用 Python 和 Gensim 库进行文本主题识别
Posted Python学习与数据挖掘
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了用 Python 和 Gensim 库进行文本主题识别相关的知识,希望对你有一定的参考价值。
主题识别是一种在大量文本中识别隐藏主题的方法,它在 Python 的 Gensim 包中有很好的实现。问题的关键是确定如何提取独特、重要的高质量主题。这取决于文本准备质量和确定理想主题数量的方法。
本文我将和大家一起尝试解决这两个问题。喜欢本文记得收藏、关注、点赞。
【注】文末代码、数据、技术交流,文末获取
写在前面
从大量文本中自动提取人们谈论的主题(主题识别)是自然语言处理的基本应用之一。大型文本示例包括社交媒体订阅、消费者对酒店、电影和其他业务的评价、用户评论、新闻和客户发来的邮件。
企业、行政人员和政治竞选活动从了解人们在谈论什么、了解他们的关注和观点中获益匪浅。就我个人而言,阅读如此庞大的书籍并整理主题是很困难的。
因此,我们需要一个自动化系统来阅读文本文档并自动输出提到的主题。
在本中,将使用LDA 从 20Newsgroup 数据集 中提取主题的实战案例。
主题识别的基础知识
本节将涵盖主题识别和建模的原则。云朵君将和大家一起学习如何使用词袋方法和简单的 NLP 模型从文本中检测和提取主题。
词形还原
将单词简化为词根或词干称为词形还原。
首先实例化 WordNetLemmatizer 。调用 '.lemmatize()' 方法来构建一个名为 LEM 的tokens 的新列表。然后调用 Counter 类并生成一个名为 bag_words 的新 Counter,最后输出六个最有可能的主题。
lemmatizer = WordNetLemmatizer()
lem_tokens = [lemmatizer.lemmatize(t) for t in stopwords_removed]
bag_words = Counter(lem_tokens)
print(bag_words.most_common(6))
Gensim 和 LDA
LDA 全称为 Latent Dirichlet Allocation,中文为潜在狄利克雷分配。
Gensim 是一个可以创建和查询语料库的开源自然语言处理 (NLP) 库。它通过构建词嵌入(embeddings)或向量(vectors)来进行操作,然后将其用于对主题进行建模。
深度学习算法用于构建称为词向量的词的多维数学表示。它们提供有关语料库中术语之间关系的信息。例如,“印度”和“新德里” 这两个词之间的距离可能与 “中国”和“北京” 这两个词之间的距离相当,因为它们是“国家-首都”向量。
Gensim 用于创建和查询语料库
之前和大家一起学习了gensim的相关知识,本文将和大家一起动手开发第一个 gensim 词典和语料库!
这些数据结构将查看文档集中的文字趋势和其他有趣的主题。首先,我们导入了一些更混乱的 Wikipedia 文章,这些文章经过预处理,将所有单词小写、标记化并删除停用词和标点符号。然后这些文件被保存为文章,这是一个文档标记的列表。在创建 gensim 词汇和语料库之前,需要做一些初步工作。
Gensim 的词袋
现在,使用新的gensim语料库和字典来查看每个文档中和所有文档中最常使用的术语。你可以在字典里查这些术语。
可以使用 defaultdict 创建一个字典,将默认值赋给不存在的键。我们可以使用int形参确保任何不存在的键被自动分配一个默认值0。
LDA 的文档术语矩阵
创建LDA模型后,我们将在文档术语矩阵上训练LDA模型对象。必须指定主题的数量和字典。我们可能会将主题的数量限制在2到3个,因为我们有一个只有9个文档的小语料库。
当文本自身连贯时,词袋信息(LDA或TF-IDF)通过检测频繁的词来识别主题非常好。当文本不连贯时(在用词或句子意义上),就需要更多的语境信息来充分反映文本的思想。
数据集
本次案例使用可以 从 sklearn 下载的 20Newsgroup 数据集。
from sklearn.datasets import fetch_20newsgroups
newsgroups_train = fetch_20newsgroups(subset='train',
shuffle = True)
newsgroups_test = fetch_20newsgroups(subset='test',
shuffle = True)
该数据集中的新闻已被分类为关键主题。
print(list(newsgroups_train.target_names))

