技术分享 - 智能简历平台
Posted 程序员网址导航
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了技术分享 - 智能简历平台相关的知识,希望对你有一定的参考价值。

项目地址
https://www.coderutil.com/jianli
背景说明
程序员盒子已经上线一年的时间了,作者最近也在思考我们接下来应该推出哪些针对对用户有帮助的服务,程序员人群还有哪些痛点的问题,后来决定做一个在线制作简历的平台,原因:很多人不知道简历该从哪些方面去写;简历内容应该突出哪些内容;找不到合适的模板,找到后模板收费都很贵;最主要的出发点是市面上的模板作者是在是不喜欢,多数都太多花里胡哨,包括自己之前做简历都是word文档个从空白页开始写的。基于这几点原因是希望可以把我从空白模板编写简历的这个耗时耗力的过程进行产品化、线上化,所以就有了现在的:程序员智能简历平台;
技术架构设计
个人在开发一个新的平台、重量级的平台之前习惯先对平台的技术架构做设计,这样可以在开发之前对整个产品的技形态、框架、包括接下来的技术选型提前有一个更清晰的认识。简单对技术架构做了抽象设计:
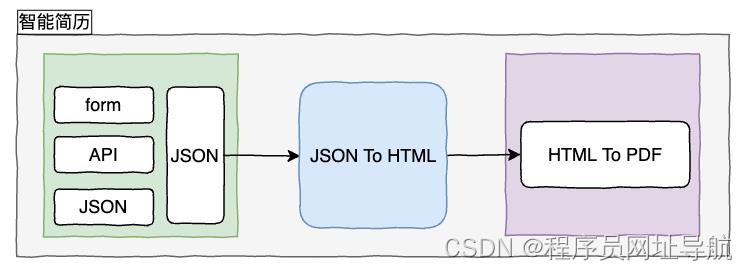
简化后的智能简历最核心的部分如上图所示:
输入:(我们希望可以支持FORM表单 + 程序员熟悉的JOSN结构),最终统一转换为JOSN参数;
JSON转html引擎: 主要负责将JOSN转化为标准化的HTML,便于合成PDF;
HTML转PDF引擎:也是最核心的组件,将HTML转为PDF文件;
核心接口
/**
* @author 程序员七七,程序员盒子网站作者
* @description 简历解析引擎
*/
public interface ResumeParser
/***
* 简历请求参数转换为JOSN
* @param resume
* @return
*/
String parser2Json(ResumeRequestVO resume);
/***
* 简历请求参数转换为HTML
* @param resume
* @param currentUserId
* @param watermark
* @return
*/
String parser2html(ResumeRequestVO resume, String currentUserId, boolean watermark);
/****
* 合成PDF
* @param resume
* @param currentUserId
* @param watermark
* @return
*/
String parser2pdf(ResumeRequestVO resume, String currentUserId, boolean watermark);
简历合成技术
简历合成是智能简历最核心的部分,但也没有很复杂,抛开简历这个业务词汇,其实我们关心的就只有两个问题:JOSN转换为HTML + HTML合成PDF。
首先作者对市面上合成PDF的技术做了一些调研,主要有这几种:
- apache的pdfbox
- itextpdf
- openoffice
- pd4ml
- wkHTMLToPDF
- 第三方的服务
- 其他不够主流的
首先放弃收费的、放弃不支持图片的、放弃过多依赖的、放弃非高清……
最终作者选择了:IText , Maven依赖:
<!--itext7 html转pdf用到的包-->
<dependency>
<groupId>com.itextpdf</groupId>
<artifactId>html2pdf</artifactId>
<version>2.0.2</version>
</dependency>
JSON转HTML引擎
关于JSON转HTML没有太多可以分享的,其实就是根据参数,动态的去拼接HTML,这里重点想要说明HTML需要遵循几点规范(iText要求的):
1.HTML开头必须为:
<!DOCTYPE html PUBLIC '-//W3C//DTD XHTML 1.0 Transitional//EN' 'http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd '>
2.标签需要严格遵守HTML的标签规范,有开头必须要有结尾,什么意思?
