Schema: test Last_errno: 1205 Killed: 0
# Query_time: 120.004564 Lock_time: 0.000000 Rows_sent: 0 Rows_examined: 0 Rows_affected: 0
# Bytes_sent: 67
SET timestamp=1651835189;
select * from testup11;可以看到这是一个SELECT由于Waiting for table flush等待超时,但是语句Lock_time为0,执行时间大约为120秒,也就是超时时间(lock_wait_timeout设置为120)。
四、lock instance for backup
这个操作主要阻塞的是DDL操作,包含不限于如下一些常见的操作:
CREATE_TABLE、CREATE_INDEX、ALTER_TABLE、TRUNCATE、DROP_TABLE、LOAD、CREATE_DB 、DROP_DB、ALTER_DB、RENAME_TABLE、DROP_INDEX、CREATE_VIEW、DROP_VIEW、CREATE_TRIGGER、DROP_TRIGGER、CREATE_EVENT、ALTER_EVENT、DROP_EVENT、IMPORT、RENAME_USER、DROP_USER、ALTER_USER、GRANT、REVOKE、GRANT_ROLE、REVOKE_ROLE、DROP_ROLE、CREATE_ROLE、OPTIMIZE、CREATE_FUNCTION、CREATE_PROCEDURE、DROP_PROCEDUR、DROP_FUNCTION、ALTER_PROCEDURE、ALTER_FUNCTION、REPAIR、ANALYZE、ALTER_TABLESPACE
我也随意测试了一些操作,确实都会被阻塞。
从内部来看,实际上这个操作的功效依然是通过MDL LOCK的实现的,其策略为m_scoped_lock_strategy,那么从scoped策略的兼容性来看,如下:
对于lock instance for backup本身而言,实际上是做了如下操作:
Sql_cmd_lock_instance::execute
->acquire_exclusive_backup_lock
->acquire_mdl_for_backup
获取的MDL LOCK为 MDL_key::BACKUP_LOCK+MDL_SHARED(S)看起来 MDL_key::BACKUP_LOCK的锁类型只会是MDL_SHARED(S)或者MDL_INTENTION_EXCLUSIVE(IX),因为acquire_mdl_for_backup里有断言:
DBUG_ASSERT(mdl_type == MDL_SHARED || mdl_type == MDL_INTENTION_EXCLUSIVE);对于上面提到的会被阻塞的这些操作,则是在响应的地方加入了获取 MDL_key::BACKUP_LOCK+MDL_INTENTION_EXCLUSIVE(IX)。
根据兼容矩阵,S和IX并不兼容,但是IX和IX之间是兼容的,因此只要不执行lock instance for backup操作,则不会有任何影响。
对于用户而言会发现processlist中出现Waiting for backup lock字样则为这样的阻塞。测试如下:
mysql> show processlist;
+----+------+-----------+---------+---------+------+-------------------------+-------------------+
| Id | User | Host | db | Command | Time | State | Info |
+----+------+-----------+---------+---------+------+-------------------------+-------------------+
| 11 | root | localhost | testpri | Query | 4 | Waiting for backup lock | OPTIMIZE table t1 |
| 12 | root | localhost | t10 | Sleep | 175 | | NULL |
| 13 | root | localhost | testpri | Query | 0 | init | show processlist |当然了,既然是MDL LOCK,它同样受到参数lock_wait_timeout参数的影响。比如我这里的操作为OPTIMIZE如下:
mysql> OPTIMIZE table t1;
+------------+----------+----------+--------------------------------------------------------+
| Table | Op | Msg_type | Msg_text |
+------------+----------+----------+--------------------------------------------------------+
| testpri.t1 | optimize | Error | Lock wait timeout exceeded; try restarting transaction |
| testpri.t1 | optimize | status | Operation failed |
+------------+----------+----------+--------------------------------------------------------+
