爬虫-从入门到入狱
Posted vlan911
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了爬虫-从入门到入狱相关的知识,希望对你有一定的参考价值。
前言:
爬虫理论上是被禁止的,这里只讲方法,so,希望大家遵守法律法规,不要去爬敏感网站的数据,不要从事贩卖国家机密相关的相关事宜等。
此次涉及到的知识点如下:
- 利用json库截取json指定字符串
- 利用argparse库实现参数化调用
- 利用pymysql库实现数据库操作
- 数据库长连接的使用
pymysql库的使用
pymysql的库作用就是联动mysql数据库,我们这里需要知道的是如何创建数据库连接,如何创建游标对象,如何执行sql语句与事务的提交
首先这里介绍的是连接数据库的长连接的使用,一开始笔者使用连接数据库的方式是短链接。
我们实现与数据库交互的时候,需要先连接数据库,而后关闭连接,这个过程在断开的时候是会产生一个tcp timeout的时间的,如果大家插入数据库、与数据库交互的次数并不多,那当然是不受影响的。
但是大家如果做爬虫,需要批量的操作数据库的时候,若是采用短连接,每次连接数据库关闭数据库就都会产生一个tcp timeout的动作,这样的话可能会造成一个泛洪的效果,意外的造成了拒绝服务攻击。
示例代码如下:
import pymysql
import time
def short():
n=0
while n <= 20:
#连接数据库
db_conn = pymysql.connect(host='192.168.xx.xx', user='root', passwd='xx', port=3306, db='xx')
# 创建游标对象
cur = db_conn.cursor()
# 执行sql语句
try:
# 执行sql语句
sql='insert into user (user,id) values (111,222);'
cur.execute(sql)
# 事物提交
db_conn.commit()
# 断开连接
cur.close()
db_conn.close()
except Exception as err:
print("sql语句执行错误", err)
db_conn.rollback() # 数据库回滚操作
time.sleep(2)
n=n+1
short()
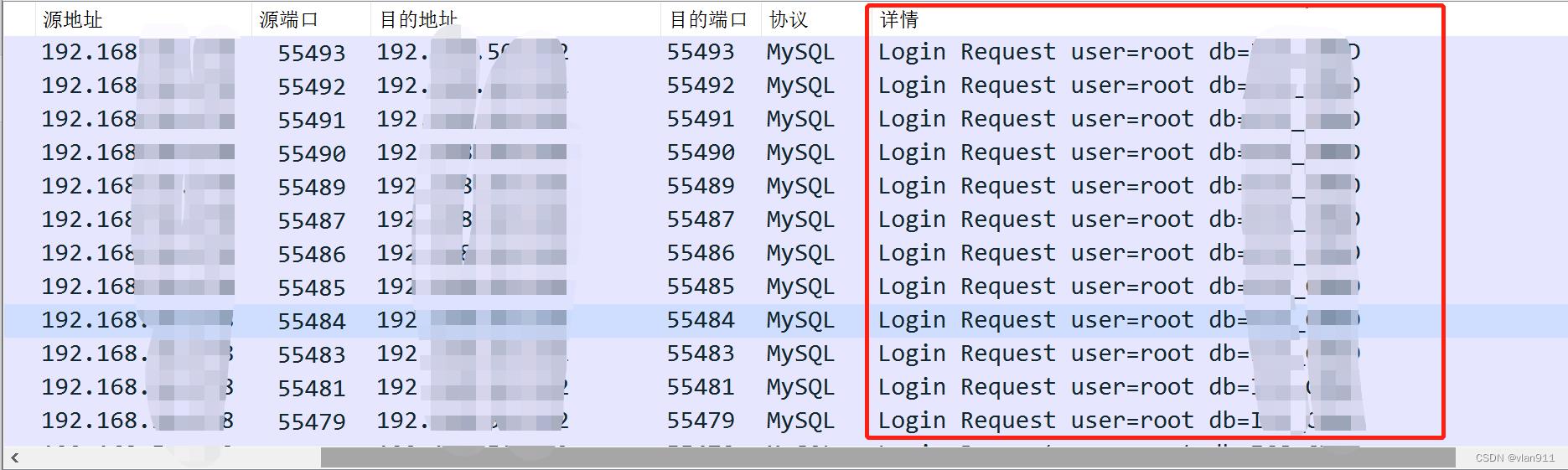
此时执行20次重复的插入动作,每次插入前都会先连接数据库然后再断开,观察主机的状态以及数据包
首先就是在请求的时候会出现大量的连接状态 time-wait,这个是在本机看到的,而不是在数据库服务器

wireshark产生大量的连接记录
当我们使用长链接的时候,此时的示例代码以及连接状态如下
import pymysql
import time
db_conn = pymysql.connect(host='192.168.xx.xxx', user='root', passwd='xxx', port=3306, db='xxx')
cur = db_conn.cursor()
def test_connection():
try:
db_conn.ping()
except:
db_conn = pymysql.connect(host='192.168.xx.xxx', user='root', passwd='xxx', port=3306, db='xxx')
return db_conn
def long():
n=0
db_conn = test_connection()
while n <= 20:
try:
# 执行sql语句
sql='insert into user (user,id) values (111,222);'
cur.execute(sql)
# 事物提交
db_conn.commit()
except Exception as err:
print("sql语句执行错误", err)
db_conn.rollback()
time.sleep(2)
n=n+1
long()

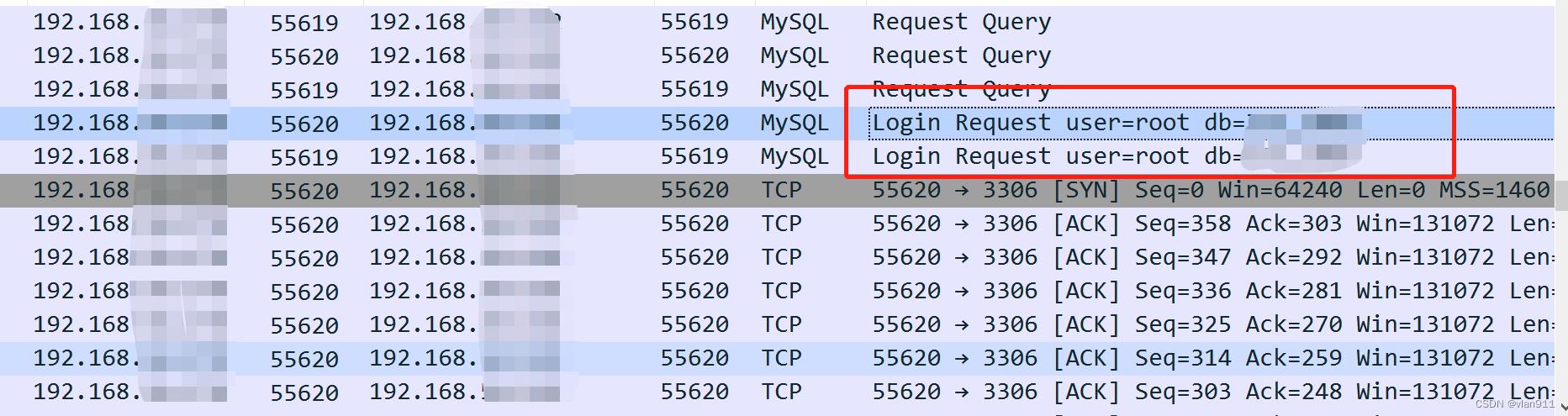
wireshark数据包流量如下
argparse 库的使用
argparse是python用于解析命令行参数和选项的标准模块,用于代替已经过时的optparse模块。argparse模块的作用是用于解析命令行参数
示例代码:
import argparse
parser = argparse.ArgumentParser(description='api help') #创建解析器对象ArgumentParser
parser.add_argument('-p','--pid', help='请输入1/2/3/4',default=' ') #用来指定程序需要接受的命令参数
args=parser.parse_args() #参数实例化,将parser参数传入args
pid=args.pid
str=("这是 %s" % pid)
print(str)
运行结果:
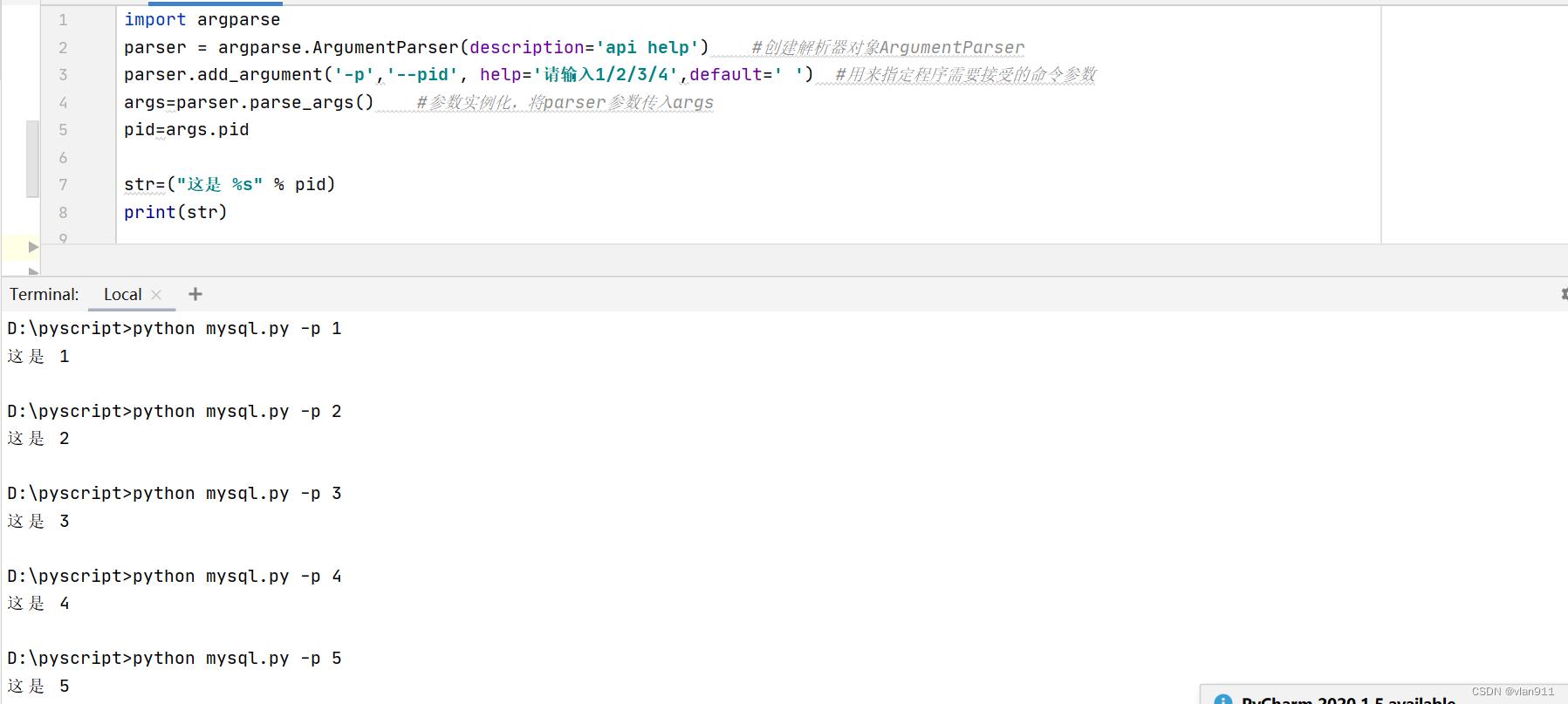
这个时候参数就可选了
json、requests库的使用
requests库无需多说,用来模拟http请求;
json库在这里则是用来返回json数据中的某个数据时使用
首先我们需要收集id参数,当页面返回的数据为json时,我们如何收集?
