人工智能-作业1:PyTorch实现反向传播
Posted 郭王山而日生
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了人工智能-作业1:PyTorch实现反向传播相关的知识,希望对你有一定的参考价值。
人工智能-作业1:PyTorch实现反向传播
1 安装pycharm,配置好python开发环境
下载链接:http://www.jetbrains.com/pycharm/download/#section=windows
professional 表示专业版,community 是社区版,建议安装社区版,因为是免费使用的。
自己选择安装位置
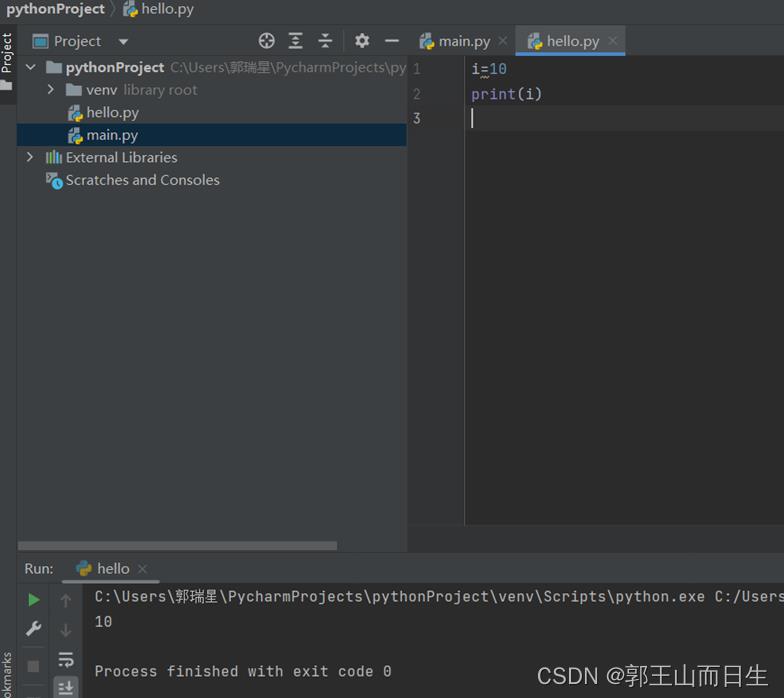
安装成功后,进入简单测试。
2 安装pytorch
第一步:首先安装 Anaconda下载数据包时可以从下面链接处下载:https://mirrors.tuna.tsinghua.edu.cn/anaconda/archive/
选择所有用户可用。
下面两个都勾选
没有必要勾选,弹出界面后还需要关闭。
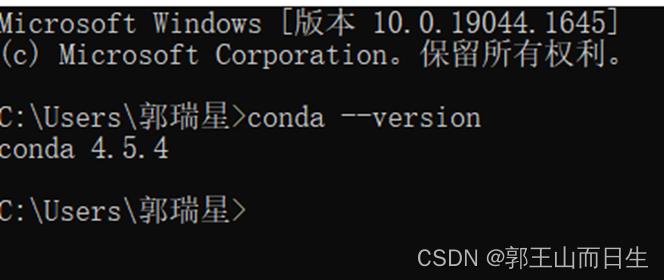
进入查看版本
然后安装PyTorch
进入pytorch官网:https://pytorch.org/
注意CUDA 10.2已不再适合windows,所以应下载CUDA 11.3
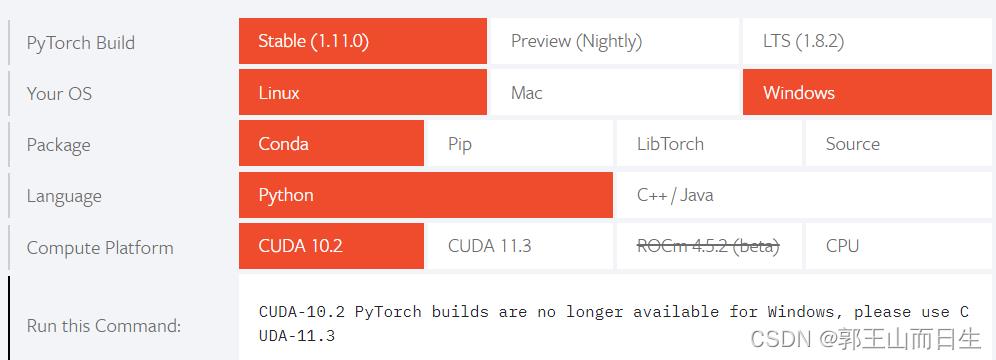
输入下列代码:
conda install pytorch torchvision torchaudio cudatoolkit=11.3 -c pytorch
最后测试一下
打开 Anaconda prompt 命令窗口,激活环境,输入python,进入python开发环境中,然后测试
import torch
torch.cuda.is_available()
结果为true,安装成功
3 使用pytorch实现反向传播
import torch
import math
x = torch.linspace(-math.pi,math.pi,2000)
y = torch.sin(x)
#xx的生成利用到了升维度unsqueeze(-1)对最后一维升维,然后使用广播
p = torch.tensor([1,2,3])
xx = x.unsqueeze(-1).pow(p)
#创建模型
model = torch.nn.Sequential(
torch.nn.Linear(3,1),
torch.nn.Flatten(0,1)
)
#使用均值误差(Mean Squared Error MSE)作为损失函数
loss_fn = torch.nn.MSELoss(reduction='sum')
learning_rate = 1e-6
for t in range(2000):
y_pred = model(xx)
loss = loss_fn(y_pred,y)
if t%100==99:
print(t,loss.item())
model.zero_grad()
loss.backward()
with torch.no_grad():
for param in model.parameters():
param -= learning_rate*param.grad
