异常检测之基于聚类的局部异常因子检测算法(CBLOF)详细解释且配上代码运行实例
Posted Icy Hunter
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了异常检测之基于聚类的局部异常因子检测算法(CBLOF)详细解释且配上代码运行实例相关的知识,希望对你有一定的参考价值。
基于聚类的局部异常因子检测算法(CBLOF)
文章目录
前言
服务外包使用了CBLOF算法来检测异常商品,感觉其实对于千万级的数据量来识别异常值还是比较困难的,首先准确率先不谈,能够真正在有限时间跑出结果的算法可能都寥寥无几吧。
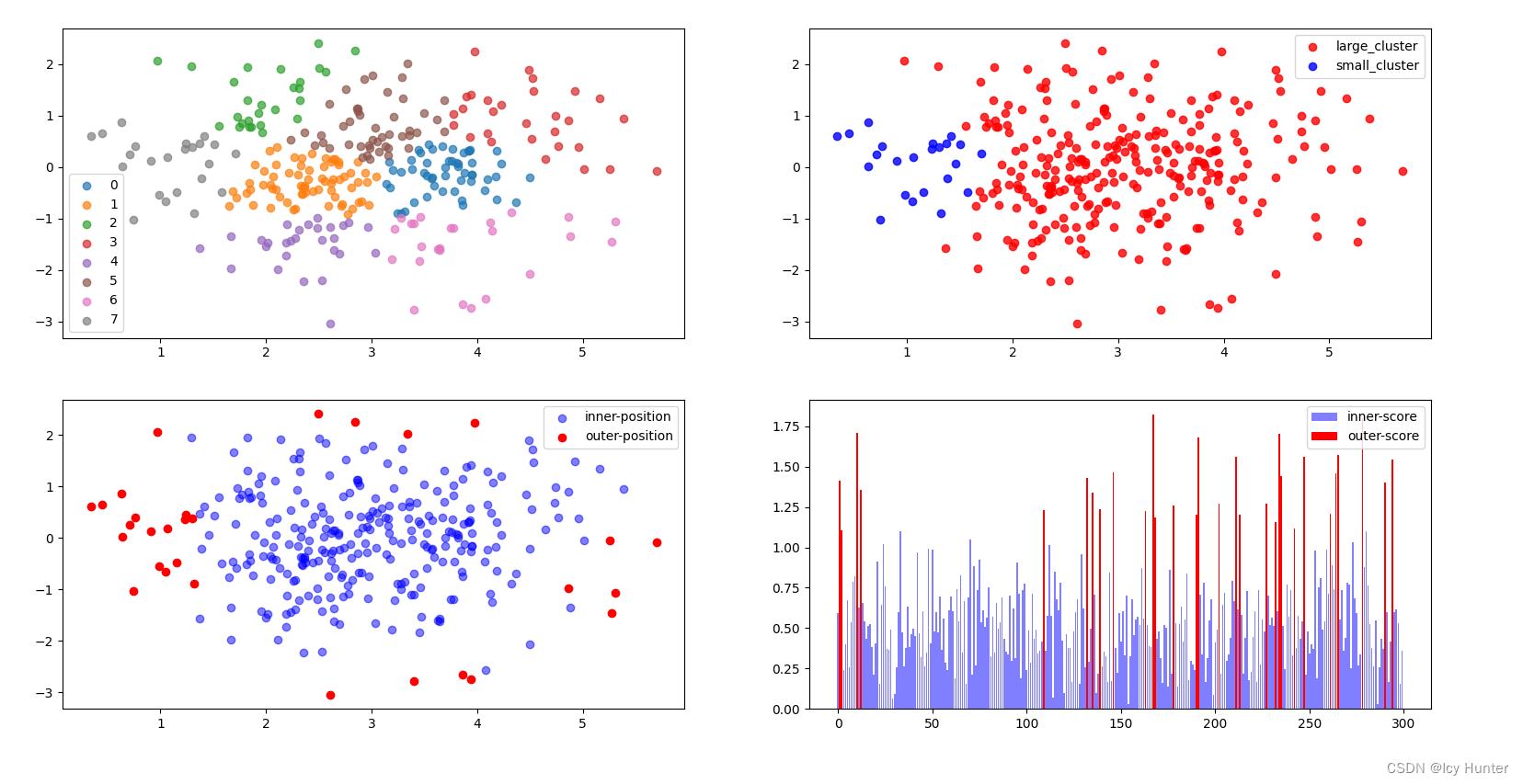
最后代码实例的效果图可以程序先呈现一下,基本上就是CBLOF的整个流程了。
一、CBLOF是什么?
