Keras深度学习实战——信用预测
Posted 盼小辉丶
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Keras深度学习实战——信用预测相关的知识,希望对你有一定的参考价值。
Keras深度学习实战(7)——信用预测
0. 前言
在金融服务行业中,某些客户的违约是导致收入损失的主要来源之一。但是,只有极少数客户会违约。因此,这一分类问题的关键在于识别稀有事件。
1. 任务与模型分析
1.1 数据集
在本节中,我们使用 Kaggle 中 Give Me Some Credit 数据集,其中包括 250000 个用户的历史数据,可以用于预测用户在未来两年内遇到财务困境的可能性,更新用户的信用评分,下载数据集后,可以看到其中包含用户年龄、收入、债务等信息:

1.2 信用预测任务分析
在本应用中,我们将分析在给定时间点跟踪客户收入、支出等属性的数据集,并尝试预测客户是否存在违约的可能性。作为企业,可能希望关注更可能违约的客户——为他们提供替代的付款方式或降低信用额度等。因此,我们用来预测客户违约的任务需求如下:
- 目标:以较高的概率识别更有可能违约的客户
- 衡量标准:将计算得到的测试数据集中违约概率最大的前
10%用户作为候选违约用户,查看两年后实际违约的客户数量,以此衡量模型性能。这是由于绝大多数用户都不会违约,我们的关键在于识别违约的用户,如果模型将所有用户均预测为不会违约,就可以获得很高的准确率,但是这样是没有实际意义的,因此我们不能仅仅考虑模型的准确率,而要进一步考察模型将用户预测为违约用户后,这些用户的实际违约状况
1.3 神经网络模型分析
我们计算每个用户违约概率的网络模型策略如下:
- 考虑所有用户的历史数据
- 构造可以用于识别可能违约客户的输入变量:
- 以收入/债务比 (
DebtRatio) 作为指示用户是否可能违约的主要指标 - 使用与之相似的其他一些变量
- 以收入/债务比 (
- 接下来,创建输出变量:
- 查看在成员未来两年内是否有严重违约行为 (
SeriousDlqin2yrs),以获取在未来两年内实际违约的成员
- 查看在成员未来两年内是否有严重违约行为 (
- 分类结果是二元变量,因此模型最小化二进制交叉熵损失
- 模型在输入层和输出层之间包含隐藏层
- 最后,计算测试数据集中违约概率最大的前
10%用户中实际违约的成员数量
我们假设测试数据具有代表性,可以评估其在训练时没有见到的数据集上的性能,即假定该模型在一个看不见的数据集上的性能可以很好地指示该模型在未来数据上的表现。
2. 使用神经网络实现信用预测
本节,我们将编写代码,实现上述神经网络模型。
- 导入相关的包和数据集:
import pandas as pd
# 读取下载的文件
data = pd.read_csv('cs-train.csv')
# 只需要使用指定列
data = data[['SeriousDlqin2yrs','age', 'DebtRatio', 'MonthlyIncome']]
我们已经在第 1 节中查看了数据集中用户包含的特征,这里我们只是用其中的一部分特征作为演示:用户两年后是否有重大违约情况 SeriousDlqin2yrs,用户年龄 age,收入/债务比 DebtRatio 以及每月收入MonthlyIncome。
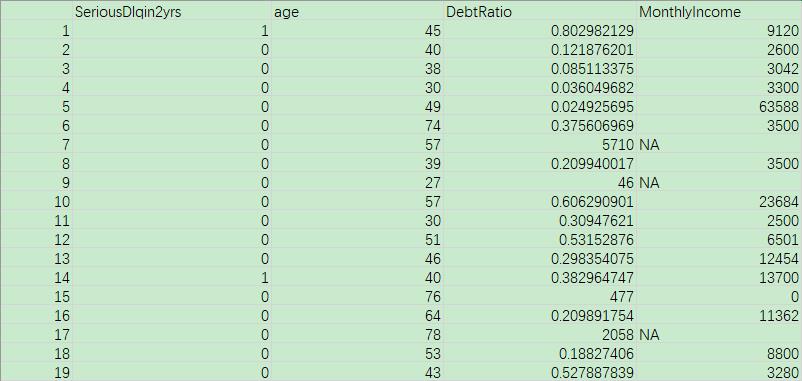
上图是原始数据集中变量的子集,SeriousDlqin2yrs 的变量是我们基于数据集中其余变量需要预测的输出变量。
- 查看汇总数据集以更好地理解变量:
print(data.describe())
数据汇总情况输出:
SeriousDlqin2yrs age DebtRatio MonthlyIncome
count 150000.000000 150000.000000 150000.000000 1.202690e+05
mean 0.066840 52.295207 353.005076 6.670221e+03
std 0.249746 14.771866 2037.818523 1.438467e+04
min 0.000000 0.000000 0.000000 0.000000e+00
25% 0.000000 41.000000 0.175074 3.400000e+03