比如有div就必须要对应的/div;
再比如img标签这样使用识别会报错,必须使用img/;
引擎核心代码:
public static String json2html(ResumeRequestVO resume, boolean waterMark)
StringBuffer html = new StringBuffer("<!DOCTYPE html PUBLIC '-//W3C//DTD XHTML 1.0 Transitional//EN' "
+ "'http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd '>");
/***
* HTML 头部
*/
html.append("<html xmlns='http://www.w3.org/1999/xhtml '>")
.append("<head>")
.append("<meta http-equiv='Content-Type' content='text/html; charset=UTF-8'/>")
.append("<style> @pagesize: 8.5in 11in; .contentposition: relative; width: 100%; clear: both; "
+ "font-size: 15px; line-height:22px; margin: 0px 0px 5px 0px; text-align: left "
+ ".titlewidth: 100%; text-align: left;font-size: 18px; color: #2d767f; line-height: 12px;"
+ " margin-top: 30px; labelfloat:left; line-height: 12px; margin-right: 10px; height: 25px;"
+ "</style>")
.append("</head>")
.append("<body style='width: 100%; padding: 20px 0px; margin: 0px; color: black;"
+ "font-family: SimHei, SimSun, Courier, Arial'>")
.append("<center>");
/***
* HTML 主体
*/
// 设置水印信息
setResumeWaterMarkInfo(waterMark, html);
// 设置应聘岗位信息
setResumeJobInfo(resume, html);
// 设置应聘人信息
setResumeUserInfo(resume, html);
// 设置学校信息
setResumeEduInfo(resume, html);
// 设置专业技能
setResumeMajorInfo(resume, html);
// 设置工作经历
setResumeWorkInfo(resume, html);
// 设置项目信息
setResumeProjectInfo(resume, html);
// 设置获奖证书信息
setResumeCertificateInfo(resume, html);
// 设置校园经历
setResumeSchoolExperienceInfo(resume, html);
// 设置兴趣特长信息
setResumeInterestInfo(resume, html);
// 设置自我评价信息
setResumeSelfAssessmentInfo(resume, html);
/***
* HTML 尾部
*/
html.append("</center>")
.append("</body>")
.append("</html>");
return html.toString();
HTML合成PDF引擎
上面有提到在PDF合成我们使用的是iText,那其实就比较简单了,直接看代码吧:
@Slf4j
public class PDFFreemarkerUtil
private static final String FONT_PATH = "/home/work/font/simsun.ttc";
/***
* html转pdf
* @param outputFile
* @throws Exception
*/
public static void htmlToPdf(String html, String outputFile) throws Exception
OutputStream os = new FileOutputStream(outputFile);
ITextRenderer renderer = new ITextRenderer();
renderer.setDocumentFromString(html);
// 解决中文支持问题
ITextFontResolver fontResolver = renderer.getFontResolver();
fontResolver.addFont(FONT_PATH, BaseFont.IDENTITY_H, BaseFont.NOT_EMBEDDED);
// 解决图片的相对路径问题
renderer.layout();
renderer.createPDF(os);
os.flush();
os.close();
log.info("PDF 已生成!output:", outputFile);
踩过的一些坑
不支持中文/中文乱码**
遇到不支持中文的情况,这个时候需要我们手动引入中文字体包, 这里我用的宋体:
// 解决中文支持问题
ITextFontResolver fontResolver = renderer.getFontResolver();
fontResolver.addFont("/home/work/font/simsun.ttc", BaseFont.IDENTITY_H, BaseFont.NOT_EMBEDDED);
simsun.tcc下载:https://www.coderutil.com/resource/view?resid=RESOURCE_6222f76083314b22b72a3d7f01da118f
pdf中英文不支持自动换行
由于使用低版本的flying saucer,不支持中文换行,解决办法重写org.xhtmlrenderer.layout.Breaker.java
package org.xhtmlrenderer.layout;
import org.xhtmlrenderer.css.constants.IdentValue;
import org.xhtmlrenderer.css.style.CalculatedStyle;
import org.xhtmlrenderer.render.FSFont;