如下图,此图为返回的json数据的树状图

此时打开[data][page][records][0]
返回的详细数据如下
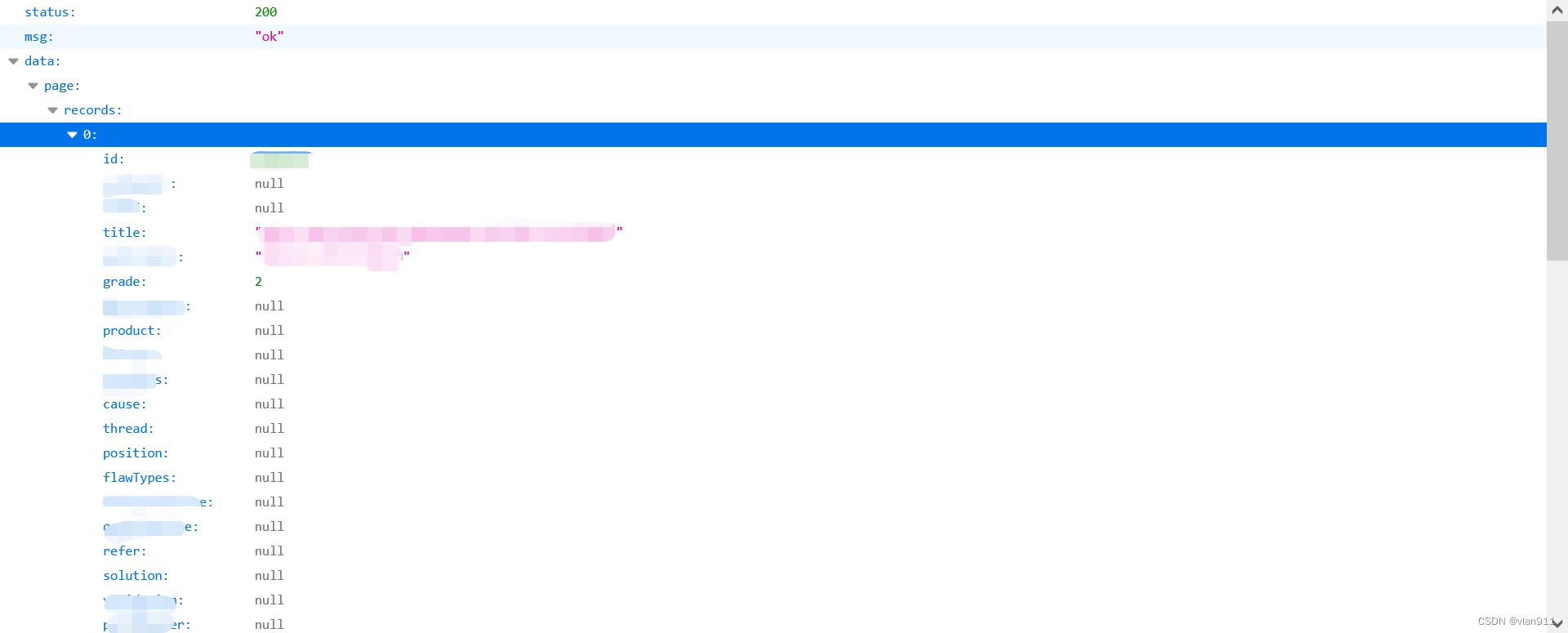
由第一张图我们可以知道,返回0-9条数据,我们需要获取这0-9条数据所有的id参数,那么应该如何快速获取呢?
