我的机器学习之路!
Posted Datawhale
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了我的机器学习之路!相关的知识,希望对你有一定的参考价值。
本文主要是介绍机器学习的一些基本内容,包含:
除了分类和回归之外的其他机器学习形式
评估机器学习模型的规范流程
为深度学习准备数据
特征工程
解决过拟合
处理机器学习问题的通用流程

一、机器学习4个分支
监督学习supervised learning
最常见的机器学习类型。给定一组样本(通常是人工标准),它可以学会将数据映射到已知目标(也叫标注)。监督学习广泛应用到光学字符识别、语音识别、图像分类和语言翻译。
监督学习除了回归和分类,还有其他变体:
序列生成
语法树预测
目标检测
图像分割
无监督学习
无监督学习是指在没有目标的情况下寻找输入数据的有趣变换,目的是在于数据可视化、数据压缩、数据去噪或者更好地理解数据中的相关性。
主要是降维和聚类
自监督学习
自监督学习是监督学习的特例。自监督学习可以看做是没有人工标注的标签的监督学习。
标签是仍然存在的,但是他们是从输入数据中生成的,通常是使用启发式算法生成的。
一个常见的例子就是:自编码器autoencoder,其目标就是未经修改的输入。
给定视频中过去的帧来预测下一帧,或者给定文本中前面的词语来预测下一个词语,都是属于自监督学习的例子(这两个例子是时序监督学习的例子)
强化学习
强化学习是因为谷歌的DeepMind公司将其成功应用于学习完Atari游戏(还有围棋阿尔法狗)中,才开始被广泛关注。
在强化学习中,智能体agent接收有关其环境的信息,并学会选择使其某种奖励最大化的行动。
二、分类和回归术语
总结一下回归和分类中常出现的术语:
样本、输入:进入模型的数据点
预测、输出:从模型出来的结果
目标:真实值。对于外部数据源,理想状态下,模型能够预测出真实值
预测误差、损失值:预测值和真实值之间的距离
类别:分类问题中供选择的一组标签。比如对猫狗图像进行分类时,猫和狗就是标签
标签:分类问题中类别标注的具体例子。比如1234号图像被标注为包含类别狗,那么“狗”就是1234号图像的标签
真实值和标注:数据集的所有目标。通常是人工收集
二分类:一种分类任务,每个输入样本应该被划分到两个互斥的类别中
多分类:一种分类任务,每个输入样本应该被划分到多个不同的类别中,比如手写数字分类
多标签分类:一种分类任务,每个输入样本都可以分配多个标签。比如一幅图像中既有猫又有狗,那么应该同时标注猫标签和狗标签。每幅图像的标签个数通常是可变的。
标量回归:目标是连续标量值的任务。比如预测房价