linear_layer = model[0]
print(f'结果为 y=linear_layer.bias.item()+linear_layer.weight[:,0].item()x+'
f'linear_layer.weight[:,1].item()x^2 +linear_layer.weight[:,2].item()*x^3')
此处可以用unsqueeze()用来增加维度
用squeeze()用来减少维度
PyTorch Autograd自动求导
为了防止跟踪历史记录(和使用内存),可以将代码块包装在with torch.no_grad():中。在评估模型时特别有用,因为模型可能具有requires_grad = True的可训练的参数,但是我们不需要在此过程中对他们进行梯度计算。 还有一个类对于autograd的实现非常重要:Function。 Tensor和Function互相连接生成了一个非循环图,它编码了完整的计算历史。每个张量都有一个.grad_fn属性,它引用了一个创建了这个Tensor的Function(除非这个张量是用户手动创建的,即这个张量的grad_fn是None)。
创建一个张量并设置requires_grad=True用来追踪其计算历史
import torch
x = torch.ones(2, 2, requires_grad=True)
print(x)
对这个张量做一次运算:
y = x + 2
print(y)
y是计算的结果,所以它有grad_fn属性。
print(y.grad_fn)
对y进行更多操作
z = y * y * 3
out = z.mean()
print(z, out)

.requires_grad_(…) 原地改变了现有张量的 requires_grad 标志。如果没有指定的话,默认输入的这个标志是False。
a = torch.randn(2, 2)
a = ((a * 3) / (a - 1))
print(a.requires_grad)
a.requires_grad_(True)
print(a.requires_grad)
b = (a * a).sum()
print(b.grad_fn)
梯度
因为out是一个标量。所以让我们直接进行反向传播,out.backward()和out.backward(torch.tensor(1.))等价
out.backward()
print(x.grad)
输出
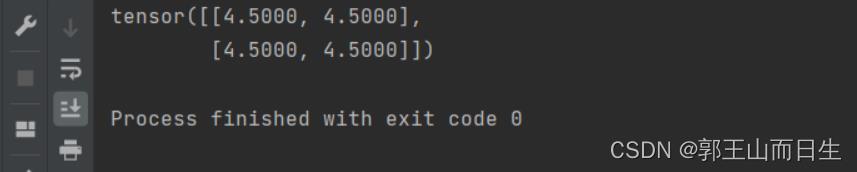
计算过程如下,实质就是一个标量函数对于各个分量求偏导数

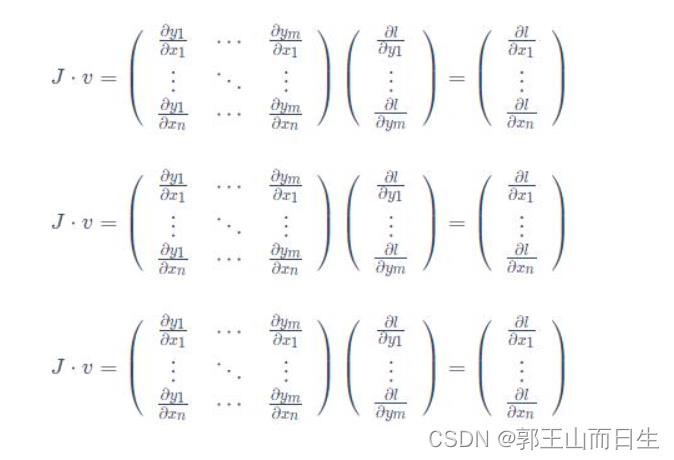
四、 总结
使用Pytorch可以快速求出损失函数对于各个权重的偏导,这个偏导值就是梯度,然后搭配梯度下降法对权重向量进行调整。这样结果反复的调整的迭代后,可以获得一个较理想的神经网络模型。
参考博客:
https://blog.csdn.net/qq_41033011/article/details/109325070
Pytorch实现反向传播: https://blog.csdn.net/qq_41033011/article/details/109325070
以上是关于人工智能-作业1:PyTorch实现反向传播的主要内容,如果未能解决你的问题,请参考以下文章