CBLOF即基于聚类的局部因子检测法顾名思义,是一种采用局部离群因子检测法的思想,基于聚类的方法来检测异常值。这个算法和孤立森林一样,是计算各个数据的异常分数,分数越大说明数据越异常。
CBLOF的基本思路就是先将数据进行聚类(我这里使用K-Means聚类),然后区分出大簇和小簇,因为异常值是占少数,往往会和大部分正常的数据有较大偏差,那么只需要计算数据与大簇之间的距离来衡量数据的异常程度,距离越大则数据越异常。
二、CBLOF详解
由于K-Means聚类是线性的时间复杂度和空间复杂度,因此被广泛运用于各种领域,即使是千万级的数据量,也是几分钟就能出结果的,别的聚类算法例如DBSCAN等等基于密度来聚类的,计算比较复杂,对于十万级的数据量可能就已经爆内存了,因此,K-Means虽然有很多局限性,但是其实运用的范围是更加广的。
关于Kmeans算法的实现可以参考我另一篇博客:
K-Means聚类及调用sklearn库代码实现
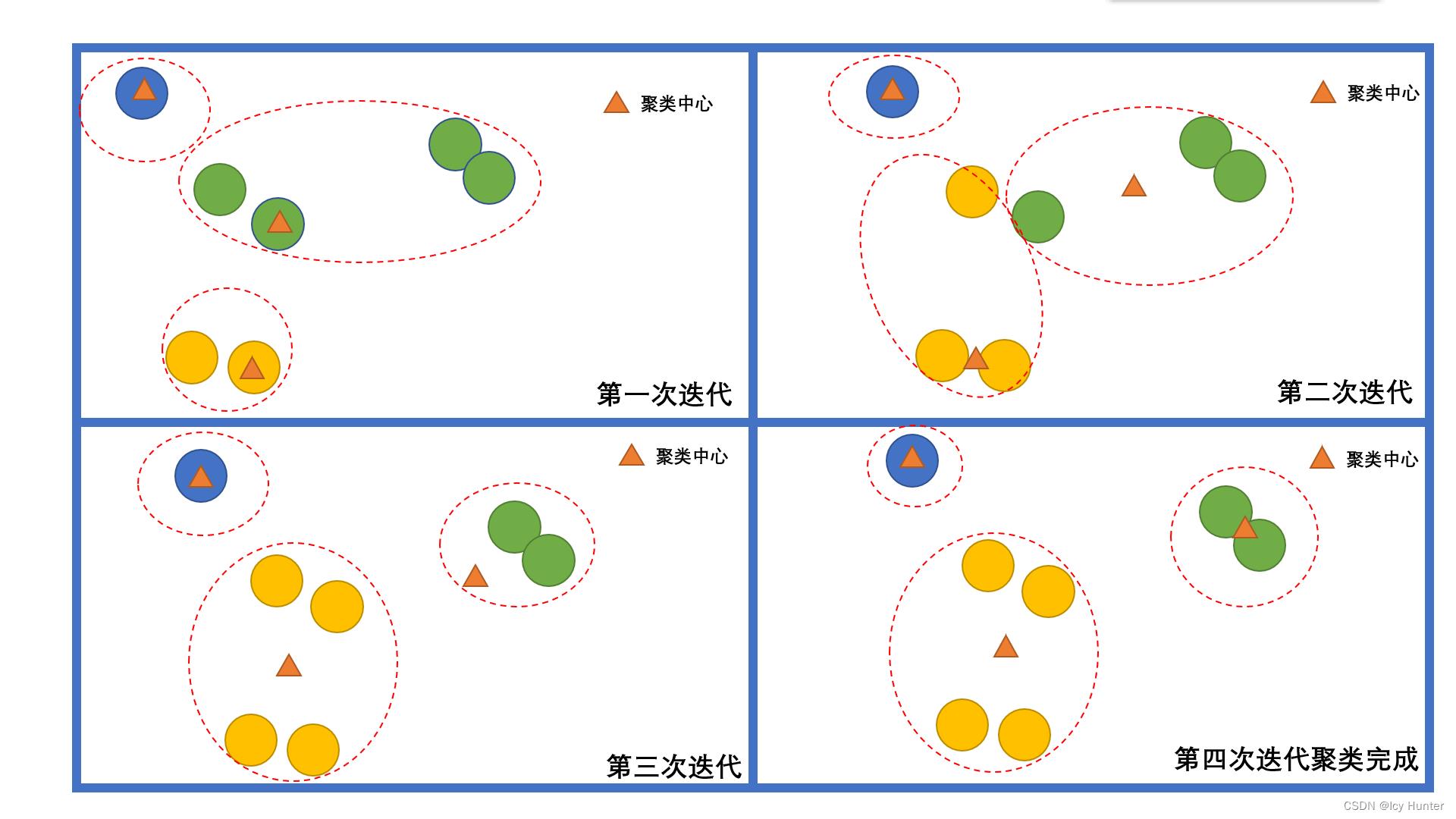
K-Means算法思想和原理基本就是上图这样了。
CBLOF其实也是比较简单,只有线性的时间复杂度和空间复杂度,因此对于千万级的数据也是非常适用的。
只需要知道其中的几个定义就能够非常清晰的了解这个算法了。

(word里的公式复制过来就乱码了,截个图凑合看看)
首先是将数据聚类,我们这里用K-Means聚类。
然后区分聚类后的大小簇,这里区分大小簇的方式有两种。
将每簇按数据量大小从大到小排序之后。
当前几簇的和占总量的α(一般取α=0.9)可以认为前几簇为大簇,之后的就被认为是小簇。
或者,当前一簇是后一簇数量的β倍时(一般β=5),也可以认为前几簇为大簇,后几簇为小簇。
当然,如果两个条件同时满足那自然是最好,满足其中任何一个条件即可区分大小簇了。
最后,计算异常分数,当数据点属于大簇的时候,计算他与当前簇的聚类中心的距离,当数据点属于小簇时,计算他与最近的大簇的聚类中心的距离。得出的就是异常分数,然后从大到小排序,就可以挑选出异常值了。
三、CBLOF代码实例
# coding:utf-8
import pandas as pd
import numpy as np
from pyod.models.cblof import CBLOF
import matplotlib.pyplot as plt
np.random.seed(0)
mean = np.array([3, 0])
cov = np.eye(2)
dot_num = 300
fxy = np.random.multivariate_normal(mean, cov, dot_num)