2 rows in set (2 min 0.01 sec)需要的注意的这个锁并不会阻塞任何DML和SELECT操作(即便是MyISAM表也不会阻塞DML操作),但是保护了元数据的正确性。如果要获取一致的数据我们就需要额外的机制也就是下面谈到的pfs.log_status。
五、pfs.log_status 访问的方式
我们先看看它包含了哪些信息:
mysql> select * from performance_schema.log_status\\G
*************************** 1. row ***************************
SERVER_UUID: b69a6373-3a03-11ec-add6-000c29948de2
LOCAL: "gtid_executed": "b69a6373-3a03-11ec-add6-000c29948de2:1-73,\\nd179f8f4-728f-11eb-b96e-000c2956fa4f:1-42", "binary_log_file": "mysql-bin.000016", "binary_log_position": 236
REPLICATION: "channels": ["channel_name": "group_replication_applier", "relay_log_file": "relay-bin-group_replication_applier.000066", "relay_log_position": 152, "channel_name": "group_replication_recovery", "relay_log_file": "relay-bin-group_replication_recovery.000008", "relay_log_position": 156]
STORAGE_ENGINES: "InnoDB": "LSN": 7109536475, "LSN_checkpoint": 7109536475
1 row in set (8 min 14.10 sec)备注:这里之所以耗时8分多钟,是因为在debug模式下跑的,实际不需要。
其中最重要的就是GTID信息,binlog的pos,这个是在我们恢复后需要的。当然我们看到还包含了主从通道的relay log信息,以及InnoDB层当前LSN信息和CHECKPOINT LSN信息等。
在完成这个功能上看,几乎是复用了现有的mutex,步骤总共有好几步,下面是重要的一些步骤:
加入了一个Log_resource类,那么将GTID信息/binlog信息/relay log信息/LSN信息 都虚拟成一种资源。
新增了多个继承类继承于Log_resource类,也就是上面的提到的分别为,并且他们都完成了Log_resource父类的虚函数,如下
Log_resource_mi_wrapper (relay log信息)
Log_resource_mi_wrapper::lock Log_resource_mi_wrapper::unlock Log_resource_mi_wrapper::collect_info
Log_resource_binlog_wrapper(binlog信息)
Log_resource_binlog_wrapper::lock Log_resource_binlog_wrapper::unlock Log_resource_binlog_wrapper::collect_info
Log_resource_gtid_state_wrapper(GTID信息)
Log_resource_gtid_state_wrapper::lock Log_resource_gtid_state_wrapper::unlock Log_resource_gtid_state_wrapper::collect_info
Log_resource_hton_wrapper(引擎层信息)
Log_resource_hton_wrapper::lock Log_resource_hton_wrapper::unlock Log_resource_hton_wrapper::collect_info
这里可以看到还是很有条理的。
3. 新增一个mutex LOCK_collect_instance_log 用于防止并发的访问pfs.log_status信息,同时新增一个访问接口table_log_status::make_row,如果在这个函数下面,就能清楚的访问的步骤大概为
加LOCK_collect_instance_log 锁
将所有资源,也就是上面4个资源放到一个叫做resources的list容器
依次调用每个资源的***::lock,先加锁,避免产生不一致的数据
依次拿到需要的信息,这里因为前面各个资源都加锁了,因此获取的信息是一致的。
依次调用每个资源的***::unlock,解锁。
解开LOCK_collect_instance_log 锁
这样我们就可以发现,获取所有的信息的时候,实际上它们是在所有信息都加锁的情况下拿到了,是一致的,全部获取完成后才开始解锁。
InnoDB引擎层实现lock/unlock/collect_info,对应了如下的调用 -> innobase_collect_hton_log_info -> innobase_unlock_hton_log -> innobase_lock_hton_log
实际上就是来获取InnoDB层的当前LSN信息和CHECKPOINT LSN信息。那么下面我们简单分析一下具体是如何做的,这里抛开relay log的信息,这貌似不太重要。
六、pfs.log_status 重要信息获取的代价
binlog位点信息
小于8.0.27,获取位点的信息主要加锁为LOCK_log,这是flush\\fsync\\commit,三阶段中第一阶段上的锁,通过加这个锁能够保证阻塞提交,获取到稳定的binlog位点。
binlog_cache_data::flush
...