向量回归:目标是一组连续值(比如一个连续变量)的任务。如果对多个值进行回归,就是向量回归
小批量或批量:模型同时处理的一小部分样本,通常是8-128.样本数通常是2的幂,方便CPU上的内存分配。训练时,小批量用来为模型权重计算一次梯度下降更新。
三、评估机器学习的模型
机器学习的目的是得到可以泛化的模型:在前所未见的数据集上也能够表现的很好,而过拟合则是核心难点。
3大数据集
评估模型的重点是将数据划分为:训练集、验证集和测试集
训练集:训练模型
验证集:评估模型
测试集:最后一次的测试
模型一定不能读取与测试集任何相关的信息,即使是间接读取也不行。3大经典评估方法:
简单的留出验证
K折验证
带有打乱数据的重复K折验证
3大评估方法
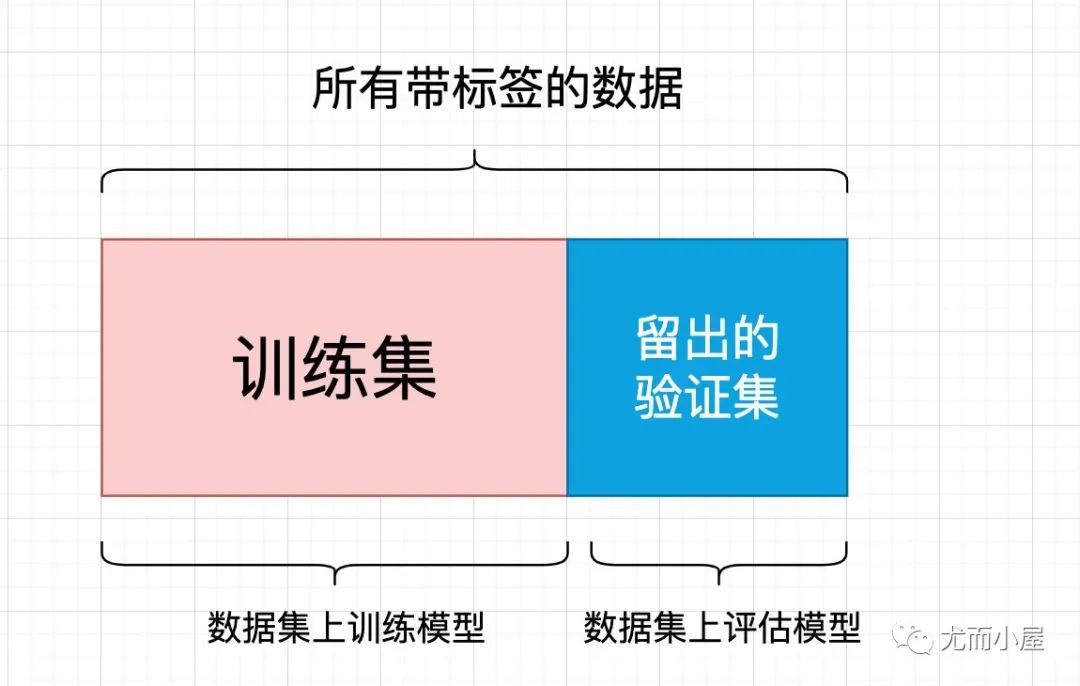
简单的留出验证(hold-out validation)
留出一定的比例的数据作为测试集,在剩余的数据集上训练数据,然后在测试集上评估模型。
为了防止信息泄露,我们不能基于测试集来调节模型,必须保留一个验证集。
# 代码实现
num_validation_samples = 10000
# 打乱数据
np.random.shuffle(data)
validation_data = data[:num_validation_samples] # 验证集
data = data[num_validation_samples:]
train_data = data # 训练集
model = get_model()
model.train(train_data) # 训练集训练模型
validation_score = model.evaluate(validation_data) # 验证集上评估模型
# 调节模型、重新训练、评估,然后再次调节,最后在测试集上评估
model = get_model()
# 将训练集和验证合并起来进行重新训练
model.train(np.concatenate([train_data,validation_data]))
# 测试集上进行评估
test_score = model.evaluate(test_data)一个缺点:如果可用的数据很少,可能验证集和测试集包含的样本很少,从而无法从统计学上代表数据。
因此就有了K折验证和重复的K折验证来解决这个问题。
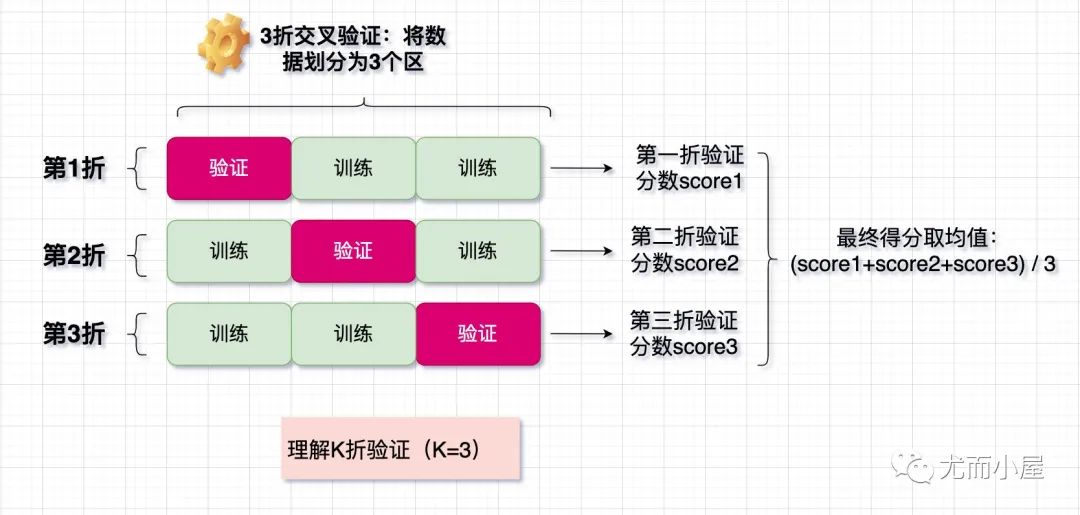
K折验证
使用K折交叉验证的基本原理:
将数据划分为K个分区,通常是4或者5
实例化K个模型,将模型在K-1个分区上训练,剩下的一个区上进行评估
模型的验证分数等于K个验证分数的均值。