data = pd.DataFrame(fxy)
data.columns = ["X", "Y"]
model = CBLOF(n_clusters=8, contamination=0.1,alpha=0.9, beta=5,random_state=1000)
model.fit(data)
data["label"] = model.predict(fxy) # 获取异常标签
data["score"] = model.decision_function(fxy) # 获取异常分数
data["cluster"] = model.cluster_labels_ # 获取聚类标签
large_cluster = model.large_cluster_labels_ # 获取大簇标签
small_cluster = model.small_cluster_labels_ # 获取小簇标签
fig = plt.figure()
fig1 = fig.add_subplot(221)
fig2 = fig.add_subplot(222)
fig3 = fig.add_subplot(223)
fig4 = fig.add_subplot(224)
# 画出聚类图(这里基于Kmeans)
for i in range(len(data["cluster"].unique())):
scatter = data[data["cluster"] == i]
fig1.scatter(scatter["X"], scatter["Y"], label=str(i), alpha=0.7)
fig1.legend()
# 画出大小簇的图
cluster_type = []
for i, d in data.iterrows():
if int(d["cluster"]) in small_cluster:
cluster_type.append(0)
else:
cluster_type.append(1)
data["type"] = cluster_type
large = data[data["type"] == 1]
small = data[data["type"] == 0]
fig2.scatter(large["X"], large["Y"], label="large_cluster", alpha=0.8, color="red")
fig2.scatter(small["X"], small["Y"], label="small_cluster", alpha=0.8, color="blue")
fig2.legend()