->MYSQL_BIN_LOG::Binlog_ofile::write(这里增加binlog的位点信息)GTID信息
获取GTID信息主要是在flush\\fsync\\commit,三阶段中第三阶段上的锁,这个时候主要防止有GTID新加入到gtid_executed,这样就能获得稳定的GTID信息了,需要注意的GTID的生成是在flush阶段,但是加入到gtid_executed是在commit阶段。而加锁的锁为 global_sid_lock,对于加入到gtid_executed会上此锁。
MYSQL_BIN_LOG::process_commit_stage_queue
->Gtid_state::update_commit_group (加global_sid_lock)
->Gtid_state::update_gtids_impl_own_gtid (加入gtid_execute)InnoDB 层的信息
这个信息包含2个如下:
当前LSN信息:
这个信息和show engine中Log sequence number 一致,主要是在MTR提交的时候增加的LSN,用于判断是否有足够的log buffer空间
->mtr_t::commit
->mtr_t::Command::execute
->log_buffer_reserve
->log_buffer_s_lock_enter_reserve加锁为log_buffer_x_lock_enter,而在MTR提交的时候需要log_buffer_s_lock_enter_reserve,这两个函数都比较复杂涉及的东西也比较多,没有仔细学习。但是可以清楚的是阻塞了MTR的提交操作,也就是写入不能写到log_buffer,这样来保证了当前LSN信息的稳定。
CHECKPOINT LSN:
本信息和show engine中的Last checkpoint at一致的,加锁同CKPT线程使用的是同一个也就是log_t::checkpointer_mutex(log_checkpointer_mutex_enter(log)),那么保证了CKPT LSN信息的稳定。
我们这里看到实际上访问pfs.log_status 不是完全没有代价的,只是相对于FTWRL来讲,通过细化达到了较小的代价。至少这里看有如下代价:
InnoDB层不能产生新的REDO,这会阻塞数据的修改操作。
MySQL层不能提交任何事务,这会阻塞所有正在提交的事务。
相对于FTWRL,table share不会涉及到释放和加载,因此SELECT是不会受到影响的。
如果不涉及到大事务,获取log_status的操作应该是比较快的,因为大事务的提交实在是有点慢。
如果在flush阶段需要较多的时间将binlog从临时文件拷贝到binlog,这个时间就需要持有LOCK_log锁。
七、一个非常重要的BUG
bug如下:
https://bugs.mysql.com/bug.php?id=102175
注意这个BUG同样导致xtrabackup出现问题,如下:
https://jira.percona.com/browse/PS-7873
本BUG导致的是访问pfs.log_status的时候发现GTID信息落后于binlog信息,我觉得本BUG足以让数据恢复出现故障,非常重要。
我们使用bug描述中的案例,测试者加了一个sleep(1)在Gtid_state::update_commit_group获取global_sid_lock之后,拖长GTID信息加入到gtid_executed的过程,很容易就重现了。如下:
mysql> select LOCAL from performance_schema.log_status\\G
*************************** 1. row ***************************
LOCAL: "gtid_executed": "0f9b691a-612b-11eb-bbf5-74d83e29c093:1-31", "binary_log_file": "binlog.000001", "binary_log_position": 1932788
1 row in set (3.29 sec)
SHOW BINLOG EVENTS;
| binlog.000001 | 1932313 | Gtid | 1 | 1932392 | SET @@SESSION.GTID_NEXT= '0f9b691a-612b-11eb-bbf5-74d83e29c093:54'|
| binlog.000001 | 1932392 | Query | 1 | 1932467 | BEGIN|