public class Breaker
public static void breakFirstLetter(LayoutContext c, LineBreakContext context,
int avail, CalculatedStyle style)
FSFont font = style.getFSFont(c);
context.setEnd(getFirstLetterEnd(context.getMaster(), context.getStart()));
context.setWidth(c.getTextRenderer().getWidth(
c.getFontContext(), font, context.getCalculatedSubstring()));
if (context.getWidth() > avail)
context.setNeedsNewLine(true);
context.setUnbreakable(true);
private static int getFirstLetterEnd(String text, int start)
int i = start;
while (i < text.length())
char c = text.charAt(i);
int type = Character.getType(c);
if (type == Character.START_PUNCTUATION ||
type == Character.END_PUNCTUATION ||
type == Character.INITIAL_QUOTE_PUNCTUATION ||
type == Character.FINAL_QUOTE_PUNCTUATION ||
type == Character.OTHER_PUNCTUATION)
i++;
else
break;
if (i < text.length())
i++;
return i;
public static void breakText(LayoutContext c,
LineBreakContext context, int avail, CalculatedStyle style)
FSFont font = style.getFSFont(c);
IdentValue whitespace = style.getWhitespace();
// ====== handle nowrap
if (whitespace == IdentValue.NOWRAP)
context.setEnd(context.getLast());
context.setWidth(c.getTextRenderer().getWidth(
c.getFontContext(), font, context.getCalculatedSubstring()));
return;
//check if we should break on the next newline
if (whitespace == IdentValue.PRE ||
whitespace == IdentValue.PRE_WRAP ||
whitespace == IdentValue.PRE_LINE)
int n = context.getStartSubstring().indexOf(WhitespaceStripper.EOL);
if (n > -1)
context.setEnd(context.getStart() + n + 1);
context.setWidth(c.getTextRenderer().getWidth(
c.getFontContext(), font, context.getCalculatedSubstring()));
context.setNeedsNewLine(true);
context.setEndsOnNL(true);
else if (whitespace == IdentValue.PRE)
context.setEnd(context.getLast());
context.setWidth(c.getTextRenderer().getWidth(
c.getFontContext(), font, context.getCalculatedSubstring()));
//check if we may wrap
if (whitespace == IdentValue.PRE ||
(context.isNeedsNewLine() && context.getWidth() <= avail))
return;
context.setEndsOnNL(false);
String currentString = context.getStartSubstring();
int left = 0;
// int right = currentString.indexOf(WhitespaceStripper.SPACE, left + 1);
int right = getStrRight(currentString,left);
int lastWrap = 0;
int graphicsLength = 0;
int lastGraphicsLength = 0;
while (right > 0 && graphicsLength <= avail)
lastGraphicsLength = graphicsLength;
graphicsLength += c.getTextRenderer().getWidth(
c.getFontContext(), font, currentString.substring(left, right));
lastWrap = left;
left = right;
// right = currentString.indexOf(WhitespaceStripper.SPACE, left + 1);
right = getStrRight(currentString,left+1);
if (graphicsLength <= avail)
//try for the last bit too!
lastWrap = left;
lastGraphicsLength = graphicsLength;
graphicsLength += c.getTextRenderer().getWidth(
c.getFontContext(), font, currentString.substring(left));
if (graphicsLength <= avail)
context.setWidth(graphicsLength);
context.setEnd(context.getMaster().length());
//It fit!