# 画出异常点的图
inner = data[data["label"] == 0]
outer = data[data["label"] == 1]
fig3.scatter(inner["X"], inner["Y"], label="inner-position", alpha=0.5, color="blue")
fig3.scatter(outer["X"], outer["Y"], label="outer-position", alpha=1, color="red")
fig3.legend()
# 画出异常分数的图
fig4.bar(inner.index, inner["score"], label="inner-score", alpha=0.5, color="blue")
fig4.bar(outer.index, outer["score"], label="outer-score", alpha=1, color="red")
fig4.legend()
plt.show()
print(data["cluster"].value_counts())
print("large_cluster", large_cluster)
print("small_cluster", small_cluster)
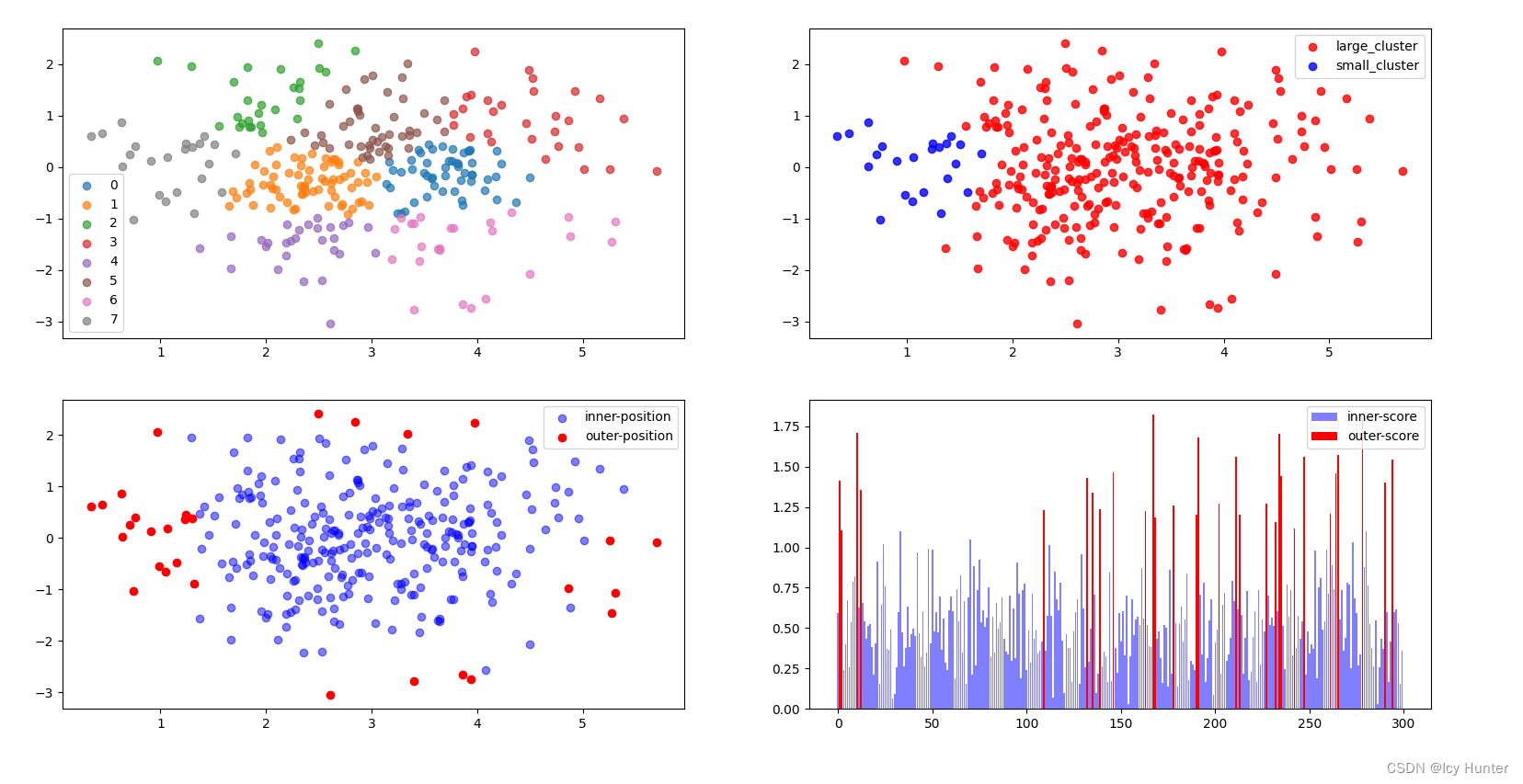
这里有四张图,第一幅图为K-Means的聚类结果,CBLOF里默认是聚成8类,可以自己调整,我这里就默认参数了,然后区分大小簇(第二幅图),然后计算异常分数标注异常(第三幅图),最后一幅图能够看到异常点都是分数较高的点。
值得注意的是这里的contamination=0.1,默认是0.1,可以自己调整,取多少就是取异常分数排名下来前百分之几作为异常。
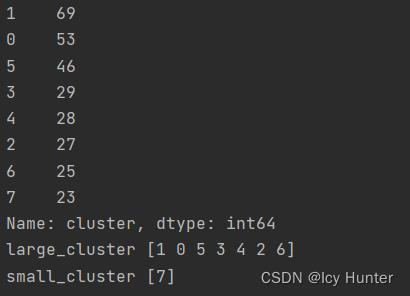
这里是K-Means聚类聚成8类后各簇的数量,由于我数据设置的是正态分布所以还是比较均匀的。
通过计算可以发现
(300-23)/ 300 = 0.923 > α
(300-23-25)/300 = 0.84 < α
因此这里判断大小簇符合的是总量占比>α的原则,由于我们取α=0.9,因此标签为7的簇被认为是小簇,其余都被认为是大簇。
CBLOF算法思路还是比较简单的,聚类算法也可以挑选不同的算法,不过对于千万级的大数据分析的时候,可能K-Means还是比较好的选择。
以上是关于异常检测之基于聚类的局部异常因子检测算法(CBLOF)详细解释且配上代码运行实例的主要内容,如果未能解决你的问题,请参考以下文章