从结果中可以看到它涵盖了各种主题,例如科学、政治、体育、宗教和技术。我们看一些最近新闻的例子。
newsgroups_train.data[:2]

数据预处理
具体步骤如下:
-
使用tokenization标记化将文本拆分为句子,将句子拆分为单词。
-
删除所有标点符号和将所有单词转换为小写单词。
-
过滤少于三个字符的单词。
-
删除所有停用词。
-
将名词进行词形还原,因此第三人称词被转换为第一人称,过去和将来时态动词被改变为现在时态。
-
将它们被简化成最简单的词根形式。
相关库准备
下载 nltk 停用词和必要的包。
import gensim
from gensim.utils import simple_preprocess
from gensim.parsing.preprocessing import STOPWORDS
from nltk.stem import WordNetLemmatizer, SnowballStemmer
from nltk.stem.porter import *
import numpy as np
np.random.seed(400)
import nltk
nltk.download('wordnet')
词形还原器
在开始预处理数据之前,看一个词形还原的例子。如果我们将“Gone”这个词进行词形还原,会发生什么?
以将过去时转换为现在时为例。
print(WordNetLemmatizer().lemmatize('gone', pos = 'v'))
go
词根提取示例。试着往词根分析器输入几句话,看看输出结果是什么。
import pandas as pd
stemmer = SnowballStemmer("english")
original_words = ['sings', 'classes', 'dies', 'mules', 'denied','played', 'agreement', 'owner',
'humbled', 'sized','meeting', 'stating', 'siezing', 'itemization','sensational',
'traditional', 'reference', 'colon','plotting']
singles = [stemmer.stem(plural) for plural in original_words]
pd.DataFrame(data='original word':original_words, 'stemmed':singles )

接下来编写一个函数来运行整个数据集的预处理阶段。
def lemmatize_stemming(text):
return stemmer.stem(WordNetLemmatizer().lemmatize(text, pos='v'))
# Tokenize and lemmatize
def preprocess(text):
result=[]
for token in gensim.utils.simple_preprocess(text) :
if token not in gensim.parsing.preprocessing.STOPWORDS and len(token) > 3:
result.append(lemmatize_stemming(token))
return resul
现在预览预处理后的文档,并得到 Tokenized 和 lemmized 文档。
document_number = 50
doc_sample = 'Sara did not like to read. She was not very good at it.'
print("Original document: ")
words = []
for word in doc_sample.split(' '):
words.append(word)
print(words)
print("nnTokenized and lemmatized document: ")
print(preprocess(doc_sample))
Original document:
['Sara', 'did', 'not', 'like', 'to', 'read.',
'She', 'was', 'not', 'very', 'good', 'at', 'it.']
nnTokenized and lemmatized document:
['sara', 'like', 'read', 'good']
开始预处理所有的新闻标题之前。需要仔细地检查训练示例中的文档列表。
processed_docs = []
for doc in newsgroups_train.data:
processed_docs.append(preprocess(doc))
# Preview 'processed_docs
print(processed_docs[:2])