| binlog.000001 | 1932467 | Table_map | 1 | 1932532 | table_id: 106 (test.sbtest1)|
| binlog.000001 | 1932532 | Write_rows | 1 | 1932757 | table_id: 106 flags: STMT_END_F|
| binlog.000001 | 1932757 | Xid | 1 | 1932788 | COMMIT /* xid=62 */这里我们发现GTID信息为1-31,binlog信息为1932788,但是通过解析binlog发现,binlog位点1932788的gtid为54。很显然这是有问题,如果这个时候我们用这个gtid信息去做主从那么肯定是失败的。
那么这个BUG如何出现的呢?实际上通过前文的描述我们来画一个简单的示意图如下: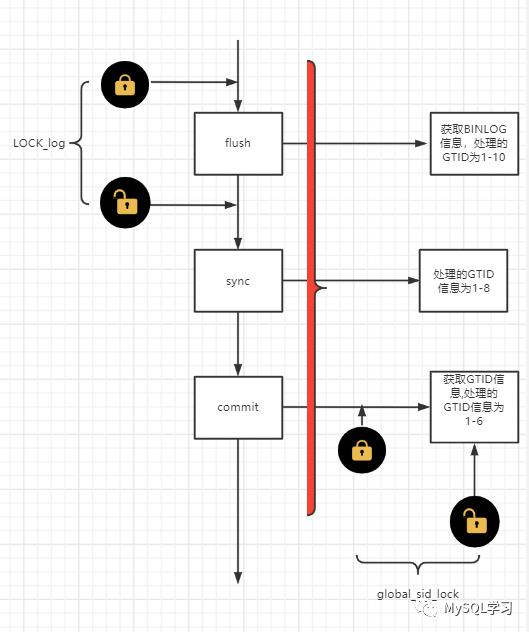
但是如图,比如当前处理到了1-10这个GTID的pos,然后解锁LOCK_log,然后log_status拿到了,而对于commit阶段处理的信息可能还在1-6这个GTID范围,一旦加入了gtid_execute,global_sid_lock就释放了,那么log_status也拿到了global_sid_lock锁,接着开始获取GTID信息和binlog信息,那么这个时候获取的信息GTID信息是1-6,binlog信息是1-10。
Percona Server 8.0.27中修复了这个问题(MySQL官方版本还未修复),加大了锁的粒度,这个红色框框都加锁了,也就是加大了加锁的访问包含了LOCK_sync /LOCK_commit,这样一来整个提交操作三阶段都会被包裹,同时global_sid_lock的获取也在其中,只要有事务正在这个流程中就必须阻塞pfs.log_status信息的获取,当然也就解决了这个问题。
但是这也稍微加大了log_status访问的代价,因为我们知道fsync实际上也是比较耗时的一个步骤,特别是IO压力较高的情况下,但是不管这么说都比FTWRL的影响小了很多。
八、xtrabackup 8.0.28和新的备份锁
这里测试使用的是xtrabkacup 8.0.28 + MySQL 8.0.28,需要注意的是8.0 mysqldump还是用的FTWRL(开genernal log看的^_^)。
原则上xtrabackup使用上面的提到的新的备份锁,但是这有一个前提就是不能有MyISAM的表,当然默认情况下8.0不会有MyISAM的表,但是是可以人为建立的。
如果有MyISAM的表最后依旧会使用了FTWRL,这个可以开general log来看,稍微看看语句的输出部分,就会发现xtrabackup一开始就在做检测如下:
char *count_str =
read_mysql_one_value(mysql_connection,
"SELECT COUNT(*) FROM information_schema.tables "
"WHERE engine = 'MyISAM' OR engine = 'RocksDB'");
unsigned long long count = strtoull(count_str, nullptr, 10);
have_unsafe_ddl_tables = (count > 0); //如果存在mysiam表记录标记
包含MyISAM表的general log重要输出:
2022-05-08T21:18:36.546024+08:00 31 Query SELECT COUNT(*) FROM information_schema.tables WHERE engine = 'MyISAM' OR engine = 'RocksDB'
2022-05-08T21:18:36.547809+08:00 31 Query LOCK INSTANCE FOR BACKUP(开始就加)
2022-05-08T21:18:36.550288+08:00 31 Query SELECT CONCAT(table_schema, '/', table_name), engine FROM information_schema.tables WHERE engine NOT IN ('MyISAM', 'InnoDB', 'CSV',
'MRG_MYISAM', 'ROCKSDB') AND table_schema NOT IN ( 'performance_schema', 'information_schema', 'mysql')
2022-05-08T21:18:47.049757+08:00 31 Query FLUSH NO_WRITE_TO_BINLOG TABLES