50% 0.000000 52.000000 0.366508 5.400000e+03
75% 0.000000 63.000000 0.868254 8.249000e+03
max 1.000000 109.000000 329664.000000 3.008750e+06
查看输出后,可以观察到以下问题:
- 某些变量的范围较小 (
age),而某些变量的范围较大 (MonthlyIncome) - 某些变量缺失一些值 (
MonthlyIncome) - 某些变量具有异常值 (
DebtRatio)
- 接下来,我们纠正先前标记的所有问题,首先用变量的中位数代替变量中的缺失值:
vars = data.columns[1:]
import numpy as np
for var in vars:
data[var]= np.where(data[var].isnull(),data[var].median(),data[var])
除了第一个变量,因为它是我们要尝试预测的变量,然后将缺失值替换为该变量的中位数。
- 消除输入变量中的离群值:
for var in vars:
x=data[var].quantile(0.95)
data[var+"outlier_flag"]=np.where(data[var]>x,1,0)
data[var]=np.where(data[var]>x,x,data[var])
在前面的代码中,我们计算了每个变量的第 95 个百分位数并存入新变量 x 中,如果该行包含异常值,则使用一个标记位将其值设为 1,否则为 0。此外,我们将变量值的上限设置为原始值的第 95 个百分位数。
Note:
n
n
n 个数据按大小排列,处于
p
%
p\\%
p% 位置的值称第
p
p
p 百分位数。
- 最后,我们限制
DebtRatio的范围为[0, 1]:
data['DebtRatio_outlier'] = np.where(data['DebtRatio']>1, 1, 0)
data['DebtRatio'] = np.where(data['DebtRatio']>1, 1, data['DebtRatio'])
- 将所有变量归一化为相同的标度,以得到介于
0和1之间的值:
for var in vars:
data[var]= data[var]/data[var].max()
在前面的代码中,通过将每个输入变量值除以输入变量列的最大值,我们将所有变量限制为相似范围,即 [0, 1]。
- 创建输入和输出数据集:
x = data.iloc[:, 1:]
y = data['SeriousDlqin2yrs']
- 将数据集分为训练和测试数据集:
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3)
使用 train_test_split 方法将输入和输出数组拆分为训练和测试数据集,其中测试数据集占数据总数的 30%。
- 创建数据集之后,定义神经网络模型,如下所示:
model = Sequential()
model.add(Dense(1000, input_dim=x_train.shape[1], activation='relu'))
model.add(Dense(1, activation='sigmoid'))
model.summary()
该模型的结构信息如下:
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense (Dense) (None, 1000) 8000
_________________________________________________________________
dense_1 (Dense) (None, 1) 1001
=================================================================
Total params: 9,001
Trainable params: 9,001
Non-trainable params: 0
_________________________________________________________________
模型将输入变量连接到具有 1000 个隐藏单元的隐藏层。