如何K折交叉验证:以3折交叉验证为例
# 代码实现
k = 4
num_validation_samples = len(data) // k
# 随机打乱数据
np.random.shuffle(data)
validation_scores = []
for fold in range(k):
# 验证集
validation_data = data[fold * num_validation_samples: (fold + 1) * num_validation_samples]
# 训练集
train_data = data[: fold * num_validation_samples] + data[(fold + 1) * num_validation_samples:]
model = get_model()
model.train(train_data)
validation_score = model.evaluate(validation_data) # 每个验证集上的得分
validation_scores.append(validation_score) # 放到列表中
validation_score = np.average(validation_scores) # K折验证的均值
model = get_model()
model.train(data) # data = train_data + validation_data 所有非测试集上进行训练
test_score = model.evaluate(test_data) # 测试集上进行评估带有打乱数据的K折验证
如果数据很少,又想精确地评估模型,可以使用打乱数据的K折交叉验证:iterated K-fold validation with shuffling。
具体做法:在每次将数据划分为k个分区之前,先将数据打乱,最终分数是每个K折验证分数的均值
注意:这个做法一共要训练和评估P*K个模型,P是重复次数,计算代价很大。
评估模型的注意事项
数据代表性:随机打乱数据
时间箭头:如果想根据过去预测未来,即针对所谓的时间序列的数据,则不应该随机打乱数据,这样会造成时间泄露
数据冗余:确保训练集和验证集之间没有交集
四、数据预处理、特征工程和特征学习
预处理
预处理的主要步骤:
向量化
标准化
处理缺失值
特征提取
向量化
神经网络的所有输入和输出都必须是浮点张量。都必须转成张量,这一步叫做向量化data vectorization
值标准化
数据输入网络前,对每个特征分别做标准化,使其均值为0,标准差为1。
输入神经网络的数据应该具有以下特征:
取值较小:大部分取值在0-1范围内