2022-05-08T21:18:47.052098+08:00 31 Query FLUSH TABLES WITH READ LOCK(最后备份myisam前加)
2022-05-08T21:18:47.254181+08:00 31 Query FLUSH NO_WRITE_TO_BINLOG BINARY LOGS
2022-05-08T21:18:47.258193+08:00 31 Query SELECT server_uuid, local, replication, storage_engines FROM performance_schema.log_status(最后获取一致性位点)
2022-05-08T21:18:47.264598+08:00 31 Query FLUSH NO_WRITE_TO_BINLOG ENGINE LOGS
2022-05-08T21:18:48.268716+08:00 31 Query UNLOCK INSTANCE
2022-05-08T21:18:48.268877+08:00 31 Query UNLOCK TABLES我们从原理上其实也能理解,如果有MyISAM的表不管是lock instance for backup还是pfs.log_status都是无法阻塞DML的,因为pfs.log_status只是获取一个一致性的点而已,但是备份MyISAM表的这段时间的redo是没有,他们是不可能达到一致的。
当然没有MyISAM表的情况就不会有FTWRL,这样就使用到了我们这里分析的新的备份锁,可以自己开一下general log看看。
在MySQL 8.0.27之前,xtrabakcup使用pfs.log_status就可能触发我们上面说的BUG。这是需要注意的是,我们如果恢复的GTID和xtrabackup 记录在文件中的GTID有出入,则以恢复后的GTID为准。这点是和MySQL 5.7完全不一样的,5.7恢复后的GTID因为受到gtid_executed表切换更新的影响,而初启动的时候始化又依赖gtid_executed表,所以可能大大落后于文件中的GTID,我们需要以xtrabackup的文件为准。
最后就是我们发现LOCK INSTANCE FOR BACKUP是备份一开始就持有的,我们很容易就能模拟出在备份期间执行DDL会出现如下结果,如果仅仅是备份最后加的,不可能这么容易就能模拟出来。
+----+-----------------+-----------+-------+---------+------+-------------------------+------------------+
| Id | User | Host | db | Command | Time | State | Info |
+----+-----------------+-----------+-------+---------+------+-------------------------+------------------+
| 6 | event_scheduler | localhost | NULL | Daemon | 8576 | Waiting on empty queue | NULL |
| 36 | root | localhost | otest | Query | 7 | Waiting for backup lock | drop table iii |
| 37 | root | localhost | NULL | Query | 0 | init | show processlist |
| 38 | root | localhost | NULL | Sleep | 15 | | NULL |
| 40 | root | localhost | NULL | Sleep | 8 | | NULL |
+----+-----------------+-----------+-------+---------+------+-------------------------+------------------+当然具体的xtrabackup流程我并没有研究,仅从general log和备份日志来看的。
以上。。。
《深入浅出MGR》视频课程
戳此小程序即可直达B站
https://www.bilibili.com/medialist/play/1363850082?business=space_collection&business_id=343928&desc=0
文章推荐:
想看更多技术好文,点个“在看”吧!
以上是关于MySQL 8.0 BACKUP LOCK浅析及其在xtrabackup的应用(深度好文)的主要内容,如果未能解决你的问题,请参考以下文章