示例代码如下
# encoding: utf-8 #使用utf-8编码
import requests
import json
token="xxx" #全局变量
def _json():
url = "https://xxx.cn/xxx"
header =
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (Khtml, like Gecko) Chrome/90.0.4430.93 Safari/537.36",
"Content-Type": "application/x-www-form-urlencoded",
"X-Token": token
try:
response = requests.get(url, headers=header, verify=False, timeout=10)
text = response.text
s = json.loads(text)
if 'id' in text:
n = 0
while n <= 10:
id = (s['data']['page']['records'][n]['id']) #获取所有的id参数
print(str(id))
n=n+1
else:
print("数据未更新")
except Exception as e:
print("[" + url + "]" + "error", format(e))
_json()
执行结果如下:

提取数据直接入库,并生成后期对比log文件
当我们学会使用以上三个小demo后,我们按需求将id直接入库并生成log文件做后期对比,示例代码如下
前言:
爬虫理论上是被禁止的,这里只讲方法,so,希望大家遵守法律法规,不要去爬敏感网站的数据,不要从事贩卖国家机密相关的相关事宜等。
此次涉及到的知识点如下:
- 利用json库截取json指定字符串
- 利用argparse库实现参数化调用
- 利用pymysql库实现数据库操作
- 数据库长连接的使用
0x01 pymysql库的使用
pymysql的库作用就是联动mysql数据库,我们这里需要知道的是如何创建数据库连接,如何创建游标对象,如何执行sql语句与事务的提交
首先这里介绍的是连接数据库的长连接的使用,一开始笔者使用连接数据库的方式是短链接。
我们实现与数据库交互的时候,需要先连接数据库,而后关闭连接,这个过程在断开的时候是会产生一个tcp timeout的时间的,如果大家插入数据库、与数据库交互的次数并不多,那当然是不受影响的。
但是大家如果做爬虫,需要批量的操作数据库的时候,若是采用短连接,每次连接数据库关闭数据库就都会产生一个tcp timeout的动作,这样的话可能会造成一个泛洪的效果,意外的造成了拒绝服务攻击。
示例代码如下:
import pymysql
import time
def short():
n=0
while n <= 20:
#连接数据库
db_conn = pymysql.connect(host=‘192.168.xx.xx’, user=‘root’, passwd=‘xx’, port=3306, db=‘xx’)
# 创建游标对象
cur = db_conn.cursor()
# 执行sql语句
try:
# 执行sql语句
sql=‘insert into user (user,id) values (111,222);’
cur.execute(sql)
# 事物提交
db_conn.commit()
# 断开连接
cur.close()
db_conn.close()
except Exception as err:
print(“sql语句执行错误”, err)
db_conn.rollback() # 数据库回滚操作
time.sleep(2)
n=n+1
short()
此时执行20次重复的插入动作,每次插入前都会先连接数据库然后再断开,观察主机的状态以及数据包
首先就是在请求的时候会出现大量的连接状态 time-wait,这个是在本机看到的,而不是在数据库服务器
wireshark产生了大量的tcp连接记录
当我们使用长链接的时候,此时的示例代码以及连接状态如下
import pymysql
import time
db_conn = pymysql.connect(host=‘192.168.xx.xxx’, user=‘root’, passwd=‘xxx’, port=3306, db=‘xxx’)
cur = db_conn.cursor()
def test_connection():
try:
db_conn.ping()
except:
db_conn = pymysql.connect(host=‘192.168.xx.xxx’, user=‘root’, passwd=‘xxx’, port=3306, db=‘xxx’)
return db_conn
def long():
n=0
db_conn = test_connection()
while n <= 20:
try:
# 执行sql语句
sql=‘insert into user (user,id) values (111,222);’
cur.execute(sql)
# 事物提交
db_conn.commit()
except Exception as err:
print(“sql语句执行错误”, err)
db_conn.rollback()
time.sleep(2)
n=n+1
long()
wireshark数据包流量如下
0x02 argparse 库的使用
argparse是python用于解析命令行参数和选项的标准模块,用于代替已经过时的optparse模块。argparse模块的作用是用于解析命令行参数
示例代码:
import argparse
parser = argparse.ArgumentParser(description=‘api help’) #创建解析器对象ArgumentParser
parser.add_argument(‘-p’,‘–pid’, help=‘请输入1/2/3/4’,default=’ ') #用来指定程序需要接受的命令参数
args=parser.parse_args() #参数实例化,将parser参数传入args
pid=args.pid
str=(“这是 %s” % pid)
print(str)
运行结果:
这个时候参数就可选了
0x03 json、requests库的使用
requests库无需多说,用来模拟http请求;
json库在这里则是用来返回json数据中的某个数据时使用
首先我们需要收集id参数,当页面返回的数据为json时,我们如何收集?