现在将使用"processed_docs"来构建一个字典,其中包含每个单词在训练集中出现的次数。为此,将其称为"dictionary"并将处理后的文档提供给gensim.corpora.Dictionary()[1]。
创建词袋
从文本中创建一个词袋
在主题识别之前,我们将标记化和词形化的文本转换成一个词包,可以将其视为一个字典,键是单词,值是该单词在语料库中出现的次数。
使用 gensim.corpora.Dictionary,从 "processed_docs" 创建一个字典,其中包含一个术语在训练集中出现的次数,并将其命名为 "dictionary"。
dictionary = gensim.corpora.Dictionary(processed_docs)
首先检查字典是否被创建。
count = 0
for k, v in dictionary.iteritems():
print(k, v)
count += 1
if count > 10:
break
0 addit1 bodi2 bricklin3 bring4 bumper5
call6 colleg7 door8 earli9 engin10 enlighten
过滤极值
删除列表中出现如下所有tokens。
-
大于没有以上文档的(绝对数量)或小于没有以下文档的(绝对数量)(总语料库大小的分数,而不是绝对数量)。
-
只保留(1)和(2)之后的第一个保留n个最常见的标记。(如果为None则保留所有标记)。
dictionary.filter_extremes(no_below=15,
no_above=0.1,
keep_n= 100000)
还可以过滤掉不经常或经常出现的单词。
现在使用生成的字典对象将每个预处理页面转换成一个词袋。即为每个文档建立一个字典,存储有多少单词以及这些单词出现了多少次。
Gensim doc2bow
doc2bow(document)
将文档(单词列表)转换为word格式的2元组列表(token id token计数)。每个单词都是标准化和标记化的字符串(Unicode或utf8-encoded)。在调用此函数之前,对文档中的单词应用标记化、词干分析和其他预处理。
必须使用Bag-of-words模型为每个文档创建一个字典,在这个字典中存储有多少单词以及这些单词出现的次数。“bow corpus”用来保存该字典比较合适。
bow_corpus = [dictionary.doc2bow(doc) for doc in processed_docs]
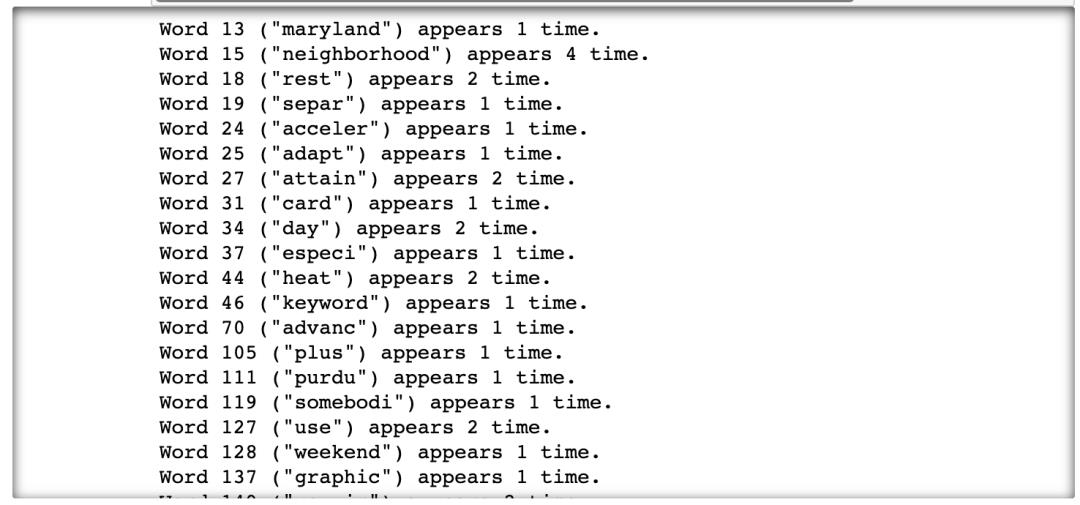
现在,预览预处理的示例文档11的BOW。
document_num = 11
bow_doc_x = bow_corpus[document_num]
for i in range(len(bow_doc_x)):
print('Word ("") appears time.'.format(bow_doc_x[i][0],
dictionary[bow_doc_x[i][0]],
bow_doc_x[i][1]))
执行 LDA
使用 Bag of Words
在文档语料库中,我们的目标是十个主题。为了并行化和加速模型训练,我们在所有 CPU 内核上执行 LDA。
以下是我们将要调整的一些参数:
-
要求从训练语料库中检索到的潜在主题个数为1个主题。
-
id2word 映射将单词 id(整数)转换为单词(字符串)。它用于调试和主题打印,以及确定词汇量。
-
用于并行化的额外进程的数量是workers数量。默认情况下,使用所有可用的内核。
-
超参数 alpha 和 eta 分别影响文档-主题 (theta) 和主题-单词 (lambda) 分布的稀疏性。目前,这些将是默认值(默认值为 1/num 个主题)。
每个文档的主题分布是Alpha
-
高alpha值: 每个文档都有多个主题(文档看起来彼此相似)。
-
低alpha值: 每个文档包含一些主题。
每个主题的单词分布称为Eta
-
高eta值: 每个主题包含各种单词(主题看起来彼此相似)。
-
低eta值: 每个主题包含少量的单词。
因为我们可以使用gensim LDA模型,所以这是相当简单的。但必须指定数据收集中的主题数量。假设我们从八个不同的主题开始。通过该文件的培训次数称为通过次数。
gensim.models 将训练 LDA model. LdaMulticore,并将其放在"LDA model"文件夹。
lda_model = gensim.models.LdaMulticore(bow_corpus,
num_topics = 8,
id2word = dictionary,
passes = 10,
workers = 2)
训练模型后,查看该主题中出现的单词以及它们对每个单词的比例重要性。
for idx, topic in lda_model.print_topics(-1):
print("Topic: nWords: ".format(idx, topic ))
print("n")
主题 Tokens
你能够从每个主题中的单词及其相应的权重中得出哪些类别?
-
0: Gun Violence
-
1: Sports
-
2: Politics
-
3: Space
-
4: Encryption
-
5: Technology
-
6: Graphics Cards
-
7: Religion
模型测试
对未知文档的数据进行预处理。
num = 70
unseen_document = newsgroups_test.data[num]print(unseen_document)
bow_vector = dictionary.doc2bow(preprocess(unseen_document))
for index, score in sorted(lda_model[bow_vector],
key=lambda tup: -1*tup[1]):
print("Score: t Topic: ".format(score, lda_model.print_topic(index, 5)))