同质性(homogenous):所有特征的取值范围都在大致相同的范围内
Numpy实现的标准化过程:
X -= X.mean(axis=0) # 假定X是个二维矩阵
X -= X.std(axis=0)缺失值处理
在神经网络中,一般将缺失值用0填充。
特征工程
根据已有的知识对数据进行编码的转换,以改善模型的效果。
特征工程的本质:用更简单的方式表述问题,从而使得问题变得更容易。
现在大部分的深度学习是不需要特征工程的,因为神经网络能够从原始数据中自动提取有用的特征。

五、解决过拟合
什么是过拟合和欠拟合
机器学习的根本问题是优化和泛化的对立。
优化:调节模型以在训练集上得到最佳性能;泛化:训练好的模型在未知数据上的性能好坏。
过拟合overfit:模型在训练集上表现良好,但是在测试集上表现不好。过拟合存在所有的机器学习问题中。
欠拟合underfit:训练数据上的损失越小,测试数据上的数据损失也越小。
过拟合和欠拟合的产生
1、欠拟合问题,根本的原因是特征维度过少,导致拟合的函数无法满足训练集,误差较大。
解决方法:欠拟合问题可以通过增加特征维度来解决。
2、过拟合问题,根本的原因则是特征维度过多,导致拟合的函数完美的经过训练集,但是对新数据的预测结果则较差。解决过拟合问题,则有2个途径:
减少特征维度;可以人工选择保留的特征,或者模型选择算法
正则化;保留所有的特征,通过降低参数θ的值,来影响模型
3招解决过拟合
减小网络大小
防止过拟合最简单的方案:减小模型大小,即减少模型中学习参数的个数(层数和每层的单元个数决定)。
容量:在深度学习中,模型中可学习参数的个数称之为容量。
使用的模型必须具有足够多的参数,以防止过拟合,即模型应该避免记忆资源不足。
# 电影评论分类的原网络
import tensorflow as tf # add
import keras as models
import keras as layers
model = models.Sequential()
model.add(tf.keras.Dense(16, activation="relu",input_shape=(10000, )))
model.add(tf.keras.Dense(16, activation="relu"))
model.add(tf.keras.Dense(1, activation="sigmoid"))用一个更小的网络来替代:
model = models.Sequential()
model.add(tf.keras.Dense(4, activation="relu",input_shape=(10000, )))