如下图,此图为返回的json数据的树状图
此时打开[data][page][records][0]
返回的详细数据如下
由第一张图我们可以知道,返回0-9条数据,我们需要获取这0-9条数据所有的id参数,那么应该如何快速获取呢?
示例代码如下
encoding: utf-8 #使用utf-8编码
import requests
import json
token=“xxx” #全局变量
def _json():
url = “https://xxx.cn/xxx”
header =
“User-Agent”: “Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36”,
“Content-Type”: “application/x-www-form-urlencoded”,
“X-Token”: token
try:
response = requests.get(url, headers=header, verify=False, timeout=10)
text = response.text
s = json.loads(text)
if ‘id’ in text:
n = 0
while n <= 10:
id = (s[‘data’][‘page’][‘records’][n][‘id’]) #获取所有的id参数
print(str(id))
n=n+1
else:
print(“数据未更新”)
except Exception as e:
print(“[” + url + “]” + “error”, format(e))
_json()
执行结果如下:
提取数据直接入库,并生成后期对比log文件
当我们学会使用以上三个小demo后,我们按需求将id直接入库并生成log文件做后期对比,示例代码如下
# encoding: utf-8 #使用utf-8编码
import requests
import json
import pymysql
import time
import argparse
import urllib3
urllib3.disable_warnings()
parser = argparse.ArgumentParser(description='api help') #创建解析器对象ArgumentParser
parser.add_argument('-p','--pid', help='请输入1/2/3/4',default=' ') #用来指定程序需要接受的命令参数
args=parser.parse_args() #参数实例化,将parser参数传入args
pid=args.pid
token="xxxx" #设置token全局变量
#建立数据库长连接
db_conn = pymysql.connect(host="192.168.xx.xxx", user="root", password="xxx", db="xxx",charset="utf8")
cursor = db_conn.cursor()
#建立数据库长链接,调用前判断数据库连接状态
dataday=(time.strftime('%Y-%m-%d',time.localtime(time.time()))) #年月日时间节点,用来保存文件名字
def test_connection():
try:
db_conn.ping()
except:
db_conn= pymysql.connect(host="192.168.xx.xxx", user="root", password="xxx", db="xxx",charset="utf8")
def _json():
url = "https://xxx/"
header =
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36",
"Content-Type": "application/x-www-form-urlencoded",
"X-Token": token
try:
response = requests.get(url, headers=header, verify=False, timeout=10)
text = response.text
s = json.loads(text)
if 'id' in text:
n = 0
test_connection()
cursor = db_conn.cursor()
while n <= 10:
id = (s['data']['page']['records'][n]['id']) #获取所有的id参数
print(str(id))
w = open(dataday + "_id.json", "a+")
w.write(str(id) + "\\n")
try:
# 执行sql语句
sql = ("insert into user (id) values ('%s');" % id )
cursor.execute(sql)
# 事物提交
db_conn.commit()
except Exception as err:
print("sql语句执行错误", err)
db_conn.rollback()
time.sleep(2)
n=n+1
else:
print("数据未更新")
except Exception as e:
print("[" + url + "]" + "error", format(e))
if __name__ == '__main__' :
_json()
运行结果:
这里没用上参数化,因为那个使用比较敏感,没有体现出来,但是大家只要知道如何去使用就可以了,比如说获取周更新、月更新都可以使用此方式,观察数据库变化

当前文件夹生成json格式文件,后续做对比使用


以上是关于爬虫-从入门到入狱的主要内容,如果未能解决你的问题,请参考以下文章