- 编译模型,使用二进制交叉熵,因为输出变量只有两个类,将指定优化器为
adam优化:
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['acc'])
- 拟合模型:
history = model.fit(x_train,
y_train,
validation_data=(x_test, y_test),
epochs=50,
batch_size=512,
verbose=1)
训练和测试损失的变化,以及随着 epoch 的推移准确率的变化如下:
from matplotlib import pyplot as plt
history_dict = history.history
loss_values = history_dict['loss']
val_loss_values = history_dict['val_loss']
acc_values = history_dict['acc']
val_acc_values = history_dict['val_acc']
epochs = range(1, len(val_loss_values) + 1)
plt.subplot(211)
plt.plot(epochs, loss_values, marker='x', label='Traing loss')
plt.plot(epochs, val_loss_values, marker='o', label='Test loss')
plt.title('Training and test loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.subplot(212)
plt.plot(epochs, acc_values, marker='x', label='Training accuracy')
plt.plot(epochs, val_acc_values, marker='o', label='Test accuracy')
plt.title('Training and test accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend()
plt.show()
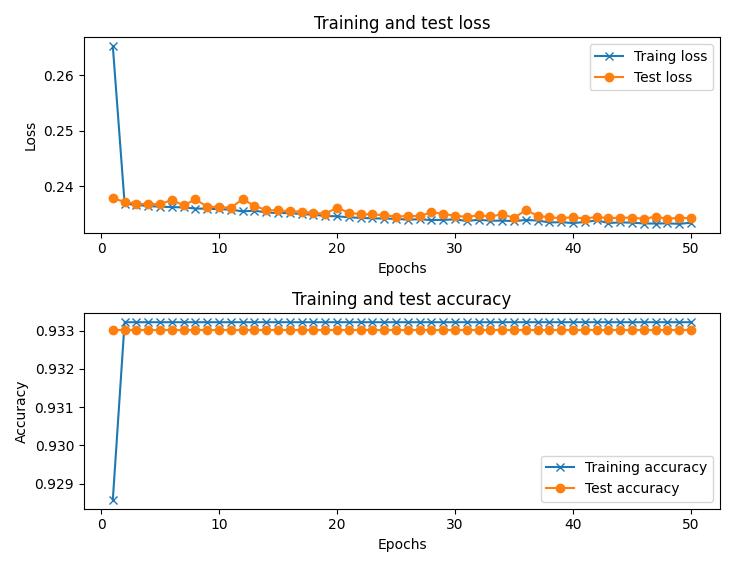
- 对测试数据集进行预测:
pred = model.predict(x_test)
- 按概率递减的顺序排列,检查在测试数据集中,模型预测违约概率最高的前
10%的用户中实际违约的用户数量:
test_data = pd.DataFrame([y_test]).T
test_data['pred'] = pred
test_data = test_data.reset_index(drop='index')
test_data = test_data.sort_values(by='pred', ascending=False)
print(test_data[:int(len(test_data) * 0.1)]['SeriousDlqin2yrs'].sum())
在前面的代码中,将预测值与实际值拼接在一起,然后按输出的预测概率对数据集进行了排序。我们统计了在测试数据集的违约预测概率前 10% (即前 4500 个)的用户中违约者的实际数量。可以看到,通过对 4500 个高概率违约用户与其真实标签进行对比后,我们识别了 1625 个实际违约者,我们可以说这模型具有很好的预测性能,因为在整个数据集中大约只有 6% 的客户违约。
3. 改进模型
3.1 为类别分配权重
当数据集中类别严重失调时称为不平衡数据集,类别权重通过对具有不同权重的类进行惩罚来修改损失函数,即增加数据量较少的类别的权重,减少数据量较多的类别的权重。我们已经知道,在我们使用的信用预测数据集中,只有少量的用户是违约用户,绝大部分用户是正常的,在这种情况下,就属于不平衡数据集。
在上一节中,我们为每个类别分配了相同的权重;即如果实际和预测之间的差异的大小相同,则分类交叉熵损失是相同的,而不管它是用于默认值的预测还是非默认值。为了进一步了解这种情况,考虑以下示例:
| 输出概率 | 真实值 | 损失 |
|---|---|---|
| 0.2 | 1 | 1*log(0.2) |
| 0.8 | 0 | (1-0)*log(1-0.8) |
可以看到,无论真实值如何,交叉熵损失的值都是相同的。但是,我们的目标是在按概率排序时,在预测的概率最大的前 10% 用户中捕获尽可能多的实际违约者。因此,当实际值为 1 时,我们为其分配更高的损失权重(例如分配权重 100 ),而实际值为 0 时分配较低的权重(例如分配权重 1 ),具体更改如下:
| 输出概率 | 真实值 | 损失 |
|---|---|---|
| 0.2 | 1 | 100*1*log(0.2) |
| 0.8 | 0 | 1×(1-0)*log(1-0.8) |
现在,当实际值为 1 时预测错误时的预测损失要比实际值为 0 时预测的损失要高得多。接下来,我们为信用数据集中的输出类分配权重。除了模型拟合过程之外,构建数据集和模型实现的所有步骤均与上一节相同。
3.2 模型构建
使用以下步骤完成模型拟合过程:
history = model.fit(x_train,
y_train,
validation_data=(x_test, y_test),
epochs=50,
batch_size=512,
class_weight=0:1, 1:100,
verbose=1)
在前面的代码片段中,我们创建了一个字典,该字典的权重与输出中的不同类相对应,然后将其传递给 class_weight 参数。上一步确保当实际结果为 1 时我们将权重 100 分配给计算损失值,而当实际结果为 0 时我们将权重 1 分配给计算损失值。准确率和损失值随时间的增加而变化,如下所示:
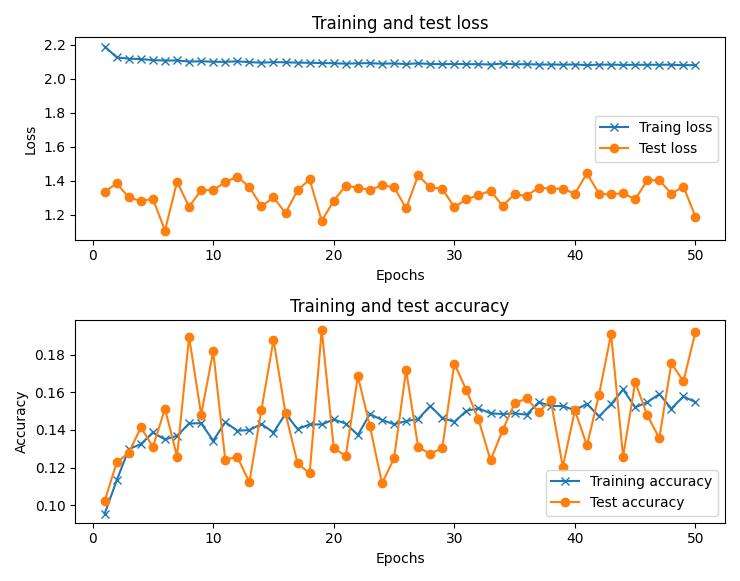
在此迭代中,准确率要低得多,因为与两个类的权重相等的情况相比,我们预计会有更多的数据点属于类别 1。
拟合模型后,我们同样检查在预测为违约用户的数据中,概率前 10% 的用户中实际违约者的数量,如下所示:
test_data = pd.DataFrame([y_test]).T
test_data['pred'] = pred
test_data = test_data.reset_index(drop='index')
test_data = test_data.sort_values(by='pred', ascending=False)
print(test_data[:int(len(test_data) * 0.1)]['SeriousDlqin2yrs'].sum())
与之前在输出概率前 10% 的用户中捕获 1625 个客户的模型相比,在此模型中,我们在输出概率前 10% 的数据中捕获了 1772 个客户,因此对于我们设定的目标而言,性能更好。
在不平衡数据集中,我们的衡量标准不一定是得到尽可能高的准确率。分配类别权重是一种为我们感兴趣的预测类别赋予更高权重的机制。
4. 数据预处理方法总结
在本节内容中,我们使用了多种重要的数据预处理方法,总结如下:
- 插补缺失值:插补变量缺失值的一种方法是将缺失值替换为相应变量的中位数。此外,也可以根据需要用平均值、众数等替换缺失值,也可以用与包含缺失值的行最相似的数据行中的平均值替换缺失值(此方法也称为 k 近邻居插补缺失值)
- 限制离群值:一种限制离群值的方法是用第 p p p 个百分位数值替换高于第 p p p 个百分位数的值
- 缩放数据集:我们对数据集进行缩放,以便随后将其传递到神经网络
小结
本节中,我们尝试构建二分类神经网络解决用户信用预测问题,在模型构建过程中展示了多种数据预处理技术,同时也讲解了如何在不平衡数据集中,对不同类别赋予不同权重可以提高模型性能。
相关链接
Keras深度学习实战(1)——神经网络基础与模型训练过程详解
Keras深度学习实战(2)——使用Keras构建神经网络
Keras深度学习实战(3)——神经网络性能优化技术
Keras深度学习实战(4)——深度学习中常用激活函数和损失函数详解
Keras深度学习实战(5)——批归一化详解
Keras深度学习实战(6)——深度学习过拟合问题及解决方法
以上是关于Keras深度学习实战——信用预测的主要内容,如果未能解决你的问题,请参考以下文章