这里模型已经完成。现在思考下,如何解释它,看看结果是否有意义。
该模型产生八个主题的输出,每个主题都由一组单词分类。LDA 模型没有给这些词一个主题名称。
模型评估
① 该模型在提取数据集的不同主题方面表现出色,可以通过目标名称评估模型。
② 模型运行速度非常快。仅仅在几分钟内,就可以从数据集中提取主题。
③ 假设数据集包含离散的主题,如果数据集是随机推文的集合,则模型结果可能难以解释。
简单总结
-
通过结合 LDA 主题概率和句子嵌入,上下文主题识别模型同时利用了词袋和上下文信息。
-
尽管LDA在主题识别任务中表现良好,但它在处理要建模的简短文本和不能连贯地解释主题的文档时很困难。它也有局限性,因为它是基于一堆单词。
-
当文本内部是连贯的,词袋信息(LDA或TF-IDF)通过检测频繁的词来识别主题非常好。当文本不连贯时(在用词或句子意义上),就需要更多的信息来反映文本的思想。
gensim.corpora.Dictionary(): https://radimrehurek.com/gensim/corpora/dictionary.html
推荐文章
技术交流
欢迎转载、收藏、有所收获点赞支持一下!

目前开通了技术交流群,群友已超过2000人,添加时最好的备注方式为:来源+兴趣方向,方便找到志同道合的朋友
- 方式①、发送如下图片至微信,长按识别,后台回复:加群;
- 方式②、添加微信号:dkl88191,备注:来自CSDN
- 方式③、微信搜索公众号:Python学习与数据挖掘,后台回复:加群

以上是关于用 Python 和 Gensim 库进行文本主题识别的主要内容,如果未能解决你的问题,请参考以下文章