model.add(tf.keras.Dense(4, activation="relu"))
model.add(tf.keras.Dense(1, activation="sigmoid"))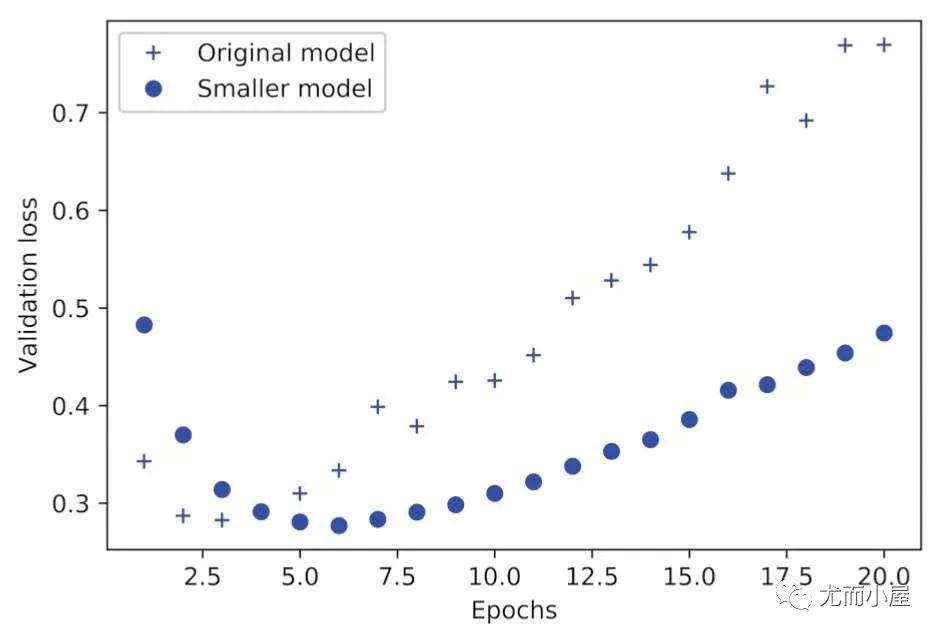
我们发现:更小的网络开始过拟合的时间要晚于之前的网络;而且小网络的性能变差的速度也更慢。
换成更大的模型:
model = models.Sequential()
model.add(tf.keras.Dense(512, activation="relu",input_shape=(10000, )))
model.add(tf.keras.Dense(512, activation="relu"))
model.add(tf.keras.Dense(1, activation="sigmoid"))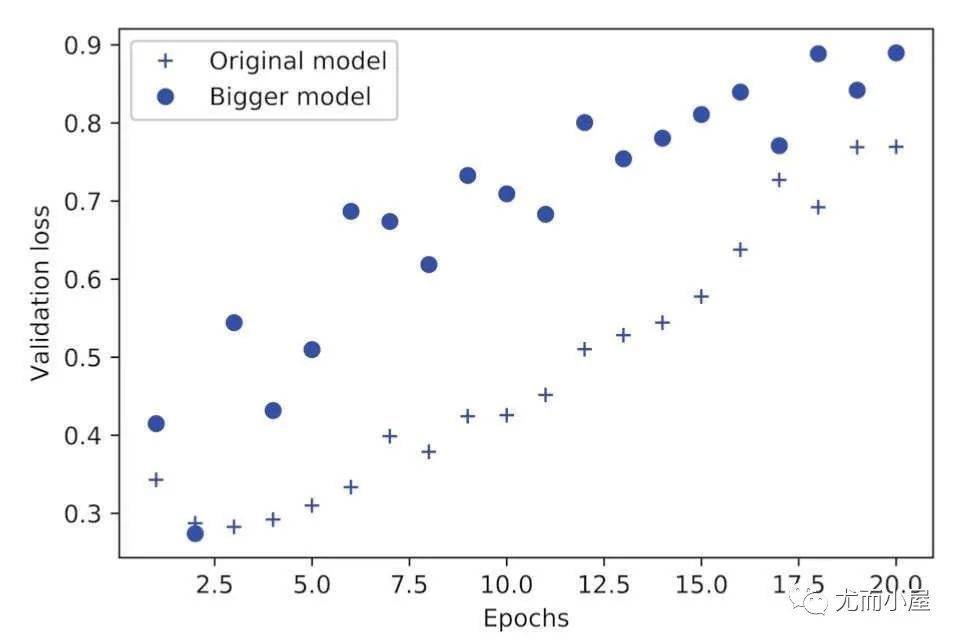
网络的容量越大,拟合训练数据的速度也越快,更容易过拟合。
添加权重正则化(最佳)
奥卡姆剃刀(Occams razor) 原理:如果一件事有两种解释,那么最可能正确的就是最简单的那个,即假设更少的那个。
权重正则化:强制让模型权重只能取较小的值,从而限制模型的复杂度,使得权重的分布更加规则regular。其实现方法:向网络损失函数中添加与较大权重值相关的成本。
具体两种方式:
L1正则化:权重系数的绝对值;L1范数
L2正则化:权重系数的平方;L2范数
神经网络中的L2正则化也叫做权重衰减weight decay。
Keras中添加权重正则化的方法是向层传递:权重正则化实例 作为关键字参数,以添加L2权重正则化为例:
from keras import regularizers
model = models.Sequential()
model.add(tf.keras.layers.Dense(16,kernel_regularizer=regularizers.l2(0.001),
activation="relu",
input_shape=(10000,)))
model.add(tf.keras.layers.Dense(16,kernel_regularizer=regularizers.l2(0.001),
activation="relu"))
model.add(tf.keras.layers.Dense(1,activation="sigmoid"))l2(0.001)的意思是该层权重矩阵的每个系数都会使网络总损失增加0.001*weight_coeffient_value