return;
context.setNeedsNewLine(true);
if (lastWrap != 0) //found a place to wrap
context.setEnd(context.getStart() + lastWrap);
context.setWidth(lastGraphicsLength);
else //unbreakable string
if (left == 0)
left = currentString.length();
context.setEnd(context.getStart() + left);
context.setUnbreakable(true);
if (left == currentString.length())
context.setWidth(c.getTextRenderer().getWidth(
c.getFontContext(), font, context.getCalculatedSubstring()));
else
context.setWidth(graphicsLength);
return;
private static boolean isChinese(char c)
Character.UnicodeBlock ub = Character.UnicodeBlock.of(c);
if (ub == Character.UnicodeBlock.CJK_UNIFIED_IDEOGRAPHS
|| ub == Character.UnicodeBlock.CJK_COMPATIBILITY_IDEOGRAPHS
|| ub == Character.UnicodeBlock.CJK_UNIFIED_IDEOGRAPHS_EXTENSION_A
|| ub == Character.UnicodeBlock.GENERAL_PUNCTUATION
|| ub == Character.UnicodeBlock.CJK_SYMBOLS_AND_PUNCTUATION
|| ub == Character.UnicodeBlock.HALFWIDTH_AND_FULLWIDTH_FORMS)
return true;
return false;
private static int getStrRight(String s,int left)
if(left>=s.length())
return -1;
char[] ch = s.toCharArray();
for(int i = left;i<ch.length;i++)
if(isChinese(ch[i]) || ' ' == ch[i])
return i==0?i+1:i;
return -1;
效果展示
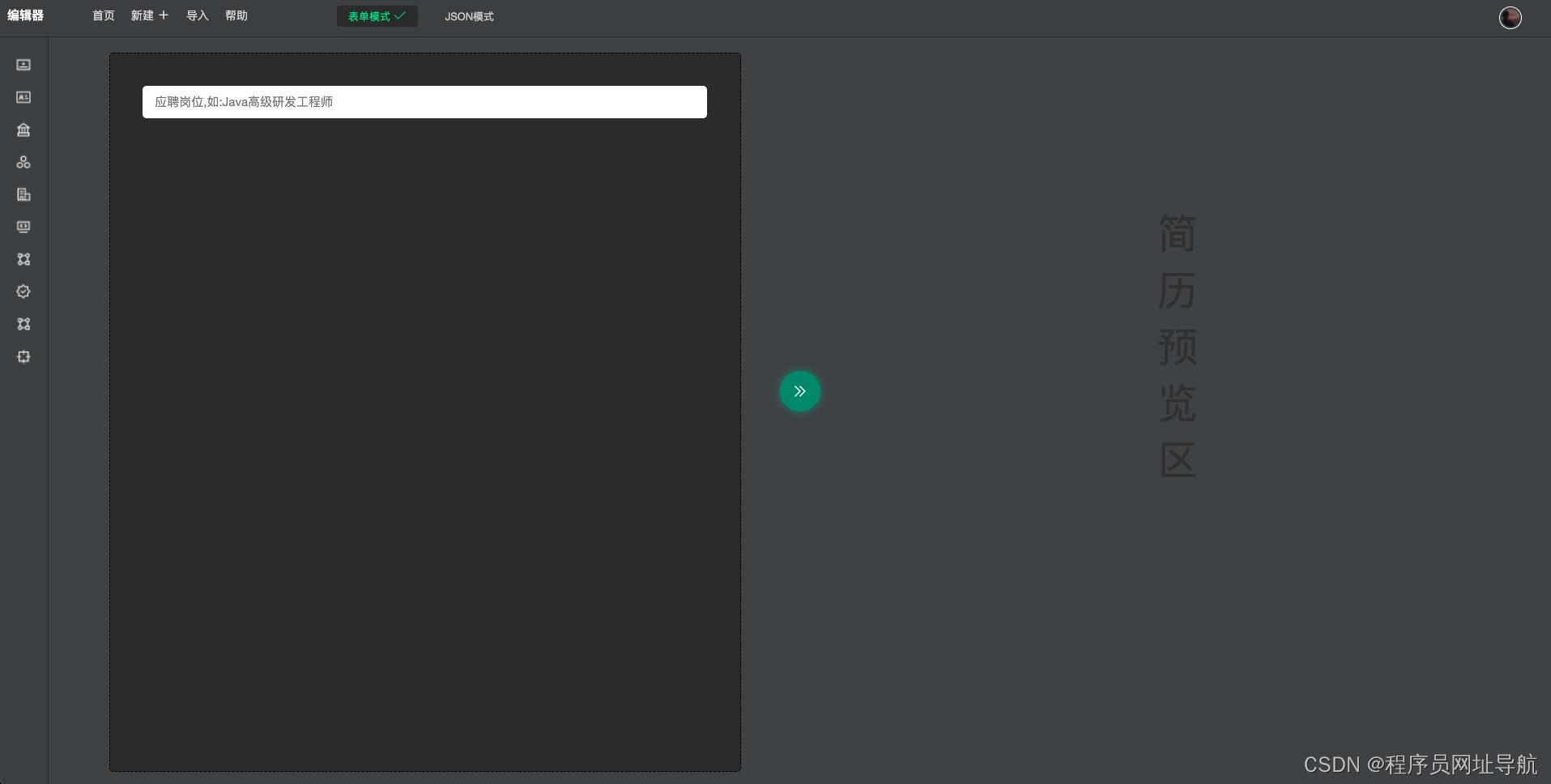
前端编辑器希望跟IDE一样好用
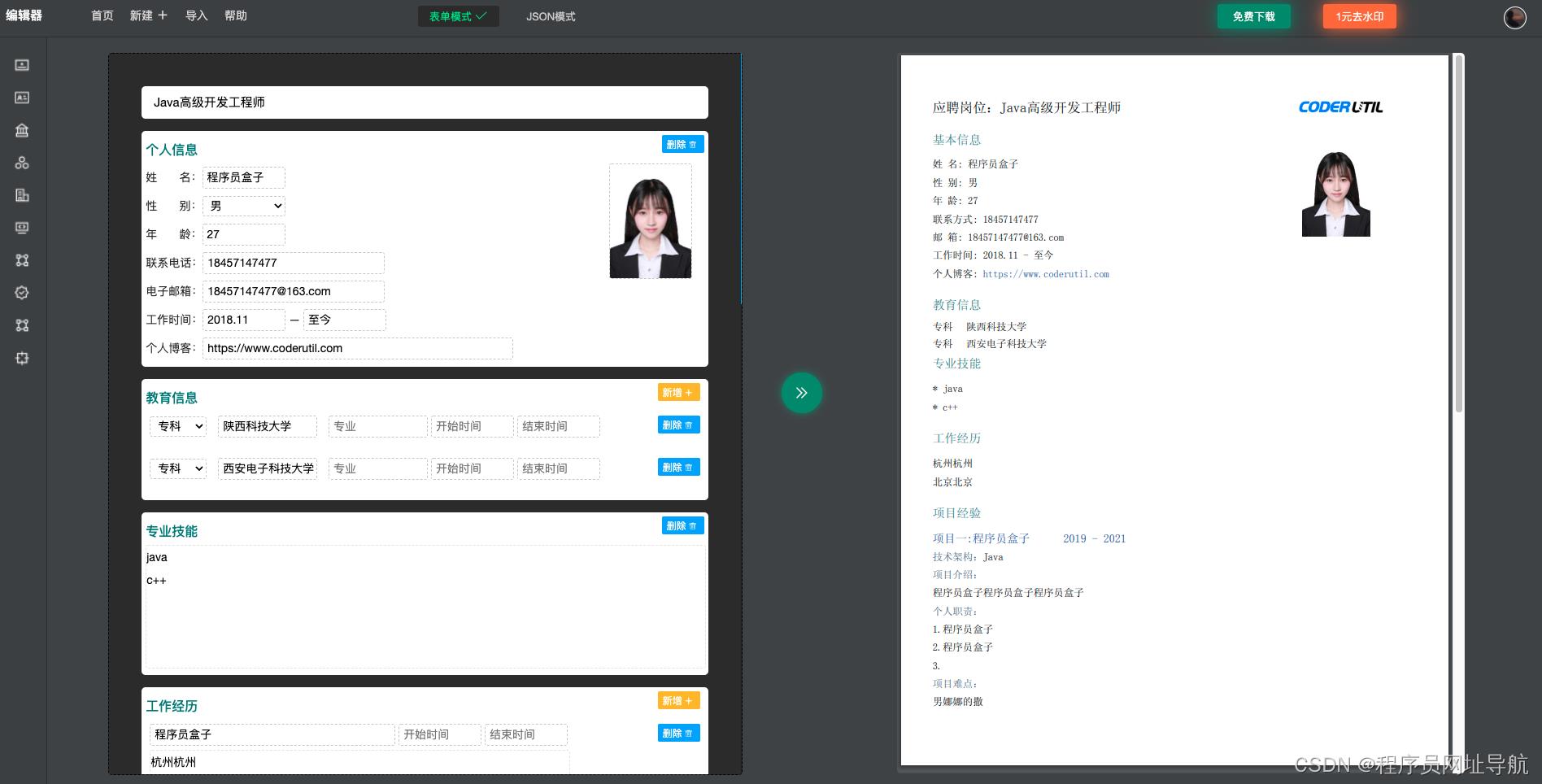
合成简历pdf效果
Good Luck!!!
原文来自:https://www.coderutil.com/article?id=106
以上是关于技术分享 - 智能简历平台的主要内容,如果未能解决你的问题,请参考以下文章