由于这个惩罚项只在训练时添加,所以网络的训练损失会比测试损失大的多
添加L2正则项前后对比:
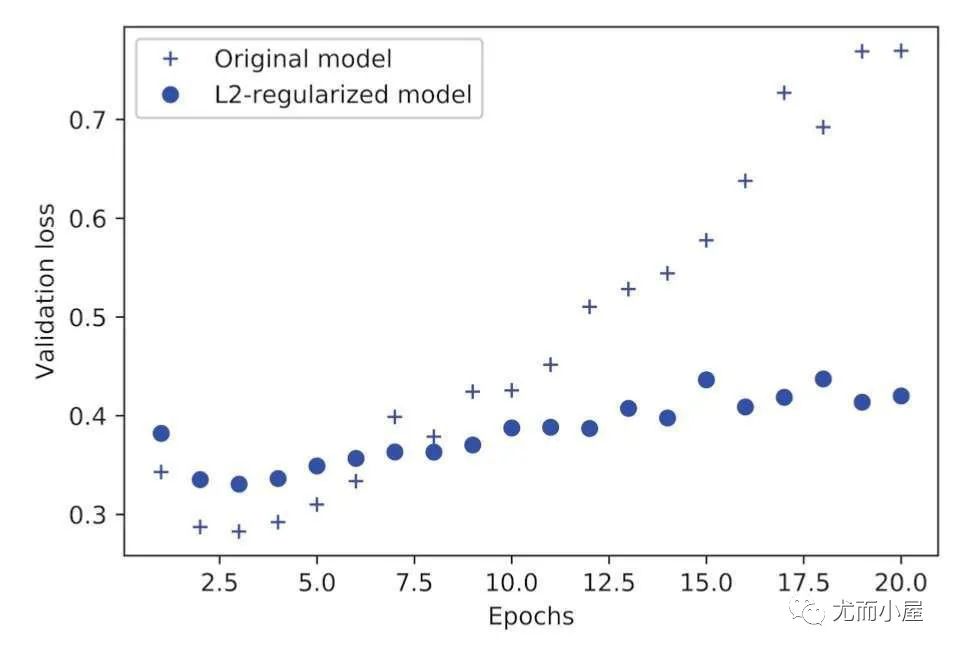
其他权重正则化的添加方式:
from keras import regularizers
regularizers.l1(0.001) # l1正则化
regularizers.l1_l2(l1=0.001, l2=0.001) # 同时添加添加dropout正则化
dropout是神经网络中最有效也是最常用的正则化方式之一,做法:在训练过程中随机将该层的一些输入特征舍弃(设置为0)
dropout的比例就是被设置为0的特征所占的比例,通常在0.2-0.5之间。添加dropout的具体过程:
model.add(tf.keras.layers.Dropout(0.5))要应用在前面一层的输出
model = models.Sequential()
model.add(tf.keras.layers.Dense(16,activation="relu",input_shape=(10000,)))
model.add(tf.keras.layers.Dropout(0.5)) # 添加
model.add(tf.keras.layers.Dense(16,activation="relu"))
model.add(tf.keras.layers.Dropout(0.5)) # 添加
model.add(tf.keras.layers.Dense(1,activation="sigmoid"))总结
防止神经网络过拟合的方法:
获取更多的训练数据
减小网络容量
添加权重正则化
添加dropout
六、机器学习的通用工作流程
问题定义、收集数据
选择衡量成功的标准
平衡分类问题:精度和接受者操作特征曲线下面积-ROC/AUC
分类不平衡问题:准确率和召回率
确定评估方法
留出验证集
K折交叉验证
重复的K折交叉验证
准备数据
数据转成张量
取值缩放到0-1之间
数据标准化
特征工程
开发比基准更好的模型

扩发模型规模:开发过拟合的模型
机器学习中无处不在的对立是优化和泛化的对立,理想的模型是刚好在欠拟合和过拟合的边界上,在容量不足和容量过大的边界上。
为了弄清楚我们需要多大的模型,就必须开发一个过拟合的模型:
添加更多的层
让每一层变的更大
训练更多的轮次
在训练的过程中始终监控训练损失和验证损失,以及我们关心的指标。
模型正则化和调节参数
添加dropout
尝试增加或者减少层数
添加L1或者L2正则化项
尝试不同的超参数
反复做特征工程
以上是关于我的机器学习之路!的主要内容,如果未能解决你的问题,请参考以下文章